




- Регистрация
- 23.11.2022
- Сообщения
- 38
- Благодарностей
- 56
- Баллы
- 18
The journey to develop an effective article extraction template using ZennoPoster was a meticulous process that involved extensive testing of different methods, tools, and browser extensions. Given the diversity of website structures, each with its unique layout and content organization, it was crucial to identify the most efficient and reliable approach for gathering content without compromising on accuracy. This required not just a superficial trial of techniques, but a deep dive into the nuances of each method, the evaluation of tens of extensions, and rigorous testing of various combinations to ensure the final solution was both robust and scalable.
1. Exploration of Extraction Techniques
The starting point for this project was to explore the various techniques available for extracting articles directly from web pages. The primary goal was to find a method that could handle the complexity of modern websites, which often include a mix of content elements such as advertisements, interactive features, multimedia, and navigation menus. These elements frequently interfere with straightforward data extraction, necessitating a more nuanced approach.
1.1. Direct HTML Parsing
Direct HTML parsing was the first method I explored, leveraging ZennoPoster’s built-in capabilities to parse and extract content directly from the DOM (Document Object Model). This approach is fundamentally simple: the template would load the HTML structure of a webpage, locate the specific tags where the article content is housed (such as <article>, <div>, or <p> tags), and extract the text within those tags.
For websites with clean, well-structured HTML where the content is neatly contained within identifiable tags, this method worked quite well. It allowed for rapid extraction of content, which could then be saved in the desired format (HTML or TXT).
However, as the testing extended to more complex websites, several issues became apparent. Many modern websites are designed with dynamic, JavaScript-driven content that loads asynchronously, meaning that the article content might not be immediately available in the initial HTML load. Furthermore, sites often embed content within nested tags or use non-standard tags and classes, making it difficult to create a one-size-fits-all extraction template. The method also struggled with sites that heavily interweave ads, related article links, and other distracting elements within the main content area.
1.2. JavaScript Execution
To address the limitations of direct HTML parsing, I next explored the use of JavaScript within ZennoPoster to interact with web pages more dynamically. This method involved executing scripts within the browser to simulate user interactions, such as clicking buttons to load more content or bypassing JavaScript-based barriers.
JavaScript execution provided a more flexible approach, allowing the template to adapt to the dynamic nature of modern web pages. It enabled the automation of interactions that would otherwise require manual input, such as dismissing pop-ups, expanding hidden content, or navigating through multi-page articles.
Despite these advantages, this method introduced new challenges. The need for custom scripts tailored to each specific website reduced the scalability of this approach. Every new site required a fresh set of scripts, significantly increasing the time and effort required to maintain the template for a large number of sites.
2. Comprehensive Testing of Browser Extensions
While refining the extraction methods, I also recognized the potential of browser extensions to enhance the process. Extensions offered a way to modify the browser environment directly, simplifying the content structure before extraction. This led me to evaluate tens of extensions to find those that could best support the article extraction task.
2.1. Ad Blockers:

One of the first and most critical challenges was dealing with intrusive advertisements. Ads not only cluttered the content but also significantly slowed down the extraction process, as they introduced additional elements that needed to be filtered out. Over time, I tested multiple ad-blocking extensions, each offering varying levels of effectiveness.
The testing involved running them on a series of ad-heavy websites, comparing how each ad blocker performed. Metrics such as page load speed, the number of ads blocked, and the impact on content accuracy were considered. Some ad blockers struggled with more aggressive ad formats, leaving behind remnants that interfered with the content extraction. Others blocked too much, including content elements, resulting in incomplete extractions.
 uBlock Origin emerged as the most effective ad blocker. It provided a balanced approach, blocking the majority of ads and trackers without disrupting the main content. Its customizable filters allowed for fine-tuning, ensuring that only unwanted elements were blocked.
uBlock Origin emerged as the most effective ad blocker. It provided a balanced approach, blocking the majority of ads and trackers without disrupting the main content. Its customizable filters allowed for fine-tuning, ensuring that only unwanted elements were blocked.2.2. Reader Mode Extensions:
Another significant challenge was dealing with non-essential content, such as navigation menus, footers, and related article links, which are commonly included alongside the main article content. To address this, I explored reader mode extensions designed to strip away all but the core text of an article.
Each reader mode extension was tested on a variety of websites, with the focus on how well it isolated the main content. The key metrics were the accuracy of the content extraction, the readability of the resulting text, and the consistency of performance across different sites.
 After testing numerous extensions, Just Read* proved to be the most reliable. It consistently delivered clean, distraction-free versions of articles, removing extraneous elements that could complicate the extraction process. Its simplicity and effectiveness made it an ideal tool to integrate into the ZennoPoster template.
After testing numerous extensions, Just Read* proved to be the most reliable. It consistently delivered clean, distraction-free versions of articles, removing extraneous elements that could complicate the extraction process. Its simplicity and effectiveness made it an ideal tool to integrate into the ZennoPoster template.*The original version was modified to meet my requirements.
2.3. Other Utility Extensions:
In addition to ad blockers and reader modes, I also tested a range of utility extensions that offered additional functionality, such as content highlighters; these extensions helped in identifying key content areas by highlighting specific tags or classes. However, while useful for manual inspection, they proved less beneficial in an automated setting.
3. ZennoPoster’s Contribution to Testing and Optimization
ZennoPoster was not just the tool used for automation; it was also a critical component in the testing and optimization process. Its capabilities allowed me to conduct thorough, systematic testing and to fine-tune the template for maximum performance.
3.1. Automating the Testing Process:
I set up automated test cases that could run through various scenarios without requiring constant manual oversight.
The template would load a set of URLs, apply a different browser extension for each run, and extract the content. This allowed for direct comparison of results under consistent conditions.
After each test run, the results were logged, and the template was adjusted based on the findings. This iterative process helped in quickly identifying the most effective methods and extensions, without the need to manually reset the environment between tests.
3.2. Comparing Results and Gathering Data:
By collecting detailed logs of each extraction attempt, including the time taken, the amount of content extracted, and any errors encountered, I was able to build a comprehensive dataset that informed my decisions.
This data was used to assess the performance of different methods and extensions, providing clear evidence of which approaches were most efficient and accurate.
4. Final Refinement and Results
The ZennoPoster template I developed is designed to automate the extraction of articles from various websites, significantly enhancing efficiency and accuracy. By automating this process, the template addresses the time-consuming task of manually collecting and organizing articles, providing users with a streamlined method to gather content in either HTML or TXT format. This solution is particularly beneficial for content aggregators, researchers, and anyone requiring bulk article extraction without compromising on quality.
4.1. Template Breakdown
4.1.1 Browser Configuration:
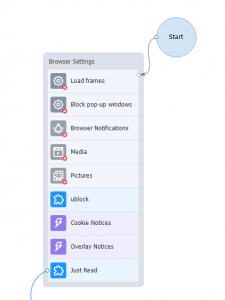
- Editing Browser Settings: The template initiates by optimizing browser settings for faster and more efficient performance. This includes disabling unnecessary features such as loading frames, blocking popup windows, and disabling notifications that could interrupt the automation process.
- Adding Required Extensions: To further streamline the extraction process, I incorporated the uBlock Origin extension to block intrusive ads and trackers, ensuring a cleaner page load. Additionally, the Just Read extension is used to enable reading mode, stripping away non-article content like menus and footers to focus solely on the article text.
4.1.2 Dual Working Modes:
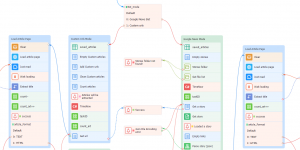
- Custom URLs Mode: In this mode, the template loads URLs from a pre-defined file, saving them to a list for sequential processing. For each URL, the template loads the page, extracts the article title and content, and saves the extracted data to a file in either HTML or TXT format, depending on the user's preference.
- Google News Mode: This mode is specifically designed to handle Google News articles. The template loads JSON files that were previously generated by another ZennoPoster template, which parses Google News stories (focusing on top news). The JSON files are then processed one by one, with each article being extracted and saved in the desired format.
4.2 Results Achieved
The template has successfully automated the extraction of articles from a variety of sources, drastically reducing the time required for manual collection. It has proven to be a reliable and efficient tool, allowing users to gather large volumes of content with minimal effort.
