


Всем привет! Столкнулся с проблемой, что не получается извлекать все почты из пдф в браузере или файле. Я хочу по регулярному значению извлекать текст из файла, но у меня не получается. Иногда извлекаются почты, но не все, а иногда вообще ничего. В данный момент я сделал следующую реализацию: по get-запросу я скачиваю pdf как файл, потом я читаю файл и добавляю содержимое в переменную, а уже потом я извлекаю текст через регулярное выражение и добавляю всё в список. До этого пробовал читать прямо с браузера через открытие ссылки в активном окне, но через DOM вообще ничего не получилось взять.
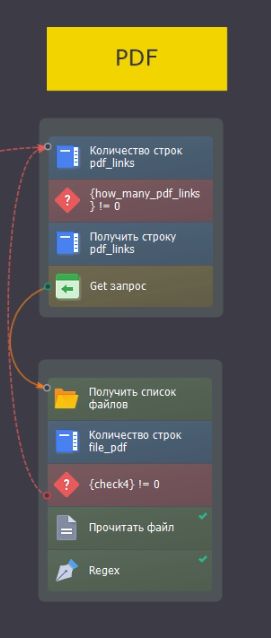
Подскажите, как это можно реализовать, может какие библиотеки нужно установить?
Подскажите, как это можно реализовать, может какие библиотеки нужно установить?