



Всем привет, друзья! Подскажите, пожалуйста, решение проблемы
Моя задача: перевести текст и скопировать его, сохраняя его оригинальную текстуру (абзацы)
Вот мой текст: https://dzen.ru/a/Y50D0_XXplwwYRK-
Вставляю его на перевод сюда: https://translate.google.com/?hl=ru&sl=ru&tl=es&op=translate
И далее мне нужно спарсить результат, сохраняя оригинальную текстуру абзацев.
Если просто парсить текст, то почему-то вместо 8 больших строк (как в оригинале), он сохраняет в список 41 абзаец по одному-два предложения.
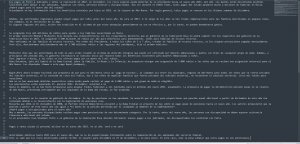
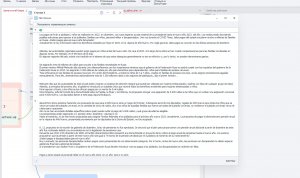
Как мне сохранить оригинальную структуру текста? Я нашел такой вариант: Парсинг DOM регуляркой (?<=language-name="испанский"\ data-text=")[\w\W]*(?="\ data-crosslingual-hint="") Результат получается правильным на глаз (скрин 1) Но если эту переменную переносить в список, то там почему-то все идет как будто один абзаец (скрин 2) Как мне вернуть тексту абзацы?
Моя задача: перевести текст и скопировать его, сохраняя его оригинальную текстуру (абзацы)
Вот мой текст: https://dzen.ru/a/Y50D0_XXplwwYRK-
Вставляю его на перевод сюда: https://translate.google.com/?hl=ru&sl=ru&tl=es&op=translate
И далее мне нужно спарсить результат, сохраняя оригинальную текстуру абзацев.
Если просто парсить текст, то почему-то вместо 8 больших строк (как в оригинале), он сохраняет в список 41 абзаец по одному-два предложения.
Как мне сохранить оригинальную структуру текста? Я нашел такой вариант: Парсинг DOM регуляркой (?<=language-name="испанский"\ data-text=")[\w\W]*(?="\ data-crosslingual-hint="") Результат получается правильным на глаз (скрин 1) Но если эту переменную переносить в список, то там почему-то все идет как будто один абзаец (скрин 2) Как мне вернуть тексту абзацы?
Вложения
-
 454,9 КБ Просмотры: 44
454,9 КБ Просмотры: 44 -
 291,1 КБ Просмотры: 52
291,1 КБ Просмотры: 52
