На мысль натолкнула простая идея от одного парсера сайтов .
Есть кусок кода который перед искомым текстом потом макрос {skip}, означающий пропустить любое число символов в этом куске
И кусок текста следующий после искомого текста.
И в принципе эта схема позволяет найти любой кусок нужного текста,
даже без указания, с чего начинается и заканчивается текст(опционально поможет)
И не нужны никакие xPath (кстати xPath до сих пор не показывает число совпадений), и прочие хреновины
В конструкторе регулярок Зенно постера отсутствует возможность вставить "пропустить любое число символов"
вписывать ".*" или любую регулярку в ТЕКСТ ПРЕДШЕСТВУЮЩИЙ ИСКОМОМУ смысла нет, ибо конструктор это сразу экранирует, и даже исправив в результируещей регулярке, потом начинаются гемор и сама идея конструктора регулярок сразу сводится на нет.
Прошу разработчиков обратить на такую систему поиска которая найдет все что угодно
1) кусок кода который перед искомым текстом,
2) в нём любое число макросов, например {skip},
означающих пропуск любого число символов включая переносы означающий [\w\W]*
3) и кусок текста следующий сразу после искомого текста.
4) опционально также помогут " с чего начинается текст", и "с чего заканчивается текст"
И уже не важно, что используется для поиска в итоге регулярное выражение или xPath
Не забудьте поставить счетчик числа совпадений
и образец выпаршенных вариантов как в инструменте "парсить текст".
Я уверен что других методов поиска даже не понадобится
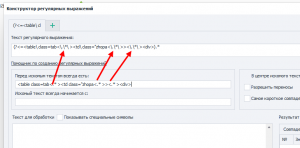
пожалуйста придумайте макрос в поле "текст перед искомым текстом"
какой нибудь макрос означающий пропуск любого числа любых символов включая переносы типа {skip} или {any}
Ибо использование ".*" и "[\w\W]*" в результирующей регулярке в конструкторе регулярок экранируется \.\*
Такой же прием очень пригодится во всех конструкторах xPath в том числе.
Идея проста: " чтоб любой конструктор мог искать только после конкретного куска кода.
Тут конечно мегапрограммисты скажут, учи xPath и проучие мануалы. Но этим способом можно найти что угодно
В парсере очень легко пишется поиск
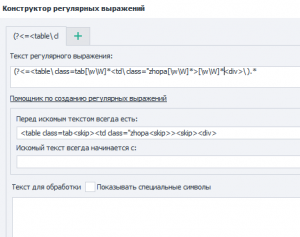
Текст вначале искомого текста:
<div class="content{skip}<table class=tab{skip}<td class="zhopa"{skip}>{skip}<div class="zhopa2"{skip}>
Текст в конце искомого текста:
</div>
Очень удобно когда нужно отбросить всякие атрибуты и теги <div{skip}myclass{skip}>
Такая схема хорошо помогает, когда в верстке напрочь отсутствуют классы и прочие атрибуты тегов и афтор решил использовать одинаковые классы для кучи разных тегов.
Начните с конструктора регулярок.
чтобы из поля текст предшествующий искомому макрос {skip} в результирующую регулярку писал [\w\W]*"
В конструкторе действий это вообще будет бомба
Всего 4 поля
1) текст которого до искомого с использованием {skip} --> [\w\W]*"
2) текст после искомого
3) 4) и текст с которого начинается и текст которым заканчивается.
И к черту все остальные способы с кучей полей и комбобоксов
Есть кусок кода который перед искомым текстом потом макрос {skip}, означающий пропустить любое число символов в этом куске
И кусок текста следующий после искомого текста.
И в принципе эта схема позволяет найти любой кусок нужного текста,
даже без указания, с чего начинается и заканчивается текст(опционально поможет)
И не нужны никакие xPath (кстати xPath до сих пор не показывает число совпадений), и прочие хреновины
В конструкторе регулярок Зенно постера отсутствует возможность вставить "пропустить любое число символов"
вписывать ".*" или любую регулярку в ТЕКСТ ПРЕДШЕСТВУЮЩИЙ ИСКОМОМУ смысла нет, ибо конструктор это сразу экранирует, и даже исправив в результируещей регулярке, потом начинаются гемор и сама идея конструктора регулярок сразу сводится на нет.
Прошу разработчиков обратить на такую систему поиска которая найдет все что угодно
1) кусок кода который перед искомым текстом,
2) в нём любое число макросов, например {skip},
означающих пропуск любого число символов включая переносы означающий [\w\W]*
3) и кусок текста следующий сразу после искомого текста.
4) опционально также помогут " с чего начинается текст", и "с чего заканчивается текст"
И уже не важно, что используется для поиска в итоге регулярное выражение или xPath
Не забудьте поставить счетчик числа совпадений
и образец выпаршенных вариантов как в инструменте "парсить текст".
Я уверен что других методов поиска даже не понадобится
пожалуйста придумайте макрос в поле "текст перед искомым текстом"
какой нибудь макрос означающий пропуск любого числа любых символов включая переносы типа {skip} или {any}
Ибо использование ".*" и "[\w\W]*" в результирующей регулярке в конструкторе регулярок экранируется \.\*
Такой же прием очень пригодится во всех конструкторах xPath в том числе.
Идея проста: " чтоб любой конструктор мог искать только после конкретного куска кода.
Тут конечно мегапрограммисты скажут, учи xPath и проучие мануалы. Но этим способом можно найти что угодно
В парсере очень легко пишется поиск
Текст вначале искомого текста:
<div class="content{skip}<table class=tab{skip}<td class="zhopa"{skip}>{skip}<div class="zhopa2"{skip}>
Текст в конце искомого текста:
</div>
Очень удобно когда нужно отбросить всякие атрибуты и теги <div{skip}myclass{skip}>
Такая схема хорошо помогает, когда в верстке напрочь отсутствуют классы и прочие атрибуты тегов и афтор решил использовать одинаковые классы для кучи разных тегов.
Начните с конструктора регулярок.
чтобы из поля текст предшествующий искомому макрос {skip} в результирующую регулярку писал [\w\W]*"
В конструкторе действий это вообще будет бомба
Всего 4 поля
1) текст которого до искомого с использованием {skip} --> [\w\W]*"
2) текст после искомого
3) 4) и текст с которого начинается и текст которым заканчивается.
И к черту все остальные способы с кучей полей и комбобоксов
Последнее редактирование:

 :-)")
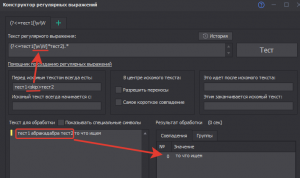



 Вопрос только в надежности работы кода. А вдруг в тексте лишний пробел или символ появится, тогда регулярка выдаст пустоту.
Вопрос только в надежности работы кода. А вдруг в тексте лишний пробел или символ появится, тогда регулярка выдаст пустоту.