




Привет всем. Что-то у меня с парсингом выдачи поломано.
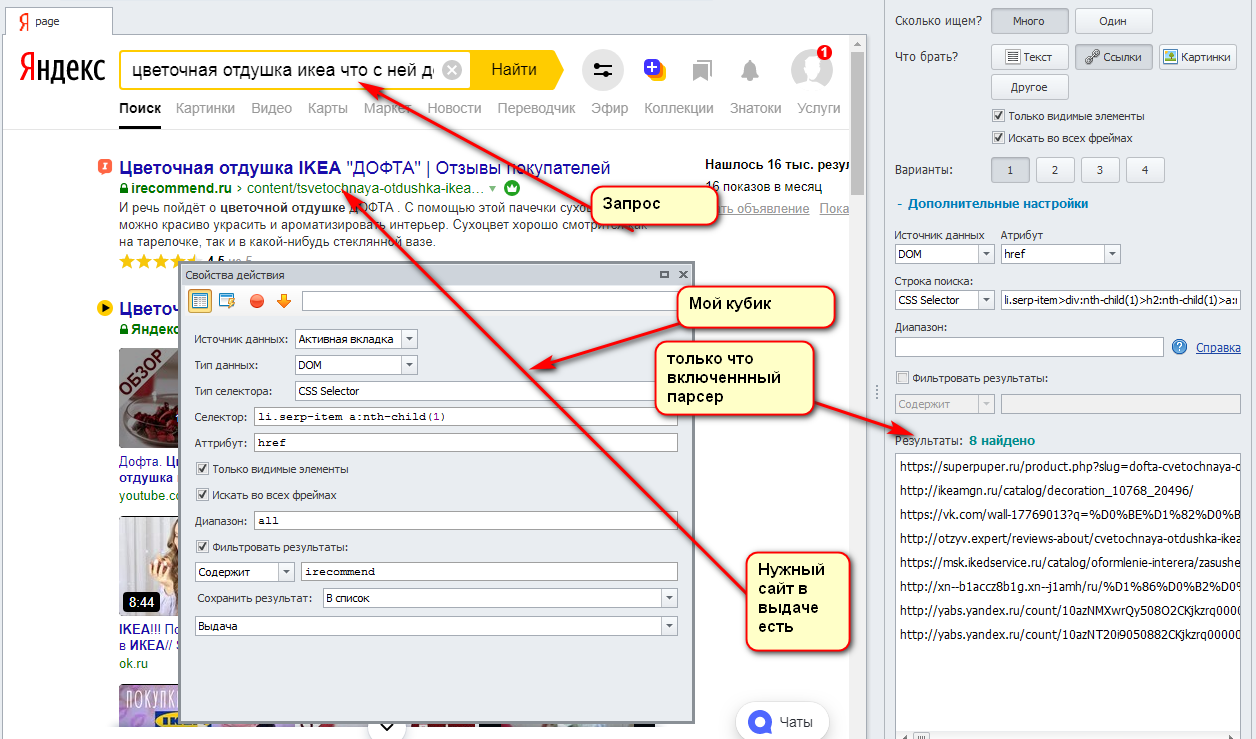
Настраиваю спарсить результаты выдачи по случайному запросу чтобы получить ссылку того сайта который мне нужен. Но иногда сайт есть в выдаче а в список не попадает и программ его не видит.
На скрине мой кубик который настроен и парсит (через раз удачно)
также указан запрос по которому идет поиск и что в результате есть нужный сайт.
Справа настройки свежего парсинга (провой кнопкой нажал на тайтл выдачи и - парсить) Как видите там в списке нет того что нужно.
Но так не всегда. В отдельных случаях в списке есть целевой урл. В какой ситуации есть и в какой нет - не понимаю и как на это повлиять тоже.
Настраиваю спарсить результаты выдачи по случайному запросу чтобы получить ссылку того сайта который мне нужен. Но иногда сайт есть в выдаче а в список не попадает и программ его не видит.
На скрине мой кубик который настроен и парсит (через раз удачно)
также указан запрос по которому идет поиск и что в результате есть нужный сайт.
Справа настройки свежего парсинга (провой кнопкой нажал на тайтл выдачи и - парсить) Как видите там в списке нет того что нужно.
Но так не всегда. В отдельных случаях в списке есть целевой урл. В какой ситуации есть и в какой нет - не понимаю и как на это повлиять тоже.
 :-)")
