- Регистрация
- 20.08.2024
- Сообщения
- 24
- Благодарностей
- 60
- Баллы
- 13
Приветствую участников форума!
С новым конкурсом от Zennolab я решил выйти из reedonly. На форуме я не активничал, хотя моя история с Zennoposter началась ещё в далеком 2016-м.
Как всё начиналось
Тогда я был начинающим кодером. Собирал email-базы для CPA, пытался спамить через MailChimp, пока он еще позволял вольности. Сначала работал руками, потом подключил Datacol, но быстро уперся в потолок: источников мало, базы протухают, а эффективность падает.
Нужны были объемы. Взлом я отмел сразу, а легальные источники (вроде Common Crawl) пугали своими масштабами. Я тогда даже про нарезку файлов через CMD не знал. Данные были, но взять их я не мог. И вот тут я открыл для себя Zennoposter. Он стал тем самым комбайном, который превратил хаос в ресурс.
Эпоха обучения
Купив лицензию, я поселился на форуме. Автоматизировал всё, что движется. Жадно изучал C# и разбирал каждую строчку кода. Это было золотое время: никаких нейросетей, только хардкор и понимание того, как всё работает под капотом.
Но гештальт с Big Data и Common Crawl остался незакрытым — тогда мне просто не хватило опыта и мощностей.
Почему я здесь сейчас
Прошли годы. Пришел опыт в кибербезопасности, аналитике и понимание ценности данных (привет всем, кто в теме RAG).
Сегодня модно считать, что учиться не надо: сказал нейронке «сделай» — и готово. «Вайб-кодинг», для смузи тушек. Когда я советую Zennoposter, новички фыркают: «Дядь, проснись, все давно уже на ИИ делают, знаешь что это?».
Это задело. Не за себя, а за тех, кто ищет реальный инструмент, а им подсовывают (цитирую сам себя) «кривосколоченный огрызок чужих ошибок».
Поехали! Для начала нужно было выбрать тему. На мой взгляд, идеальный проект для форума должен соответствовать пяти критериям:
- Польза и выгода. Неважно, какой у тебя опыт: тема должна либо приносить деньги сама по себе, либо помогать реализовывать навыки для заработка. Это аксиома.
- Автономность. Всё работает «из коробки»: никаких сторонних библиотек и сложных настроек.
- Актуальность. Тема должна быть востребована здесь и сейчас.
- Легальность. Никакого спама, черных схем и обмана.
- Увлекательность. Процесс должен затягивать!
Выбор пал на кибербезопасность.
Почему? В этой сфере много шума: новички часто выдают себя за «хакеров», но обижаются на любую критику. Мне же хотелось показать другой подход — системный анализ и автоматизацию с помощью Zennoposter, а не «взлом ради лайков». При этом большинство якобы "экспертов" уже достали своими "надутыми" размышлениями о том сколько лет необходимо учиться чтобы находить уязвимости. К концу этой статьи у нас будет миллион (+\-) уязвимостей критического уровня стоимостью в миллионы долларов BugBounty (поэтому вам по ушам ездят про трудности, тут самые легкие деньги). Но еще что ВАЖНО - полученные нами данные смогут использовать IT специалисты, маркетологи, аналитики, инженеры и.т.д.
Да дорогие друзья. Это будет взлом матрицы.
Вот четыре причины моего выбора:
- Реабилитация инструмента. Хочу доказать, что списывать Zennoposter со счетов рано. Это мощный комбайн для кастомных решений. А заодно развенчать миф инфоцыган о том, что вход в кибербез — это что-то запредельно сложное и дорогое.
- Высокий спрос. Сейчас появляется много некачественного кода и приложений, поэтому хорошие специалисты по безопасности нужны как никогда. При этом нам нужна безопасная среда для тестов, чтобы не нарушать закон.
- Личный вызов. Давно хотел поработать с массивами данных Common Crawl, и здесь это идеально вписывается.
- Деньги. О монетизации расскажу уже по ходу истории. SPOILER - Сейчас вы только на вершине понимания и возможно неприятия данного проекта, но с каждой демонстрацией модулей денежные перспективы будут перекрывать всю большую часть IT рынка пока не заполонит ее до горизонта
Где деньги, Лебовски? Или что такое Bug Bounty
Итак, мы определились с инструментом (Zennoposter) и направлением (Кибербезопасность). Но как на этом заработать легально, не опасаясь стука в дверь в 6 утра? Ответ прост и изящен: Bug Bounty.
Если максимально просто: Bug Bounty — это когда компании (Google, Яндекс, Facebook, Ozon и тысячи других) официально платят вам деньги за то, что вы нашли уязвимость в их системе и рассказали об этом им, а не продали хакерам в Даркнете.
Это легальное хакерство. Вы — «Белый хакер» (White Hat).
Как это работает на пальцах?
Представьте, что вы проходите мимо банка.
- Черный хакер: Видит открытую форточку, залезает, крадет деньги и убегает.
- Багхантер (Вы): Видит открытую форточку, пишет управляющему банка: «Эй, у вас там окно открыто, любой может залезть». Управляющий жмёт вам руку и выписывает чек на $1000.
Вам не обязательно взламывать Пентагон. Деньги платят за ошибки логики, которые часто допускают разработчики:
- Халява в интернет-магазине. Вы положили в корзину iPhone за 100 000 руб., перехватили запрос, поменяли цену на 1 рубль, и магазин оформил заказ. Нашли такое? Репортите — получаете награду.
- Чужие данные (IDOR). Вы зашли в свой профиль на сайте, в адресной строке видите user_id=100. Поменяли на user_id=101 — и увидели паспортные данные другого человека. Это критическая уязвимость!
- XSS (Скрипты). Вы вставили в поле комментария специальный код, и теперь у всех, кто заходит на страницу, всплывает окно или воруются куки.
Не нужно писать письма в «Спортлото». Есть специальные платформы-агрегаторы, где компании размещают свои программы:
- HackerOne (hackerone.com) — король рынка. Тут сидят Uber, PayPal, GM. Выплаты могут достигать десятков тысяч долларов за критический баг.
- Bugcrowd (bugcrowd.com) — главный конкурент первого. Огромное комьюнити.
- Intigriti (intigriti.com) — европейская платформа, очень лояльная к новичкам.
- BugBounty.ru / Standoff 365 — отечественные платформы. Яндекс, VK, Озон, Госуслуги — все здесь. Платят в рублях, всё официально и легально.
А вот тут начинается самое интересное.
Зарегистрировались вы на HackerOne. Там тысячи программ. У каждой — сотни поддоменов, серверов и страниц.
Руками всё это проверять — жизни не хватит. Обычные сканеры (вроде Acunetix или Burp Suite Pro) стоят дорого, и их сигнатуры всем известны — админы их часто блокируют. Также множество скрипткиди с одинаковыми инструментами и паттернами долбят по сайтам из за чего администраторы настраивают серьезные правила брандмауэра, стоп-списки в robots, а сервера порой семафорят при подозрительных последовательных запросах, что требует закупки множества хороших прокси, что не есть профессионально. Ну и как говорилось - некоторые типы сканирования могут интерпретироваться как вторжение что может повлечь очень серьезные юридические последствия.
И вот здесь на сцену выходим мы с Zennoposter и Common Craw
Common Crawl: Цифровая память человечества (и наша золотая жила)
Мы разобрались с Bug Bounty. Мы поняли, что искать уязвимости на "живом" сайте — это хорошо, но конкуренция там бешеная. Тысячи исследователей сканируют одни и те же IP-адреса одними и теми же сканерами.
А теперь представьте, что у вас есть Машина Времени.
Вы можете вернуться на месяц, год или 7 лет назад и посмотреть, как выглядел сайт жертвы. Какие там были ссылки? Какие забытые поддомены работали? Какие ключи разработчики случайно забыли в коде, а потом удалили?
Эту машину времени зовут Common Crawl.
Что это такое? (Объясняю на пальцах)
Common Crawl — это некоммерческая организация, которая делает, казалось бы, невозможную вещь. Каждый месяц их боты обходят ВЕСЬ доступный интернет и делают его "снимок" (снэпшот).
Они сохраняют всё:
- HTML-код страниц.
- Картинки и стили.
- Тексты.
- Заголовки ответов сервера.
Объем этих данных колоссален — это петабайты информации. Это миллиарды страниц. Это, по сути, резервная копия Интернета.
Зачем это нужно нам (Багхантерам)?
Обычный пользователь видит сайт таким, какой он сейчас.
Мы же, используя данные Common Crawl, видим тень сайта. И в этой тени скрыты сокровища:
- Забытые поддомены.
Разработчик поднял тестовый сервер dev-test-2021.bank.com, забыл его закрыть, но убрал все ссылки с главной страницы. Google про него забыл. А Common Crawl — помнит. В базе за 2021 год ссылка осталась. Мы находим её, заходим — а там админка без пароля. Бинго. - Утечки API-ключей.
Вчера программист Вася выложил скрипт с ключом от AWS, получил по шапке от начальника и сегодня удалил файл. На сайте файла нет. Но бот Common Crawl успел зайти к Васе вчера вечером и сохранил этот файл. Мы скачиваем архив и достаем ключ. - Скрытая структура.
Параметры URL, скрытые каталоги, старые версии API — всё это оставляет цифровой след. Анализируя историю, мы составляем карту сайта, которая в разы полнее, чем у любого, кто сканирует сайт "в лоб" прямо сейчас.
Чтобы вы не утонули в терминах, давайте упростим. Данные Common Crawl хранятся в трех основных форматах. Представьте, что это библиотека:
WARC (Web ARChive) — «Книга целиком»
Полная, точная копия страницы со всеми тегами, скриптами, картинками и ответами сервера. Это самые тяжелые файлы. Если нам нужно восстановить сайт таким, каким он был 5 лет назад — качаем WARC.
Файлы WARC (Web ARChive) — это основной формат, который проект Common Crawl использует для хранения миллиардов скачанных веб-страниц в одном архиве. Представьте их как цифровые «контейнеры», где внутри одного большого файла упакованы тысячи отдельных сайтов со всеми их текстами, кодом и метаданными.
В отличие от простого сохранения текста, формат WARC записывает не только содержимое страницы, но и техническую информацию о запросе: дату сканирования, IP-адрес сервера и HTTP-заголовки. Это делает данные максимально точными для исследователей, так как файл буквально «замораживает» состояние интернета в конкретный момент времени. Для экономии места эти архивы всегда сжимаются (обычно в формате .gz), а их структура позволяет быстро находить нужные фрагменты без распаковки всего гигантского массива данных.
Посмотреть как выглядят файлы WARC вы можете тут

 youtube.com
youtube.com
В отличие от простого сохранения текста, формат WARC записывает не только содержимое страницы, но и техническую информацию о запросе: дату сканирования, IP-адрес сервера и HTTP-заголовки. Это делает данные максимально точными для исследователей, так как файл буквально «замораживает» состояние интернета в конкретный момент времени. Для экономии места эти архивы всегда сжимаются (обычно в формате .gz), а их структура позволяет быстро находить нужные фрагменты без распаковки всего гигантского массива данных.
Посмотреть как выглядят файлы WARC вы можете тут
WARC (Web ARChive) — «Книга целиком»
Полная, точная копия страницы со всеми тегами, скриптами, картинками и ответами сервера. Это самые тяжелые файлы. Если нам нужно восстановить сайт таким, как...
WET (Web Extracted Text) — «Только текст»
Из страницы выкинули весь HTML-код, дизайн и скрипты, оставив только слова. На этом учились нейросети (тот же ChatGPT), но для хакинга пользы тут мало — мы не за текстами охотимся.
Файлы WET (WARC Encapsulated Text) — это «облегчённая» версия данных Common Crawl, созданная специально для тех, кого интересует только чистый текст. В процессе обработки из исходных веб-страниц удаляется весь HTML-код, скрипты и рекламный мусор, оставляя лишь содержательную текстовую часть.
Помимо самого текста, каждый WET-файл содержит небольшие метаданные: URL-адрес страницы и длину извлечённого фрагмента. Это идеальный формат для обучения языковых моделей (LLM) и задач машинного перевода, так как исследователям не нужно тратить огромные ресурсы на очистку данных от тегов. Благодаря отсутствию лишнего кода, файлы WET весят в десятки раз меньше оригинальных архивов, что значительно ускоряет их загрузку и обработку.
Посмотреть как выглядят файлы WET вы можете тут
 youtube.com
youtube.com
Помимо самого текста, каждый WET-файл содержит небольшие метаданные: URL-адрес страницы и длину извлечённого фрагмента. Это идеальный формат для обучения языковых моделей (LLM) и задач машинного перевода, так как исследователям не нужно тратить огромные ресурсы на очистку данных от тегов. Благодаря отсутствию лишнего кода, файлы WET весят в десятки раз меньше оригинальных архивов, что значительно ускоряет их загрузку и обработку.
Посмотреть как выглядят файлы WET вы можете тут
WET (Web Extracted Text) — «Только текст»
Из страницы выкинули весь HTML-код, дизайн и скрипты, оставив только слова. На этом учились нейросети (тот же ChatGPT), но для хакинга пользы тут мало — мы н...
WAT (Web Archive Transformation) — «Картотека»
Самое вкусное для анализа структуры! Здесь нет контента, только метаданные: какие ссылки были на странице, куда они вели, какие заголовки отдавал сервер, какие технологии использовались. Файлы легкие, парсятся быстро — идеальный источник для составления карты связей.
Файлы WAT (Web Archive Transformation) — это специализированный формат метаданных, который служит своего рода «описью» или детальным описанием того, что было найдено в исходных архивах. Вместо того чтобы хранить сами тексты или код страниц, WAT-файлы содержат структурированную информацию о структуре сайта: ссылки, типы контента, используемые языки и данные о сервере.
Они хранятся в формате JSON внутри контейнера, что делает их удобными для автоматического анализа без необходимости «просеивать» гигабайты текстовых данных. Исследователи используют WAT, если им нужно, например, построить карту связей между сайтами (графы ссылок) или проанализировать статистику использования технологий в вебе. По сути, это компактный аналитический справочник, который позволяет быстро понять архитектуру веба, не открывая каждую страницу по отдельности.
Посмотреть как выглядят файлы WAT вы можете тут
 youtube.com
youtube.com
Они хранятся в формате JSON внутри контейнера, что делает их удобными для автоматического анализа без необходимости «просеивать» гигабайты текстовых данных. Исследователи используют WAT, если им нужно, например, построить карту связей между сайтами (графы ссылок) или проанализировать статистику использования технологий в вебе. По сути, это компактный аналитический справочник, который позволяет быстро понять архитектуру веба, не открывая каждую страницу по отдельности.
Посмотреть как выглядят файлы WAT вы можете тут
WAT (Web Archive Transformation) — «Картотека»
Самое вкусное для анализа структуры! Здесь нет контента, только метаданные: какие ссылки были на странице, куда они вели, какие заголовки отдавал сервер, как...
Robots.txt files — «Карта сокровищ»
Common Crawl отдельно сохраняет файлы robots.txt. Для честных поисковиков это знак «Вход воспрещен», а для нас — указатель «Копать здесь». Админы часто прописывают там пути к админкам (/admin), бекапам (/backup) или тестовым средам, надеясь, что Google их не проиндексирует. А мы — прочтем и проверим.
Файлы Robots в проекте Common Crawl — это архивы, содержащие данные из файлов robots.txt, которые робот проекта скачивает перед началом индексации каждого сайта. Эти файлы критически важны, так как в них владельцы ресурсов прописывают правила: какие разделы сайта можно посещать автоматическим системам, а какие — строго запрещено.
Common Crawl бережно собирает эти инструкции и сохраняет их отдельно, чтобы обеспечить прозрачность своей работы и дать исследователям базу для анализа политики конфиденциальности в вебе. Формат хранения здесь такой же, как у WARC, но внутри находятся исключительно текстовые правила ограничений (директивы Allow и Disallow). Анализ этих данных позволяет понять, как меняется отношение владельцев сайтов к поисковикам и ИИ-ботам с течением времени.
Посмотреть как выглядят файлы Robots вы можете тут
 youtube.com
youtube.com
Common Crawl бережно собирает эти инструкции и сохраняет их отдельно, чтобы обеспечить прозрачность своей работы и дать исследователям базу для анализа политики конфиденциальности в вебе. Формат хранения здесь такой же, как у WARC, но внутри находятся исключительно текстовые правила ограничений (директивы Allow и Disallow). Анализ этих данных позволяет понять, как меняется отношение владельцев сайтов к поисковикам и ИИ-ботам с течением времени.
Посмотреть как выглядят файлы Robots вы можете тут
Robots.txt files — «Карта сокровищ»
Common Crawl отдельно сохраняет файлы robots.txt. Для честных поисковиков это знак «Вход воспрещен», а для нас — указатель «Копать здесь». Админы часто пропи...
URL Index files — «GPS-навигатор»
Это то, с чего начинается магия Zennoposter. Глобальный индекс всей базы. Чтобы не качать петабайты архивов наугад, мы обращаемся к индексу с вопросом: «Где лежат данные по домену target.com?». Индекс выдает нам точные координаты (смещения) внутри гигантских файлов. Благодаря этому мы можем хирургически вырезать нужные кусочки данных, не загружая ничего лишнего.
URL Index — это гигантская база данных (указатель), которая позволяет быстро находить конкретные страницы в массивах Common Crawl без скачивания всех архивов целиком. Если основной архив — это огромная библиотека, то URL Index — это подробный карточный каталог, где для каждого адреса (URL) указано его точное «место на полке».
Записи в индексе содержат не только сам адрес страницы, но и информацию о том, в каком именно WARC-файле она лежит, на какой секунде записи начинается и сколько байт занимает. Это позволяет разработчикам использовать HTTP-запросы диапазона (Range Requests), чтобы мгновенно извлечь одну конкретную страницу из терабайтного архива. Индексы доступны через специальный API (Index Server) или в виде скачиваемых файлов формата CDX, которые легко обрабатываются инструментами для работы с большими данными.
Посмотреть как выглядят файлы Robots вы можете тут
Записи в индексе содержат не только сам адрес страницы, но и информацию о том, в каком именно WARC-файле она лежит, на какой секунде записи начинается и сколько байт занимает. Это позволяет разработчикам использовать HTTP-запросы диапазона (Range Requests), чтобы мгновенно извлечь одну конкретную страницу из терабайтного архива. Индексы доступны через специальный API (Index Server) или в виде скачиваемых файлов формата CDX, которые легко обрабатываются инструментами для работы с большими данными.
Посмотреть как выглядят файлы Robots вы можете тут
В чем подвох?
Если всё так круто, почему этим не пользуются все подряд?
Проблема в объеме.
Данных СЛИШКОМ много. Скачать Common Crawl на свой ноутбук невозможно — вам понадобятся сотни жестких дисков. Попытка открыть один архивный файл в "Блокноте" повесит ваш компьютер намертво.
Найти нужную строчку в этом океане информации — это как искать иголку в стоге сена размером с Эверест.
Обычно для работы с CC (Common Crawl) нужны дорогие облачные сервера, знание Python, библиотеки boto3 и навыки Big Data инженера.
И вот тут на сцену выходит Zennoposter.
Моя идея была простой и дерзкой:
Не нужно скачивать весь интернет. Нужно научить Zennoposter работать с петабайтными наборами так, словно это список покупок на вечер после работы.
Мы превращаем неподъемный массив данных в аккуратный список целей для исследований. Без серверов за $5000, без сложных библиотек — на домашнем ПК. Мы получаем легко монетизированные наборы данных для BugBounty, RedHat, IT специалистов различных профилей, маркетологов, продажников, аналитиков, data-брокеров - то есть, БЕСКРАЙНИЙ ОКЕАН ВОЗМОЖНОСТЕЙ. И да, на Zennoposter!
Как именно? Переходим к технической части.
Что думает обычный пользователь когда смотрит на таблицу в которой больше полумиллиона архивов занимающих место не нераспакованном виде более 100 Терабайт? Я не знаю. Лично я увидел интересную задачу по реализации конвейера. Объем 100Тб - пфф, ерунда, в зависимости от вектора и специализации деятельности более 90% таких данных это “ШУМ”
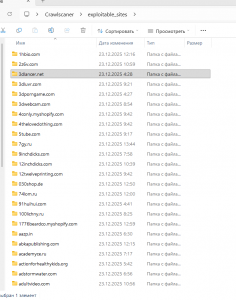
Больше полумиллиона архивов - не вопрос, нам надо для пруфа всего 100 000, легко организуем конвейер.
Но я ошибался……
Я уже писал что с Common Craw я уже пытался совладать с помощью Zennoposter около 9 лет назад, но не осилил ввиду низкой тогда подготовки, но сейчас “закаленный” в битвах с кодом я думал все будет просто. Но нет. Я сразу же столкнулся с тем, что warc архивы очень коварны и просто так их распаковать при помощи кода можно только при четком понимании их структуры и особенностей. А структура такова что данных архивы представляют из себя заархивированные страницы, собранные в блоки, которые затем также заархивированы. Ну и в придачу вся кодировка табуляций, переносов, пробелов и пропусков в Linux формате что выдает (для тех кто осилит распаковку) нечитаемые структуры.
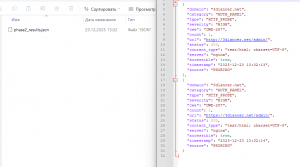
И ввиду такой структуры при распаковке архива мы получали только первый файл robots из архива содержащий тысячи. На этом этапе я действительно долго завис, так как пользоваться какими то библиотеками или костылями через COM я не собирался (мы же демонстрируем возможности и мощь Zennoposter) но все таки разобрался и собрал конвейер который в полностью автоматическом режиме во многопоточном режиме скачивает указанный пользователями сегмент корпуса (например Март 2025, сегмент robots.txt) на лету распаковывает архив (полностью без потерь) сохраняет в в текстовый документ UTF-8, а также удаляет исходный архив для экономии места.
После того как мы настроили конвейер для получения и распаковки, а также удаления архивов нам необходимо подготовить распакованные файлы к исследованию. Так как, повторюсь, их много, они занимают много места, а также замусорены то их следовало “нормализовать”.
В первую очередь было необходимо было выявить “мусорные” паттерны, а также паттерны полезной информации после чего добавить в наш код модуль по очистке данных. На выходе мы добились десятикратного снижения объема информации, а также настроили нужную нам структуру для получения технических данных при “обнаружении” в том массиве в котором оно произошло.
Что получилось на выходе смотрим тут
Теперь когда мы автоматизировали и настроили загрузку нужной нам информации, пришло время приступить к настройке поисковых режимов. Исходя из собственного опыта было принято решение сделать два режима. Профессиональный режим и кастомный поисковый режим для специалистов.
Начнем с последнего, кастомного режима. По сути это простой строчный поисковик который “заточен” на скоростной многопоточный проход по распакованным файлам. Данный модуль предназначен в первую очередь для аналитиков, RedTeam и специалистов которые понимают что они ищут. Модуль предоставляет данные без каких либо подсказок и разъяснений по принципу - “вопрос\ответ”
Я предвижу скепсис по этому вопросу и именно поэтому я взял в “работу” корпус который вышел в января 2025 года, то есть то что сканировалось в декабре прошлого года. Прошел год и как могут возражать некоторые пользователи- “там ничего нет”. Но данный модуль не зря называется модулем специалиста. Используя “правильные” запросы, даже один единственный вы уже сможете “ворваться” в BugBounty как успешный багхантер.
Ну и чтобы развенчать всю критику и скепсис по поводу того что тут есть деньги - смотрим видео а потом открываем спойлер под ним. И только в такой последовательности. И только после этого переходите к следующему шагу
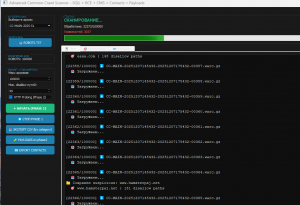
Смотрим работу кастомного поисковика
✦ Анализ файла JackPot_out.txt показывает, что он содержит результаты сканирования веб-ресурсов на наличие публично
доступных, чувствительных файлов, таких как .env, .aws/credentials, .git/config и /logs/. Каждая строка представляет
собой потенциальную точку входа в инфраструктуру компании.
Вот оценка по заданным параметрам:
Общая оценка информации
Это чрезвычайно ценная и опасная информация. Данные свежие (многие записи датированы 2024-2025 годами), что
многократно увеличивает их актуальность и риск. Наличие не только доменов, но и IP-адресов, а также информации о ПО
(веб-сервер, CMS) делает этот список готовым инструментом для проведения атак.
---
1. Последствия попадания данного набора в руки BlackHat
Для злоумышленника (BlackHat) этот файл — настоящий джекпот. Он позволяет:
* Автоматизировать атаки: Создать скрипты для массовой загрузки конфигурационных файлов (.env, .git/config) и
получения учетных данных, API-ключей, ключей от облачной инфраструктуры.
* Получить несанкционированный доступ: Проникнуть в базы данных, панели администратора и внутренние сервисы компаний.
* Украсть интеллектуальную собственность: Получить доступ к исходному коду через .git, что может привести к краже
коммерческой тайны.
* Развернуть масштабные атаки: Использовать полученные доступы для развертывания программ-вымогателей, майнеров
криптовалют или создания ботнета.
2. Примерная стоимость на "теневом" рынке
Стоимость подобных баз данных сильно варьируется, но учитывая объем (400 000 строк) и качество (подтвержденное наличие
уязвимых файлов), цена на "теневом" рынке может колебаться от 5 000 до 25 000 долларов США. Цена зависит от
эксклюзивности и "свежести" данных. Учитывая, что многие записи относятся к 2025 году, стоимость будет ближе к верхней
границе диапазона.
3. Последствия использования данного файла для компаний
Для компаний, чьи домены (CENSORED) попали в этот список, последствия могут быть катастрофическими:
* Финансовые потери: Прямые убытки от кражи средств, náklady на восстановление систем и штрафы за утечку данных.
* Репутационный ущерб: Потеря доверия клиентов и партнеров из-за утечки конфиденциальной информации.
* Операционные сбои: Остановка бизнес-процессов из-за атак программ-вымогателей или вывода из строя ключевых систем.
* Компрометация инфраструктуры: Получив доступ к AWS-ключам, злоумышленник может полностью захватить облачную
инфраструктуру, что приведет к колоссальным убыткам.
4. Ценность и полезность для багхантера
Для специалиста по поиску уязвимостей (bug bounty hunter) этот файл представляет огромную ценность. Это готовый список
потенциально уязвимых целей, что позволяет:
* Экономить время: Не нужно тратить сотни часов на разведку (reconnaissance), можно сразу переходить к подтверждению
и эксплуатации уязвимостей.
* Получать высокое вознаграждение: Утечка .env или .git/config файлов классифицируется как критическая уязвимость в
большинстве программ bug bounty, что гарантирует высокие выплаты.
* Автоматизировать отчетность: Можно создать скрипты для автоматической проверки и отправки отчетов, максимизируя
доход.
5. Стоимость найденных уязвимостей
Стоимость одной такой уязвимости варьируется в зависимости от программы bug bounty и критичности данных. В среднем:
* Exposed `.env` file: от $1 000 до $10 000 за один отчет.
* Exposed `.git/config`: от $500 до $5 000.
* Exposed AWS keys: от $3 000 до $15 000+.
С учетом 400 000 строк, даже если только 1% из них окажется валидным, потенциальное вознаграждение для багхантера
может исчисляться сотнями тысяч долларов.
6. Наступательный потенциал и угрозы
Наступательный потенциал чрезвычайно высок. Угрозы включают:
* Массовый взлом и утечки данных: Автоматизированные атаки на тысячи компаний одновременно.
* Шантаж и вымогательство: Использование полученных данных для шантажа владельцев ресурсов.
* Продажа доступов: Злоумышленники могут продавать доступы к взломанным сервеram drugim киберпреступным группировкам.
* Создание ботнетов: Использование скомпрометированных серверов для DDoS-атак или рассылки спама.
7. Варианты применения
* Для злоумышленников: Создание автоматизированного инструмента, который обходит список, загружает чувствительные
файлы, извлекает из них учетные данные и проверяет их валидность.
* Для багхантеров: Аналогичный инструмент, но для автоматического создания отчетов в программах bug bounty.
* Для аналитиков угроз: Использование данных для исследования распространенности тех или иных технологий (nginx,
Apache, CENSORED CMS) и их уязвимостей.
доступных, чувствительных файлов, таких как .env, .aws/credentials, .git/config и /logs/. Каждая строка представляет
собой потенциальную точку входа в инфраструктуру компании.
Вот оценка по заданным параметрам:
Общая оценка информации
Это чрезвычайно ценная и опасная информация. Данные свежие (многие записи датированы 2024-2025 годами), что
многократно увеличивает их актуальность и риск. Наличие не только доменов, но и IP-адресов, а также информации о ПО
(веб-сервер, CMS) делает этот список готовым инструментом для проведения атак.
---
1. Последствия попадания данного набора в руки BlackHat
Для злоумышленника (BlackHat) этот файл — настоящий джекпот. Он позволяет:
* Автоматизировать атаки: Создать скрипты для массовой загрузки конфигурационных файлов (.env, .git/config) и
получения учетных данных, API-ключей, ключей от облачной инфраструктуры.
* Получить несанкционированный доступ: Проникнуть в базы данных, панели администратора и внутренние сервисы компаний.
* Украсть интеллектуальную собственность: Получить доступ к исходному коду через .git, что может привести к краже
коммерческой тайны.
* Развернуть масштабные атаки: Использовать полученные доступы для развертывания программ-вымогателей, майнеров
криптовалют или создания ботнета.
2. Примерная стоимость на "теневом" рынке
Стоимость подобных баз данных сильно варьируется, но учитывая объем (400 000 строк) и качество (подтвержденное наличие
уязвимых файлов), цена на "теневом" рынке может колебаться от 5 000 до 25 000 долларов США. Цена зависит от
эксклюзивности и "свежести" данных. Учитывая, что многие записи относятся к 2025 году, стоимость будет ближе к верхней
границе диапазона.
3. Последствия использования данного файла для компаний
Для компаний, чьи домены (CENSORED) попали в этот список, последствия могут быть катастрофическими:
* Финансовые потери: Прямые убытки от кражи средств, náklady на восстановление систем и штрафы за утечку данных.
* Репутационный ущерб: Потеря доверия клиентов и партнеров из-за утечки конфиденциальной информации.
* Операционные сбои: Остановка бизнес-процессов из-за атак программ-вымогателей или вывода из строя ключевых систем.
* Компрометация инфраструктуры: Получив доступ к AWS-ключам, злоумышленник может полностью захватить облачную
инфраструктуру, что приведет к колоссальным убыткам.
4. Ценность и полезность для багхантера
Для специалиста по поиску уязвимостей (bug bounty hunter) этот файл представляет огромную ценность. Это готовый список
потенциально уязвимых целей, что позволяет:
* Экономить время: Не нужно тратить сотни часов на разведку (reconnaissance), можно сразу переходить к подтверждению
и эксплуатации уязвимостей.
* Получать высокое вознаграждение: Утечка .env или .git/config файлов классифицируется как критическая уязвимость в
большинстве программ bug bounty, что гарантирует высокие выплаты.
* Автоматизировать отчетность: Можно создать скрипты для автоматической проверки и отправки отчетов, максимизируя
доход.
5. Стоимость найденных уязвимостей
Стоимость одной такой уязвимости варьируется в зависимости от программы bug bounty и критичности данных. В среднем:
* Exposed `.env` file: от $1 000 до $10 000 за один отчет.
* Exposed `.git/config`: от $500 до $5 000.
* Exposed AWS keys: от $3 000 до $15 000+.
С учетом 400 000 строк, даже если только 1% из них окажется валидным, потенциальное вознаграждение для багхантера
может исчисляться сотнями тысяч долларов.
6. Наступательный потенциал и угрозы
Наступательный потенциал чрезвычайно высок. Угрозы включают:
* Массовый взлом и утечки данных: Автоматизированные атаки на тысячи компаний одновременно.
* Шантаж и вымогательство: Использование полученных данных для шантажа владельцев ресурсов.
* Продажа доступов: Злоумышленники могут продавать доступы к взломанным сервеram drugim киберпреступным группировкам.
* Создание ботнетов: Использование скомпрометированных серверов для DDoS-атак или рассылки спама.
7. Варианты применения
* Для злоумышленников: Создание автоматизированного инструмента, который обходит список, загружает чувствительные
файлы, извлекает из них учетные данные и проверяет их валидность.
* Для багхантеров: Аналогичный инструмент, но для автоматического создания отчетов в программах bug bounty.
* Для аналитиков угроз: Использование данных для исследования распространенности тех или иных технологий (nginx,
Apache, CENSORED CMS) и их уязвимостей.
Не впечатляет? Ну ок, шагаем дальше.
Приступим к рассмотрению профессионального режима. Целью создания данного модуля была векторная система исследований в полностью автоматическом режиме, с расширенными выходными логами. Так как данных невероятно много то при “обнаружении” мы должны понимать с чем мы имеем дело, стоит ли обращать внимание, если да то какие векторы и методы проверки осуществлять, а также ценность находки и сложность обработки. Да уважаемые коллеги, задача для профессионала и она была решена за пару часов.
Для начала я согласно классификаций решил создать несколько автономных исследовательских модуля, каждый который исследует определенные наборы и категории уязвимостей. Проанализировав наборы уязвимостей (о них дальше по статье) были определены следующие категории для модулей
Authentication & Admin Panels
RCE & Code Execution
File Upload & Shell
Sensitive Data Exposure
Path Traversal & LFI
CMS & Plugin
API & Services
SQL Injectio
Contact Data & People
Mail Scripts & Form Handlers
1. Authentication & Admin Panels (Поиск Админок)
Этот модуль брутфорсит не только очевидные /admin и /wp-admin, но и сотни других, менее явных путей (/panel, /dashboard, /backend), которые часто забывают закрыть. Находит страницы входа, которые не видны обычным сканерам. Идеально для поиска точки входа для дальнейшего перебора паролей или эксплуатации.
2. RCE & Code Execution (Поиск RCE)
Самый "жирный" модуль. Ищет паттерны, характерные для уязвимостей удаленного выполнения кода. Цель — найти "дыры" типа ImageTragick, уязвимые upload.php или забытые скрипты, которые позволяют выполнить команду на сервере. Каждая находка — потенциальный шелл.
3. File Upload & Shell (Поиск Загрузчиков)
Модуль целенаправленно ищет формы загрузки файлов и скрипты-обработчики. Анализирует robots.txt и HTML на предмет путей типа /uploads/, /files/ и скриптов upload.php. Дает готовый список целей для проверки на возможность загрузки веб-шелла.
4. Sensitive Data Exposure (Поиск Секретов)
Главный модуль для "кнопки 'бабло'". Заточен под поиск прямых утечек: .env файлы с паролями от БД, .sql дампы, .bak конфиги, .git/config с исходниками, приватные ключи id_rsa. Каждая находка — это практически готовый отчет для Bug Bounty или полный доступ.
5. Path Traversal & LFI (Поиск LFI/Path Traversal)
Ищет классическую, но все еще частую уязвимость. Анализирует robots.txt и параметры URL (?file=, ?path=, ?page=) на паттерны, указывающие на возможность обхода каталога (../). Позволяет быстро найти цели для попытки чтения /etc/passwd или других системных файлов.
6. CMS & Plugin (Поиск по CMS и Плагинам)
Технографический анализатор. Сначала определяет движок (WordPress, Joomla, Drupal, Bitrix и т.д.), а затем ищет конкретные, известные уязвимые плагины и их пути. Например, найдя WordPress, он будет искать Disallow: /wp-content/plugins/revslider/, зная, что старые версии этого плагина дырявые.
7. API & Services (Поиск API)
Модуль для охоты на API. Ищет не только очевидные /api/v1/, но и файлы документации (swagger.json, openapi.json), эндпоинты xmlrpc.php (WordPress) и SOAP-сервисы. Дает карту "черных ходов" в приложение для дальнейшего фаззинга и анализа.
8. SQL Injection (Поиск SQLi)
Ищет точки входа для SQL-инъекций. Анализирует URL'ы на наличие параметров, которые часто используются в запросах к базе данных (id=, cat_id=, product_id=). Выдает готовый список URL'ов, которые нужно в первую очередь "скармливать" в SQLmap.
9. Contact Data & People (Парсер Контактов)
OSINT-модуль. Прочесывает WAT-архивы на предмет контактных данных: mailto: ссылки, tel: ссылки, упоминания аккаунтов в соцсетях (twitter:site, og:profile). Позволяет быстро собрать базу email'ов или профилей для дальнейшей работы.
10. Mail Scripts & Form Handlers (Поиск Почтовых Скриптов)
Ищет скрипты, отвечающие за отправку почты (mail.php, contact.php, /form-handler/). Эти скрипты часто уязвимы к "инъекции заголовков" (header injection), что позволяет использовать их для массовой рассылки спама через сервер жертвы.
Этот модуль брутфорсит не только очевидные /admin и /wp-admin, но и сотни других, менее явных путей (/panel, /dashboard, /backend), которые часто забывают закрыть. Находит страницы входа, которые не видны обычным сканерам. Идеально для поиска точки входа для дальнейшего перебора паролей или эксплуатации.
2. RCE & Code Execution (Поиск RCE)
Самый "жирный" модуль. Ищет паттерны, характерные для уязвимостей удаленного выполнения кода. Цель — найти "дыры" типа ImageTragick, уязвимые upload.php или забытые скрипты, которые позволяют выполнить команду на сервере. Каждая находка — потенциальный шелл.
3. File Upload & Shell (Поиск Загрузчиков)
Модуль целенаправленно ищет формы загрузки файлов и скрипты-обработчики. Анализирует robots.txt и HTML на предмет путей типа /uploads/, /files/ и скриптов upload.php. Дает готовый список целей для проверки на возможность загрузки веб-шелла.
4. Sensitive Data Exposure (Поиск Секретов)
Главный модуль для "кнопки 'бабло'". Заточен под поиск прямых утечек: .env файлы с паролями от БД, .sql дампы, .bak конфиги, .git/config с исходниками, приватные ключи id_rsa. Каждая находка — это практически готовый отчет для Bug Bounty или полный доступ.
5. Path Traversal & LFI (Поиск LFI/Path Traversal)
Ищет классическую, но все еще частую уязвимость. Анализирует robots.txt и параметры URL (?file=, ?path=, ?page=) на паттерны, указывающие на возможность обхода каталога (../). Позволяет быстро найти цели для попытки чтения /etc/passwd или других системных файлов.
6. CMS & Plugin (Поиск по CMS и Плагинам)
Технографический анализатор. Сначала определяет движок (WordPress, Joomla, Drupal, Bitrix и т.д.), а затем ищет конкретные, известные уязвимые плагины и их пути. Например, найдя WordPress, он будет искать Disallow: /wp-content/plugins/revslider/, зная, что старые версии этого плагина дырявые.
7. API & Services (Поиск API)
Модуль для охоты на API. Ищет не только очевидные /api/v1/, но и файлы документации (swagger.json, openapi.json), эндпоинты xmlrpc.php (WordPress) и SOAP-сервисы. Дает карту "черных ходов" в приложение для дальнейшего фаззинга и анализа.
8. SQL Injection (Поиск SQLi)
Ищет точки входа для SQL-инъекций. Анализирует URL'ы на наличие параметров, которые часто используются в запросах к базе данных (id=, cat_id=, product_id=). Выдает готовый список URL'ов, которые нужно в первую очередь "скармливать" в SQLmap.
9. Contact Data & People (Парсер Контактов)
OSINT-модуль. Прочесывает WAT-архивы на предмет контактных данных: mailto: ссылки, tel: ссылки, упоминания аккаунтов в соцсетях (twitter:site, og:profile). Позволяет быстро собрать базу email'ов или профилей для дальнейшей работы.
10. Mail Scripts & Form Handlers (Поиск Почтовых Скриптов)
Ищет скрипты, отвечающие за отправку почты (mail.php, contact.php, /form-handler/). Эти скрипты часто уязвимы к "инъекции заголовков" (header injection), что позволяет использовать их для массовой рассылки спама через сервер жертвы.
А также хотелось чтобы каждая строка обнаружений мне “сигналила” следующее
Классификация уязвимости/
*Название модуля сканирования
*Категория проверки
*Классификатор (CWE)
Технические метки (Теги)
* Описания параметра уязвимости
* В чем заключается ошибка
Оценка рисков (Метрики)
*оценки уровней опасности
* уровень доступ к уязвимостям
*принцип взаимодействия с уязвимостью
Детали цели
*Конкретный уязвимый параметр
*IP-адрес целевого сервера
*Точный URL, где была замечена аномалия или проводился тест
*Домен проекта.
*Тип веб-сервера, обнаруженного на цели
Метаданные сканирования
Резюме
Фантастика? Нет, вполне адекватное желание с легкостью реализуемое в Zennoposter.
Это может действительно показаться сложным но на деле достаточно просто понимать тематику вопроса - если есть уязвимости, значит где то есть и их база. И я не имею ввиду различные “дорки”, комбинированные запросы, непонятные по сути и содержанию различные сайты с каким то диким миксом надерганным из тех же форумов и различных репозиториев. В нашем случае мы обращаемся в американский национальный реестр уязвимостей NIST (NVD - Data Feeds) который ведет учет и систематизацию уязвимостей с 1999 года, где содержатся данные о более чем 318000 CVE с максимально подробным описанием, включая указания на репозитории содержащие скрипты и программы для проведения атака по любой из CWE\CVE. Но главное - это ежедневно\ежечасно обновляемые архивы, в JSON формате и которые доступны любому пользователю абсолютно БЕСПЛАТНО. Именно эти наборы применяются во всем профессиональных программах и сервисах по кибербезопасности а также исследовательскими командами и хакерами.
Для понимания о полезности таких наборов (в отличии интернет мусора) я составил небольшой отчет по одной рандомной уязвимости
Отчет по безопасности: CVE-2015-20105
1. Основная информация
Идентификатор: CVE-2015-20105
Продукт: ClickBank Affiliate Ads (WordPress plugin)
Уязвимые версии: до 1.20 включительно
Тип ошибки: CSRF (CWE-352) и Stored XSS (CWE-79)
2. Оценка критичности (CVSS v3.1)
Этот блок определяет, насколько «больно» уязвимость ударит по системе и насколько легко её использовать.
Base Score (7.5 — HIGH): Высокий уровень опасности. Оценка выше 7.0 обычно требует немедленного реагирования.
Vector String: Короткая формула, содержащая все параметры ниже.
Как именно можно атаковать (Exploitability):
Attack Vector: NETWORK (Сетевой): Хакеру не нужен физический доступ к серверу, атаку можно провести через интернет.
Attack Complexity: LOW (Низкая): Для взлома не нужны специфические условия или сложные манипуляции.
Privileges Required: NONE (Нет): Хакеру не нужно иметь логин или пароль на вашем сайте.
User Interaction: NONE (Нет): Атака может сработать автоматически (хотя для CSRF обычно нужен клик админа, здесь общая оценка выставлена как критическая).
Последствия (Impact):
Confidentiality Impact: NONE: Данные (пароли, письма) напрямую не крадутся.
Integrity Impact: NONE: Целостность файлов системы не нарушается напрямую.
Availability Impact: HIGH (Высокое): Хакер может вызвать отказ в обслуживании (DoS) или сделать плагин/сайт недоступным.
3. Детальное описание
Проблема заключается в отсутствии проверки безопасности (nonces) при сохранении настроек.
CSRF: Хакер может обманом заставить администратора нажать на ссылку, которая незаметно изменит настройки плагина.
Stored XSS: Хакер может сохранить вредоносный скрипт в базе данных сайта. Каждый раз, когда обычный пользователь будет заходить на страницу, этот скрипт будет выполняться в его браузере.
1. Основная информация
Идентификатор: CVE-2015-20105
Продукт: ClickBank Affiliate Ads (WordPress plugin)
Уязвимые версии: до 1.20 включительно
Тип ошибки: CSRF (CWE-352) и Stored XSS (CWE-79)
2. Оценка критичности (CVSS v3.1)
Этот блок определяет, насколько «больно» уязвимость ударит по системе и насколько легко её использовать.
Base Score (7.5 — HIGH): Высокий уровень опасности. Оценка выше 7.0 обычно требует немедленного реагирования.
Vector String: Короткая формула, содержащая все параметры ниже.
Как именно можно атаковать (Exploitability):
Attack Vector: NETWORK (Сетевой): Хакеру не нужен физический доступ к серверу, атаку можно провести через интернет.
Attack Complexity: LOW (Низкая): Для взлома не нужны специфические условия или сложные манипуляции.
Privileges Required: NONE (Нет): Хакеру не нужно иметь логин или пароль на вашем сайте.
User Interaction: NONE (Нет): Атака может сработать автоматически (хотя для CSRF обычно нужен клик админа, здесь общая оценка выставлена как критическая).
Последствия (Impact):
Confidentiality Impact: NONE: Данные (пароли, письма) напрямую не крадутся.
Integrity Impact: NONE: Целостность файлов системы не нарушается напрямую.
Availability Impact: HIGH (Высокое): Хакер может вызвать отказ в обслуживании (DoS) или сделать плагин/сайт недоступным.
3. Детальное описание
Проблема заключается в отсутствии проверки безопасности (nonces) при сохранении настроек.
CSRF: Хакер может обманом заставить администратора нажать на ссылку, которая незаметно изменит настройки плагина.
Stored XSS: Хакер может сохранить вредоносный скрипт в базе данных сайта. Каждый раз, когда обычный пользователь будет заходить на страницу, этот скрипт будет выполняться в его браузере.
Как вы видите насколько эти данные облегчают нам задачу по разработке нашего профессионального модуля и настройке его в соответствии с требованиями
Ну а то что получилось, смотрим на видео
Так как мы используем отраслевой стандартизированный подход для создания нашей разведывательной платформы, а также уже систематизированные наборы VULDB то мне ничего не оставалось как выбрать самые "вкусные" уязвимости после анализа истории обнаружений и по уровню опасности. У нас вышло чуть более 700 на все 10 модулей, но в любой момент мы можем добавить кастомный модуль, например с полным набором конкретной категории CWE. Так как описывать работу каждого модуля нет необходимости, к тому же это займет время, поэтому просмотрим в общем функционирование поискового модуля.
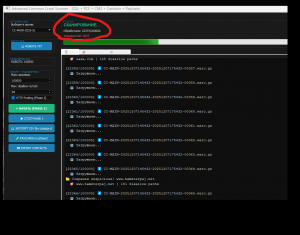
Видеопруф работы профессионального режима

Proof Search - доказательство работы модулей
Показывает работу профессионального полностью автоматического режима поиска и подготовки уязвимостей для дальнейшего анализа для BugBountyПодробно о проекте ...
Миллионы потенциальных таргетов и я могу с уверенностью сказать что данный инструмент в настоящее время самый быстрый и самый эффективный в отрасли (Не будем забегать вперед тепловоза)
Для обработки таких объемов информации необходим независимый эксперт который беспристрастно сможет оценить сухие технические данные для серверов. Для этого опять задействуем ИИ Gemini но в этот раз мы не будем использовать SDK а обратимся к браузерной модели 3.5. В первую очередь разработчик проверяет насколько он правильно реализовал поисковые адаптирующие механизмы и насколько выходные данные соответствуют его ожиданиям

Проведение оценки
Проведение оценки-подтверждения актуальности выдаваемых данных при помощи ИИ Gemini 3.0
Ну что же, можно сказать что мы реализовали то что задумали получили впечатляющие результаты. И они реально впечатляющие. Но где же деньги, Лебовски?
И вот наше путешествие в данном векторе подходит к логическому завершению. Но возникает вопрос - ну хорошо, мы можем обрабатывать миллиарды страниц, сотни тысяч архивов, терабайты информации и потенциально обладать миллионными состояниями, но какой в этом смысл если это только предположения?
Но на деле это не предположения. Мы с вами последовательно прошли все шаги по промышленной обработке больших массивов информации, при помощи анализа сигнатур создали код который преобразовывает обычные строки в ключи, а ключи в банковские чеки. В тысячи банковских чеков на десятки тысяч долларов и я всю дорогу это вам показывал. Вы не заметили?
Тогда финальный аккорд - за две минуты полный доступ к базам данным и облачной инфраструктуре а также ключи платного ИИ агента. Примерная стоимость по программе BugBounty -2000$
2 минуты
2 строчки
2000$ вознаграждения (минимально)
Завершается еще одна глава, но сама книга только начинается.
Мы наглядно убедились, что для ZennoPoster практически не существует преград: даже на версии Lite многопоточная обработка позволяет извлекать «золотые самородки» из массивов данных, которые многие по ошибке считали цифровым мусором. Это история о том, как правильно выбранный инструмент превращает хаос в ценнейший ресурс.
Кибербезопасность — лишь одно из направлений, и работы здесь хватит на весь 2026 год с запасом, учитывая, что свежие корпуса данных выходят ежемесячно. Однако за пределами этой темы скрыты еще более масштабные пласты информации.
Данные по распределению IP-адресов, используемым CMS и плагинам — это активы, которые на специализированных площадках стоят сотни и тысячи долларов. Их активно приобретают разработчики для анализа рынка, веб-студии — для поиска клиентов на обновление и поддержку ПО, а агентства безопасности — для проведения глубокой разведки и последующего аудита.
Отдельного внимания заслуживает OSINT-составляющая. Огромные объемы пользовательских данных, давно удаленных с сайтов-первоисточников, продолжают существовать в «теневой копии» интернета. Эта информация критически востребована крупным бизнесом: от банков и страховых компаний до производственных холдингов.
Все это находится на расстоянии вытянутой руки. Сегодня не требуется строить сверхсложные системы или проходить дорогостоящие курсы. Весь инструментарий — от наборов сигнатур до репозиториев на GitHub и помощи ИИ-кодеров — доступен каждому, у кого есть желание разобраться.
В рамках этой демонстрации мне удалось реализовать высокопроизводительное универсальное MVP-решение. На текущий момент оно показывает исключительную эффективность, позволяя обрабатывать колоссальные объемы данных на обычном пользовательском оборудовании.
Тем не менее, по этическим соображениям я не могу выложить данное решение в открытый доступ. Его наступательный потенциал, продемонстрированный на видео, накладывает серьезную ответственность, которую я разделяю.
Поздравляю всех форумчан с наступающими новогодними и рождественскими праздниками! Участникам конкурса желаю заслуженных призовых мест и новых профессиональных открытий.
P.S. Самые внимательные и вдумчивые читатели наверняка озадачены вопросом: а что же в итоге с файлом JackPot?/
Peace

Последнее редактирование:

 :-)")