

- Регистрация
- 19.02.2015
- Сообщения
- 244
- Благодарностей
- 172
- Баллы
- 43
Замучился с случайным переходом по сайту нужна помощь !
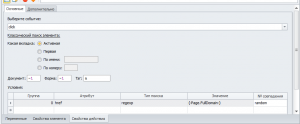
Задача сделать 3 разных случайных перехода по сайту, сайты всегда почти разные.
На разность переходов сделал проверку по URL что бы не было одинаковых переходов, но вот переходы по сайту стабильно не работают, то в картинку попадают или раскрытие меню, то в рекламу тогда вообще открывается новая вкладка но вкладку поборол закрытием вкладки и возвратом на переход опять, хотя вроде сделал переход по {-Page.FullDomain-} имени по чему так и не пойму пока. Вот мой блок клик.

В общем надо 3 перехода разных внутри сайта, желательно с первого раза, сайты все разные.
Или как вариант, как можно узнать адреса всех страниц сайта допустим ?
Задача сделать 3 разных случайных перехода по сайту, сайты всегда почти разные.
На разность переходов сделал проверку по URL что бы не было одинаковых переходов, но вот переходы по сайту стабильно не работают, то в картинку попадают или раскрытие меню, то в рекламу тогда вообще открывается новая вкладка но вкладку поборол закрытием вкладки и возвратом на переход опять, хотя вроде сделал переход по {-Page.FullDomain-} имени по чему так и не пойму пока. Вот мой блок клик.
В общем надо 3 перехода разных внутри сайта, желательно с первого раза, сайты все разные.
Или как вариант, как можно узнать адреса всех страниц сайта допустим ?
Последнее редактирование: