


- Регистрация
- 04.11.2010
- Сообщения
- 2 382
- Благодарностей
- 917
- Баллы
- 113
Эта статья техническая. В ней разобраны самые основы.
Понимание основ и умение их применять позволит Вам решать большинство задач.
Самые основы не требуют глубокого изучения, а требуют просто ознакомления и понимания.
Огромное количество вопросов на форуме из-за того, что люди не понимают самых основ, отсутствуют умения их грамотно группировать, из-за этого куча всяких деревянных решений. Люди пишут кривые, чудом работающие шабы, и часто долбятся днями в элементарные участки.
А задачи решаются элегантно одним шагом на самом деле, а не пятью.
И часто из-за непонимания основ у людей не хватает понимания, как правильно задать вопрос. А как мы знаем, каков вопрос, таков и ответ.
Эта статья поможет Вам во всем этом!
Текста много, но все просто, если вчитаться.
Если обобщить, то работа шаблонов зенно постера состоит из двух видов операций:
1. Логических
2. Работы с элементами на странице.
В данной статье пойдет разговор про понимание и умение применять самые основы работы с элементами.
Приступим.
Любой элемент на странице это тег.
Тег - элемент разметки гипертекста.
Проще говоря весь html код с которым зенно проводит манипуляции держится на тегах.
Wiki: https://ru.wikipedia.org/wiki/Тег_(языки_разметки)
Основы HTML: http://www.postroika.ru/html/content2.html
Уделите пол часика и просто прочитайте уроки. Начнете понимать, как и что между собой на странице взаимодействует.
Примеры тегов: <a>,<p>,<html>,<form>,<input>
У большинства тегов есть закрывающие части, т.е. </a>, </p>,</html>
т.е. например - <b>тут жирный текст</b>
Прочитайте уроки html и все станет понятно. Глубокое изучение тут не нужно, хватит внимательного ознакомления.
При любой работе с элементом мы взаимодействуем с ним следующим образом:
1. Где этот тег
2. Что это за тег
3. Какие у него уникальные признаки
4. Что мы делаем
Действие с элементом бывают 3х типов:
Set - присваиваем атрибуту элемента того или иного значения. (разберем ниже)
Get - получаем значение того или иного атрибута. (разберем ниже)
Rise - устанавливаем события взаимодействия с элементом. (фокусируемся на элементе, кликаем по элементу и т.д.)
Для работы, когда записи действий недостаточно, нам поможет:
В режиме записи и отладки:
-Окна -> Свойства действия, если уже записано
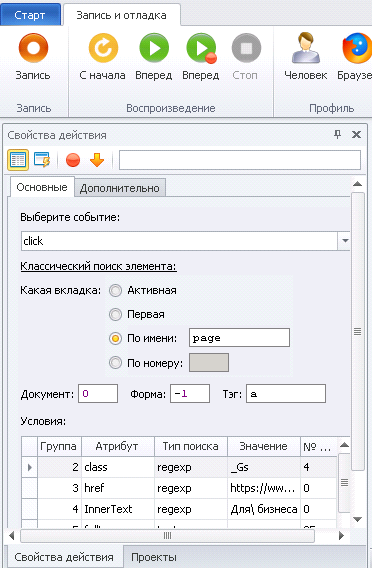
-Окна -> Свойства элемента
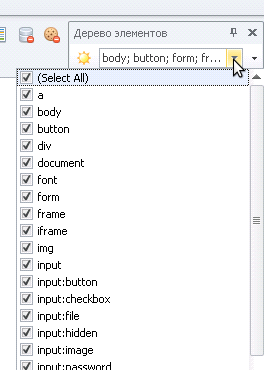
-Окна -> Дерево элементов
Дерево элементов -> Select ALL или те теги которые вам нужны, поможет отловить нужный тег
-По элементу ПКМ (Правой кнопкой мыши) -> В конструктор действий
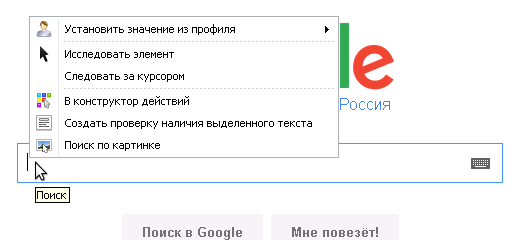
Для примера разберем поле с главной страницы гугла.
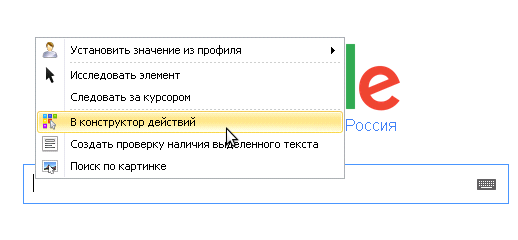
Кликаем по полю, которое служит для вбивания текста Правой Кнопкой Мыши -> В конструктор действий
И разберем все условия по которым проводится поиск элемента:
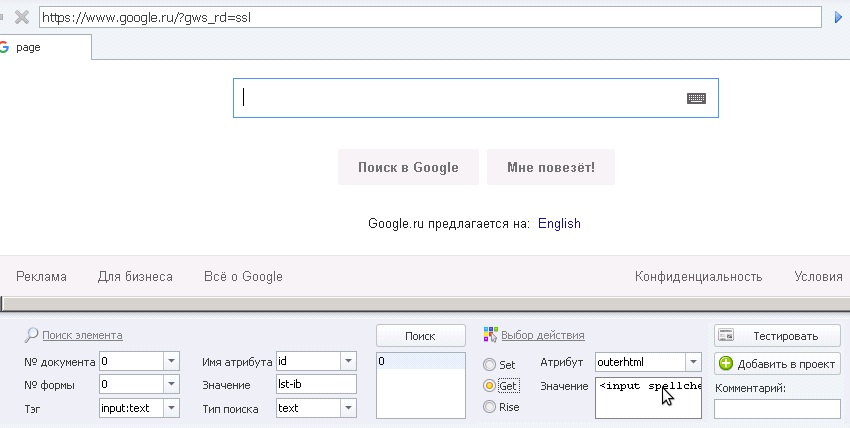
Номер документа:
0
номер документа может меняться (например 0;1 или 0 или 0;_0 или 1 и т.д.), если например Вы в попапе страницы что-то прописываете.
Не будем на этом участке заострять внимание.
Ставьте в этом поле -1, это значит что поиск будет совершаться во всех документах на странице.
Номер формы:
Это из языка программирования - php, имеется ввиду тег <form></form>.
На странице может быть несколько таких тегов. Этот тег служит для считывания информации из полей и отправки на сервер для обработки. Не заморачивайтесь и просто ставьте также -1.
Кому интересны детали для понимания, вот тут элементарный пример: http://php.net/manual/ru/tutorial.forms.php
Далее, для понимания, возьмем из свойства элемента - outerhtml (подробно, что это такое, разберем чуть ниже), вкратце – это весь тег со всеми атрибутами и т. д.
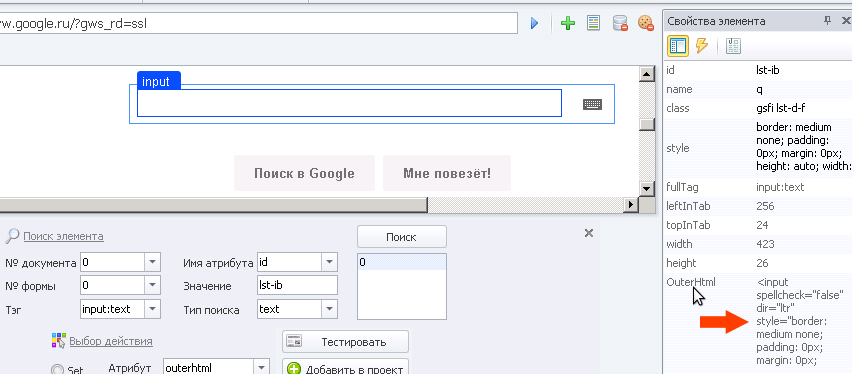
Тег:
Видим, что тег указан через двоеточие, как input:text, после двоеточия у тега прописан его тип, такое бывает у элементов содержащих тип, у большинства тегов не бывает типа, тип – это тот же самый атрибут, что такое атрибут мы рассмотрим ниже, но не типе атрибута внимание, если оставить просто "input", то элемент будет также успешно найден.
Имя Атрибута:
Тут вы можете указать любой существующий атрибут у элемента:
Атрибут это свойства тега. WIKI - https://ru.wikipedia.org/wiki/Тег_(языки_разметки)#.D0.90.D1.82.D1.80.D0.B8.D0.B1.D1.83.D1.82.D1.8B
Атрибуты которые мы видим:
spellcheck, dir, style, aria-autocomplete, role, aria-haspopup, class, maxlength, q, autocomplete, title, value, aria-label и type - это атрибуты тега.
Однако в свойствах элемента указаны далеко не все атрибуты, т.е. есть некоторые которые мы не видим внутри нашего тега input в привычном для нас формате. Давайте разберемся.
Есть атрибут outerhtml, т.е. если вы хотите взять весь тег со всеми свойствами внутри, также есть еще атрибуты innertext, innerhtml, fulltagname, tagname, width, height, top, left.
Приведу пример того, что у нас есть.
fulltagname = input:text
tagname = input
height = если элемент непосредственно видим, то будет его высота на странице, иначе 0
width = если элемент непосредственно видим, то будет его ширина на странице, иначе 0
top = расстояние до элемента от верхней части окна (используется для кликов по координатам)
left = расстояние до элемента от левой части окна (используется для кликов по координатам)
innertext = в данном случае будет равен пустоте, ибо у тега input нет закрывающей части, см. пример ниже
innerhtml = в данном случае будет равен пустоте, ибо у тега input нет закрывающей части, см. пример ниже
Для ознакомления выберите в действиях: Get и введите какой-либо атрибут и ознакомьтесь с результатами.

Для примера возьмем такой тег:
<div>Это <b>жирный текст</b></div>
Продемонстрирую значение следующих атрибутов:
innertext = Это жирный текст
innerhtml = Это <b>жирный текст</b>
Т.е. innertext берет только текст внутри тега, а innerhtml берет в том числе теги внутри нашего обрабатываемого тега
Значение:
Это то, что стоит внутри атрибута в кавычках, исходя из примера выше
для spellcheck это - false
для dir это - ltr
Или же то значение, которое характерно для другого типа атрибутов.
Исходя из примера - <div>Это <b>жирный текст</b></div>
для innertext это - Это жирный текст
для innerhtml это - Это <b>жирный текст</b>
Тип поиска:
Но не всегда обязательно указывать такое точное вхождение в поле "значение" для поиска.
Условие тип поиска может быть следующих видов:
-text
-regexp
-notext
При выборе типа поиска text, необходимо указывать в поле "значение" полностью значение необходимого атрибута или часть этого значения.
Т.е. например если на странице содержится 2 тега:
1. <div>Это <b>жирный текст</b></div>
2. <div>Это тоже <b>жирный текст</b></div>
Получается Innertext для тегов:
1. Это жирный текст
2. Это тоже жирный текст
и если Вы хотите найти оба этих тега, то достаточно указать
атрибут - innertext
значение - жирный текст
Т.к. это универсальный участок атрибута для обоих тегов
Найдутся оба тега, но они будут под разными номерами совпадений. (про совпадения поговорим чуть ниже)
Часто есть необходимость найти универсальные участки атрибутов, но не всегда они бывают столь явными. Часто они могут находиться и в начале и в конце, а часть атрибута в середине меняется, а одного только начального или только конечного участка атрибута недостаточно, ибо подхватываются какие-то лишние элементы, в атрибутах в которых есть такие же участки.
Тут нас выручит тип поиска - regexp
regexp=RegExp=Regular expression=Регулярные Выражения
Регулярные выражения — формальный язык поиска и осуществления манипуляций с подстроками в тексте, основанный на использовании мета-символов. По сути это строка-образец (по-русски её часто называют «шаблоном», «маской»), состоящая из символов и мета-символов и задающая правило поиска.
Крайне советую изучить самые основы. Для понимания процессов. Ничего сложного.
-https://ru.wikipedia.org/wiki/Регулярные_выражения
-http://zennolab.com/wiki/ru:creating-a-regular-expressions
В прожект мейкере для создания самых простых регулярных выражений нам поможет конструктор регулярных выражений.
Запустим его:
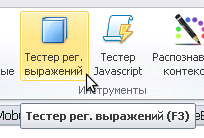
Вставим в текст для обработки:
автомобиль
электроавтомобиль
электромобиль
электроскуторомобиль
Искомый текст всегда начинается с: электро
Этим заканчивается искомый текст: мобиль
Регулярное выражение отобразится как:
электро.*?мобиль
Жмем - Тест
Получаем:
электроавтомобиль
электромобиль
электроскуторомобиль
Т.е. благодаря регулярным выражениям мы получаем возможность находить элементы, атрибуты которых имеют общие черты, но не полностью идентичны.
Вариантов очень много, это могут быть последовательности символов, соотношение символов и цифр, количество символов и т.д.
Регулярные выражения выручают очень часто! Следует иметь представление о том как они работают!
-notext
Помогает находить элементы, значение заданных атрибутов которых не содержит заданный текст.
Приведу пример, у нас на странице есть две кнопки:
name->notext->btnK, то найдется кнопка с атрибутом name="btnI"
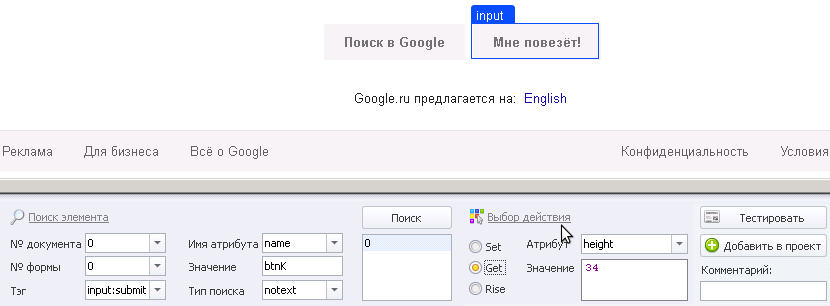
Если же указать name->notext->btnI, то найдется кнопка с атрибутом name="btnK"
Если же указать name->notext->btn, то не найдется ни одной, ибо эти обе кнопки содержат в себе btn
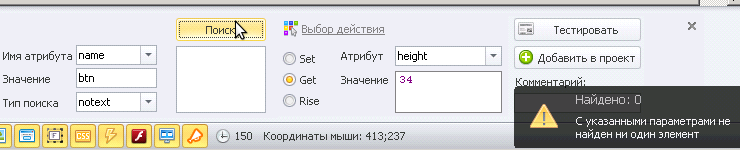
Параметр notext не может содержать регулярные выражения, только текст, как он есть.
Номер совпадения на странице:
Если элементов несколько и они удовлетворяют одним и тем же условиям при поиске, то они точно будут отличаться по номеру совпадения.
Отчет ведется с начала страницы и начинается с нуля.
Как пример A->Class->_Gs
Этому атрибуту и такому значению удовлетворяет сразу несколько элементов на странице.

Если Вам нужен только один элемент со страницы, для совершения действия, то старайтесь выбирать такие параметры поиска, чтобы находилось только одно совпадение.
Ибо верстка страницы может меняться, могут будь отличия при заходе с разных прокси, могут на странице появляться какие-то новые временные элементы.
Т.е. на пример на сайте, div элемент, с которым вы хотите поработать, он сегодня 16ый, а завтра сайт добавит себе рекламный блок и уже ваш элемент 17ый, а ваш шаблон работает все ещё с 16ым.
Т.е. Вам нужно находить такие атрибуты по возможности чтобы ваш элемент был уникальным, и был в номере совпадения номером 0.
По условиям поиска элементов на этом все. Далее мы будет разбираться, как можно группировать условия, задавать порядок поиска атрибутов, как воздействовать на код страницы.
Теперь попробуем разобраться с присваиванием значений несуществующим атрибутам.
Когда мы устанавливаем полю значение, мы выбираем set->value и указываем значение, которое хотим указать в поле. Т.е. изначально <input value="" type="text">, а после выполненного set->value->data, будет выглядеть так: <input value="data" type="text">, то есть, мы существующему атрибуту присвоили значение, так же можно сделать с любым несуществующим атрибутом.
Тому же элементу присвоить например атрибут capital="moscow", название атрибута и значение я сам придумал.
set->capital->moscow
будет иметь вид в итоге
<input capital="moscow" value="data" type="text">
Т.е. например, я могу присвоить любому элементу желаемый стиль, или какой-то уникальный атрибут для того, что бы находить в следующий раз этот элемент по этому уникальному атрибуту. Приведу наглядный пример для чего это может пригодиться.
Есть например такой код:
и т.д.
А нам нужно кликнуть по кнопке button внутри дива с определенным айди.
Но у кнопки нет каких-то уникальных признаков.
Мы для начала делаем:
div->data-object-id->53453->set->innerhtml-><button id="this">Add</button>
теперь участок кода имеет вид:
и следом делаем:
button->id->this->rise->click
Т.е. мы чуть изменили верстку под себя, присвоили тегу дополнительный атрибут, и благодаря этому смогли кликнуть удачно по вложенному тегу.
Бывают и более хитрые задачи.
Так же еще возможность использования для изменения верстки, путем изменения атрибутов, я нашел при работе с флешем.
На одном из сайтов мне нужно было кликать по флеш-каптче, я использовал функцию "клик по картинке",
но эта картинка была не слишком уникальна и часто, когда на флеш-каптче не находилось такого четкого совпадения, кликались другие элементы на странице, не имеющие отношения к флеш-каптче. А мне было необходимо, чтобы действие не выполнялось, и была возможность для других попыток клика по каптче, с другим примером картинки.
Для этого я просто затирал на странице все ненужные элементы перед попыткой клика, а именно - я присваивал innerhtml со значением пустоты этим тегам, и все содержимое в них уничтожалось.
Для примера уберем со страницы кнопку button. Таким образом, я убрал со страницы различные ссылки, флеш элементы ненужные и т.д. Благодаря этому, если клик и совершался, то он совершался по нужному участку!
div->data-object-id->53453->set->innerhtml->пустота
Т.е. участок кода теперь выглядит так:
Редактирование и упорядочивание приоритетов условий поиска элемента:
Это очень важный пункт, который поможет Вам грамотно сгруппировать те основы, которые мы разобрали выше и понять, что именно записывает в проект когда идет "запись действий", так же поможет Вам значительно сократить объемы ваших проектов и увеличить их читабельность.
Для примера я кликнул по какой-то ссылке на главной гугла и, давайте откроем шаг через редактор и посмотрим что же нам записалось:
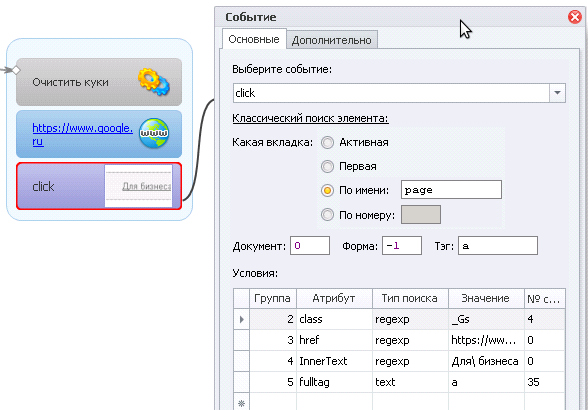
Действие - Click (все верно, думаю понятно)
Вкладка - Page
В зенно есть возможность вести работу через вкладки, т.е. в одном инстансе открыть сразу несколько вкладок, различные сайты или различные страницы, и можно кликать не только по активной на данный момент вкладке на которой мы находимся, но и по другим вкладкам - по их именам, не активируя её. По умолчанию у нашей вкладки имя page.
Документ 0
Форма -1
Это мы разбирали выше
Тег a (тут думаю тоже все понятно, любая ссылка это тег А с какими-то атрибутами)
Условия:
Вот тут начинается интересное.
Мы видим таблицу условий.
Разберем первый столбец - группа.
Номер в этом столбце обозначает приоритет обработки строки с её условием.
Чем номер меньше, тем первостепенней обрабатывается это условие.
Т.е. ищется элемент на странице, удовлетворяющий этому условию, и если такой элемент находится, то выполняется выбранное действие. В нашем случае выполняется клик.
Разберем строки и найдем слабые места такой "Автоматической" генерации этих условий.
2->class->regexp->Gs_->4
Слабое место, на мой взгляд, что тут под это условие подойдет элемент на странице, например с классом "superGs_", т.е. для этого нужно подробнее глянуть исходный код, а еще более слабое место – это номер совпадения, ибо в любой момент они могут изменить расположение элемента на странице (но не убрать, и уже согласно этому условию элемент нужный не кликнется или кликнется какой-то другой)
3->href->regexp->https://www\.google\.ru/services/\?fg=1->0
На мой взгляд, это самое верное условие для контекста задачи, кликается ссылка непосредственно с нужным урлом, но можно сделать еще чуть более умно. Рассмотрим ссылку подробнее.
https://www\.google\.ru/services/\?fg=1
Это обычная ссылка равная https://www.google.ru/services/?fg=1 , но т.к. стоит тип поиска regexp, т.е. регулярное выражение, то оно должно соответствовать правилам регулярных выражений и для корректного поиска, символы, которые могут быть распознаны как спец.символы, экранируются.
Т.е. в регулярных выражениях "." точка значит не точку, и вопрос "?" значит не знак вопроса, но чтобы они воспринимались в синтаксисе регулярных выражений так, как они есть, перед ними ставится символ "\" обратного слеша, но наше регулярное выражение удовлетворяет условию не только ссылки https://www\.google\.ru/services/\?fg=1
, но и например ссылке
https://www\.google\.ru/services/\?fg=15
, т.е. она не ограничена в длине, а подобные ссылки могут на странице встретится. Для того, чтобы этого избежать, вставим символ "^" в начале строки и "$" в конце строки, т.е.
^https://www\.google\.ru/services/\?fg=1$
Это значит, что будет с этого начинаться значение атрибута и этим заканчиваться, т.е. не может быть каких-то символов до или после. Почитайте подробнее про регулярные выражения. Самые основы Вам значительно увеличат понимание и упростят решение задач.
4->innertext->regexp->Для\ бизнеса->0
Неплохое условие. Но опять же лучше вставить ^ и $, и при заходе с айпи других стран язык будет меняться. Имейте ввиду.
5->fulltag->text->a->35
По мне это самое слабое условие из всех. Тут происходит клик по любой ссылке, которая идет под порядковым номером 35 на странице.
Т.е. весьма высока вероятность, что клик пройдет по какой-то другой ссылке. Ибо условие поиска очень не общее.
Хотя для каких-то задач именно важен номер ссылки на странице, например.
Тут я рассматриваю максимальную точность условий, это не всегда необходимо, но я стараюсь максимально перестраховываться, ибо какие-то изменения небольшие действительно часто встречаются, и лично у меня нет желания лезть и править ошибки.
Для себя, я бы удалил все условия, кроме условия 3, и подправил его так, как я советовал выше.
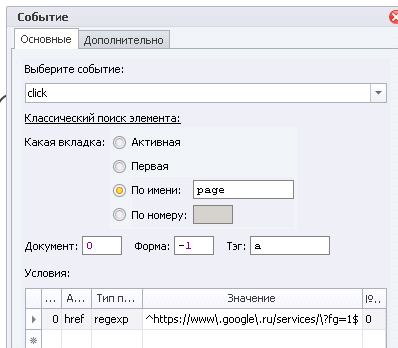
Кстати, для удаления условия нужно кликнуть на мелкий прямоугольник левее номера группы и нажать "Delete" на клавиатуре.
Группирование условий поиска элемента:
представим, что на странице есть эти ссылки в рандомной очередности:
Представим, что у нас задача кликнуть по ссылке которая:
1. содержит в урле max
2. не содержит в урле us
3. и если есть класс alfa, то кликаем по ней
4. и если нет класса alfa, то кликаем по ссылке с классом gama, которая также содержит в урле max, не содержит в урле us, но второй по порядку совпадения
Будет это выглядеть так:
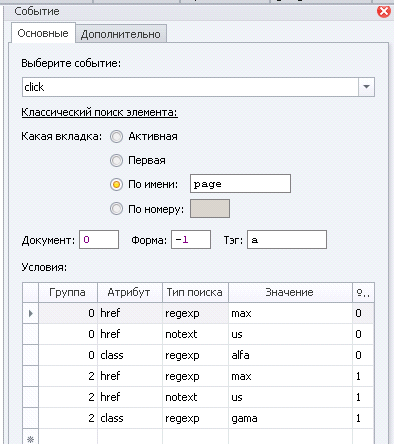
Давайте разберем подробнее:
Если Вы хотите задать в условиях поиска, что элемент должен удовлетворять сразу нескольким условиям, то номер группы у этих условий должен совпадать. Как видно в моем примере на скрине выше, у меня две группы условий по 3 в каждой группе.
Как видно, первая группа под цифрой "0" (тут может быть любое число), удовлетворят построчно условию 1, 2 и 3. Тут думаю понятно.
Вторая группа под цифрой "2", цифра 2 тут как пример, главное, чтобы она была больше номера числа предыдущей группы (т.е. может быть 1-99999....), т.к. чем выше номер группы, тем ниже у неё приоритет обработки.
Вторая группа удовлетворяет условию 1, 2 и 4.
Но обращу внимание еще на такой момент, что если условия относятся к одной группе, то и номер совпадения должен быть у них одинаковый.
Т.е. у всех 0 или 1 или 2 и т.д.
Как видно, у первой группы мы кликаем по первой ссылке, поэтому в номере совпадения у всех условий стоит 0 (не забываем, что отчет в зенно постере начинается с нуля), а у второй группы стоит 1, т.к. в задаче в пункте 4 прописано, что мы должны кликать по второму совпадению на странице.
Т.е. второй группе условий удовлетворит две ссылки 3 и 4, но т.к. у нас задача кликать на вторую по счету, т.е. в совпадении под числом 1, то у нас произойдет клик по ссылке 4.
На этом в этот раз все. Все объяснил на элементарных примерах. Думаю, эта статья порешает целую кучу создающихся топиков на форуме.
Понимание основ и умение их применять позволит Вам решать большинство задач.
Самые основы не требуют глубокого изучения, а требуют просто ознакомления и понимания.
Огромное количество вопросов на форуме из-за того, что люди не понимают самых основ, отсутствуют умения их грамотно группировать, из-за этого куча всяких деревянных решений. Люди пишут кривые, чудом работающие шабы, и часто долбятся днями в элементарные участки.
А задачи решаются элегантно одним шагом на самом деле, а не пятью.
И часто из-за непонимания основ у людей не хватает понимания, как правильно задать вопрос. А как мы знаем, каков вопрос, таков и ответ.
Эта статья поможет Вам во всем этом!
Текста много, но все просто, если вчитаться.
Если обобщить, то работа шаблонов зенно постера состоит из двух видов операций:
1. Логических
2. Работы с элементами на странице.
В данной статье пойдет разговор про понимание и умение применять самые основы работы с элементами.
Приступим.
Любой элемент на странице это тег.
Тег - элемент разметки гипертекста.
Проще говоря весь html код с которым зенно проводит манипуляции держится на тегах.
Wiki: https://ru.wikipedia.org/wiki/Тег_(языки_разметки)
Основы HTML: http://www.postroika.ru/html/content2.html
Уделите пол часика и просто прочитайте уроки. Начнете понимать, как и что между собой на странице взаимодействует.
Примеры тегов: <a>,<p>,<html>,<form>,<input>
У большинства тегов есть закрывающие части, т.е. </a>, </p>,</html>
т.е. например - <b>тут жирный текст</b>
Прочитайте уроки html и все станет понятно. Глубокое изучение тут не нужно, хватит внимательного ознакомления.
При любой работе с элементом мы взаимодействуем с ним следующим образом:
1. Где этот тег
2. Что это за тег
3. Какие у него уникальные признаки
4. Что мы делаем
Действие с элементом бывают 3х типов:
Set - присваиваем атрибуту элемента того или иного значения. (разберем ниже)
Get - получаем значение того или иного атрибута. (разберем ниже)
Rise - устанавливаем события взаимодействия с элементом. (фокусируемся на элементе, кликаем по элементу и т.д.)
Для работы, когда записи действий недостаточно, нам поможет:
В режиме записи и отладки:
-Окна -> Свойства действия, если уже записано
-Окна -> Свойства элемента
-Окна -> Дерево элементов
Дерево элементов -> Select ALL или те теги которые вам нужны, поможет отловить нужный тег
-По элементу ПКМ (Правой кнопкой мыши) -> В конструктор действий
Для примера разберем поле с главной страницы гугла.
Кликаем по полю, которое служит для вбивания текста Правой Кнопкой Мыши -> В конструктор действий
И разберем все условия по которым проводится поиск элемента:
Номер документа:
0
номер документа может меняться (например 0;1 или 0 или 0;_0 или 1 и т.д.), если например Вы в попапе страницы что-то прописываете.
Не будем на этом участке заострять внимание.
Ставьте в этом поле -1, это значит что поиск будет совершаться во всех документах на странице.
Номер формы:
Это из языка программирования - php, имеется ввиду тег <form></form>.
На странице может быть несколько таких тегов. Этот тег служит для считывания информации из полей и отправки на сервер для обработки. Не заморачивайтесь и просто ставьте также -1.
Кому интересны детали для понимания, вот тут элементарный пример: http://php.net/manual/ru/tutorial.forms.php
Далее, для понимания, возьмем из свойства элемента - outerhtml (подробно, что это такое, разберем чуть ниже), вкратце – это весь тег со всеми атрибутами и т. д.
HTML:
<input spellcheck="false" dir="ltr" style="border: medium none; padding: 0px; margin: 0px; height: auto; width: 100%; background: url("data:image/gif;base64,R0lGODlhAQABAID/AMDAwAAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw%3D%3D") repeat scroll 0% 0% transparent; position: absolute; z-index: 6; left: 0px; outline: medium none;" aria-autocomplete="both" role="combobox" aria-haspopup="false" class="gsfi lst-d-f" id="lst-ib" maxlength="2048" name="q" autocomplete="off" title="Поиск" value="" aria-label="Найти" type="text">Видим, что тег указан через двоеточие, как input:text, после двоеточия у тега прописан его тип, такое бывает у элементов содержащих тип, у большинства тегов не бывает типа, тип – это тот же самый атрибут, что такое атрибут мы рассмотрим ниже, но не типе атрибута внимание, если оставить просто "input", то элемент будет также успешно найден.
Имя Атрибута:
Тут вы можете указать любой существующий атрибут у элемента:
Атрибут это свойства тега. WIKI - https://ru.wikipedia.org/wiki/Тег_(языки_разметки)#.D0.90.D1.82.D1.80.D0.B8.D0.B1.D1.83.D1.82.D1.8B
Атрибуты которые мы видим:
spellcheck, dir, style, aria-autocomplete, role, aria-haspopup, class, maxlength, q, autocomplete, title, value, aria-label и type - это атрибуты тега.
Однако в свойствах элемента указаны далеко не все атрибуты, т.е. есть некоторые которые мы не видим внутри нашего тега input в привычном для нас формате. Давайте разберемся.
Есть атрибут outerhtml, т.е. если вы хотите взять весь тег со всеми свойствами внутри, также есть еще атрибуты innertext, innerhtml, fulltagname, tagname, width, height, top, left.
Приведу пример того, что у нас есть.
fulltagname = input:text
tagname = input
height = если элемент непосредственно видим, то будет его высота на странице, иначе 0
width = если элемент непосредственно видим, то будет его ширина на странице, иначе 0
top = расстояние до элемента от верхней части окна (используется для кликов по координатам)
left = расстояние до элемента от левой части окна (используется для кликов по координатам)
innertext = в данном случае будет равен пустоте, ибо у тега input нет закрывающей части, см. пример ниже
innerhtml = в данном случае будет равен пустоте, ибо у тега input нет закрывающей части, см. пример ниже
Для ознакомления выберите в действиях: Get и введите какой-либо атрибут и ознакомьтесь с результатами.
Для примера возьмем такой тег:
<div>Это <b>жирный текст</b></div>
Продемонстрирую значение следующих атрибутов:
innertext = Это жирный текст
innerhtml = Это <b>жирный текст</b>
Т.е. innertext берет только текст внутри тега, а innerhtml берет в том числе теги внутри нашего обрабатываемого тега
Значение:
Это то, что стоит внутри атрибута в кавычках, исходя из примера выше
для spellcheck это - false
для dir это - ltr
Или же то значение, которое характерно для другого типа атрибутов.
Исходя из примера - <div>Это <b>жирный текст</b></div>
для innertext это - Это жирный текст
для innerhtml это - Это <b>жирный текст</b>
Тип поиска:
Но не всегда обязательно указывать такое точное вхождение в поле "значение" для поиска.
Условие тип поиска может быть следующих видов:
-text
-regexp
-notext
При выборе типа поиска text, необходимо указывать в поле "значение" полностью значение необходимого атрибута или часть этого значения.
Т.е. например если на странице содержится 2 тега:
1. <div>Это <b>жирный текст</b></div>
2. <div>Это тоже <b>жирный текст</b></div>
Получается Innertext для тегов:
1. Это жирный текст
2. Это тоже жирный текст
и если Вы хотите найти оба этих тега, то достаточно указать
атрибут - innertext
значение - жирный текст
Т.к. это универсальный участок атрибута для обоих тегов
Найдутся оба тега, но они будут под разными номерами совпадений. (про совпадения поговорим чуть ниже)
Часто есть необходимость найти универсальные участки атрибутов, но не всегда они бывают столь явными. Часто они могут находиться и в начале и в конце, а часть атрибута в середине меняется, а одного только начального или только конечного участка атрибута недостаточно, ибо подхватываются какие-то лишние элементы, в атрибутах в которых есть такие же участки.
Тут нас выручит тип поиска - regexp
regexp=RegExp=Regular expression=Регулярные Выражения
Регулярные выражения — формальный язык поиска и осуществления манипуляций с подстроками в тексте, основанный на использовании мета-символов. По сути это строка-образец (по-русски её часто называют «шаблоном», «маской»), состоящая из символов и мета-символов и задающая правило поиска.
Крайне советую изучить самые основы. Для понимания процессов. Ничего сложного.
-https://ru.wikipedia.org/wiki/Регулярные_выражения
-http://zennolab.com/wiki/ru:creating-a-regular-expressions
В прожект мейкере для создания самых простых регулярных выражений нам поможет конструктор регулярных выражений.
Запустим его:
Вставим в текст для обработки:
автомобиль
электроавтомобиль
электромобиль
электроскуторомобиль
Искомый текст всегда начинается с: электро
Этим заканчивается искомый текст: мобиль
Регулярное выражение отобразится как:
электро.*?мобиль
Жмем - Тест
Получаем:
электроавтомобиль
электромобиль
электроскуторомобиль
Т.е. благодаря регулярным выражениям мы получаем возможность находить элементы, атрибуты которых имеют общие черты, но не полностью идентичны.
Вариантов очень много, это могут быть последовательности символов, соотношение символов и цифр, количество символов и т.д.
Регулярные выражения выручают очень часто! Следует иметь представление о том как они работают!
-notext
Помогает находить элементы, значение заданных атрибутов которых не содержит заданный текст.
Приведу пример, у нас на странице есть две кнопки:
HTML:
<input value="Поиск в Google" aria-label="Поиск в Google" name="btnK" jsaction="sf.chk" type="submit">
<input value="Мне повезёт!" aria-label="Мне повезёт!" name="btnI" jsaction="sf.lck" type="submit">
HTML:
<input value="Мне повезёт!" aria-label="Мне повезёт!" name="btnI" jsaction="sf.lck" type="submit">Если же указать name->notext->btnI, то найдется кнопка с атрибутом name="btnK"
Если же указать name->notext->btn, то не найдется ни одной, ибо эти обе кнопки содержат в себе btn
Параметр notext не может содержать регулярные выражения, только текст, как он есть.
Номер совпадения на странице:
Если элементов несколько и они удовлетворяют одним и тем же условиям при поиске, то они точно будут отличаться по номеру совпадения.
Отчет ведется с начала страницы и начинается с нуля.
Как пример A->Class->_Gs
Этому атрибуту и такому значению удовлетворяет сразу несколько элементов на странице.
Если Вам нужен только один элемент со страницы, для совершения действия, то старайтесь выбирать такие параметры поиска, чтобы находилось только одно совпадение.
Ибо верстка страницы может меняться, могут будь отличия при заходе с разных прокси, могут на странице появляться какие-то новые временные элементы.
Т.е. на пример на сайте, div элемент, с которым вы хотите поработать, он сегодня 16ый, а завтра сайт добавит себе рекламный блок и уже ваш элемент 17ый, а ваш шаблон работает все ещё с 16ым.
Т.е. Вам нужно находить такие атрибуты по возможности чтобы ваш элемент был уникальным, и был в номере совпадения номером 0.
По условиям поиска элементов на этом все. Далее мы будет разбираться, как можно группировать условия, задавать порядок поиска атрибутов, как воздействовать на код страницы.
Теперь попробуем разобраться с присваиванием значений несуществующим атрибутам.
Когда мы устанавливаем полю значение, мы выбираем set->value и указываем значение, которое хотим указать в поле. Т.е. изначально <input value="" type="text">, а после выполненного set->value->data, будет выглядеть так: <input value="data" type="text">, то есть, мы существующему атрибуту присвоили значение, так же можно сделать с любым несуществующим атрибутом.
Тому же элементу присвоить например атрибут capital="moscow", название атрибута и значение я сам придумал.
set->capital->moscow
будет иметь вид в итоге
<input capital="moscow" value="data" type="text">
Т.е. например, я могу присвоить любому элементу желаемый стиль, или какой-то уникальный атрибут для того, что бы находить в следующий раз этот элемент по этому уникальному атрибуту. Приведу наглядный пример для чего это может пригодиться.
Есть например такой код:
HTML:
<div data-object-id="12356">
<button>Add</button>
</div>
<div data-object-id="53453">
<button>Add</button>
</div>
<div data-object-id="23534">
<button>Add</button>
</div>А нам нужно кликнуть по кнопке button внутри дива с определенным айди.
Но у кнопки нет каких-то уникальных признаков.
Мы для начала делаем:
div->data-object-id->53453->set->innerhtml-><button id="this">Add</button>
теперь участок кода имеет вид:
HTML:
<div data-object-id="53453">
<button id="this">Add</button>
</div>button->id->this->rise->click
Т.е. мы чуть изменили верстку под себя, присвоили тегу дополнительный атрибут, и благодаря этому смогли кликнуть удачно по вложенному тегу.
Бывают и более хитрые задачи.
Так же еще возможность использования для изменения верстки, путем изменения атрибутов, я нашел при работе с флешем.
На одном из сайтов мне нужно было кликать по флеш-каптче, я использовал функцию "клик по картинке",
но эта картинка была не слишком уникальна и часто, когда на флеш-каптче не находилось такого четкого совпадения, кликались другие элементы на странице, не имеющие отношения к флеш-каптче. А мне было необходимо, чтобы действие не выполнялось, и была возможность для других попыток клика по каптче, с другим примером картинки.
Для этого я просто затирал на странице все ненужные элементы перед попыткой клика, а именно - я присваивал innerhtml со значением пустоты этим тегам, и все содержимое в них уничтожалось.
Для примера уберем со страницы кнопку button. Таким образом, я убрал со страницы различные ссылки, флеш элементы ненужные и т.д. Благодаря этому, если клик и совершался, то он совершался по нужному участку!
div->data-object-id->53453->set->innerhtml->пустота
Т.е. участок кода теперь выглядит так:
HTML:
<div data-object-id="53453"></div>Редактирование и упорядочивание приоритетов условий поиска элемента:
Это очень важный пункт, который поможет Вам грамотно сгруппировать те основы, которые мы разобрали выше и понять, что именно записывает в проект когда идет "запись действий", так же поможет Вам значительно сократить объемы ваших проектов и увеличить их читабельность.
Для примера я кликнул по какой-то ссылке на главной гугла и, давайте откроем шаг через редактор и посмотрим что же нам записалось:
Действие - Click (все верно, думаю понятно)
Вкладка - Page
В зенно есть возможность вести работу через вкладки, т.е. в одном инстансе открыть сразу несколько вкладок, различные сайты или различные страницы, и можно кликать не только по активной на данный момент вкладке на которой мы находимся, но и по другим вкладкам - по их именам, не активируя её. По умолчанию у нашей вкладки имя page.
Документ 0
Форма -1
Это мы разбирали выше
Тег a (тут думаю тоже все понятно, любая ссылка это тег А с какими-то атрибутами)
Условия:
Вот тут начинается интересное.
Мы видим таблицу условий.
Разберем первый столбец - группа.
Номер в этом столбце обозначает приоритет обработки строки с её условием.
Чем номер меньше, тем первостепенней обрабатывается это условие.
Т.е. ищется элемент на странице, удовлетворяющий этому условию, и если такой элемент находится, то выполняется выбранное действие. В нашем случае выполняется клик.
Разберем строки и найдем слабые места такой "Автоматической" генерации этих условий.
2->class->regexp->Gs_->4
Слабое место, на мой взгляд, что тут под это условие подойдет элемент на странице, например с классом "superGs_", т.е. для этого нужно подробнее глянуть исходный код, а еще более слабое место – это номер совпадения, ибо в любой момент они могут изменить расположение элемента на странице (но не убрать, и уже согласно этому условию элемент нужный не кликнется или кликнется какой-то другой)
3->href->regexp->https://www\.google\.ru/services/\?fg=1->0
На мой взгляд, это самое верное условие для контекста задачи, кликается ссылка непосредственно с нужным урлом, но можно сделать еще чуть более умно. Рассмотрим ссылку подробнее.
https://www\.google\.ru/services/\?fg=1
Это обычная ссылка равная https://www.google.ru/services/?fg=1 , но т.к. стоит тип поиска regexp, т.е. регулярное выражение, то оно должно соответствовать правилам регулярных выражений и для корректного поиска, символы, которые могут быть распознаны как спец.символы, экранируются.
Т.е. в регулярных выражениях "." точка значит не точку, и вопрос "?" значит не знак вопроса, но чтобы они воспринимались в синтаксисе регулярных выражений так, как они есть, перед ними ставится символ "\" обратного слеша, но наше регулярное выражение удовлетворяет условию не только ссылки https://www\.google\.ru/services/\?fg=1
, но и например ссылке
https://www\.google\.ru/services/\?fg=15
, т.е. она не ограничена в длине, а подобные ссылки могут на странице встретится. Для того, чтобы этого избежать, вставим символ "^" в начале строки и "$" в конце строки, т.е.
^https://www\.google\.ru/services/\?fg=1$
Это значит, что будет с этого начинаться значение атрибута и этим заканчиваться, т.е. не может быть каких-то символов до или после. Почитайте подробнее про регулярные выражения. Самые основы Вам значительно увеличат понимание и упростят решение задач.
4->innertext->regexp->Для\ бизнеса->0
Неплохое условие. Но опять же лучше вставить ^ и $, и при заходе с айпи других стран язык будет меняться. Имейте ввиду.
5->fulltag->text->a->35
По мне это самое слабое условие из всех. Тут происходит клик по любой ссылке, которая идет под порядковым номером 35 на странице.
Т.е. весьма высока вероятность, что клик пройдет по какой-то другой ссылке. Ибо условие поиска очень не общее.
Хотя для каких-то задач именно важен номер ссылки на странице, например.
Тут я рассматриваю максимальную точность условий, это не всегда необходимо, но я стараюсь максимально перестраховываться, ибо какие-то изменения небольшие действительно часто встречаются, и лично у меня нет желания лезть и править ошибки.
Для себя, я бы удалил все условия, кроме условия 3, и подправил его так, как я советовал выше.
Кстати, для удаления условия нужно кликнуть на мелкий прямоугольник левее номера группы и нажать "Delete" на клавиатуре.
Группирование условий поиска элемента:
представим, что на странице есть эти ссылки в рандомной очередности:
HTML:
<a class="alfa" href="http://google.com/max7">рандомный текст1</a>
<a class="beta" href="http://google.com/maxus">рандомный текст2</a>
<a class="gama" href="http://google.com/maxer">рандомный текст3</a>
<a class="gama" href="http://google.com/maxim">рандомный текст4</a>1. содержит в урле max
2. не содержит в урле us
3. и если есть класс alfa, то кликаем по ней
4. и если нет класса alfa, то кликаем по ссылке с классом gama, которая также содержит в урле max, не содержит в урле us, но второй по порядку совпадения
Будет это выглядеть так:
Давайте разберем подробнее:
Если Вы хотите задать в условиях поиска, что элемент должен удовлетворять сразу нескольким условиям, то номер группы у этих условий должен совпадать. Как видно в моем примере на скрине выше, у меня две группы условий по 3 в каждой группе.
Как видно, первая группа под цифрой "0" (тут может быть любое число), удовлетворят построчно условию 1, 2 и 3. Тут думаю понятно.
Вторая группа под цифрой "2", цифра 2 тут как пример, главное, чтобы она была больше номера числа предыдущей группы (т.е. может быть 1-99999....), т.к. чем выше номер группы, тем ниже у неё приоритет обработки.
Вторая группа удовлетворяет условию 1, 2 и 4.
Но обращу внимание еще на такой момент, что если условия относятся к одной группе, то и номер совпадения должен быть у них одинаковый.
Т.е. у всех 0 или 1 или 2 и т.д.
Как видно, у первой группы мы кликаем по первой ссылке, поэтому в номере совпадения у всех условий стоит 0 (не забываем, что отчет в зенно постере начинается с нуля), а у второй группы стоит 1, т.к. в задаче в пункте 4 прописано, что мы должны кликать по второму совпадению на странице.
Т.е. второй группе условий удовлетворит две ссылки 3 и 4, но т.к. у нас задача кликать на вторую по счету, т.е. в совпадении под числом 1, то у нас произойдет клик по ссылке 4.
На этом в этот раз все. Все объяснил на элементарных примерах. Думаю, эта статья порешает целую кучу создающихся топиков на форуме.
- Тема статьи
- Другое
- Номер конкурса статей
- Четвертый конкурс статей
Для запуска проектов требуется программа ZennoPoster или ZennoDroid.
Это основное приложение, предназначенное для выполнения автоматизированных шаблонов действий (ботов).
Подробнее...
Для того чтобы запустить шаблон, откройте нужную программу. Нажмите кнопку «Добавить», и выберите файл проекта, который хотите запустить.
Подробнее о том, где и как выполняется проект.
Последнее редактирование:

 :-)")


 ;-)")



