



- Регистрация
- 22.07.2014
- Сообщения
- 1 996
- Благодарностей
- 828
- Баллы
- 113
в конструкторе регулярок анализирую текст:
Нажимаю «Тест», получаю два элемента в результирующем списке.
Почему не один?
И отдельный вопрос: почему первый элемент обозначен числом ноль? Не говорите мне, что у программистов нумерация начинается с нуля — это неправда. С нуля начинают смещение относительно первого элемента, а тут смещение вообще ни при чём.
В поле «Это идёт после искомого текста» ставлю кавычку - вот такую: "1669">Абакан
Нажимаю «Тест», получаю два элемента в результирующем списке.
Почему не один?
И отдельный вопрос: почему первый элемент обозначен числом ноль? Не говорите мне, что у программистов нумерация начинается с нуля — это неправда. С нуля начинают смещение относительно первого элемента, а тут смещение вообще ни при чём.
 :-)") в обоих случаях получается не то, что пользователь ожидает, прошу считать это багом)
в обоих случаях получается не то, что пользователь ожидает, прошу считать это багом)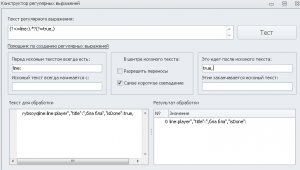
")


