




В этом небольшом мануале мы с вами научимся использовать xpath для поиска элементов.
Любая страница состоит из html тэгов. Чтобы это увидеть достаточно нажать по странице правой кнопкой мыши и нажать "показать исходный код"
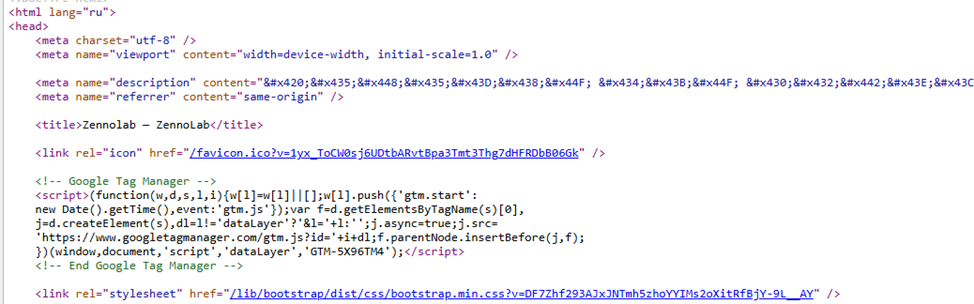
Всё, что отмечено фиолетовым цветом – тэги html. В скриншоте выше это <html>, <head>, <meta>, <title>, <link>, <script>.
У каждого html тэга есть атрибуты, а у атрибута его значение. Атрибуты помечены оранжевым цветом, а значение атрибута синим. Атрибуты позволяют дать какую-то дополнительную информацию о тэге или как-то изменить его вненший вид. Так, в скриншоте вида у тэга <html> есть атрибут "lang" со значением "ru", у тэга <head> никаких атрибутов нет у первого тэга <meta> есть атрибут "charset" со значением "utf-8".
Большинство тэгов имеют закрывающие тэги (но не все). Например, посмотрите на <title> </title>. Первый тэг открывающий, второй (с косой чертой) закрывающий.
На странице тэги располагаются как в матрешке, т.е. одни тэги вложены в другие, в них вложены ещё и т.д. Например:
В данном случае внутрь <body> вложено два тэга <div>, а внутри каждого из них находится тэг <button>. Определить кто в кого вложен можно по закрывающим тэгам, о которых говорили выше.
Если вам это совсем непонятно, рекомендую просто пройти на ютубе любой ролик по html. Вам не надо полностью верстать сайт, достаточно понять принцип. Думаю, часа хватит разобраться.
Когда мы хотим кликнуть по элементу, установить или получить его значение, нам надо идентифицировать конкретный тэг. Т.е. из всех тэгов на странице оставить только один, тот, что нужен именно нам. Для этого прекрасно подходит xpath.
Ну для начала. Многие для поиска элементов до сих пор используют "дерево элементов". Как по мне это уже пережиток прошлого и гораздо удобнее пользоваться встроенными инструментами хром.
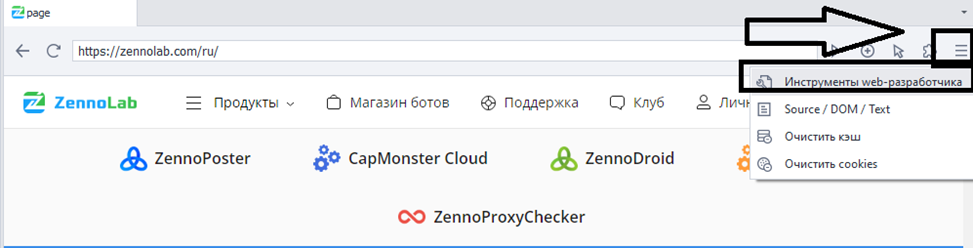
На вкладке "Elements" мы с вами видим все элементы, которые есть на странице.
Когда вы выделяете какой-то элемент, то он автоматически выделяется и на странице
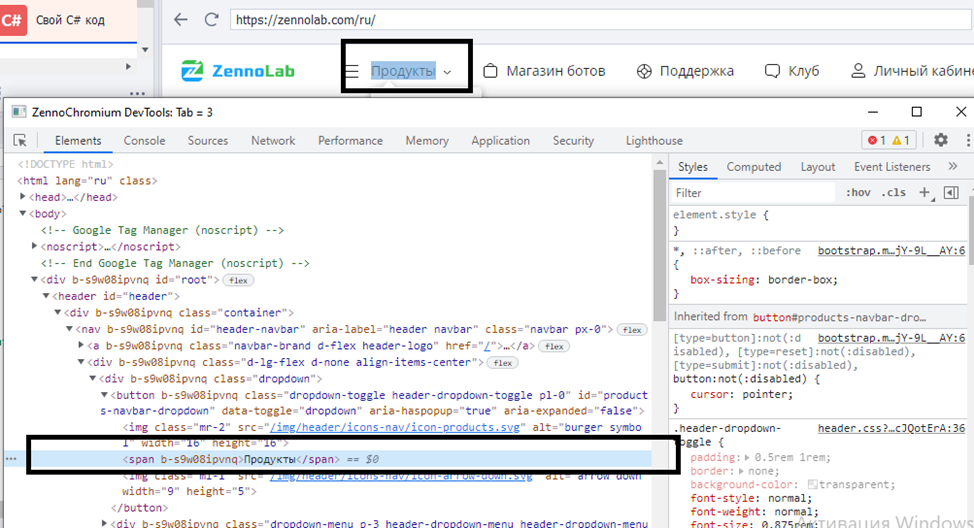
Чтобы найти конкретный элемент, нужно нажать по значку мыши в левом верхнем углу, а затем нажать по тому элементу, что вам нужен
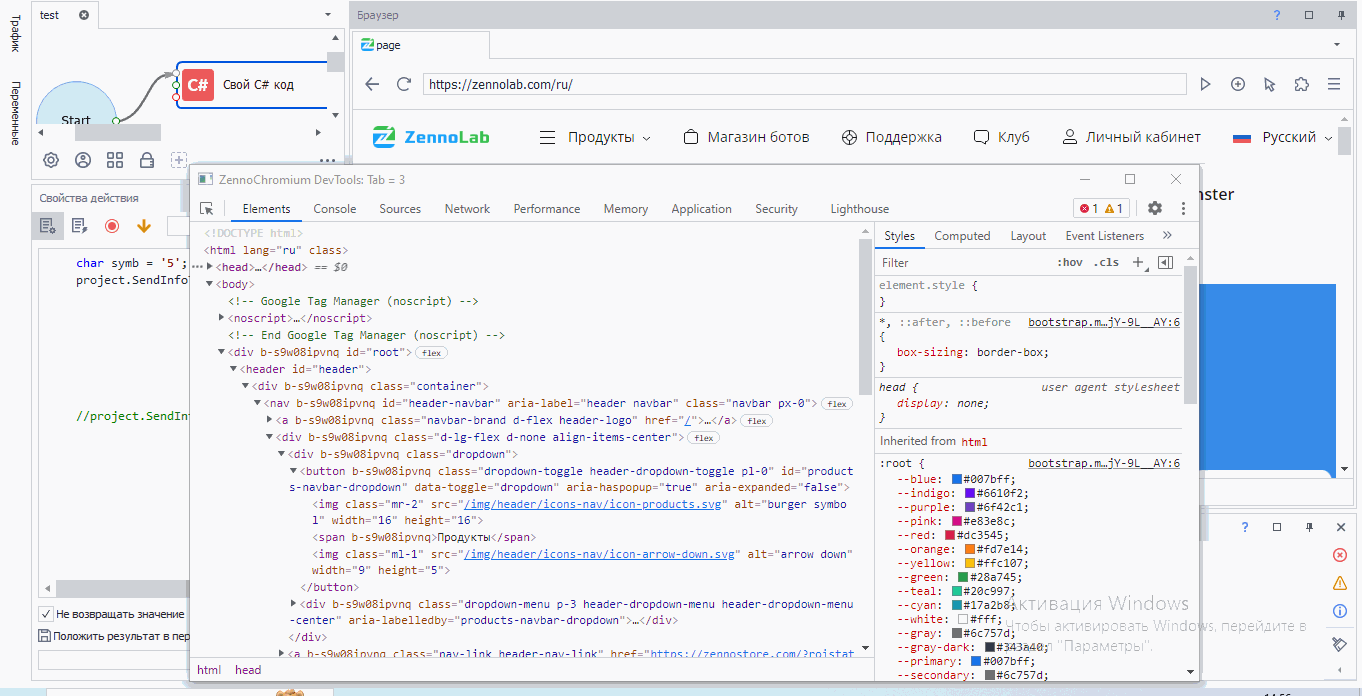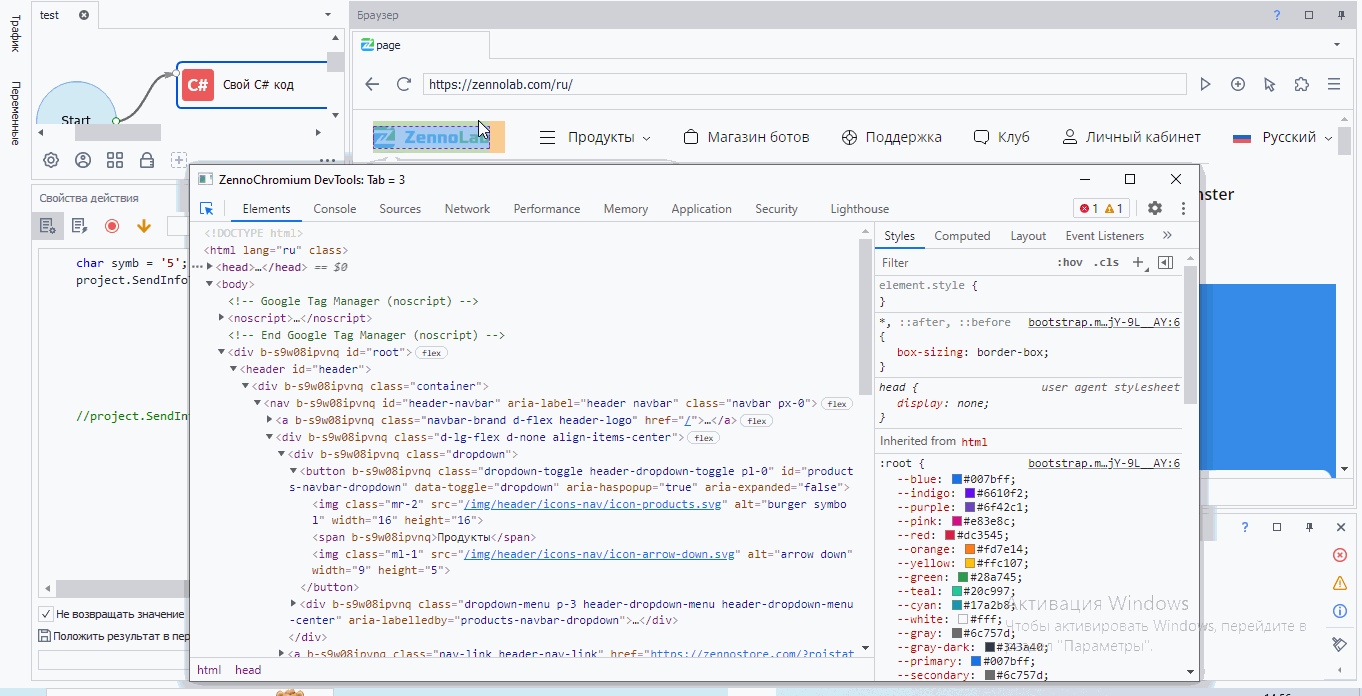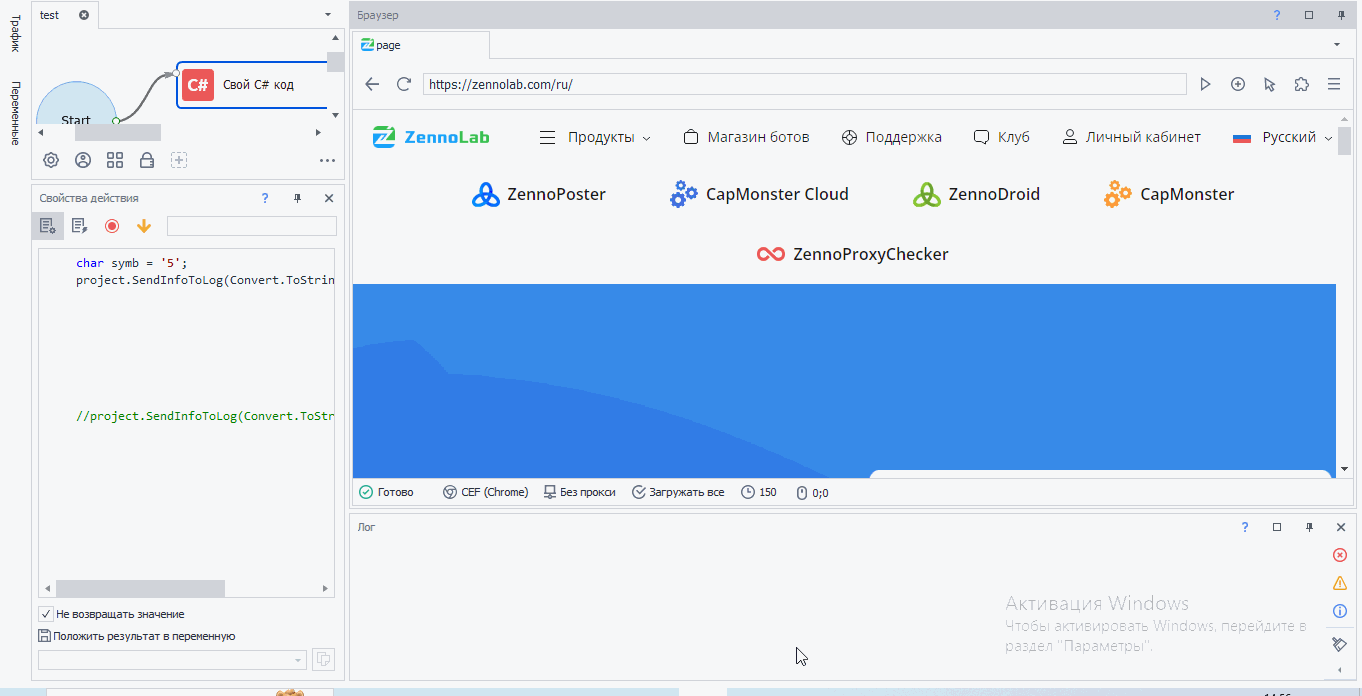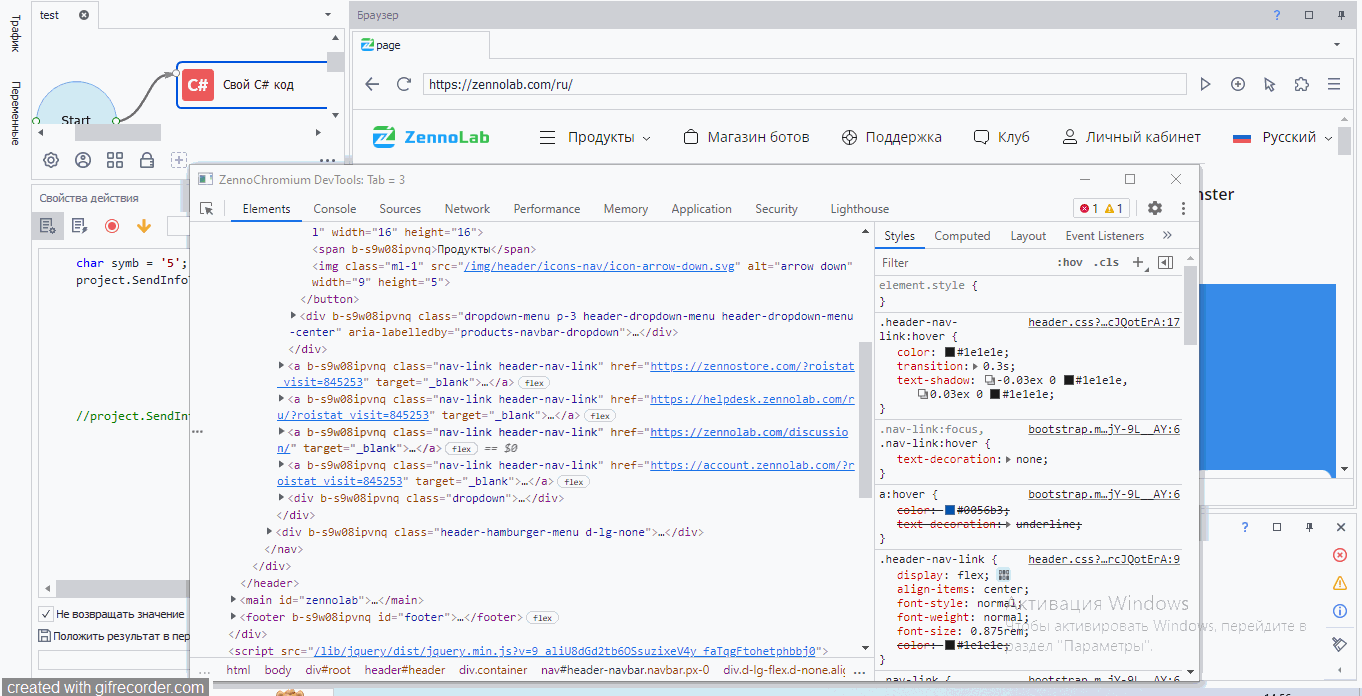
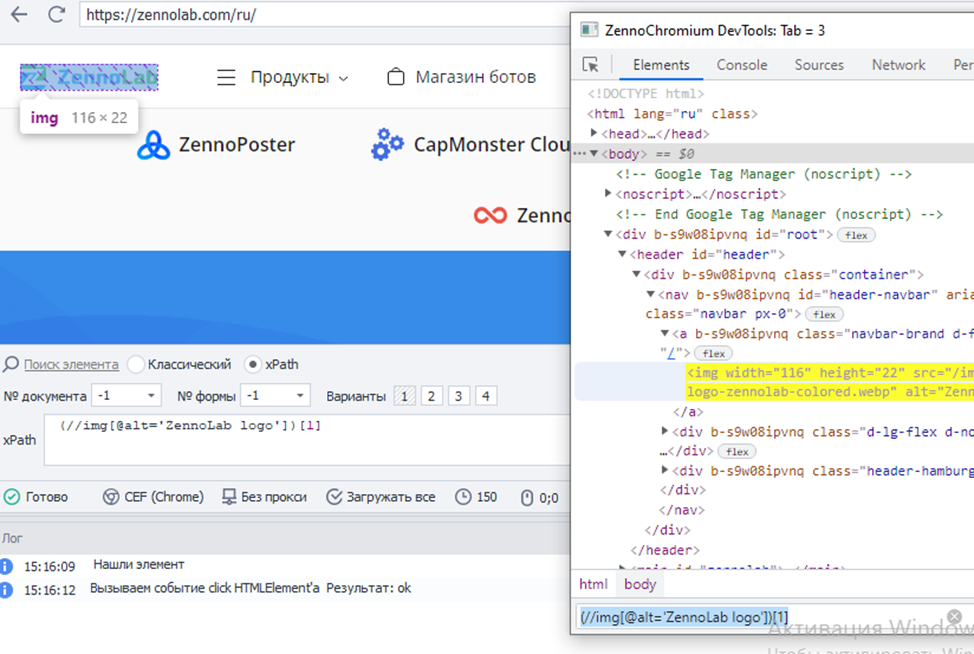
Самый простой вариант найти элемент – это указать название тэга, название атрибута и значение атрибута. Потренируемся на примере https://zennolab.com/ru/.
Давайте найдем логотип. Сначала выделяем его
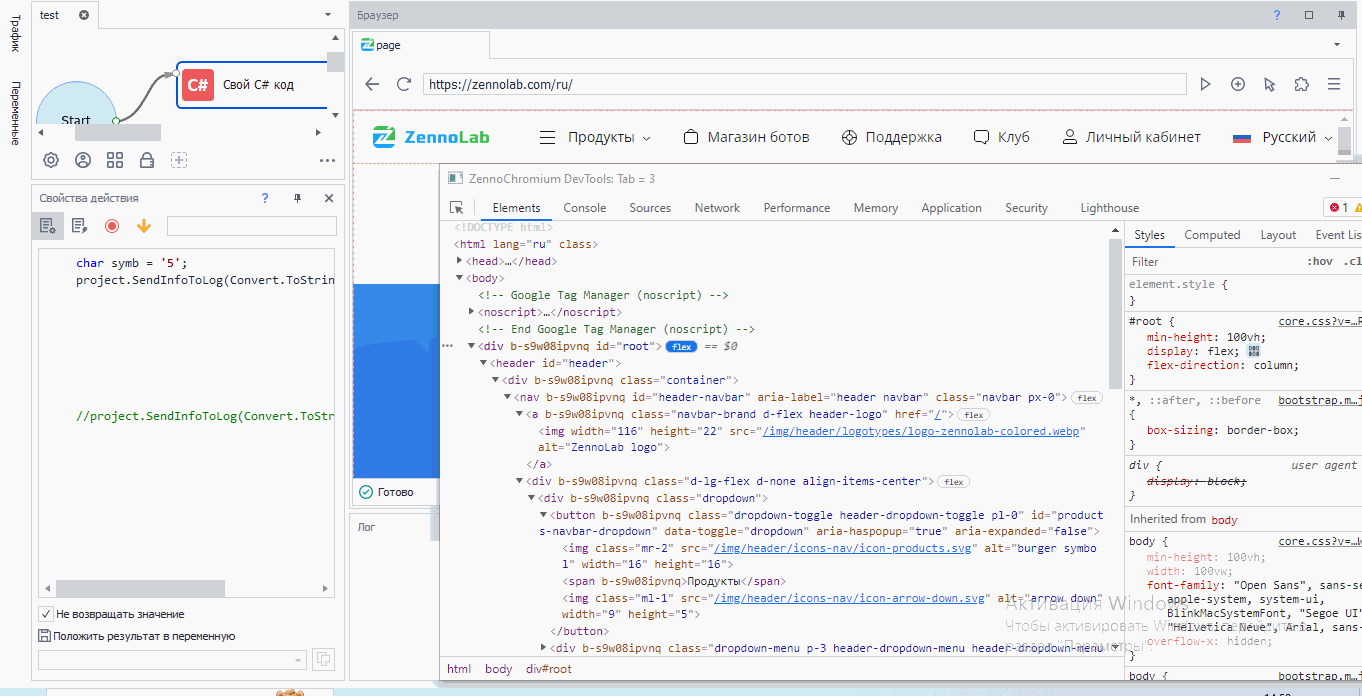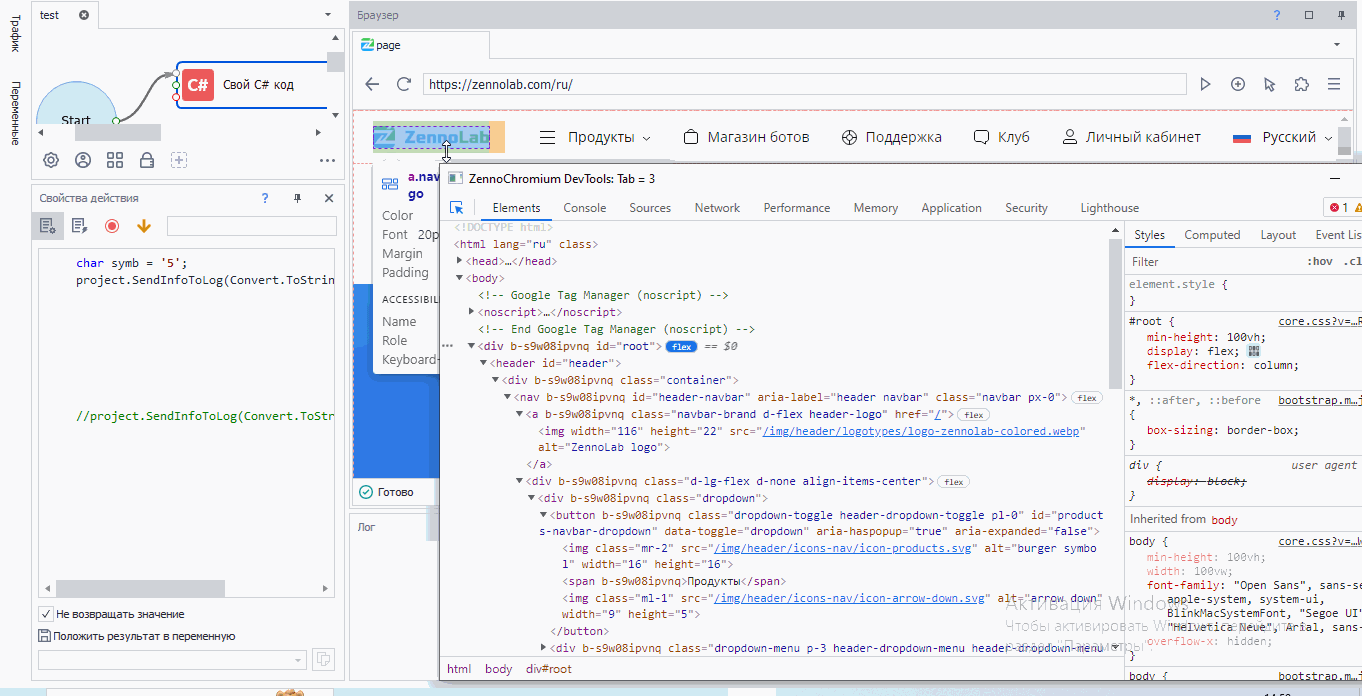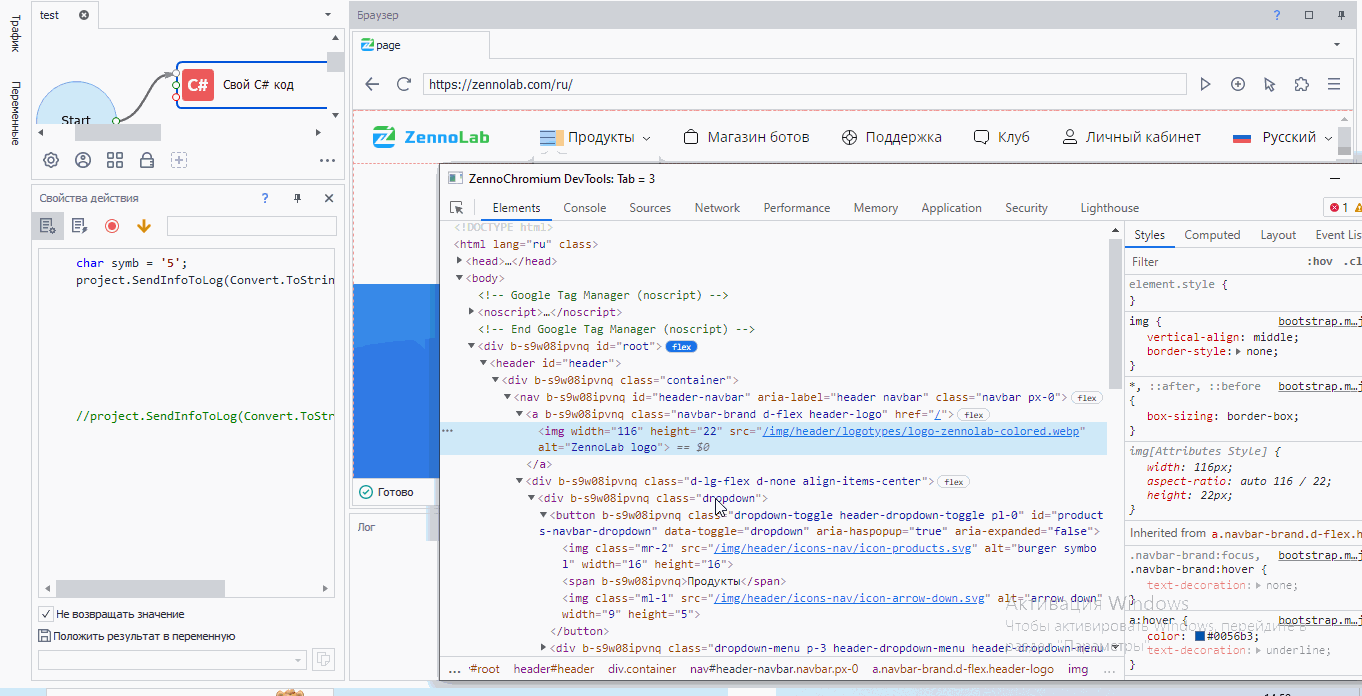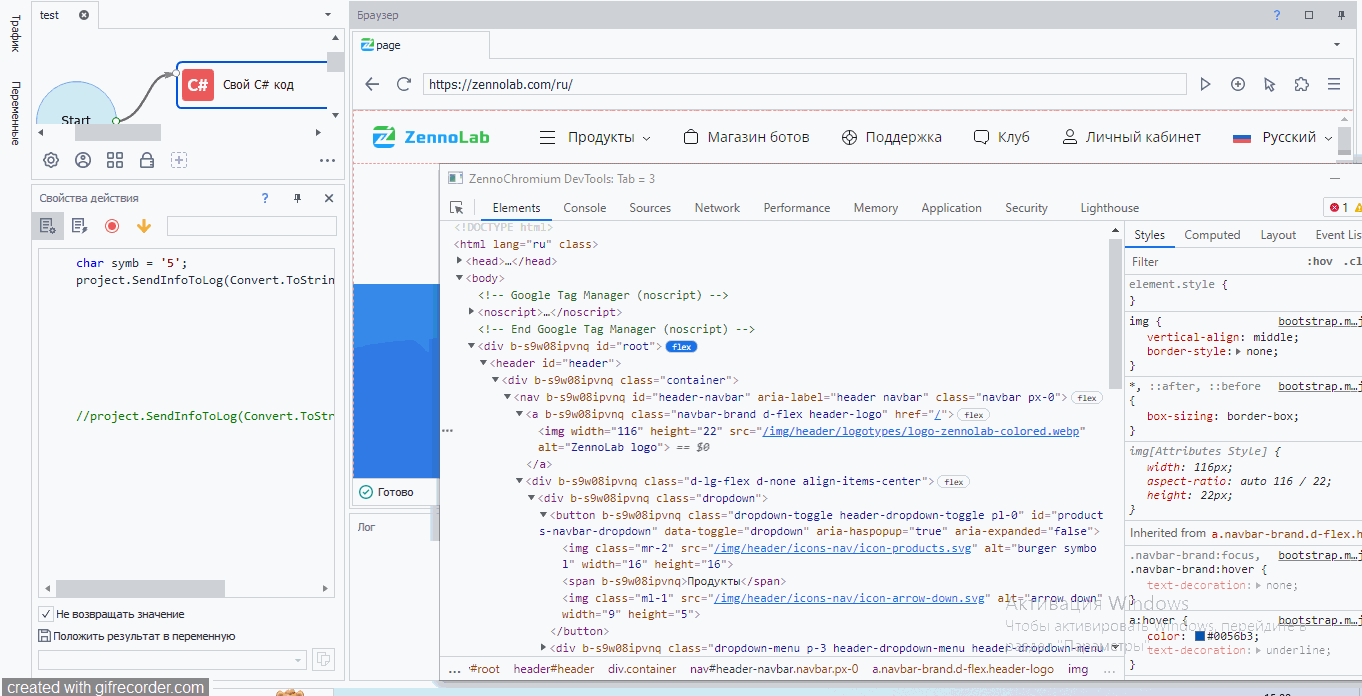

Мы с вами видим, что это тэг <img>. У этого тэга множество атрибутов:
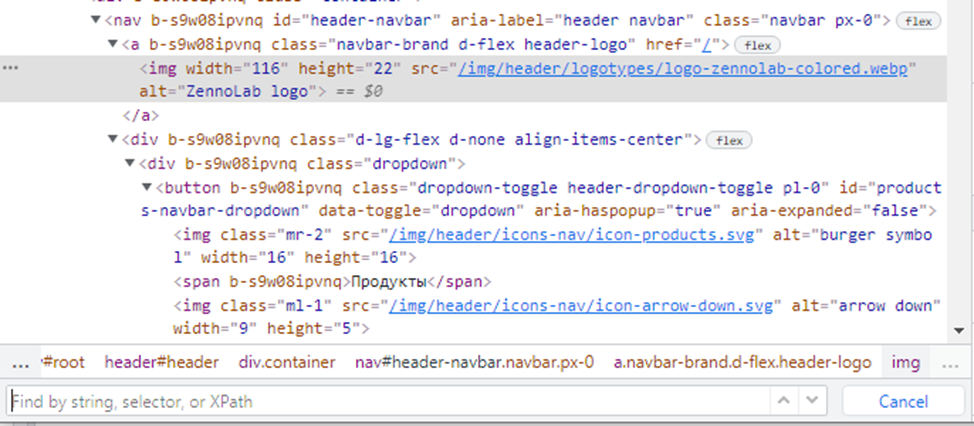
Формула такая:
//тэг[@названиеАтрибута='значениеАтрибута']
В нашем случае мы можем попробовать четыре варианта:
Первые три xpath пути выдали нам один элемент. Значит, по идее мы можем использовать любой из них. Давайте кликнем по логотипу. Как обычно вызываем конструктор действий, но тип поиска ставим xpath и вставляем туда наш xpath путь
Как я и сказал, по идее можно использовать любой из трех xpath путей. Но подбирать надо стараться такой, который с наименьшей вероятностью изменится.
Как и в случае с поиском по атрибутам, если было найдено несколько элементов, мы можем выбрать конкретный по номеру. Для этого нужно наш xpath обернуть в круглые скобки и в квадратных указать номер. Формула такая:
(//тэг[@названиеАтрибута='значениеАтрибута'])[номер]
Вот по этому xpath мы с вами получили два результата: //img[@alt='ZennoLab logo']
Давайте выберем первый:
(//img[@alt='ZennoLab logo'])[1]
Мы также можем указать, что нам нужен последний найденный элемент. Для этого вместо конкретной цифры прописываем функцию last()
(//img[@alt='ZennoLab logo'])[last()]
А вот так предпоследний
(//img[@alt='ZennoLab logo'])[last()-1]
С помощью xpath можно искать по тексту элемента. Формула:
//тэг[text()='значениеАтрибута']
Давайте найдем элемент, у которой текст "ZennoPoster":
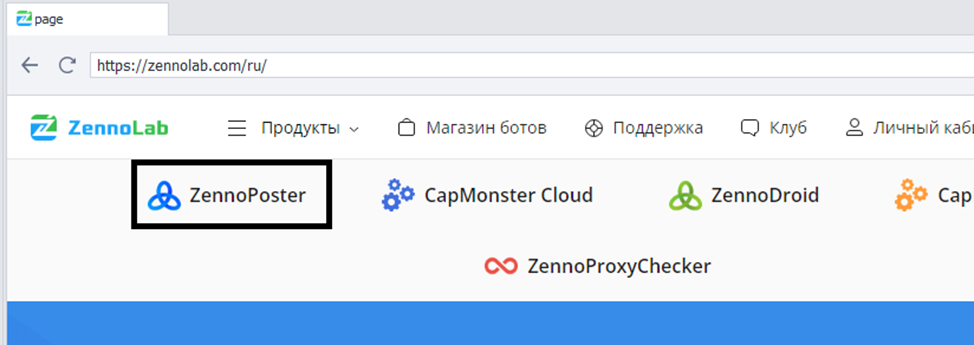
//span[text()='ZennoPoster']
Имейте ввиду, что если сайт мультиязычный, то поиск по тексту у вас может поломаться, если вы решите перейти с ру прокси на бурж.
Выше мы с вами рассматривали случаи точного совпадения текста. Но мы также можем искать и по части текста. Формула
//тэг[contains(@названиеАтрибута, значениеАтрибута)]
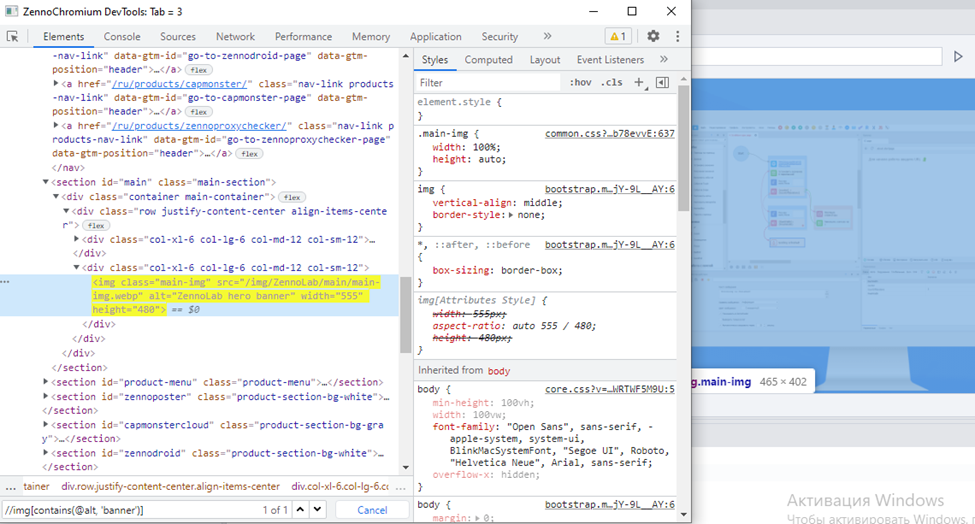
Пример поиска картинки на главной
//img[contains(@alt, 'banner')]
Если бы надо было искать по части текста, то наш xpath был бы примерно такой (на примере верхнего меню):
//span[contains(text(), 'Продукты')]
До этого момента мы использовали с вами только одно условие. Но мы можем использовать с вами сразу несколько условий с помощью and, or. And у нас проверяет, чтобы сразу несколько атрибутов соответствовали условию, а or чтобы хотя бы один из атрибутов тэга совпадал по условию.
Формула:
//тэг[@названиеАтрибута='значениеАтрибута' and @названиеАтрибута='значениеАтрибута' and @названиеАтрибута='значениеАтрибута']
или
//тэг[@названиеАтрибута='значениеАтрибута' or @названиеАтрибута='значениеАтрибута']
Никто не запрещает и совмещать and и or.
Примеры
//img[@width='116' and @height='22']
Т.е. в данном случае у тэга <img> обязательно должен быть атрибут width со значением 116 и атрибут height со значением 22.
//a[contains(@href, 'discussion' ) or text()='Клуб']
В этом же случае у нас тэг <a> либо в атрибуте href должен содержать discussion или же должен иметь текст "Клуб".
Ниже я рассказываю о функциях, которые сам почти не использовал. Можете их пропустить и переходить к осям, если нет желания перегружать свой мозг
Работает аналогично contains, но он проверяет, чтобы начало точно совпадало с тем, что вы указали. Формула:
//тэг[starts-with(@названиеАтрибута, значениеАтрибута)]
Например:
//span[starts-with(text(), 'Проду')]
До этого мы с вами рассматривали варианты "атрибут равен" или "текст равен". Но мы также можем указать и "не равен". Обычно это может быть полезно в связке с другими приемами, об этом ещё поговорим. Формула:
//тэг[@названиеАтрибута!='значениеАтрибута']
или
//тэг[not(contains(@названиеАтрибута, 'значениеАтрибута'))]
Например:
//img[@src!='header']
//img[not(contains(@src, 'header'))]
Сейчас вам может показаться это бессмысленным, т.к. количество найденных тэгов по таким условиям будет очень большим. Но как я писал выше, данная функция используется в связке с другими.
Пускай есть вот такая страничка:
Как нам с вами выцепить именно первый абзац? Для этого мы можем сказать, что нам нужен тот тэг <p> внутри которого будет три тэга <a>. Сделать это можно с помощью функции count
//p[count(a)=3]
Помимо знака равно вы можете использовать !=, >, <.
Мы можем проверять длину содержимого тэга. Вот пример того, как можно найти <span>, чья длина будет ровно 11 символов
//span[string-length()=11]
Бывает такое, что часть значения атрибута может быть динамической, т.е. меняться при каждой перезагрузке страницы. Мы это можем обходить с помощью contains, но что если мы хотим более точно задать что искать. В этом случае можно использовать функцию substring.
//span[substring(@class, '5','4')=asfa] – вернет span, у которых класс, начиная с пятого символа 4 символа равны asfa
Всё, о чём мы говорили выше, на самом деле не так сильно отличается от поиска по атрибуту. Ведь в атрибутах нам доступен такой мощный инструмент, как регулярные выражения, а в xpath такого нет. Но у xpath есть одно большое преимущество – мы можем гулять от одного тэга к другому. Давайте я поясню.
Пускай есть вот такая разметка, и мы хотим нажать по второму <button>
Как видите, в данном случае зацепиться не за что. Оба <button> не имеют никаких атрибутов и текст у них одинаковый. Исходя из тех знаний, что у нас есть, мы можем только лишь выбрать по номеру элемента. Но разработчик с помощью js может менять их местами, путая нам карты или же потом добавить ещё одну кнопку вперед нашей и наш код поломается.
Но что мы тут видим? Мы видим, что наши <button> находятся внутри <div>. Первый <button> внутри тэга <div id='btn1'>, а второй <div id='btn2'>. Мы можем привязаться к div по атрибуту, а от него уже спуститься к нужному тэгу <a>. Делается это так:
//div[@id='btn2']/button
Т.е. чтобы нам "спуститься" на одну ступеньку вниз (к "ребенку атрибута") достаточно поставить слэш и указать название того тэга, что нам нужен. Помните, что у "родителя" может быть множество таких "детей", поэтому мы можем уточнять путь с помощью всех приемов, описанных выше.
Давайте вернемся на zennolab.com и потренируемся. Сначала я ещё раз заострю внимание на том, кто именно является "детьми".
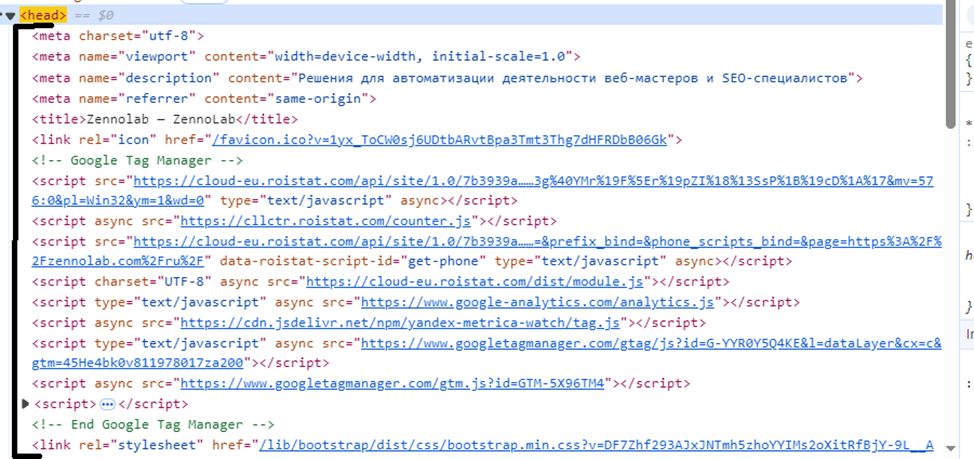
Вот например у первого тэга <head> столько "детей". Например, нас интересует <meta name="description">. Тогда мы могли бы прописать xpath путь так:
//head/meta[@name='description']
Спускаться таким образом "по ступенькам" можно сколь угодно глубоко. Давайте найдем вот этот элемент, начиная с тэга <section>
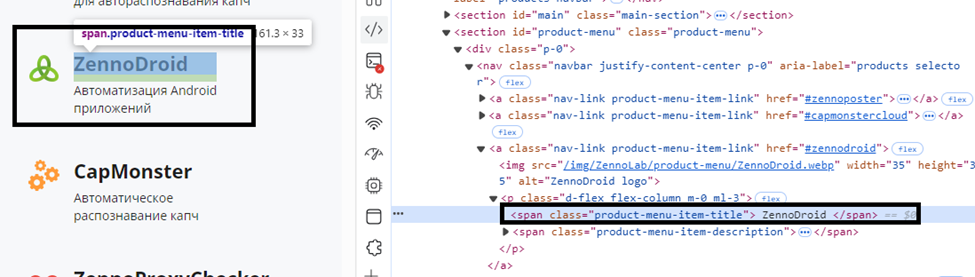
//section[@id='product-menu']/div/nav/a/p/span[contains(text(), 'ZennoDroid')]
Ранее мы с вами "спускались" по одной ступеньке вниз. Точно также мы можем "подниматься наверх" (т.е. к родителю), используя ось parent. Делается это так:
//head/parent::html
Т.е. в данном случае мы начали с тэга <head>, а затем поднялись к его родителю <html>.
Чуть выше мы с вами от <section> опустились к <span> ZennnoDroid. Давайте проделаем обратную операцию, т.е. поднимемся от <span> ZennnoDroid к <section>
//span[contains(text(), 'ZennoDroid')]/parent::p/parent::a/parent::nav/parent::div/parent::section[@id='product-menu']
Если вам не требуется указывать конкретный тэг, то можно использовать более краткую запись:
//span[contains(text(), 'ZennoDroid')]/../../../../parent::section[@id='product-menu']
Смотрите, вот такие длинные пути, как мы с вами прописывали выше, это не есть гуд. Я просто приводил их как пример. Обычно мы опускаемся или поднимаемся буквально на 1-3 уровня. Т.к. если админ решит добавить какой-то тэг, то наш путь сразу поломается.
Но случаи, когда "нормальный" тэг находится достаточно далеко от того, что нам нужен, бывает довольно часто (особенно во всяких соц сетях). В этом случае нам поможет ось descendant. Прописывая её, мы говорим, что нас интересуют все элементы потомки данного тэга.
Давайте возьмём такую разметку:
В данном случае у тэга <div id="main"> потомками будут все <div> и <span>
Если мы просто напишем
//span
То на реальной странице результатов будет очень много.
Если мы напишем
//div[@id='main']/div/div/div/div/span
То путь получается довольно длинным, что рискованно. Используя descendant, мы делаем так:
//div[@id='main']/descendant::span
Т.е. нас интересуют все потомки <span> (дети, внуки, правнуки и т.д.) тэга //div[@id='main'].
Возвращаемся на zennolab. Давайте сократим этот путь до адекватного
//section[@id='product-menu']/div/nav/a/p/span[contains(text(), 'ZennoDroid')]
//section[@id='product-menu']/descendant::span[contains(text(), 'ZennoDroid')]
Есть также краткая запись. Вместо слова descendant можно просто поставить //
//section[@id='product-menu']//span[contains(text(), 'ZennoDroid')]
Аналогична descendant, только движемся мы наверх. Т.е. она захватывает всех предков ("папу, деда, прадеда"). Перепишем вот этот путь
//span[contains(text(), 'ZennoDroid')]/parent::p/parent::a/parent::nav/parent::div/parent::section[@id='product-menu']
//span[contains(text(), 'ZennoDroid')]/ancestor::section[@id='product-menu']
Данная ось нужна нам для элементов, которые находятся на одном уровне. Образно говоря, для "младших братьев". Посмотрим на такую разметку:
Видите, все <span> находятся на одном уровне, т.е. являются "братьями". Вот так можно перейти от <span id="1"> к последнему "брату"
//span[@id='1']/following-sibling::span[last()]
Ось Following-sibling берет именно тех братьев, что "ниже" изначально указанного тэга. Т.е. вот этих (красный цвет), но не этого (белый цвет).
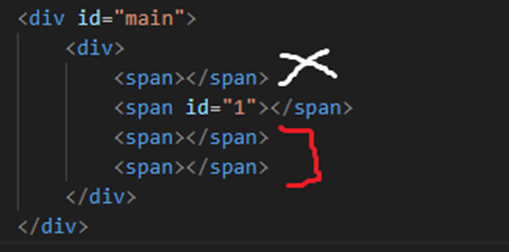
Номер нужного нам "брата" указываем в квадратных скобках, если это необходимо [] (в примере выше мы вместо номера использовали функцию last()).
Пример пути для zennolab.com (берем последнююю ссылку внутри блока section[@id='product-menu'])
//section[@id='product-menu']//following-sibling::a[last()]
Она аналогично предыдущей, только ищет тех, что предшествуют текущему ("старших братьев"). Возвращаясь к предыдущему примеру, мы можем добратсья до самого первого <span> таким образом:
//span[@id='1']/preceding-sibling::span
Т.е. мы сначала "зацепились" к <span>, у которого id='1', а затем сказали, что нас интересуют все "старшие братья" <span>
Их я на практике не использовал. Даю описание с wikipedia
Ось following содержит множество элементов, расположенных ниже текущего элемента по дереву (на всех уровнях и слоях), исключая собственных потомков.
Ось preceding содержит множество элементов, расположенных выше текущего элемента по дереву (на всех уровнях и слоях), исключая множество собственных предков.
Давайте теперь расскажу о тех моментах, что остались "за кадром".
Вам не обязательно указывать название тэга. Вы можете воспользоваться * чтобы указать, что вас устраивает любой тэг. Например:
//*[@id='1234']
Вам не обязательно указывать значение атрибута. Вы можете просто сказать, что у элемента должен быть такой-то атрибут с любым значением. Делается это вот так:
//a[@href]
Иногда бывает, что тэг на странице есть, но когда мы составляем xpath, то он не ищется. Обычно это когда используются какие-то редкие тэги (или вовсе кастомные). В таких ситуациях нам следует использовать функцию name(), в которой мы и указываем название тэга (в примере ниже это тэг <svg>).
//*[name()='svg']
Вы можете указать несколько xpath путей через |. Иногда это бывает полезно. Пример:
//div[@id='1234']|//span[@id='1234']
Вы можете уточнить путь до элемента внутри []. Что я имею ввиду. Посмотрите на картинку
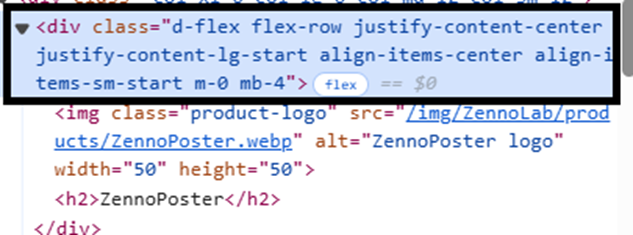
Предположим, нам нужен вот этот вот <div>, но у него какой-то непонятный class и всё. В таком случае мы можем сказать, что нам нужен <div>, у которого есть ребенок <h2> с текстом "ZennoPoster"
//div[h2[text()='ZennoPoster']]
Т.е. надо просто поставить [] и внутри прописать дополнительные условия, кто должен быть у него в предках. Можно использовать любые оси:
//div[descendant::h2[text()='ZennoPoster']]
Вы не сможете найти элемент, который внутри shadow dom. Это встречается редко, но об этом следует знать. Стандартный поиск по тэгу у вас тоже не сработает. Давайте посмотрим пример на https://www.ea.com/sports. Если вам нужно будет кликнуть по верхнем элементам меню, то ничего не выйдет. Посмотрите на код:

Видите надпись "shadow-root"? Если нужный вам элемент внутри него, то значит кликнуть стандартными средствами не выйдет. Что же делать? Если вы видите надпись open, то можно кликнуть через js. Если же будет надпись closed, то только поиском по картинке.
В видео я покажу вам, как использовать xpath в кубике c#.
Основы
Любая страница состоит из html тэгов. Чтобы это увидеть достаточно нажать по странице правой кнопкой мыши и нажать "показать исходный код"
Всё, что отмечено фиолетовым цветом – тэги html. В скриншоте выше это <html>, <head>, <meta>, <title>, <link>, <script>.
У каждого html тэга есть атрибуты, а у атрибута его значение. Атрибуты помечены оранжевым цветом, а значение атрибута синим. Атрибуты позволяют дать какую-то дополнительную информацию о тэге или как-то изменить его вненший вид. Так, в скриншоте вида у тэга <html> есть атрибут "lang" со значением "ru", у тэга <head> никаких атрибутов нет у первого тэга <meta> есть атрибут "charset" со значением "utf-8".
Большинство тэгов имеют закрывающие тэги (но не все). Например, посмотрите на <title> </title>. Первый тэг открывающий, второй (с косой чертой) закрывающий.
На странице тэги располагаются как в матрешке, т.е. одни тэги вложены в другие, в них вложены ещё и т.д. Например:
Код:
<body>
<div id='btn1'>
<button>Кнопка</button>
</div>
<div id='btn2'>
<button>Кнопка</button>
</div>
</body>Если вам это совсем непонятно, рекомендую просто пройти на ютубе любой ролик по html. Вам не надо полностью верстать сайт, достаточно понять принцип. Думаю, часа хватит разобраться.
Когда мы хотим кликнуть по элементу, установить или получить его значение, нам надо идентифицировать конкретный тэг. Т.е. из всех тэгов на странице оставить только один, тот, что нужен именно нам. Для этого прекрасно подходит xpath.
Используем инструменты веб-разработчика
Ну для начала. Многие для поиска элементов до сих пор используют "дерево элементов". Как по мне это уже пережиток прошлого и гораздо удобнее пользоваться встроенными инструментами хром.
На вкладке "Elements" мы с вами видим все элементы, которые есть на странице.
Когда вы выделяете какой-то элемент, то он автоматически выделяется и на странице
Чтобы найти конкретный элемент, нужно нажать по значку мыши в левом верхнем углу, а затем нажать по тому элементу, что вам нужен
Основы xpath
Самый простой вариант найти элемент – это указать название тэга, название атрибута и значение атрибута. Потренируемся на примере https://zennolab.com/ru/.
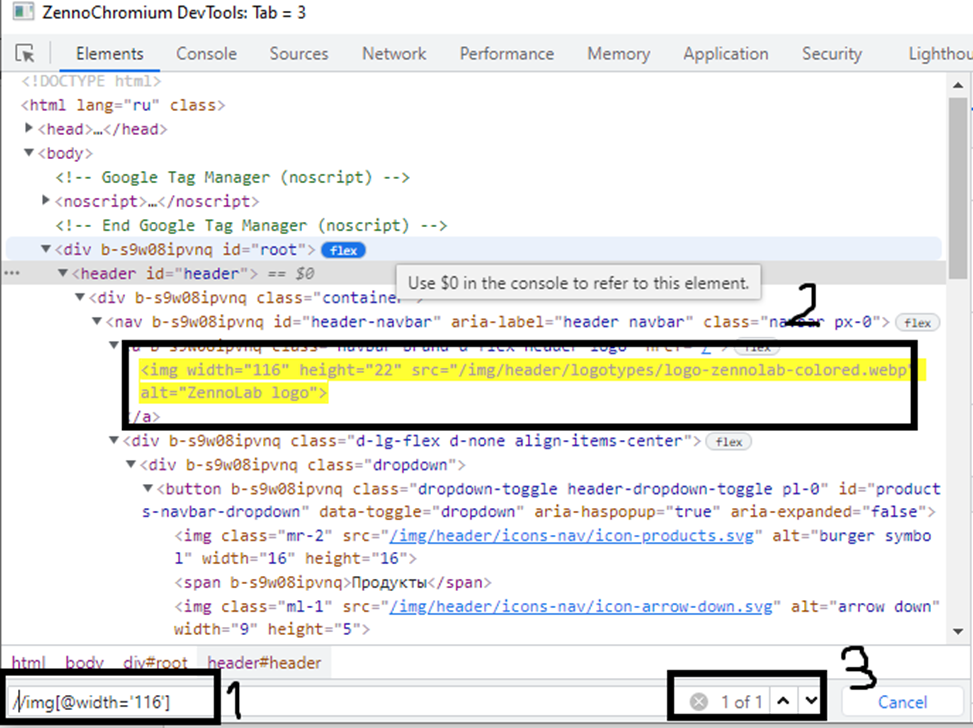
Давайте найдем логотип. Сначала выделяем его
Мы с вами видим, что это тэг <img>. У этого тэга множество атрибутов:
- width со значением 116
- height со значением 22
- src со значением /img/header/logotypes/logo-zennolab-colored.webp
- alt со значением ZennoLab logo
Формула такая:
//тэг[@названиеАтрибута='значениеАтрибута']
В нашем случае мы можем попробовать четыре варианта:
- //img[@width='116']
- //img[@height='22']
- //img[@src='/img/header/logotypes/logo-zennolab-colored.webp']
- //img[@alt='ZennoLab logo']
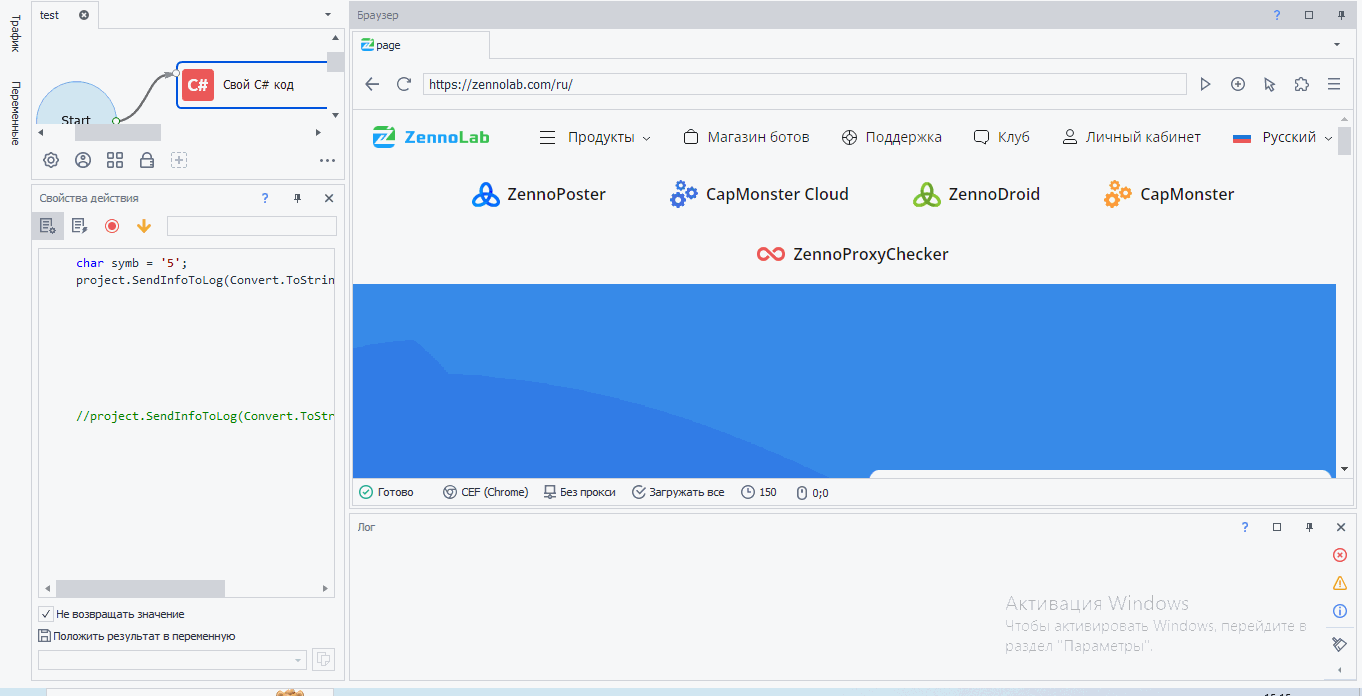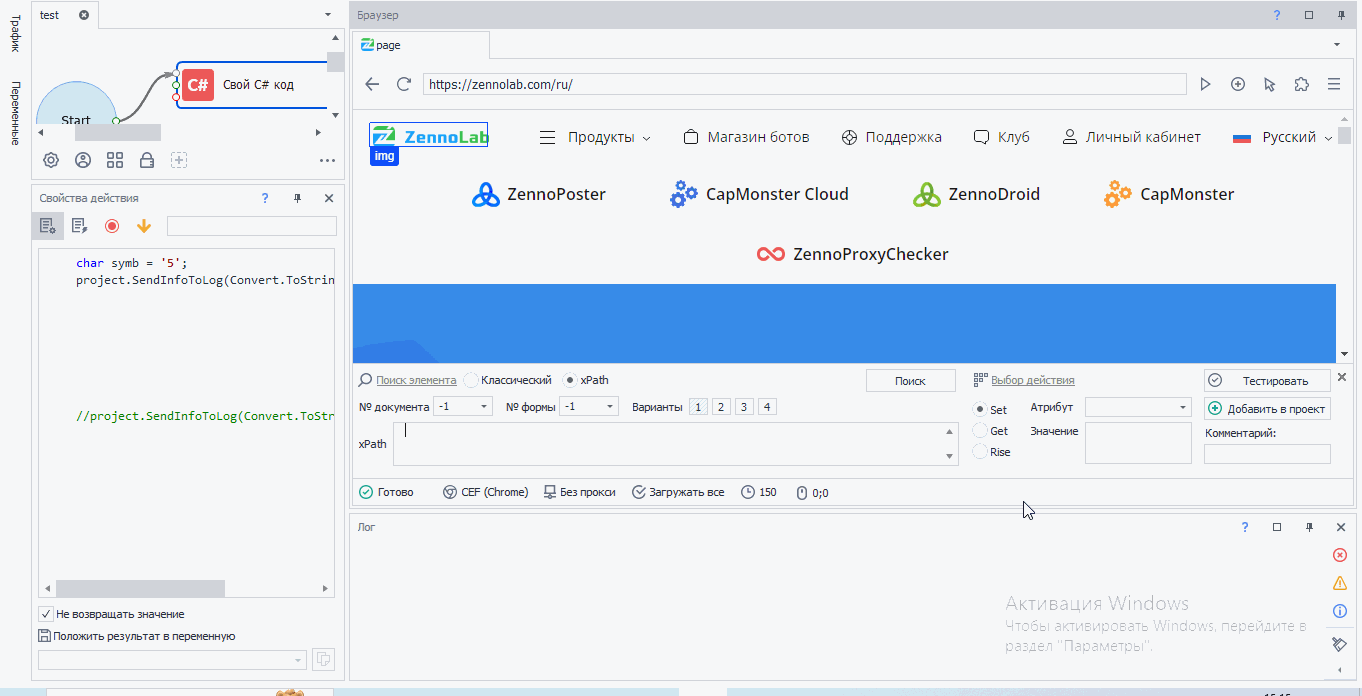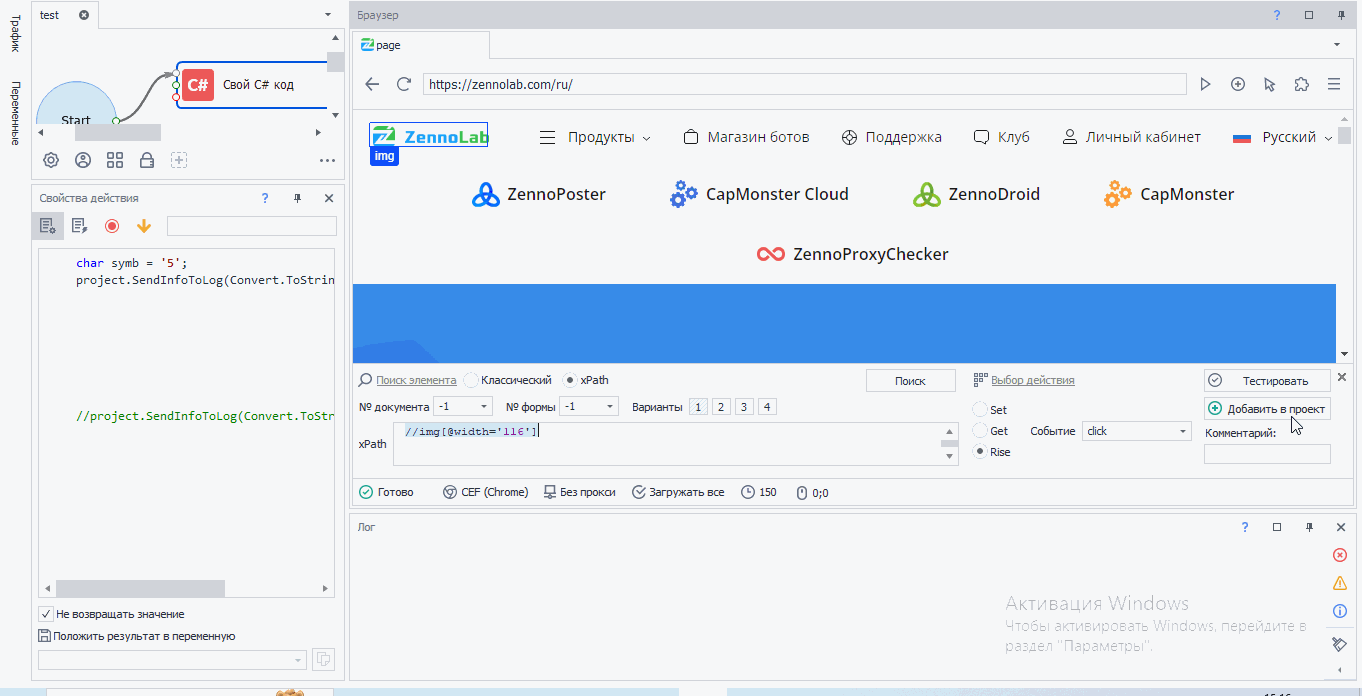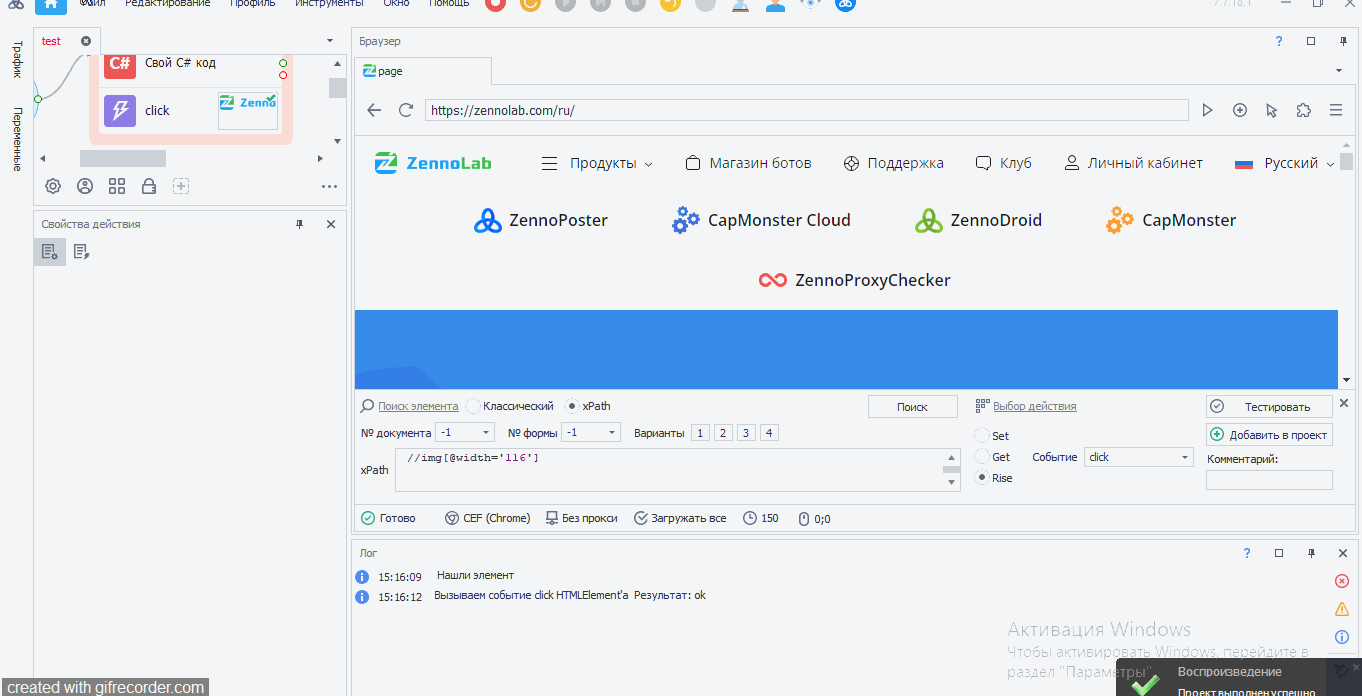
Первые три xpath пути выдали нам один элемент. Значит, по идее мы можем использовать любой из них. Давайте кликнем по логотипу. Как обычно вызываем конструктор действий, но тип поиска ставим xpath и вставляем туда наш xpath путь
Как я и сказал, по идее можно использовать любой из трех xpath путей. Но подбирать надо стараться такой, который с наименьшей вероятностью изменится.
Выбираем элемент по номеру
Как и в случае с поиском по атрибутам, если было найдено несколько элементов, мы можем выбрать конкретный по номеру. Для этого нужно наш xpath обернуть в круглые скобки и в квадратных указать номер. Формула такая:
(//тэг[@названиеАтрибута='значениеАтрибута'])[номер]
Вот по этому xpath мы с вами получили два результата: //img[@alt='ZennoLab logo']
Давайте выберем первый:
(//img[@alt='ZennoLab logo'])[1]
Мы также можем указать, что нам нужен последний найденный элемент. Для этого вместо конкретной цифры прописываем функцию last()
(//img[@alt='ZennoLab logo'])[last()]
А вот так предпоследний
(//img[@alt='ZennoLab logo'])[last()-1]
Поиск по тексту
С помощью xpath можно искать по тексту элемента. Формула:
//тэг[text()='значениеАтрибута']
Давайте найдем элемент, у которой текст "ZennoPoster":
//span[text()='ZennoPoster']
Имейте ввиду, что если сайт мультиязычный, то поиск по тексту у вас может поломаться, если вы решите перейти с ру прокси на бурж.
Содержит текст
Выше мы с вами рассматривали случаи точного совпадения текста. Но мы также можем искать и по части текста. Формула
//тэг[contains(@названиеАтрибута, значениеАтрибута)]
Пример поиска картинки на главной
//img[contains(@alt, 'banner')]
Если бы надо было искать по части текста, то наш xpath был бы примерно такой (на примере верхнего меню):
//span[contains(text(), 'Продукты')]
Несколько условий
До этого момента мы использовали с вами только одно условие. Но мы можем использовать с вами сразу несколько условий с помощью and, or. And у нас проверяет, чтобы сразу несколько атрибутов соответствовали условию, а or чтобы хотя бы один из атрибутов тэга совпадал по условию.
Формула:
//тэг[@названиеАтрибута='значениеАтрибута' and @названиеАтрибута='значениеАтрибута' and @названиеАтрибута='значениеАтрибута']
или
//тэг[@названиеАтрибута='значениеАтрибута' or @названиеАтрибута='значениеАтрибута']
Никто не запрещает и совмещать and и or.
Примеры
//img[@width='116' and @height='22']
Т.е. в данном случае у тэга <img> обязательно должен быть атрибут width со значением 116 и атрибут height со значением 22.
//a[contains(@href, 'discussion' ) or text()='Клуб']
В этом же случае у нас тэг <a> либо в атрибуте href должен содержать discussion или же должен иметь текст "Клуб".
Отступление
Ниже я рассказываю о функциях, которые сам почти не использовал. Можете их пропустить и переходить к осям, если нет желания перегружать свой мозг
Начинается с …
Работает аналогично contains, но он проверяет, чтобы начало точно совпадало с тем, что вы указали. Формула:
//тэг[starts-with(@названиеАтрибута, значениеАтрибута)]
Например:
//span[starts-with(text(), 'Проду')]
Условие not
До этого мы с вами рассматривали варианты "атрибут равен" или "текст равен". Но мы также можем указать и "не равен". Обычно это может быть полезно в связке с другими приемами, об этом ещё поговорим. Формула:
//тэг[@названиеАтрибута!='значениеАтрибута']
или
//тэг[not(contains(@названиеАтрибута, 'значениеАтрибута'))]
Например:
//img[@src!='header']
//img[not(contains(@src, 'header'))]
Сейчас вам может показаться это бессмысленным, т.к. количество найденных тэгов по таким условиям будет очень большим. Но как я писал выше, данная функция используется в связке с другими.
Количество тэгов внутри элемента
Пускай есть вот такая страничка:
C#:
<p>
<a href="#">1</a>
<a href="#">2</a>
<a href="#">3</a>
</p>
<p>
<a href="#">1</a>
<a href="#">2</a>
<a href="#">3</a>
<a href="#">4</a>
<a href="#">5</a>
</p>//p[count(a)=3]
Помимо знака равно вы можете использовать !=, >, <.
Длина содержимого тэга
Мы можем проверять длину содержимого тэга. Вот пример того, как можно найти <span>, чья длина будет ровно 11 символов
//span[string-length()=11]
Поиск по части атрибута
Бывает такое, что часть значения атрибута может быть динамической, т.е. меняться при каждой перезагрузке страницы. Мы это можем обходить с помощью contains, но что если мы хотим более точно задать что искать. В этом случае можно использовать функцию substring.
//span[substring(@class, '5','4')=asfa] – вернет span, у которых класс, начиная с пятого символа 4 символа равны asfa
Оси
Ось child
Ось child
Всё, о чём мы говорили выше, на самом деле не так сильно отличается от поиска по атрибуту. Ведь в атрибутах нам доступен такой мощный инструмент, как регулярные выражения, а в xpath такого нет. Но у xpath есть одно большое преимущество – мы можем гулять от одного тэга к другому. Давайте я поясню.
Пускай есть вот такая разметка, и мы хотим нажать по второму <button>
C#:
<div id='btn1'>
<button>Кнопка</button>
</div>
<div id='btn2'>
<button>Кнопка</button>
</div>Но что мы тут видим? Мы видим, что наши <button> находятся внутри <div>. Первый <button> внутри тэга <div id='btn1'>, а второй <div id='btn2'>. Мы можем привязаться к div по атрибуту, а от него уже спуститься к нужному тэгу <a>. Делается это так:
//div[@id='btn2']/button
Т.е. чтобы нам "спуститься" на одну ступеньку вниз (к "ребенку атрибута") достаточно поставить слэш и указать название того тэга, что нам нужен. Помните, что у "родителя" может быть множество таких "детей", поэтому мы можем уточнять путь с помощью всех приемов, описанных выше.
Давайте вернемся на zennolab.com и потренируемся. Сначала я ещё раз заострю внимание на том, кто именно является "детьми".
Вот например у первого тэга <head> столько "детей". Например, нас интересует <meta name="description">. Тогда мы могли бы прописать xpath путь так:
//head/meta[@name='description']
Спускаться таким образом "по ступенькам" можно сколь угодно глубоко. Давайте найдем вот этот элемент, начиная с тэга <section>
//section[@id='product-menu']/div/nav/a/p/span[contains(text(), 'ZennoDroid')]
Ось Parent
Ранее мы с вами "спускались" по одной ступеньке вниз. Точно также мы можем "подниматься наверх" (т.е. к родителю), используя ось parent. Делается это так:
//head/parent::html
Т.е. в данном случае мы начали с тэга <head>, а затем поднялись к его родителю <html>.
Чуть выше мы с вами от <section> опустились к <span> ZennnoDroid. Давайте проделаем обратную операцию, т.е. поднимемся от <span> ZennnoDroid к <section>
//span[contains(text(), 'ZennoDroid')]/parent::p/parent::a/parent::nav/parent::div/parent::section[@id='product-menu']
Если вам не требуется указывать конкретный тэг, то можно использовать более краткую запись:
//span[contains(text(), 'ZennoDroid')]/../../../../parent::section[@id='product-menu']
Ось descendant
Смотрите, вот такие длинные пути, как мы с вами прописывали выше, это не есть гуд. Я просто приводил их как пример. Обычно мы опускаемся или поднимаемся буквально на 1-3 уровня. Т.к. если админ решит добавить какой-то тэг, то наш путь сразу поломается.
Но случаи, когда "нормальный" тэг находится достаточно далеко от того, что нам нужен, бывает довольно часто (особенно во всяких соц сетях). В этом случае нам поможет ось descendant. Прописывая её, мы говорим, что нас интересуют все элементы потомки данного тэга.
Давайте возьмём такую разметку:
C#:
<div id="main">
<div>
<div>
<div>
<div>
<span></span>
</div>
</div>
</div>
</div>Если мы просто напишем
//span
То на реальной странице результатов будет очень много.
Если мы напишем
//div[@id='main']/div/div/div/div/span
То путь получается довольно длинным, что рискованно. Используя descendant, мы делаем так:
//div[@id='main']/descendant::span
Т.е. нас интересуют все потомки <span> (дети, внуки, правнуки и т.д.) тэга //div[@id='main'].
Возвращаемся на zennolab. Давайте сократим этот путь до адекватного
//section[@id='product-menu']/div/nav/a/p/span[contains(text(), 'ZennoDroid')]
//section[@id='product-menu']/descendant::span[contains(text(), 'ZennoDroid')]
Есть также краткая запись. Вместо слова descendant можно просто поставить //
//section[@id='product-menu']//span[contains(text(), 'ZennoDroid')]
Ось ancestor
Аналогична descendant, только движемся мы наверх. Т.е. она захватывает всех предков ("папу, деда, прадеда"). Перепишем вот этот путь
//span[contains(text(), 'ZennoDroid')]/parent::p/parent::a/parent::nav/parent::div/parent::section[@id='product-menu']
//span[contains(text(), 'ZennoDroid')]/ancestor::section[@id='product-menu']
Ось following-sibling
Данная ось нужна нам для элементов, которые находятся на одном уровне. Образно говоря, для "младших братьев". Посмотрим на такую разметку:
C#:
<div id="main">
<div>
<span></span>
<span id="1"></span>
<span></span>
<span></span>
</div>
</div>//span[@id='1']/following-sibling::span[last()]
Ось Following-sibling берет именно тех братьев, что "ниже" изначально указанного тэга. Т.е. вот этих (красный цвет), но не этого (белый цвет).
Номер нужного нам "брата" указываем в квадратных скобках, если это необходимо [] (в примере выше мы вместо номера использовали функцию last()).
Пример пути для zennolab.com (берем последнююю ссылку внутри блока section[@id='product-menu'])
//section[@id='product-menu']//following-sibling::a[last()]
Ось preceding-sibling
Она аналогично предыдущей, только ищет тех, что предшествуют текущему ("старших братьев"). Возвращаясь к предыдущему примеру, мы можем добратсья до самого первого <span> таким образом:
//span[@id='1']/preceding-sibling::span
Т.е. мы сначала "зацепились" к <span>, у которого id='1', а затем сказали, что нас интересуют все "старшие братья" <span>
Оси following и preceding
Их я на практике не использовал. Даю описание с wikipedia
Ось following содержит множество элементов, расположенных ниже текущего элемента по дереву (на всех уровнях и слоях), исключая собственных потомков.
Ось preceding содержит множество элементов, расположенных выше текущего элемента по дереву (на всех уровнях и слоях), исключая множество собственных предков.
Прочие моменты
Давайте теперь расскажу о тех моментах, что остались "за кадром".
Вам не обязательно указывать название тэга. Вы можете воспользоваться * чтобы указать, что вас устраивает любой тэг. Например:
//*[@id='1234']
Вам не обязательно указывать значение атрибута. Вы можете просто сказать, что у элемента должен быть такой-то атрибут с любым значением. Делается это вот так:
//a[@href]
Иногда бывает, что тэг на странице есть, но когда мы составляем xpath, то он не ищется. Обычно это когда используются какие-то редкие тэги (или вовсе кастомные). В таких ситуациях нам следует использовать функцию name(), в которой мы и указываем название тэга (в примере ниже это тэг <svg>).
//*[name()='svg']
Вы можете указать несколько xpath путей через |. Иногда это бывает полезно. Пример:
//div[@id='1234']|//span[@id='1234']
Вы можете уточнить путь до элемента внутри []. Что я имею ввиду. Посмотрите на картинку
Предположим, нам нужен вот этот вот <div>, но у него какой-то непонятный class и всё. В таком случае мы можем сказать, что нам нужен <div>, у которого есть ребенок <h2> с текстом "ZennoPoster"
//div[h2[text()='ZennoPoster']]
Т.е. надо просто поставить [] и внутри прописать дополнительные условия, кто должен быть у него в предках. Можно использовать любые оси:
//div[descendant::h2[text()='ZennoPoster']]
Вы не сможете найти элемент, который внутри shadow dom. Это встречается редко, но об этом следует знать. Стандартный поиск по тэгу у вас тоже не сработает. Давайте посмотрим пример на https://www.ea.com/sports. Если вам нужно будет кликнуть по верхнем элементам меню, то ничего не выйдет. Посмотрите на код:
Видите надпись "shadow-root"? Если нужный вам элемент внутри него, то значит кликнуть стандартными средствами не выйдет. Что же делать? Если вы видите надпись open, то можно кликнуть через js. Если же будет надпись closed, то только поиском по картинке.
В видео я покажу вам, как использовать xpath в кубике c#.
