


все страницы сайта
- Автор темы desided
- Дата начала
zortexx
Client
- Регистрация
- 19.09.2011
- Сообщения
- 2 520
- Благодарностей
- 1 226
- Баллы
- 113
Парсите с входной страницы (например с домена) все ссылки в список (массив), переходите по всем ссылкам и добавляйте в список найденные на других страницах ссылки в тот же список.
Для посещенных страниц создайте отдельный список и сверяйтесь по нему - все ли ссылки посетили.
Для посещенных страниц создайте отдельный список и сверяйтесь по нему - все ли ссылки посетили.
doc
Client
- Регистрация
- 30.03.2012
- Сообщения
- 8 685
- Благодарностей
- 4 652
- Баллы
- 113
Можно просто удалять дубли. При условии, конечно, что дубли удаляются с конца списка, а не с началаДля посещенных страниц создайте отдельный список и сверяйтесь по нему - все ли ссылки посетили.
zortexx
Client
- Регистрация
- 19.09.2011
- Сообщения
- 2 520
- Благодарностей
- 1 226
- Баллы
- 113
Не имеет смысла, поскольку порождает кучу лишних телодвижений.Можно просто удалять дубли. При условии, конечно, что дубли удаляются с конца списка, а не с начала
doc
Client
- Регистрация
- 30.03.2012
- Сообщения
- 8 685
- Благодарностей
- 4 652
- Баллы
- 113
т.е. сверятся после парсинга - это не лишние телодвижения, а удалять дубли - лишние. интересно)Не имеет смысла, поскольку порождает кучу лишних телодвижений.
zortexx
Client
- Регистрация
- 19.09.2011
- Сообщения
- 2 520
- Благодарностей
- 1 226
- Баллы
- 113
Для начала покажите ваш вариант алгоритма "с удалением дублей из конца списка".т.е. сверятся после парсинга - это не лишние телодвижения, а удалять дубли - лишние. интересно)
Мой без детализации выглядит примерно так:
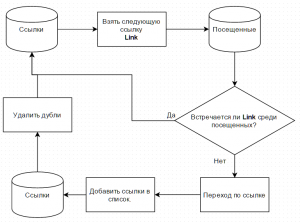
doc
Client
- Регистрация
- 30.03.2012
- Сообщения
- 8 685
- Благодарностей
- 4 652
- Баллы
- 113
Оно то на то и выходит. Парсим ссылки, добавляем в список, удаляем дубли, отрабатываем список.
Просто этот вариант будет работать только при условии, что в стандартном методе удаления дублей со списка удаление идет с конца.
Т.е. если мы имеем список "1,2,3,1" нужно, чтобы при удаление дублей остался список "1,2,3". Я никогда не вникал, как оно работает.
Такой вариант заменит одной строкой цикл проверки
Просто этот вариант будет работать только при условии, что в стандартном методе удаления дублей со списка удаление идет с конца.
Т.е. если мы имеем список "1,2,3,1" нужно, чтобы при удаление дублей остался список "1,2,3". Я никогда не вникал, как оно работает.
Такой вариант заменит одной строкой цикл проверки
ИМХО задача обойти все страницы сайта средствами ZP часто схоже на забивание гвоздей микроскопом.
Но вроде алгоритм простой:
Чтобы не запутаться ведем несколько списков:
1- адреса спарсенные с текущей страницы
2- адреса с посещенными (читай пропарсенными) страницами
3- запланированные на парсинг
Дальше все логично и по порядку:
1 Собрали локальные адреса с текущей страницы в первый список.
2 Прошлись по первому списку перебрав адреса: взяли адрес с 1 списка, проверили на наличие его во втором списке, если есть - удаляем берем следующий, если нет - добавляем его в третий список и переходим к новой строке.
3 Закончив перебор строк первого списка, чистим от дублей третий, на случай если мы добавили туда то что там уже было.
4(0) берем (естественно с удалением) новый адрес с третьего списка, переходим по нему и добавляем этот адрес во второй список .
Кстати, очень не хватает в стандартных функциях ZP Операции над списком
такого простого пункта как "найти в списке", приходится через C#
Но вроде алгоритм простой:
Чтобы не запутаться ведем несколько списков:
1- адреса спарсенные с текущей страницы
2- адреса с посещенными (читай пропарсенными) страницами
3- запланированные на парсинг
Дальше все логично и по порядку:
1 Собрали локальные адреса с текущей страницы в первый список.
2 Прошлись по первому списку перебрав адреса: взяли адрес с 1 списка, проверили на наличие его во втором списке, если есть - удаляем берем следующий, если нет - добавляем его в третий список и переходим к новой строке.
3 Закончив перебор строк первого списка, чистим от дублей третий, на случай если мы добавили туда то что там уже было.
4(0) берем (естественно с удалением) новый адрес с третьего списка, переходим по нему и добавляем этот адрес во второй список .
Кстати, очень не хватает в стандартных функциях ZP Операции над списком
такого простого пункта как "найти в списке", приходится через C#

doc
Client
- Регистрация
- 30.03.2012
- Сообщения
- 8 685
- Благодарностей
- 4 652
- Баллы
- 113
это всё делается одним списком)ИМХО задача обойти все страницы сайта средствами ZP часто схоже на забивание гвоздей микроскопом.
Но вроде алгоритм простой:
Чтобы не запутаться ведем несколько списков:
1- адреса спарсенные с текущей страницы
2- адреса с посещенными (читай пропарсенными) страницами
3- запланированные на парсинг
Дальше все логично и по порядку:
1 Собрали локальные адреса с текущей страницы в первый список.
2 Прошлись по первому списку перебрав адреса: взяли адрес с 1 списка, проверили на наличие его во втором списке, если есть - удаляем берем следующий, если нет - добавляем его в третий список и переходим к новой строке.
3 Закончив перебор строк первого списка, чистим от дублей третий, на случай если мы добавили туда то что там уже было.
4(0) берем (естественно с удалением) новый адрес с третьего списка, переходим по нему и добавляем этот адрес во второй список .
Кстати, очень не хватает в стандартных функциях ZP Операции над списком
такого простого пункта как "найти в списке", приходится через C#
zortexx
Client
- Регистрация
- 19.09.2011
- Сообщения
- 2 520
- Благодарностей
- 1 226
- Баллы
- 113
Можете расписать как вы это собираетесь делать одним списком?это всё делается одним списком)
Полагаю не только ТС будет рад изучить пример реализации вашего варианта с одним списком в шаблоне.
Dimionix
Moderator
- Регистрация
- 09.04.2011
- Сообщения
- 3 068
- Благодарностей
- 3 133
- Баллы
- 113
С одним списком норм вариант. Берем из списка по счетчику > парсим в этот же список > удаляем дубли > опять берем по счетчику. Как только взять будет нечего (ошибка - индекс за пределами диапазона) = профит.Можете расписать как вы это собираетесь делать одним списком?
Полагаю не только ТС будет рад изучить пример реализации вашего варианта с одним списком в шаблоне.
doc
Client
- Регистрация
- 30.03.2012
- Сообщения
- 8 685
- Благодарностей
- 4 652
- Баллы
- 113
именно)С одним списком норм вариант. Берем из списка по счетчику > парсим в этот же список > удаляем дубли > опять берем по счетчику. Как только взять будет нечего (ошибка - индекс за пределами диапазона) = профит.
 Ну если дубли удаляются с конца списка, то соглашусь, что такой вариант выглядит гораздо проще.
Ну если дубли удаляются с конца списка, то соглашусь, что такой вариант выглядит гораздо проще. 