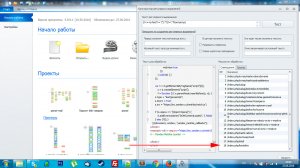
Столкнулся еще с одной проблемой... Попытался сам составить регулярное выражение и вроде регулярка должна работать как надо, но...
Задача состоит в следующем:
Имеется DOM дерево сайта. При помощи регулярного выражения нужно:
1. найти вот такую конструкци <a href="/index.php/kontakty" >Контакты</a> то есть весь тег с текстом "Контакты".
2. сохранить результат работы в переменную и при помощи регулярки получить url адрес (с этим этапом проблем не возникает, поэтому его пропускает)
Проблема с этапом №1
Я написал регулярное выражение:
(<a .+?>)Контакты(</[ ]?a>)
И как мне казалось, все должно было работать. Но нет
 :-)")
Находится куча ссылок вместо одной нужно при этом в них нет текста "Контакты", но они все равно находятся...
DOM дерево брал с этого сайта auto-pokrasim точка ru
Сюда файл с DOM загрузить не получилось.
Где я ошибся?
И возможно ли сделать регулярку более универсальной, к примеру если "Контакты" будут расположены вот так:
<a href="/index.php/kontakty" ><span class="test">Контакты</span></a>