



- Регистрация
- 25.12.2011
- Сообщения
- 284
- Благодарностей
- 23
- Баллы
- 18
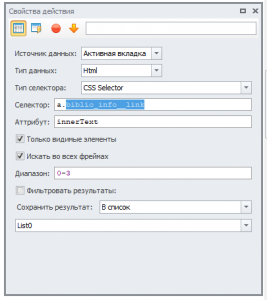
занимаюсь шаблоном парсера litres.ru , застрял на таком моменте, нужно вытащить названия жанров в список, проблема в том что первая буква идет через тег span.
подскажите как грамотно вытащить названия жанров из такой разметки ?
<li><strong>Жанр:</strong> <a href="/knigi-priklucheniya/priklucheniya_knigi/" class="biblio_info__link"><span class="uppercase">к</span>ниги о приключениях</a>, <a href="/knigi-fentezi/lubov/" class="biblio_info__link"><span class="uppercase">л</span>юбовное фэнтези</a>, <a href="/knigi-uzhasy-mistika-trillery/mistika/" class="biblio_info__link"><span class="uppercase">м</span>истика</a>, <a href="/knigi-lubovnye-romany/ostrosyuzhetnyye/" class="biblio_info__link"><span class="uppercase">о</span>стросюжетные любовные романы</a></li>
подскажите как грамотно вытащить названия жанров из такой разметки ?
<li><strong>Жанр:</strong> <a href="/knigi-priklucheniya/priklucheniya_knigi/" class="biblio_info__link"><span class="uppercase">к</span>ниги о приключениях</a>, <a href="/knigi-fentezi/lubov/" class="biblio_info__link"><span class="uppercase">л</span>юбовное фэнтези</a>, <a href="/knigi-uzhasy-mistika-trillery/mistika/" class="biblio_info__link"><span class="uppercase">м</span>истика</a>, <a href="/knigi-lubovnye-romany/ostrosyuzhetnyye/" class="biblio_info__link"><span class="uppercase">о</span>стросюжетные любовные романы</a></li>


 :-)")