

- Регистрация
- 08.05.2019
- Сообщения
- 441
- Благодарностей
- 177
- Баллы
- 43
Подскажите, плиз...
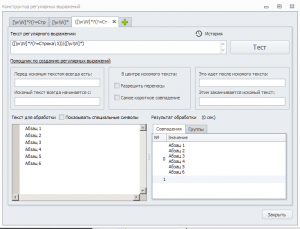
На странице идет вот такой текст:
Абзац 1
Абзац 2
Абзац 3
Абзац 4
Строка Х
Абзац 5
Абзац 6
Мне нужно спарсить текст до Строки Х, т.е. только Абзацы 1-4.
Проблема осложняется тем, что на некоторых страницах может не быть Строки Х, в этом случае нужно спарсить все абзацы.
Иными словами, если есть Строка Х – нужно ее игнорировать, и игнорировать все, что идет за ней; а если Строки Х нет – то нужно парсить все.
В DOM'е у всех абзацев одинаковые теги, т.е. как-то идентифицировать ненужные абзацы вроде как невозможно. Строку Х идентифицировать можно, у нее есть уникальные опознавательные признаки.
Подскажите, как решить такую задачу?
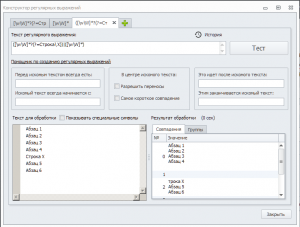
На странице идет вот такой текст:
Абзац 1
Абзац 2
Абзац 3
Абзац 4
Строка Х
Абзац 5
Абзац 6
Мне нужно спарсить текст до Строки Х, т.е. только Абзацы 1-4.
Проблема осложняется тем, что на некоторых страницах может не быть Строки Х, в этом случае нужно спарсить все абзацы.
Иными словами, если есть Строка Х – нужно ее игнорировать, и игнорировать все, что идет за ней; а если Строки Х нет – то нужно парсить все.
В DOM'е у всех абзацев одинаковые теги, т.е. как-то идентифицировать ненужные абзацы вроде как невозможно. Строку Х идентифицировать можно, у нее есть уникальные опознавательные признаки.
Подскажите, как решить такую задачу?

 :-)")
