

- Регистрация
- 13.08.2017
- Сообщения
- 232
- Благодарностей
- 18
- Баллы
- 18
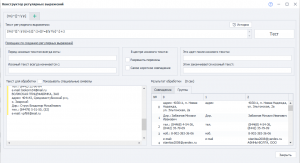
Добрый вечер. Такой вопрос. Подскажите пожалуйста метод, с помощью которого можно будет составить таблицу, из всех параметров.
Сейчас получается большой список. По предприятиям. Где-то присутствует email, где-то нет. Где-то присутствует директор, где-то нет, где-то "ген. директор". И самое главное что во многих местах, например адрес располагается на 2-3 строчках.
Сейчас получается большой список. По предприятиям. Где-то присутствует email, где-то нет. Где-то присутствует директор, где-то нет, где-то "ген. директор". И самое главное что во многих местах, например адрес располагается на 2-3 строчках.
Вложения
-
1,4 КБ Просмотры: 3

 :-)")
