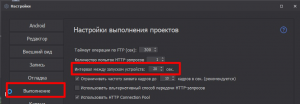
Выше я писал пост конкретно под ситуацию ТС, ведь у него долго запускаются ВМ. Поэтому я предложил оптимизировать ВМ, сделать шаблон в цикле и увеличить тайминги.
Если у вас на каждое выполнение новый запуск ВМ, то нужно отталкиваться уже от производительности железа и количества потоков.
Условно, если у вас 10 потоков и вм запускается быстро, то ставим минимальную задержку.
А если 50 вм в работе, то при низком интервале у вас будет одновременно перезапускаться большое кол-во ВМ, и все это будет тупить, долго прогружаться даже на производительном железе. Представьте условно 40-50 ВМ, которые стартуют одновременно. В таком случае нужно увеличивать интервал, чтобы ВМ запускались поочередно, а не в 1 раз.
Все индивидуально настраивается под каждый проект и возможности железа, тут нет единых стандартов. Но от информации, которую я предоставил ранее (
1,
2) можно уже как-то отталкиваться и подстроить под себя. Если вы нашли для себя более оптимальные настройки, то это на ваше усмотрение. Я ничего не навязываю.