

- Регистрация
- 06.05.2015
- Сообщения
- 210
- Благодарностей
- 97
- Баллы
- 28
Доброго времени форумчане, коллеги и просто прохожие....  ;-)")
Все мы, рано или поздно приходим к многопоточным шаблонам. А с многопотоком обязательно приходит вопрос "КААААК???" организовать ЗАПРЕТ на параллельное использование данных?! Ибо результаты "такого многопотока" никому не нужны...

Предлагаю вашему вниманию своё видение/решение этого вопроса. А вижу и понимаю я это так: если есть 2 "работника" и более, ТО уже нужен старший / управляющий, по другому практически невозможно.
И так есть 2 шаблона болванки: Manager.zp и Worker.zp (далее М и W соответственно), логика работы:
1) W генерирует уник. id_key и сохраняет его в таблицу tb_key нашей БД, с пометкой request. Также в БД сохраняется текущее время в unix формате (время требуется для контроля за ключами).
2) М видя ключ с пометкой request, берёт его и помечает свободные данные со статусом ready, в рабочих таблица tb_accounts и tb_proxy данным ключом + присваивает статус work / выдаёт работу W, и сам id_key помечается как work.
3) W получив "задание" - исполняет его, после чего помечает свой id_key как stop.
4) М видя id_key с пометкой stop, меняет статус данных на chill, а id_key удаляется из таблицы.
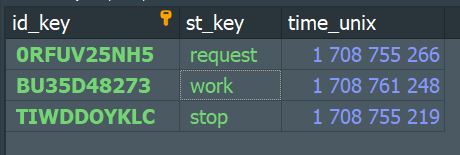


!!! В таблице tb_key, данные столбца id_key помечены как PRIMARY KEY, это означает что даже если будет сгенерирован НЕ уникальный id_key, при попытке его сохранить в БД, сама база данных не позволит этого сделать.
Кроме раздачи заданий Manager.zp:
1) Выдаёт задачи с некоторой задержкой по времени. (полезно для "нагруженных" шаблонов, дабы равномерно распределить пиковые нагрузки, в результате одновременного выполнения которых, можно "положить" всю работу)
2) Удаляет ключи из таблицы tb_key которые небыли удаленны из-за какого либо сбоя.
3) Освобождает данные в таблицах tb_accounts и tb_proxy которые заняты длительное время (в результате каких либо ошибок).
4) Следит чтоб данные "ОСТЫЛИ" некоторое время, после использования.
5) Обеспечивает равномерное использование всех данных, в работу идут первыми данные которые дольше простаивают.
Все тайминги можно регулировать прямо на лету, так как они хранятся в таблице tb_config и подтягиваются по необходимости.
!!! ОБРАТИТЕ ВНИМАНИЕ !!! При задании временных промежутков/таймингов, на соответствующий ему комментарий. Если временные промежутки буду заданы НЕ верно = параллельное использование данных.
Почему именно так?! Потому что после сброса блокировки данных, данные помечаются статусом "ready" (готовы к использованию).
 Для работы шаблону необходимо:
Для работы шаблону необходимо:
1) База данных (у меня установлен Open Server 5.3.7, файл импорта БД приложу)
2) Для подключения к БД во входных настройках шаблона указать: имя БД, IP сервера, имя и пароль пользователя.
3) Дописать шаблоны под себя + заполнить таблицы своими данными.
Для удобной работы с БД можно использовать HeidiSQL (установочный файл в архиве).


Все мы, рано или поздно приходим к многопоточным шаблонам. А с многопотоком обязательно приходит вопрос "КААААК???" организовать ЗАПРЕТ на параллельное использование данных?! Ибо результаты "такого многопотока" никому не нужны...
Предлагаю вашему вниманию своё видение/решение этого вопроса. А вижу и понимаю я это так: если есть 2 "работника" и более, ТО уже нужен старший / управляющий, по другому практически невозможно.
И так есть 2 шаблона болванки: Manager.zp и Worker.zp (далее М и W соответственно), логика работы:
1) W генерирует уник. id_key и сохраняет его в таблицу tb_key нашей БД, с пометкой request. Также в БД сохраняется текущее время в unix формате (время требуется для контроля за ключами).
2) М видя ключ с пометкой request, берёт его и помечает свободные данные со статусом ready, в рабочих таблица tb_accounts и tb_proxy данным ключом + присваивает статус work / выдаёт работу W, и сам id_key помечается как work.
3) W получив "задание" - исполняет его, после чего помечает свой id_key как stop.
4) М видя id_key с пометкой stop, меняет статус данных на chill, а id_key удаляется из таблицы.
!!! В таблице tb_key, данные столбца id_key помечены как PRIMARY KEY, это означает что даже если будет сгенерирован НЕ уникальный id_key, при попытке его сохранить в БД, сама база данных не позволит этого сделать.
Кроме раздачи заданий Manager.zp:
1) Выдаёт задачи с некоторой задержкой по времени. (полезно для "нагруженных" шаблонов, дабы равномерно распределить пиковые нагрузки, в результате одновременного выполнения которых, можно "положить" всю работу)
2) Удаляет ключи из таблицы tb_key которые небыли удаленны из-за какого либо сбоя.
3) Освобождает данные в таблицах tb_accounts и tb_proxy которые заняты длительное время (в результате каких либо ошибок).
4) Следит чтоб данные "ОСТЫЛИ" некоторое время, после использования.
5) Обеспечивает равномерное использование всех данных, в работу идут первыми данные которые дольше простаивают.
Все тайминги можно регулировать прямо на лету, так как они хранятся в таблице tb_config и подтягиваются по необходимости.
!!! ОБРАТИТЕ ВНИМАНИЕ !!! При задании временных промежутков/таймингов, на соответствующий ему комментарий. Если временные промежутки буду заданы НЕ верно = параллельное использование данных.
Почему именно так?! Потому что после сброса блокировки данных, данные помечаются статусом "ready" (готовы к использованию).
1) База данных (у меня установлен Open Server 5.3.7, файл импорта БД приложу)
2) Для подключения к БД во входных настройках шаблона указать: имя БД, IP сервера, имя и пароль пользователя.
3) Дописать шаблоны под себя + заполнить таблицы своими данными.
Для удобной работы с БД можно использовать HeidiSQL (установочный файл в архиве).
- Номер конкурса шаблонов
- Двенадцатый конкурс шаблонов
Вложения
-
21,4 МБ Просмотры: 158
Для запуска проектов требуется программа ZennoPoster или ZennoDroid.
Это основное приложение, предназначенное для выполнения автоматизированных шаблонов действий (ботов).
Подробнее...
Для того чтобы запустить шаблон, откройте нужную программу. Нажмите кнопку «Добавить», и выберите файл проекта, который хотите запустить.
Подробнее о том, где и как выполняется проект.
Последнее редактирование модератором:


 :-)") , про блокировку и c# слышал, знаю... Но нужно знание c#, коих у меня маловато..., а стандартными кубиками блокировки нет, в рамках одного подключения к БД, два и более запроса не выполнить.
, про блокировку и c# слышал, знаю... Но нужно знание c#, коих у меня маловато..., а стандартными кубиками блокировки нет, в рамках одного подключения к БД, два и более запроса не выполнить.