A-Parser Support
Активный пользователь
- Регистрация
- 03.06.2013
- Сообщения
- 344
- Благодарностей
- 32
- Баллы
- 28
Сборник статей #11: анализ содержимого картинок, добавление ссылок в индекс Google и поиск RSS лент
11-й сборник статей, в котором рассказано, как в А-Парсере анализировать содержимое картинок, добавлять страницы своих сайтов в индекс Google и искать RSS ленты необходимой тематики.
Фильтрация картинок по их содержимому
В этой статье на примере поиска картинок с определенным содержимым, показана работа с Google Vision. С помощью "компьютерного зрения" для каждого изображения присваивается набор меток, который описывает содержимое.
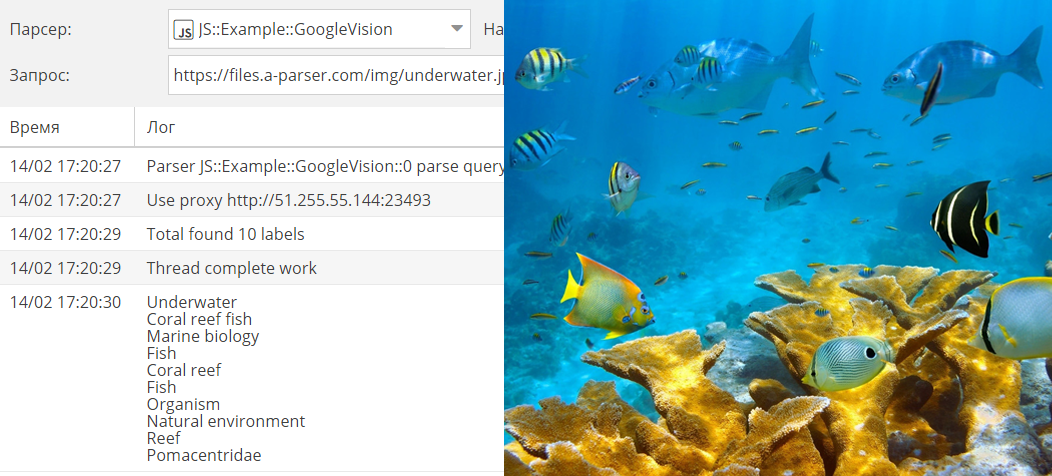
Инструкция по использованию Google Indexing API
В данной статье рассмотрена работа с Google Indexing API, который позволяет владельцам сайтов напрямую уведомлять Google о добавлении или удалении страниц. Таким образом ваш сайт будет быстрее просканирован Google, что способствует повышению качества трафика.
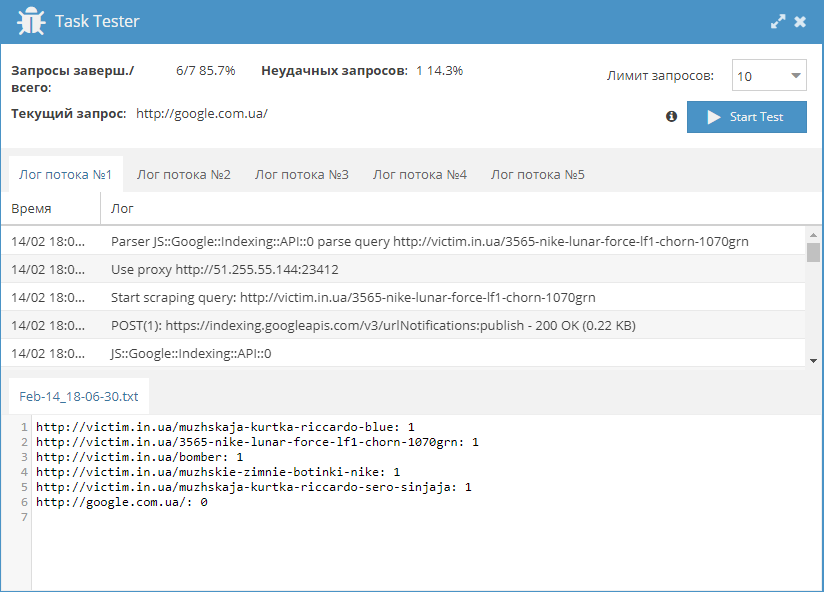
Поиск и сбор rss лент
В этой статье рассмотрен простой пример поиска ссылок на rss ленты по заданной тематике. Решение состоит из 3-х пресетов, каждый из которых отвечает за определенный этап работы.

Если вы хотите, чтобы мы более подробно раскрыли какой-то функционал парсера, у вас есть идеи для новых статей или вы желаете поделиться собственным опытом использования A-Parser (за небольшие плюшки :-)") ) - отписывайтесь здесь.
) - отписывайтесь здесь.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Все сборники статей

11-й сборник статей, в котором рассказано, как в А-Парсере анализировать содержимое картинок, добавлять страницы своих сайтов в индекс Google и искать RSS ленты необходимой тематики.
Фильтрация картинок по их содержимому
В этой статье на примере поиска картинок с определенным содержимым, показана работа с Google Vision. С помощью "компьютерного зрения" для каждого изображения присваивается набор меток, который описывает содержимое.
Инструкция по использованию Google Indexing API
В данной статье рассмотрена работа с Google Indexing API, который позволяет владельцам сайтов напрямую уведомлять Google о добавлении или удалении страниц. Таким образом ваш сайт будет быстрее просканирован Google, что способствует повышению качества трафика.
Поиск и сбор rss лент
В этой статье рассмотрен простой пример поиска ссылок на rss ленты по заданной тематике. Решение состоит из 3-х пресетов, каждый из которых отвечает за определенный этап работы.
Если вы хотите, чтобы мы более подробно раскрыли какой-то функционал парсера, у вас есть идеи для новых статей или вы желаете поделиться собственным опытом использования A-Parser (за небольшие плюшки
) - отписывайтесь здесь.Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Все сборники статей

 SE::Yandex::ByImage
SE::Yandex::ByImage Social::Instagram::post
Social::Instagram::post Util::YandexRecognize
Util::YandexRecognize SE::Yandex::SQI
SE::Yandex::SQI HTML::EmailExtractor
HTML::EmailExtractor SE::Google::Trends
SE::Google::Trends SE::Seznam
SE::Seznam SE::Yandex
SE::Yandex SE::Yandex:: Direct
SE::Yandex:: Direct SE::Bing::LangDetect
SE::Bing::LangDetect Rank::Ahrefs
Rank::Ahrefs SE::Bing
SE::Bing SE::Startpage
SE::Startpage Shop::eBay
Shop::eBay SE::Yahoo
SE::Yahoo  SE::Google::Images
SE::Google::Images Net::HTTP
Net::HTTP
![[IMG]](/discussion/proxy.php?image=https%3A%2F%2Ffiles.a-parser.com%2Fimg%2F1.2.852.png&hash=327fc00b267efb8e8ce3d8387e4ee1b2)




 uckDuckGo
uckDuckGo ost
ost





![[IMG]](/discussion/proxy.php?image=https%3A%2F%2Ffiles.a-parser.com%2Fimg%2Fsite%2Ftg_chat_btn.png%231500&hash=1106770b4841899eb1e681ab6823dc94 "[IMG]")
![[IMG]](/discussion/proxy.php?image=https%3A%2F%2Ffiles.a-parser.com%2Fimg%2FA-Parser__Advanced_SE_Parser_%2526_Analyze_tool_-_Google_Chrome_2020-04-27_11.43.26.png&hash=aa262d01206b6294f6ea986a0a26062f)
![[IMG]](/discussion/proxy.php?image=https%3A%2F%2Ffiles.a-parser.com%2Fimg%2Fdnr3e_200427125510.png&hash=5dc0863d428a5c415b01437e8f1dbd29)
![[IMG]](/discussion/proxy.php?image=https%3A%2F%2Ffiles.a-parser.com%2Fimg%2Ffwrq2_200427130816.png&hash=badc4260386aea9bbd89be4fe45415ee)
![[IMG]](/discussion/proxy.php?image=https%3A%2F%2Ffiles.a-parser.com%2Fimg%2Fbutton_a-parser_small_1500.png&hash=1f06f701f06038601cfd2cbdd8f6343e "[IMG]")