A-Parser Support
Активный пользователь
- Регистрация
- 03.06.2013
- Сообщения
- 344
- Благодарностей
- 32
- Баллы
- 28
Сборник рецептов #20: автообновление цен в ИМ, анализ текстов и регистрация аккаунтов
В 20-м сборнике рецептов наш пользователь glukmaster поделится опытом решения реальной задачи на практике с помощью A-Parser. А также мы будем анализировать тексты и автоматизировать регистрацию аккаунтов Яндекса. Поехали!
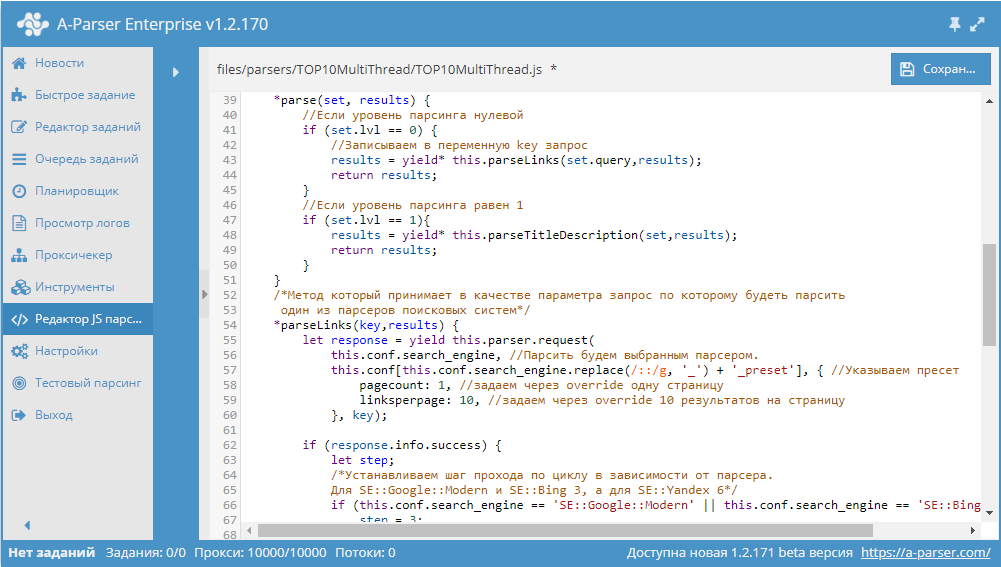
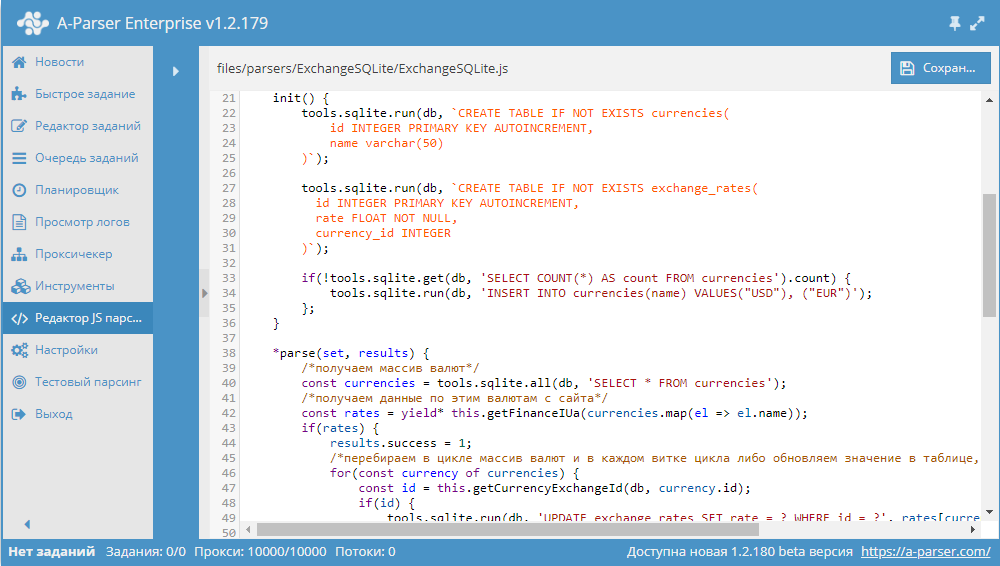
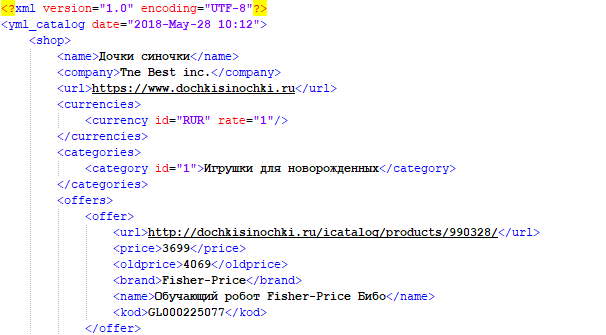
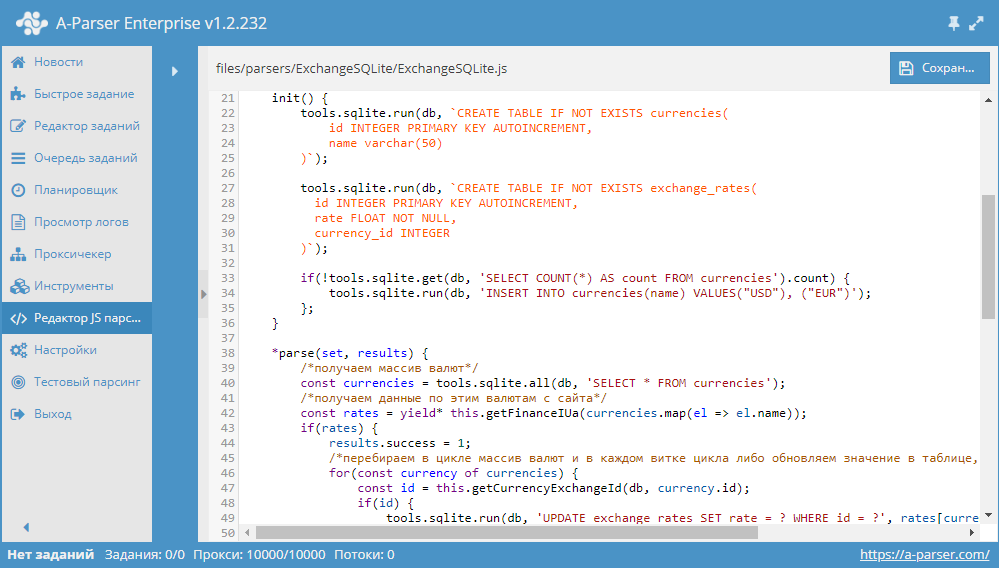
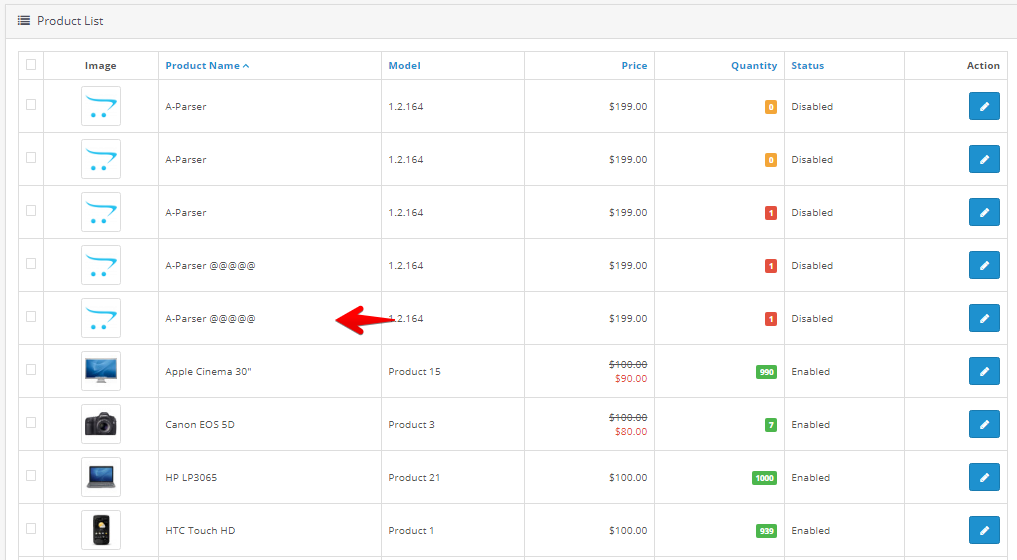
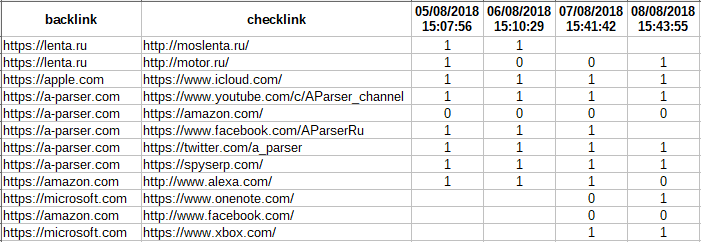
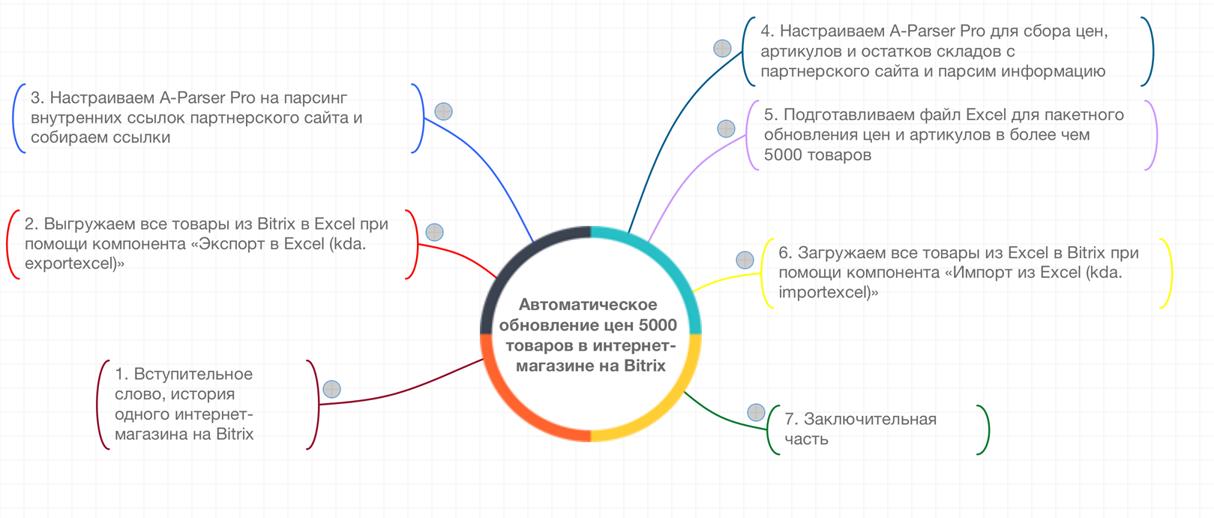
Автоматическое обновление цен 5000 товаров в интернет-магазине на Bitrix
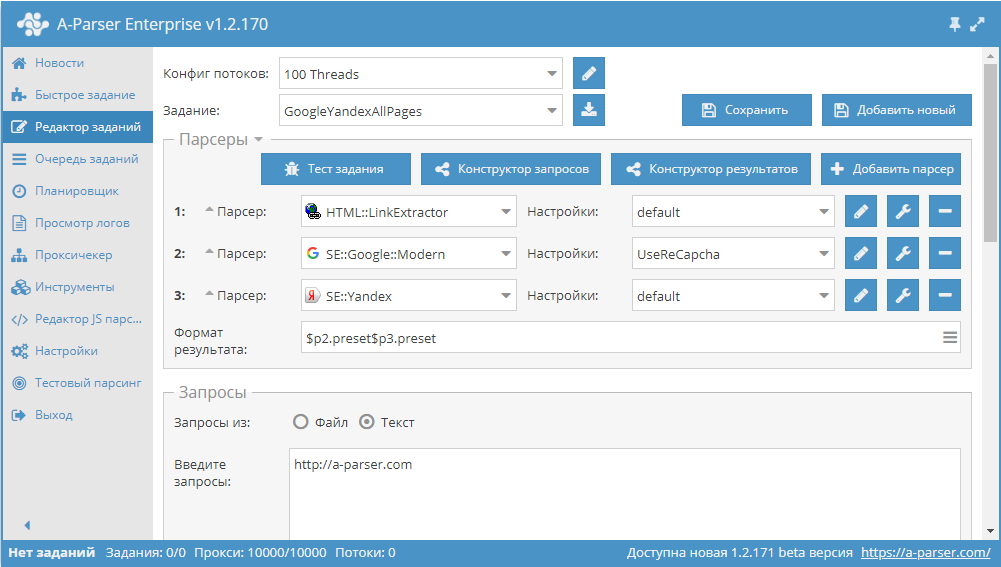
Цикл видео из 7 частей, в которых очень детально и наглядно показано, как решать такую задачу, как обновление цен в интернет магазине. Для парсинга используется A-Parser. Посмотреть видео можно по ссылке выше.
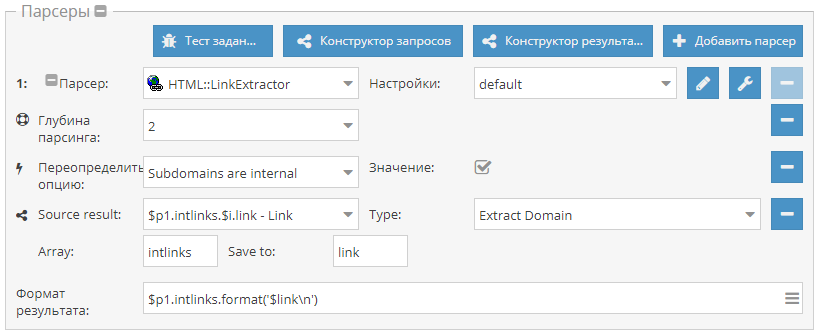
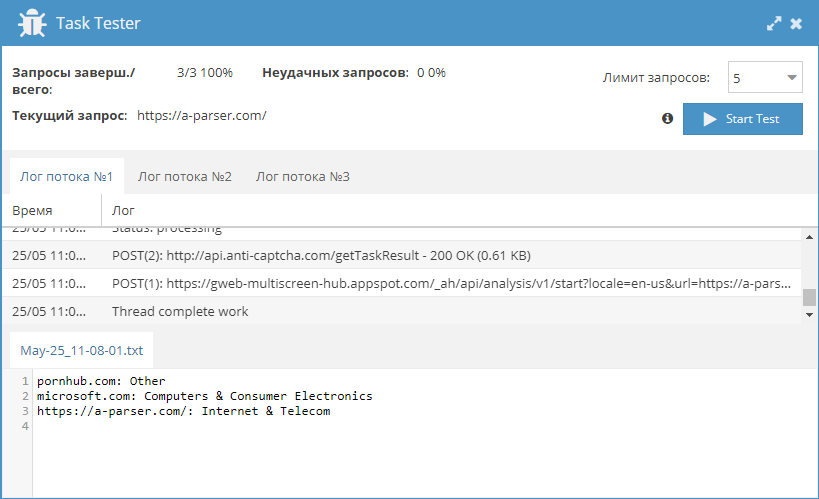
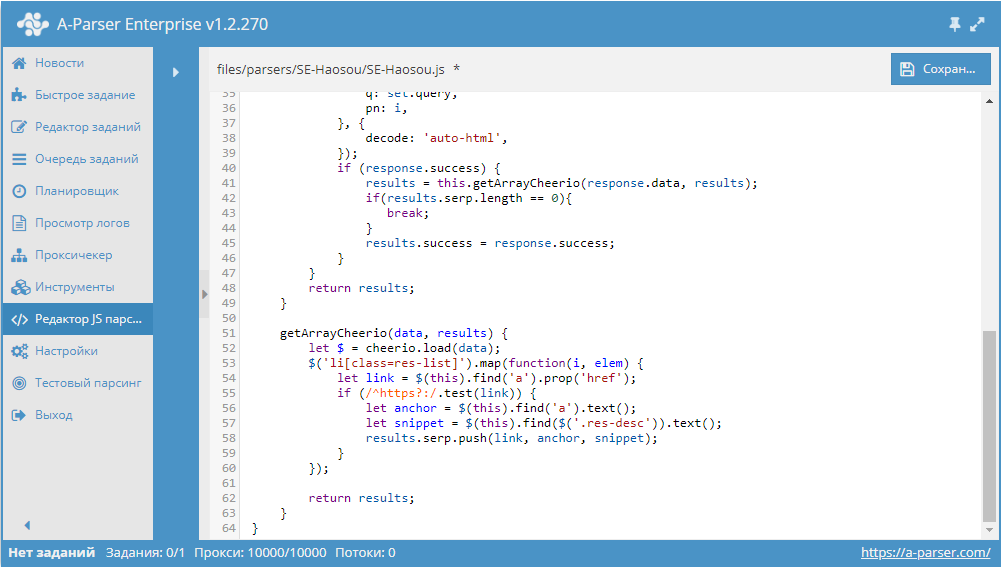
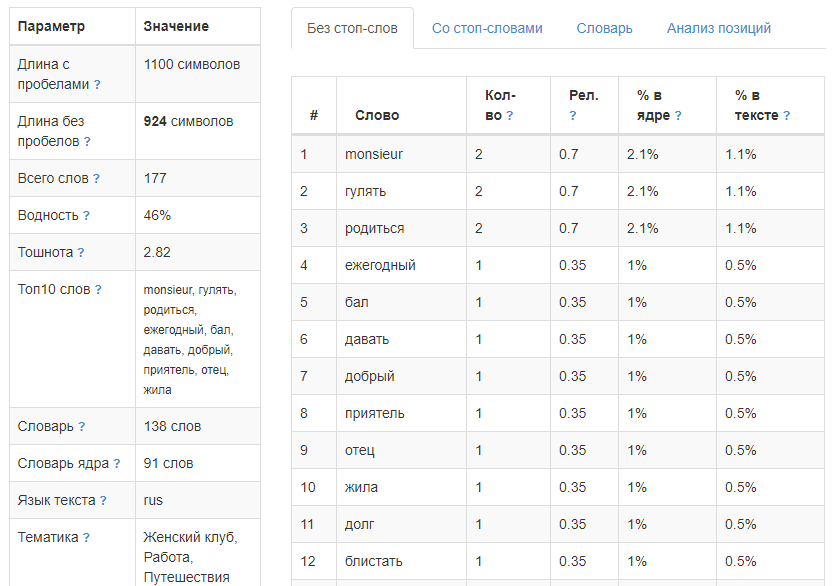
Анализ текста
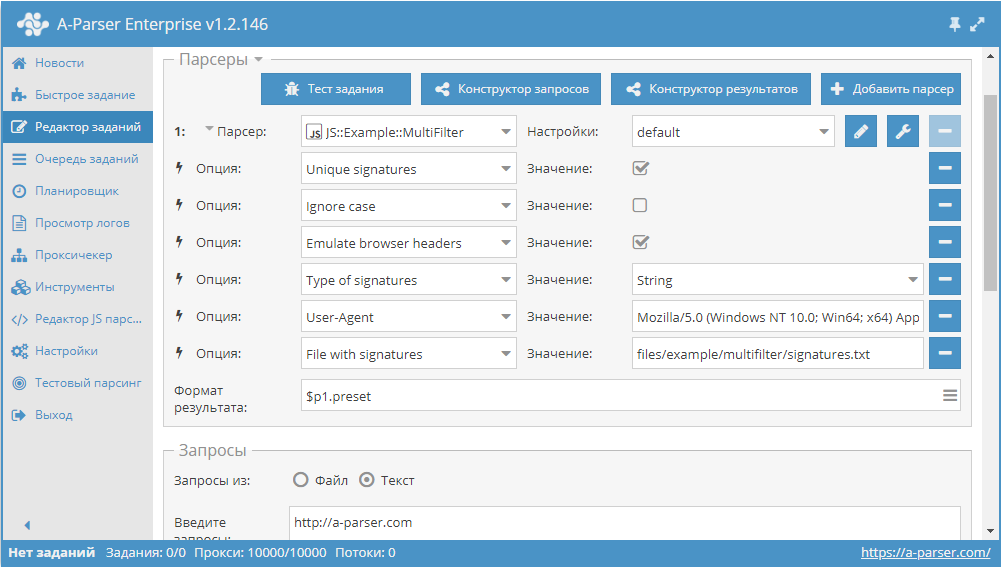
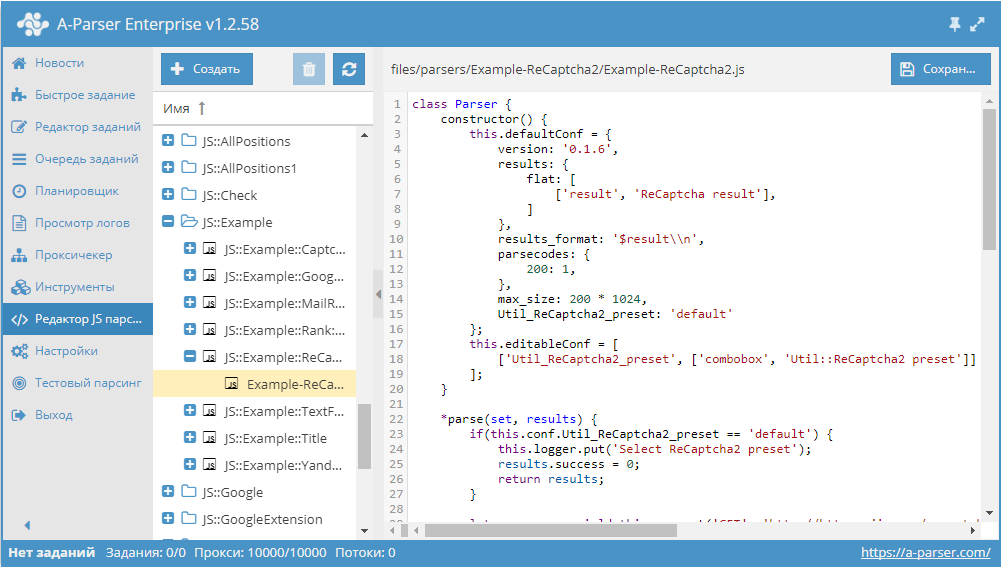
Одним из самых популярных кейсов по применению А-Парсера является парсинг текстов. При этом возникает задача их анализа. Полноценно решить эту задачу позволяют специальные ресурсы. Ранее мы уже публиковали пресет по парсингу одного из таких сервисов. Теперь же это решение полностью переписано в виде JS-парсера, добавлена возможность анализировать не только тексты, а и полностью страницы, т.е. подавать на вход ссылки. Все детали и сам парсер - по ссылке выше.
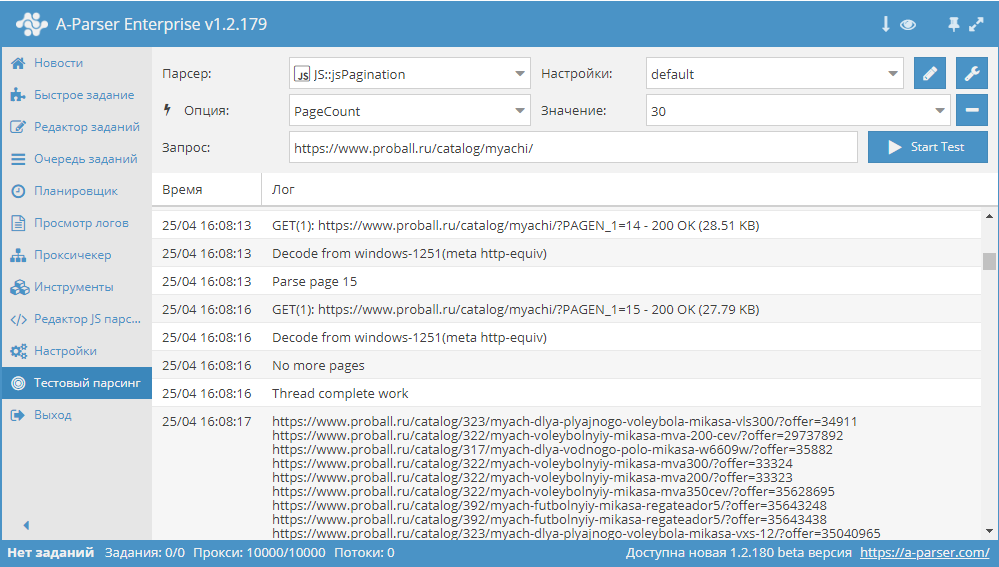
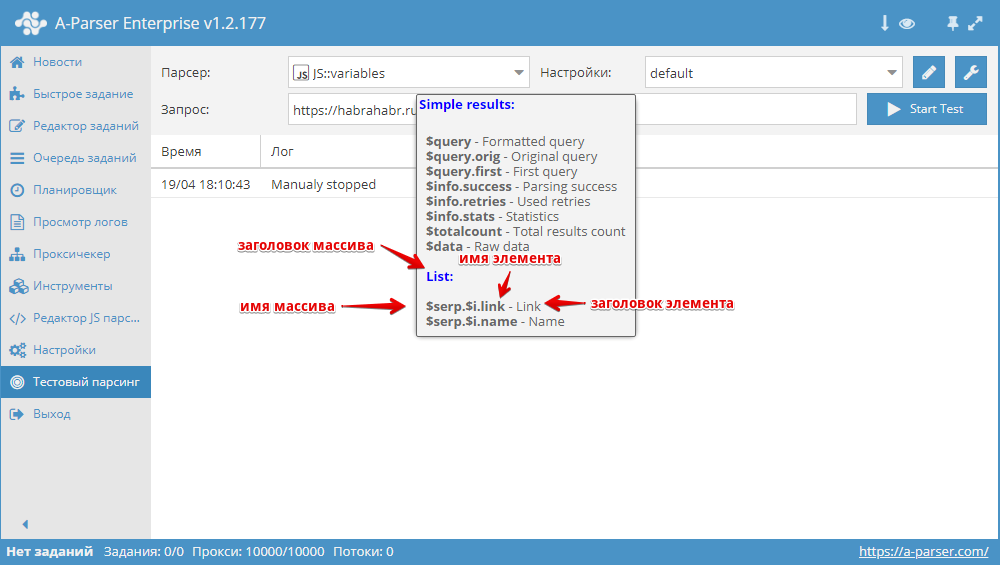
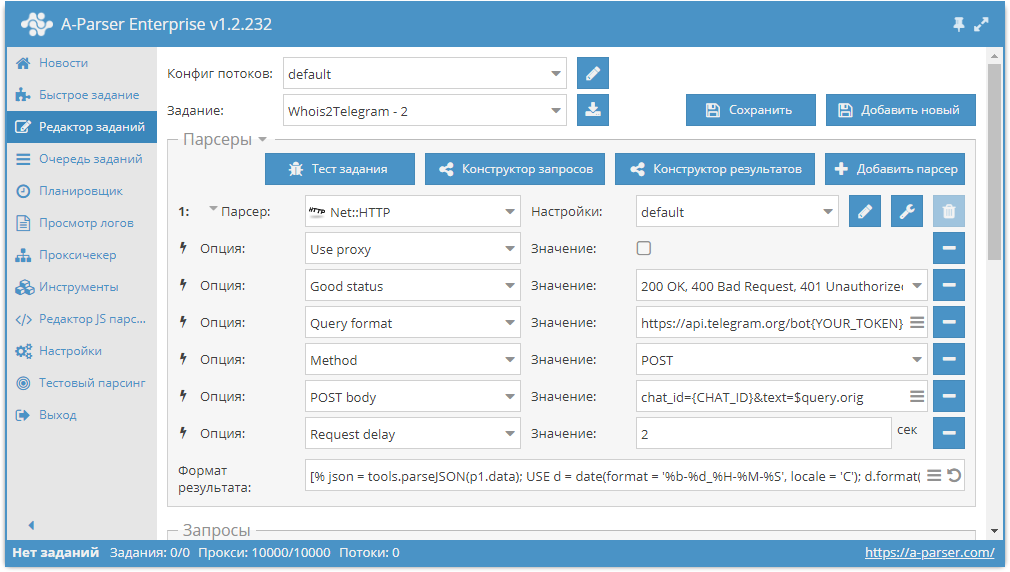
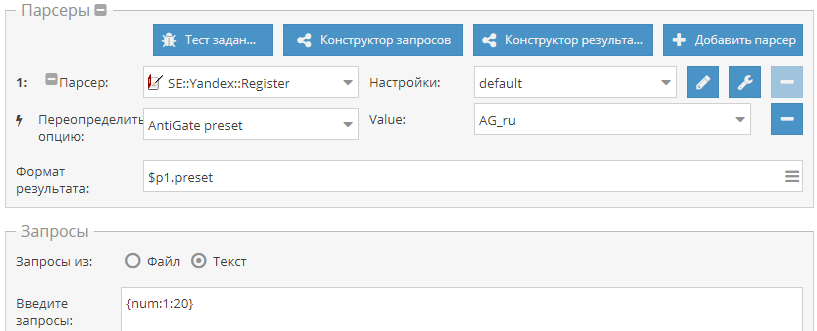
Автоматизация регистрации аккаунтов Яндекса
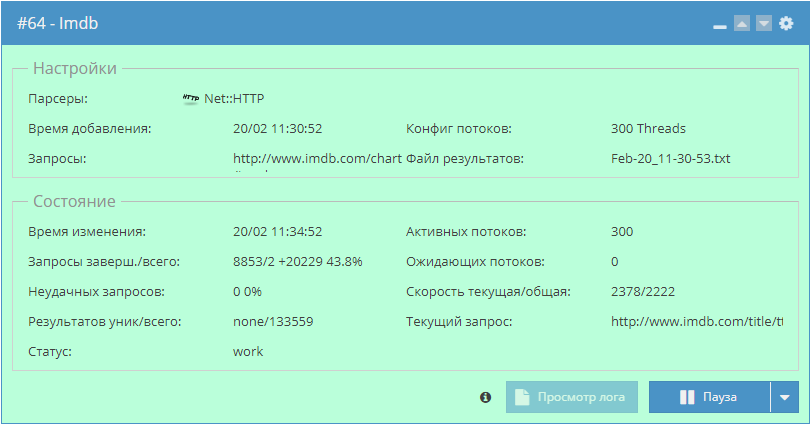
Как известно, для парсинга WordStat нужны аккаунты Яндекса. А-Парсер умеет их регистрировать, но их срок жизни невелик, т.к. спустя 1-2 суток включается проверка номера телефона. Поэтому возникает необходимость периодической регистрации новых аккаунтов. И это можно легко автоматизировать. По ссылке выше показано как это сделать.
Кроме этого:
Еще больше различных рецептов в нашем обновленном Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Предыдущие сборники рецептов:
В 20-м сборнике рецептов наш пользователь glukmaster поделится опытом решения реальной задачи на практике с помощью A-Parser. А также мы будем анализировать тексты и автоматизировать регистрацию аккаунтов Яндекса. Поехали!
Автоматическое обновление цен 5000 товаров в интернет-магазине на Bitrix
Цикл видео из 7 частей, в которых очень детально и наглядно показано, как решать такую задачу, как обновление цен в интернет магазине. Для парсинга используется A-Parser. Посмотреть видео можно по ссылке выше.
Анализ текста
Одним из самых популярных кейсов по применению А-Парсера является парсинг текстов. При этом возникает задача их анализа. Полноценно решить эту задачу позволяют специальные ресурсы. Ранее мы уже публиковали пресет по парсингу одного из таких сервисов. Теперь же это решение полностью переписано в виде JS-парсера, добавлена возможность анализировать не только тексты, а и полностью страницы, т.е. подавать на вход ссылки. Все детали и сам парсер - по ссылке выше.
Автоматизация регистрации аккаунтов Яндекса
Как известно, для парсинга WordStat нужны аккаунты Яндекса. А-Парсер умеет их регистрировать, но их срок жизни невелик, т.к. спустя 1-2 суток включается проверка номера телефона. Поэтому возникает необходимость периодической регистрации новых аккаунтов. И это можно легко автоматизировать. По ссылке выше показано как это сделать.
Кроме этого:
Еще больше различных рецептов в нашем обновленном Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Предыдущие сборники рецептов:
- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для (другой софт), парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
- Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
- Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
- Сборник рецептов #9: проверяем сезонность ключевых слов и их полезность
- Сборник рецептов #10: пишем кастомный парсер поисковика и парсим дерево категорий
- Сборник рецептов #11: парсим Авито, работаем с JavaScript, анализируем тексты и участвуем в акции!
- Сборник рецептов #12: парсим Instagram, собираем статистику и делаем свои парсеры подсказок
- Сборник рецептов #13: сохраняем результат в файл дампа SQL и знакомимся с $tools.query
- Сборник рецептов #14: используем XPath, анализируем сайты и создаем комбинированные пресеты
- Сборник рецептов #15: анализируем скорость и юзабилити сайтов, парсим Яндекс.Картинки и Baidu
- Сборник рецептов #16: парсинг OpenSiteExplorer с авторизацией, Яндекс.Каталога и Яндекс.Новостей
- Сборник рецептов #17: картинки из Flickr, язык ключевых слов, список лайков в ВК
- Сборник рецептов #18: скриншоты сайтов, lite выдача Яндекса и проверка сайтов
- Сборник рецептов #19: публикация сообщений в Wordpress, парсинг Chrome Webstore и AliExpress










 :-)") ) - отписывайтесь
) - отписывайтесь