



Бесплатно напишу регулярное выражение. Часть 2.
- Автор темы LightWood
- Дата начала
cherus09
Client
- Регистрация
- 10.10.2016
- Сообщения
- 172
- Благодарностей
- 14
- Баллы
- 18
Посмотрел как вы подсказали и действительно в коде по другому ссылки прописаны, подправил регулярку, теперь все норм парсит. Спасибо за наводку!А в зенке парсите DOM модель или код страницы?
Как вариант сделать сохранение кода страницы в TXT файл из переменной и посмотреть что не так.
Jorge_Rodrigez
Client
- Регистрация
- 27.12.2012
- Сообщения
- 70
- Благодарностей
- 8
- Баллы
- 8
Подскажите про замену групп. Есть тексты, хочу в каждом тексте одно рандомное слово заменять этим же словом но уже с ссылкой. Делал через кубик замены, в поиске (\s\w{4,20}) меняю на <a href="ссылка">$1</a>, в итоге зенно меняет буквально на этот текст, не заменяя $1 на группу. Через сниппет C# замена работает, но я не знаю как через C# сделать одну рандомную замену, и он меняет все вхождения.
doc
Client
- Регистрация
- 30.03.2012
- Сообщения
- 8 685
- Благодарностей
- 4 652
- Баллы
- 113
\\r\\nКак в одном экшн заменить пустые строки? в тестере показывает Строка1\r\n\r\nСтрока2 При замене нифига не срабатывает в regexp
Посмотреть вложение 36223
udder
Client
- Регистрация
- 28.03.2017
- Сообщения
- 638
- Благодарностей
- 140
- Баллы
- 43
@doc Здравствуйте, помогите пожалуйста с регуляркой.
https://test.com
http://sub.test.com/postname/
http://www.test.com/article/post/
Как оставить только имена доменов, если есть сабдомен, то его так же оставить. Протокол оставлять необязательно.
Чтобы на выходе оставить только
test.com
sub.test.com
www.test.com
https://test.com
http://sub.test.com/postname/
http://www.test.com/article/post/
Как оставить только имена доменов, если есть сабдомен, то его так же оставить. Протокол оставлять необязательно.
Чтобы на выходе оставить только
test.com
sub.test.com
www.test.com
doc
Client
- Регистрация
- 30.03.2012
- Сообщения
- 8 685
- Благодарностей
- 4 652
- Баллы
- 113
/[^/]+$как получить выделенное красным?
путь к файлу рандомный
/main_foto/KOS8YA4QZX3aTiIkX6jdcGXj.jpg

санчил
Client
- Регистрация
- 15.04.2016
- Сообщения
- 344
- Благодарностей
- 60
- Баллы
- 28
очень вам благодарен ,все четко работаетМожно по простому вырезать нужную часть
.*:
inilim
Client
- Регистрация
- 16.09.2017
- Сообщения
- 446
- Благодарностей
- 171
- Баллы
- 43
как составить регулярку, взять содержимое тега в котором отсутствуют любые теги. Например тег <a>:
<a>text<span>1</span></a>
<a><span>1</span>text</a>
<a>текс</a>
но при этом содержимое может и не быть вовсе.
<a></a>
<a>text<span>1</span></a>
<a><span>1</span>text</a>
<a>текс</a>
но при этом содержимое может и не быть вовсе.
<a></a>
Последнее редактирование:
orka13
Client
- Регистрация
- 07.05.2015
- Сообщения
- 2 190
- Благодарностей
- 2 209
- Баллы
- 113
как составить регулярку, взять содержимое тега в котором отсутствуют любые теги. Например тег <a>:
<a>text<span>1</span></a>
<a><span>1</span>text</a>
<a>текс</a>
но при этом содержимое может и не быть вовсе.
<a></a>
Код:
(?<=<(\w+)[^\<\>]*?>)[^\<\>]*?(?=< ?\/ ?(\1)>)
Код:
(?<=<a[^\<\>]*?>)[^\<\>]*?(?=< ?\/ ?a>)orka13
Client
- Регистрация
- 07.05.2015
- Сообщения
- 2 190
- Благодарностей
- 2 209
- Баллы
- 113
В какой среде используются? Я в конструкторе регулярок проверил, все ок. В C# подправить может придется.Не одна не пашет
inilim
Client
- Регистрация
- 16.09.2017
- Сообщения
- 446
- Благодарностей
- 171
- Баллы
- 43
проверял в regex101В какой среде используются? Я в конструкторе регулярок проверил, все ок. В C# подправить может придется.
orka13
Client
- Регистрация
- 07.05.2015
- Сообщения
- 2 190
- Благодарностей
- 2 209
- Баллы
- 113
Тут под зенку тема, зачем на сервисе стороннем тестировать? Там сложные регулярки могут не сработать. Вот скрин что в зенке работает:
Вложения
-
 17,7 КБ Просмотры: 9
17,7 КБ Просмотры: 9
санчил
Client
- Регистрация
- 15.04.2016
- Сообщения
- 344
- Благодарностей
- 60
- Баллы
- 28
подскажите пожалуйста есть строки в таком виде
http://kourortchernomor.ru/divnomorsk-otdyx/
http://www.nashikurorty.ru/blog/divnomorskoe-otdyx-kruglyj-god/
http://www.kurortniku.ru/divnomorsk.htm
https://www.sunnyregion.ru/region/divnomorskoe/
как их получить в таком виде ( обработать
http://www.nashikurorty.ru
http://kourortchernomor.ru/divnomorsk-otdyx/
http://www.nashikurorty.ru/blog/divnomorskoe-otdyx-kruglyj-god/
http://www.kurortniku.ru/divnomorsk.htm
https://www.sunnyregion.ru/region/divnomorskoe/
как их получить в таком виде ( обработать
http://www.nashikurorty.ru
- Регистрация
- 05.09.2012
- Сообщения
- 22 689
- Благодарностей
- 10 152
- Баллы
- 113
подскажите пожалуйста есть строки в таком виде
http://kourortchernomor.ru/divnomorsk-otdyx/
http://www.nashikurorty.ru/blog/divnomorskoe-otdyx-kruglyj-god/
http://www.kurortniku.ru/divnomorsk.htm
https://www.sunnyregion.ru/region/divnomorskoe/
как их получить в таком виде ( обработать
http://www.nashikurorty.ru
Код:
(http|https)://.*?/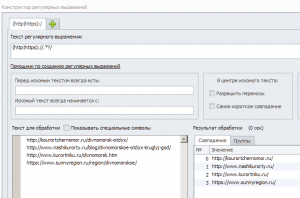
санчил
Client
- Регистрация
- 15.04.2016
- Сообщения
- 344
- Благодарностей
- 60
- Баллы
- 28
благодарен Вам , все работаетПосмотреть вложение 39235Код:(http|https)://.*?/
- Регистрация
- 05.09.2012
- Сообщения
- 22 689
- Благодарностей
- 10 152
- Баллы
- 113
Приветствую! Помогите составить регулярку, чтобы обрезалась строка на точке или запятой и в строке после обрезки оставалось не более 250 символов.
Код:
[\w\W]{0,250}[,\.]Вложения
-
 69,6 КБ Просмотры: 8
69,6 КБ Просмотры: 8
POLOZ
Client
- Регистрация
- 06.02.2018
- Сообщения
- 42
- Благодарностей
- 4
- Баллы
- 8
Спасибо большое за оперативную помощь!Обработка текста - Regex (Первое совпадение)Код:[\w\W]{0,250}[,\.]
orka13
Client
- Регистрация
- 07.05.2015
- Сообщения
- 2 190
- Благодарностей
- 2 209
- Баллы
- 113
Вот отрывок моего говнокода из старенького моего шаблона конкурсного Быстрый парсер RU + ENG текстового контента на Get-запросах:Всем привет.
Знатоки к вам вопрос.
Как разбить текст по предложениям (т.е. по точкам) если в тексте куча сокращений типа "г.", "км.", "мл.", "сек." и т.п.?
C#:
// умно разбиваем длинные строки на предложение по наличию точки, + пробела и заглавной буквы после нее, + текста без точки недалеко перед ней:
regexTest = System.Text.RegularExpressions.Regex.Replace(regexTest, @"(?<=[^\!\.\?\r\n]{10,650})[\!\.\?]\ (?=[A-ZА-Я][^\.]{10,650})", ".\r\n", System.Text.RegularExpressions.RegexOptions.Multiline);Сибиряк
Client
- Регистрация
- 12.07.2014
- Сообщения
- 916
- Благодарностей
- 373
- Баллы
- 63
Парсер огонь!Вот отрывок моего говнокода из старенького моего шаблона конкурсного Быстрый парсер RU + ENG текстового контента на Get-запросах:
Там можно много интересных идей по обработке текста одолжить. Не все костыли там идеальные, но вроде рабочие.C#:// умно разбиваем длинные строки на предложение по наличию точки, + пробела и заглавной буквы после нее, + текста без точки недалеко перед ней: regexTest = System.Text.RegularExpressions.Regex.Replace(regexTest, @"(?<=[^\!\.\?\r\n]{10,650})[\!\.\?]\ (?=[A-ZА-Я][^\.]{10,650})", ".\r\n", System.Text.RegularExpressions.RegexOptions.Multiline);
Спасибо за код))
- Регистрация
- 05.09.2012
- Сообщения
- 22 689
- Благодарностей
- 10 152
- Баллы
- 113
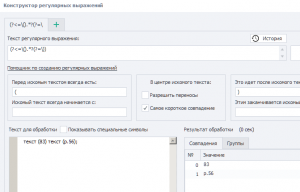
Регулярка:текст (83) текст (р.56);
нужно получить значение во вторых скобках
";" - после скобок всегда
Код:
(?<=\().*?(?=\))
Sanekk
Client
- Регистрация
- 24.06.2016
- Сообщения
- 1 002
- Благодарностей
- 389
- Баллы
- 83
первых скобок может не быть
- Регистрация
- 05.09.2012
- Сообщения
- 22 689
- Благодарностей
- 10 152
- Баллы
- 113
Это можно кубиками алгоритмически обыграть.первых скобок может не быть
Если по второму совпадению ничего не найдено (проверяем через IF),
то берем первое совпадение.