- Регистрация
- 25.06.2011
- Сообщения
- 1 547
- Реакции
- 1 312
- Баллы
- 113
I Love Time Series Data

Intro
Данную статью начну с цитаты...

Сегодня эти слова можно понимать как:
"Бабло начинается там, где начинают измерять!"
"Бабло начинается там, где начинают измерять!"
Что такое Time Series Data?
Немного теории. По научному - это временные ряды. По простому, это абсолютно любые данные которые мы можем положить на ось времени и эти данные меняют свое значение в некотором промежутке времени.
Примеры:
[Обьект наблюдения] - [Свойства] + {UnixTime} метка фиксирующая состояние в текущий момент измерения
- Человек - пульс, температура, давление + UnixTime метка= График(или любой другой компонент визуализации) отражающий каждое из состояний
- Автомобиль - скорость, расход топлива + UnixTime метка = ...
- Этот форум - статистика пользователей на главной странице + UnixTime =...
- Счетчик Яндекс метрики - много параметров + UnixTime = Графики, чарты, гистограммы, таблицы, ...
- Ссылка на странице - клик + UnixTime
- Процессор (/etc) - частота , загрузка, все то что мы видим в диспетчере задач системы + UnixTime
- Курс крипты на бирже = обьемы, бид, аск..+
- Программа (ООП) - состояние свойств классов +
И еще много обьектов в окружающем мире. Ну как много, более 50%
 :-)")
Сразу определимся с общепринятой терминологией .
measurement = обьект измерения (запомните это слово, далее мы его будем использовать)
tag = метка
key 1= value1 значение которое измеряем
В каких типах баз нужно хранить такие данные?

Сейчас очень много телеметрии во всех приложениях и на сайтах, и все эти данные нужно обрабатывать практически в режиме реального времени. С минимальными задержками на запись и чтение.
Как эти базы устроены и что у них под капотом подробно затрагивать не буду
- Скажу только что написаны большинство из них на Go lang и представляют из себя один бинарный файл. Размещаются эти базы сразу в оперативной памяти.
- Имеют несколько интерфейсов (UDP, gRPC, TCP, ...) и HTTP API интерфейс в который мы и будем писать/читать.
- Запустили бинарник => http://ip.port у нас висит база в которую мы делаем Post/Get запросы.
- Новые данные вытесняют "протухшие". По умолчанию вытесняют в /dev/null . Если в конфиге изменить, будет бекапить, и не только бекапить, но и сжимать если хотим...
- Нет, не только в архивчик паковать, а резать сами ряды без потери информативности.
- Если мы писали в базу ряд с интервалом 5s, то через неделю мне не нужна такая детализация и можно порезать данные до тайм-фрейма 1m/10m/.... при этом данные сохранят общую картину и тренды.
- Размер стека для всех баз всегда фиксированный в памяти. По умолчанию - 1G. Больше чем это значение все базы не займут в памяти. Иначе говоря вхолостую базы не жгут память, если мы записали 10кб то и база займет (100-150мб бинарик процесса сам) + 10кб?, а если забьем 1G начнется вытеснение с заданными параметрами.
Такие базы созданы чтобы их просто насиловать потоком данных
Маленькая крупица подкапотной магии таких баз и напутствие для написания шаблонов ZennoPoster
Если мы каждую 1s будем передавать одно фиксированное значение
forum,user=admin status=1
То в базе не будет создано дубликатов этого значения, база будет всегда занимать 1 байт (или 4 зависимости от кодировки)
Когда пишите шаблоны, смотрите на данные с которыми вы работаете.
К примеру, парсите сайт, пишете в список что-то в таком духе http://site.com/cat1/page1.html
Не стоит насиловать диск и память такими I/O
В список пишем: cat1/page1.html
В переменную:http://site.com/
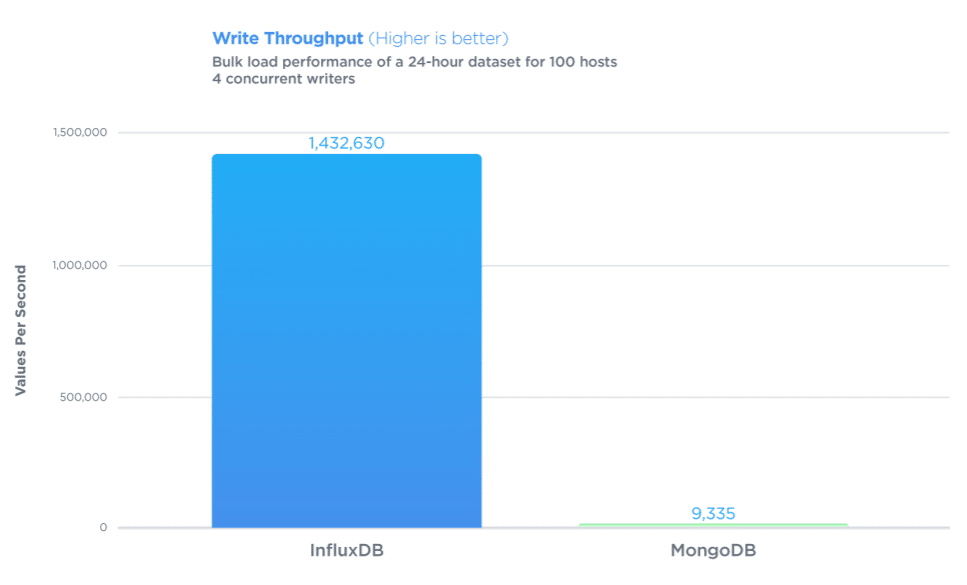
Когда говорят о TSDB, то это тема про скорость +- 1 000 000 записей/выборок в секунду!

Самая популярная, быстрая и удобная на сегодня TSDB - InfluxDB. Популярность получила за счет своего синтаксиса, очень похожего на SQL. Ее мы с вами чуть позже пощупаем.
Стенд - домашний PC
- Win 10 LTSB R5
- CPU - 4770k
- RAM - 16G

InfluxDB HTTP endpoints
- После запуска база доступна на порту localhost:8086
- База имеет несколько эндпоинтов, но нас интересует всего два
POST http://localhost:8086/write
POST http://localhost:8086/query --data-urlencode q=CREATE DATABASE mydb
POST http://localhost:8086/query --data-urlencode q=CREATE DATABASE mydb
Синтаксис на запись:
Код:
http://localhost:8086/write?db=mydb measurement,mytag=pc1 myfield=90 1463683075- mydb - название базы [string]
- measurement - обьект измерения (cpu,ram,forum,page,...) [string]
- mytag - название метки [string]*
- pc1- значение метки [string] *
- myfield - название параметра [string]
- 90 - значение [string, float, integer, Boolean]
- 1463683075 - метка времени
- Пушить можно сразу сетом в несколько строк, каждая с новой строки
- Пушить можно файл в котором эти строки
Первым идет обьект измерения, далее через запятую теги, и после первого пробела уже измеряемые значения которые замыкает метка времени (UnixTime)
Более подробная информация на >странице документации<

- Работает как веб панелька которая висит на ip:port (default localhost:3000)
- 52 DataSource (JSON, MySQL, InfluxDB, ... )
- 41 Визуальный компонент (графики, чарты, гистограммы, таблицы,)
- 1к+ готовых дашбоардов под все эти 52 дата сорса. Но свой создать делов на 20 мин.
- Расшаривание как конкретного визуального компонета так и всего дашбоарда
- Расшаривание как снепшот
- Алерты - очень гибкие под все возможные случаи
- Алерты/Отчеты - пушит в кучу каналов: вебхуки, почту, телегу, .....
- Мульти аккаунты с разными правами доступа
- Очень реактивная. Не фризит и т.п.
- Если этого мало, есть у дашбоарда и свое HTTP API
>PlayDemo<
Чтобы симулятор данных завелся и графики ожили,в правом верхнем углу панелька там кликните
Refreshing every: 5s + Apply
Если демки мало, то Google Images => Grafana
Чекпоинт #1 + маленькое отступление от темы
На данном этапе вы уже можете для себя унести панельку для визуализации своих данных с любого из дата провайдеров. В конце статьи будет архивчик со всеми инструментами из этой статьи с настроенными конфигами.(я там только пути поменял из расчета что все будет лежать на C://Apps )
Запустил и пользуйся, на первую недельку посмотреть и понять что оно такое и нужно ли мне будет достаточно. Если поняли что оно вам нужно, а оно вам нужно, но вы не поняли еще...то нужно все это ставить на ВПС. Никаких докеров не юзаем, не предлагаю даже, ибо есть exe под винду для посмотреть и пощупать. Докер писали хипстеры для хипстетров, там все под рутом, и запускать образ который собрал неизвестно кто и подложил там носок....(кто не знает где добыть прокси и соксов, ну вы поняли куда и что ....) Докер это продолжение Денвера)) Чтобы что-то поломать и за это ничего не было...
И второй момент, что база, что панельки само собой имеют настройки авторизациим и торговать отрытым доступом в веб не стоит...
Что это и зачем? Что туда писать и зачем оно мне? О чем ***** статья?
Кейсы!! = Money$$$$
- Я, разработчик софта = App Metrics => Начиная с этапа разработки, дебаг и отладка приложения,снимаем все параметры приложения и его окружения. Находим мемори-лики и прочие баги. Если сбилдилось и пошло в продакшн, остлеживаем миграцию клиентов по версиям и на каких системах кто сидит и как наше приложение работает. Единственный минус который поджидает разработчиков ПП с приличной базой клиентов, что один инстанс базы распухнет и вырастут аппетиты на данные, а чтобы кластеризоваться нужно будет занести...Это стоит учитывать, что аппетит будет...всех остальных этот вопрос не затронет и им хватит 1 инстанса базы.
- Я, разработчик шаблонов под ЗенноПостер =
- -Если на продажу, my_sale_project1,client_id=user1@zenno.com, status_online=true ....
- -Если для себя, на God/End два пуша в базу
- my_project1,version=1, ok=true
- my_project1,version=1, ne_ok=true
- Если ne_ok много для нас, правим и отлаживаем. Или далее углубляемся, ставим пуши после каждого кубика и находим "виновника торжества"
- Так вы видите просто циферку сколько потоков сейчас крутит зенно. Ну минуту-три посмотрите и свернете его или выйдете с сервера. А в динамике на графике он (ваш проект) метр едет- два стоит, а вы заходили смотрели когда ехал. Но чуть ниже я расскажу про еще одну утилиту которая как демон/служба будет в системе снимать все ее состояние и пушить в базу. Потому что, чтобы выявить причину DevOpps нужен внешний наблюдатель. И из самого шаблона пушить не лучший подход. Все что вы получите если настроите алерты, алерт что не приходило данных за последние 10 минут, а почему все упало не поймете.
- Я, "трейдер" и с криптой работаю - Все та же утилита демон выше упомянутая имеет плагин http, который может дергать любое JSON апи биржи, и пушить в базу. Вы из базы через дашбоард дергать эти данные, бид, аск, обьемы строить графики, на графики накладывать очень гибкие алерты (значение вошло в диапазон, вышло из него, считать спред и т.д) Пушить себе в телегу отчет и веб хук для зенно, Алерт в виде пуша на http://myhost.com/task.php?run=projectname => php скрипт добавляет строку в файл myhost.com/task.txt с именем шаблона. Шаблон-демон раздает задачи другим используя систему запуска по триггеру.
- Я, Арбитражник & А/В тестер&Вебмастер&Дорвейщик&сам себе ЯдексМетрика и ГуглАналитикс - все тот же демон имеет плагин для парсинга логов апача, все эти данные + на страницах на JS обработчики событий которые пушат что пожелаете пушить (клики, параметры браузеров, время сессий и т.д.)
- Я у Мамы инженер, я у Мамы умный дом - все данные пушим на панельку.
- Я у мамы дважды инженер, купил ардуино+ .net модуль + сенсор движения - запушил себе через алерты сигналку)

Telegraf
Еще одна тула входящая в пакет поставки с InfluxDB.
По простому, работает как Крон+плагины.
Плагины вшиты уже в него, активация плагинов происходит просто добавлением в конфиг нескольких строк
Есть четыре вида плагинов:
Output = выхлоп, куда писать. Мы его не будем трогать, он по умолчанию настроен писать в InfluDB
Наша секция в конфиге:
##################################################################
INPUTS
##################################################################
[Input ]- какой плагин использовать для сбора чего-то / откуда-то
И в помощь идут два вспомогательных типа плагинов если стоит задача
[Processing] и/или [Aggregation]
Ссылки кликабельные.
Там на страницах ссылки на гитхаб с описанием настроек плагинов.
Какой у него выхлоп (какие параметры он выдаст)
Те плагины которые только под linux , то там это явно указано в описании
>Клик<
Сорсы тащить ничего не нужно, просто можете заглянуть как оно на Go lang кодится.
Все они уже скомпилены в поставляемой exe.
И в помощь идут два вспомогательных типа плагинов если стоит задача
[Processing] и/или [Aggregation]
Ссылки кликабельные.
Там на страницах ссылки на гитхаб с описанием настроек плагинов.
Какой у него выхлоп (какие параметры он выдаст)
Те плагины которые только под linux , то там это явно указано в описании
>Клик<
Сорсы тащить ничего не нужно, просто можете заглянуть как оно на Go lang кодится.
Все они уже скомпилены в поставляемой exe.
Пример одного плагина

Плагин будет дергать этот апи и сам сконвертит (JSON)в нужный формат и запушит в базу.
Простое правило - одна здача = 1 плагин инпута + опиционально плагины пострпроцессинга данных*
*совмещать можно только плагины сбора телеметрии системы (cpu/ram/net./etc....)
**Вообще все можно в 1 конфиг напихать, но не нужно. Систему мы дергать будем каждые 5s, а json api binance по бесплатнопу тарифу разрешено к примеру 10 000 запросов /месяц= 60*60*24*30=2592000s/10 000=260s
Запускать так: telegraf.exe --config C://Apps//telegraf//my.conf
После того как правильно все настроили, увидели через дашбоард что данные идут, можем запускать несколько копий со своими задачами как служба Windows со всеми плюшками.
Running Telegraf as a Windows Service
Chronograf + Capacitor
Самые важные компоненты всей этой кухни и всей сути. Именно они раскрывают всю суть почему Time Series базы используем и городим весь этот огород.Running Telegraf as a Windows Service
Chronograf + Capacitor
Chronograf - просто еще один дашбоард который идет в пакете. Альтернатива грфане. Но если к нему подключаем Capacitor то мы получим совсем другую картину. Capacitor это бекенд для хронографа добавляющий ему функционал. Без него мы получаем просто визуализацию графиками и все.
Запускаем chronograf + capacitor = http://localhost:8888 тут панелька.
У нее есть вкладка InfluxDB Admin в которой мы можем создавать наши базы (назначать имена) и указывать очень важный параметр Duration
Если указать только имя базы и создать по умолчанию, то он будет равен 7дней - время сколько хранить в этой базе данные. Но так же мы можем явно указать там 1h30m, 2d, ...
Почему такая градация?
Там нужно указывать примерное время вашей реакции на любой алерт который сработает у вас.
И умножить на X2....X3 это время с запасом
для чего?
А теперь вся эта кухна по полочкам.
Пример#1
1. У нас есть база
2. У нас есть телеграф который снимает телеметрию системы (CPU+RAM ....)
3. У нас есть настроенные алерты
алерт#1 = Если нагрузка на CPU за последние 10мин находилась за пределами границы 0,1...0,9
-Load CPU держался 10 минут менее 10% - у нас прекратилась полезная нагрузка, перестал Работать ЗенноПостер
-Load CPU держался 10 минут более 90% - сильно машину
алерт#2 = Если нагрузка на RAM (16G) за последние 30мин находилась за пределами границы 2G...14G
-Used RAM держался 10 минут менее 2G - у нас прекратилась полезная нагрузка, перестал Работать ЗенноПостер
-Used RAM держался 10 минут более 14G - сильно грузило машину
Мы сами субьективно создали условия для понятия алер=аномалия.
Всего два графика на дашбоарде, больше и не нужно в этом примере
Если сработал один из алертов , значит дела плохи и нужно бы за время указанном в Duration
успеть попасть в дашбоард!
Почему?
Потому что данные об аномали будут удалены из базы (вытеснены другими, или в бекап упадут я не хочу в нем ковыряться) и мы не сможем проанализировать ее глазами и ....
Мы зашли в панельку и видим, что да, сработал алерт на CPU или RAM
Мы на языке (Flux) который из каропки идет вторым, накидываем на нем скрипт.
Примерно 10-20 строк это будет.
По простому мы "говорим" (кодим выборку), слушай ка, а ну ка возьми ты данные от момента пока все ровно было и до момента факта аномалии (факт=сработал алерт) и обучись как ванга. И если будет похожая температура в больнице ты мне заранее пришли алерт грядущего пи..ца. И называем его лейблом "Грядет DevOpps RAM"
Потому что я не могу сутками сидеть втыкать на дашбоард, а просто ловить алерты толку мало, уже свершившийся факт. И если будут предвестники мы узнаем он них заранее.
Пример#2 - Антифрод = Мы теряем деньги (у нас их пи**дят)
Я создал кран и раздаю 5 сатошиков или Я магазин запустился в CPA,
а ко мне боты ЗенноПостера валят и скликавают меня или еще что-то делают чтоя бабки теряю.. не хорошо
Алерты не нужны, ибо я не знаю какие параметры обьектов наблюдения (логи с апача, поведение на странице есть нормальное ,а есть аномалия) но у меня есть другой алерт, баланс кошелька который начал худеть очень резко вчера вечером.
Я все на том же Flux кидаю скрипт, и говорю выбери мне все данные что есть по страницам и отсортируй по количеству (частоте). все параметры. Есть бос. Опа, глазками смотрю и вижу за час этот было много (серия заходов) юзерагенты и скрин резолюшены одинаковые. Так теперь возьми все остальные данные что у нас есть для них и запомни это явление как боты и в следующий раз мне алерт и пуш на добавление этих IP в блек лист, а еще скажи зенно постеру (триггеры) пусть пойдет в админку рекаптчи и включит Hight режим сложности каптчи.
Пример#3 - Я Арбитражник
Аналогичный подход. Разместил рекламуна площадках, а там боты бегут через лендинг или прокладку мою. Надо чтобы спотыкались. Снимаем браузерные параметры, фильтруем, смотрим, метим что это боты.
Еще примеры нужны?..
Чекпоинт #2
После прочтения статьи, возможно вы вынесете для себя нестандартные подходы и сможете в связке с ЗенноПостером оптимизировать ваши кейсы и увеличить профит.
Все эти инструменты будут как мозги + Зенно как руки которые будут выполнять автоматизацию более гибко, по триггерам, а ваше участие будет минимальным. Только на этапе разработки шаблона и запуска в его в бой!
##################################################################
>Скачать APPS<
Запускать в таком порядке
1. InfluxDB будет висеть на localhost:8088
2. Telegraf
3. Grafana admin:admin localhost:3000
Переходим на localhost:3000 и Визард панельки по шагам сам покажет как первые шаги делать
##################################################################
>Скачать APPS<
Запускать в таком порядке
1. InfluxDB будет висеть на localhost:8088
2. Telegraf
3. Grafana admin:admin localhost:3000
Переходим на localhost:3000 и Визард панельки по шагам сам покажет как первые шаги делать
##################################################################
Official:
http://docs.influxdata.com/https://grafana.com/
Спасибо за внимание. Всем профита $)
p.s. Меня тут просят видео записать как куда что тыкать в панельках, ибо сходу не понятно.
Само собой и не должно быть все понятно. я не могу все GetStarted сюда копипастить с переводом по каждой утилите. Вам самим нужно топать по ссылкам и изучать. Видео как построить график это ничто, по сравнению с остальными настройками и пониманием как что и куда. Но там все очень доступно и понятно. Порог входа = максимум месяц со скриптингом на Flux. Я просто обозначил какие утилиты и какие подходы к ним нужно делать и какие кейсы можно решать максимально продуктивно и максимально автоматизированно благодаря связки с зеннопостером.
p.s2 Вам не нужно городить глобальну систему по "завату мира" и строить под каждый параметр график, если вам эти данные не нужны. Берете то что полезно для вашей темы с которой работаете. Пишете софт-телеметрия систем, с вебом работаете - все параметры с браузеров и т.д.
- Номер конкурса статей
- Десятый конкурс статей
- Тема статьи
- Другое
Последнее редактирование: