- Регистрация
- 16.08.2017
- Сообщения
- 36
- Благодарностей
- 4
- Баллы
- 8
Всем добрый день, подскажите, пожалуйста.
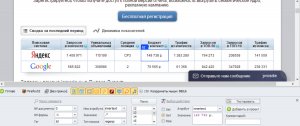
Есть сайт, spywords.ru. Служит для того, чтобы проверить активность конкурентов в части контекстной рекламы.
Хочу вытащить данные оттуда по затратам, но дело в том, что все ячейки с данными имеют один и тот же тэг td

В свойствах же элемента данный каждые раз новые.
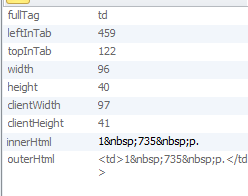
Не знаю к чему прицепиться, чтобы данные тащить. Как можно решить задачу?
Есть сайт, spywords.ru. Служит для того, чтобы проверить активность конкурентов в части контекстной рекламы.
Хочу вытащить данные оттуда по затратам, но дело в том, что все ячейки с данными имеют один и тот же тэг td
В свойствах же элемента данный каждые раз новые.
Не знаю к чему прицепиться, чтобы данные тащить. Как можно решить задачу?