



Есть большая таблица в БД MySQL с исходными данными и есть шаблон который берет одну запись из этой таблицы, обрабатывает ее и сохраняет обработанные данные в ту же таблицу. Вопрос в том как сделать так чтобы в многопотоке шаблоны брали каждый свою запись и не мешали друг другу?
Пробовал вот такие варианты:
1. Через транзакции с "select for update"
Работает только если потоков немного, при увеличении количества потоков таблица постоянно заблокирована
2. Обычный select и список с последними id взятыми в работу
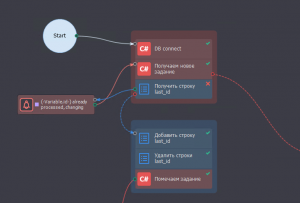
получаем необработанную строку из БД
проверяем есть ли в списке такая строка
если есть снова берем необработанную строку из БД
если нет то добавляем строку в начало списка, удаляем из списка последнюю, помечаем в БД что строка взята в работу, обрабатываем
В общем работает, но за время пока один поток проверяет список еще несколько потоков успевают взять в обработку ту же строку и несколько потоков обрабатывают одно и то же
3. "Lock" файл
Перед выполнением запроса шаблон проверяет наличие определенного файла, если его нет то создает такой файл и выполняет запрос, после выполнения удаляет. Если файл есть то ждет и проверяет снова
Все работает но очень медленно и увеличение количества потоков ничего не дает так как одновременно все равно работает только один
Какие есть еще способы? ну или как докрутить один из этих?
Пробовал вот такие варианты:
1. Через транзакции с "select for update"
C#:
var db = project.Context["db"];
List<string> row = db.getRow("start transaction;SELECT id, data FROM `table` WHERE `result` is NULL limit 1 for update;");
if ( row.Count > 0 ){
string free_id = row[0];
project.Variables["id"].Value = row[0];
project.Variables["data"].Value = row[1];
project.SendInfoToLog("Есть задание id: "+free_id, true);
db.query("update table set result = 'zenno' where id="+free_id+" ; commit;");
}
else {
db.query("commit;");
project.Variables["id"].Value = "-1";
}2. Обычный select и список с последними id взятыми в работу
получаем необработанную строку из БД
проверяем есть ли в списке такая строка
если есть снова берем необработанную строку из БД
если нет то добавляем строку в начало списка, удаляем из списка последнюю, помечаем в БД что строка взята в работу, обрабатываем
В общем работает, но за время пока один поток проверяет список еще несколько потоков успевают взять в обработку ту же строку и несколько потоков обрабатывают одно и то же
3. "Lock" файл
Перед выполнением запроса шаблон проверяет наличие определенного файла, если его нет то создает такой файл и выполняет запрос, после выполнения удаляет. Если файл есть то ждет и проверяет снова
Все работает но очень медленно и увеличение количества потоков ничего не дает так как одновременно все равно работает только один
Какие есть еще способы? ну или как докрутить один из этих?
