В этой статье я хочу продемонстрировать вам, как можно распараллелить работу даже на однопоточной версии зеннопостера. Благо, зенка позволяет выполнять произвольный C# код, чем мы и воспользуемся. В качестве демонстрационного примера, с помощью многопоточного паука будем решать задачу по парсингу одного интернет магазина с сохранением полученных данных в базу. Поэтому, базовые навыки работы с базой данных вы тоже освоите.
Паук представляет из себя очередь задач, по мере выполнения которых, производится обработка полученных из сети данных. Он написан таким образом, что параллелится только работа с сетью, а обработка данных выполняется в один поток. Так сделано потому, что процесс обработки данных происходит быстро, и выполнять его многопоточно просто нерационально. Зато у нас появляется возможность не используя блокировок выгрузить данные в файл, например, или загрузить из файла новые ссылки и добавить их в очередь.
Принцип работы паука довольно прост:
- Задачи, которые являют собой пару из ссылки и привязанной к ней функции, добавляются в очередь
- Паук берет задачи из очереди и запускает потоки, которые GET запросом получают ответ сервера по ссылке
- Паук контролирует количество запущенных потоков согласно заданному лимиту
- После получения данных из сети по определенной ссылке, запускается функция, привязанная к этой ссылке, для обработки полученных данных. При этом, функция принимает в качестве аргумента html документ, сформированный из ответа сервера
- В процессе обработки можно спарсить из документа новые ссылки и добавить их в очередь
- Паук работает до тех пор, пока очередь не будет исчерпана
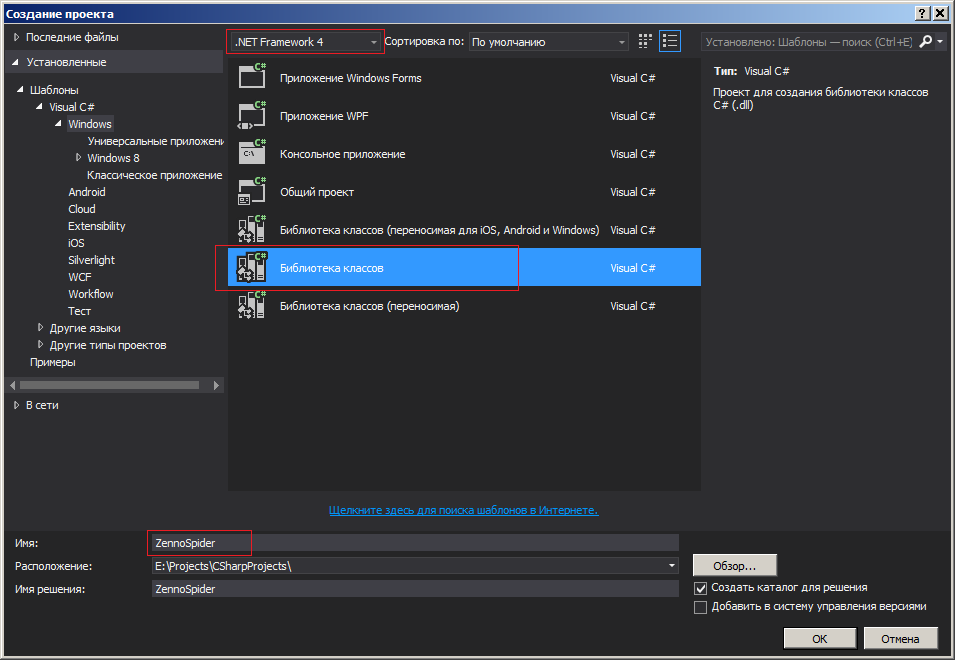
1. Создаем в Visual Studio проект библиотечного типа, именуем его как-нибудь (я назвал ZennoSpider) и выбираем рантайм .net framework 4 версии.
2. Подключаем в проекте ссылки на библиотеки HtmlAgilityPack.dll и xNet.dll. Они есть в архиве, прикрепленном к статье.
3. Копируем исходники паука в проект.
4. Собираем, выбрав в панели инструментов Сборка ==> Собрать решение или просто нажав F6 на клавиатуре.
2. Подключаем в проекте ссылки на библиотеки HtmlAgilityPack.dll и xNet.dll. Они есть в архиве, прикрепленном к статье.
3. Копируем исходники паука в проект.
Код:
using HtmlAgilityPack;
using System;
using System.Collections.Generic;
using System.Text;
using System.Threading;
using System.Threading.Tasks;
using xNet;
namespace ZennoSpider
{
public class Spider
{
private readonly Queue<Tuple<string, Action<HtmlDocument>>> _urlQueue = new Queue<Tuple<string, Action<HtmlDocument>>>();
private readonly List<Tuple<Task<string>, Action<HtmlDocument>>> _tasks = new List<Tuple<Task<string>, Action<HtmlDocument>>>();
private readonly int _threadsCount;
private int _counter = 0;
private Action<string> _log;
private Encoding _encoding;
public Spider(int threadsCount = 10)
{
_threadsCount = threadsCount;
}
public Encoding Encoding
{
set
{
_encoding = value;
}
}
public Action<string> OnLog
{
set
{
_log = value;
}
}
protected void AddTask(string url, Action<HtmlDocument> callbackFunc)
{
if (_tasks.Count < _threadsCount)
_tasks.Add(new Tuple<Task<string>, Action<HtmlDocument>>(Task.Factory.StartNew<string>(Worker, url, TaskCreationOptions.LongRunning), callbackFunc));
else
_urlQueue.Enqueue(new Tuple<string, Action<HtmlDocument>>(url, callbackFunc));
}
protected virtual void Initialize() { }
public void Start()
{
this.Initialize();
while (_urlQueue.Count > 0 || _tasks.Count > 0)
{
if (_tasks.Count > 0)
{
Tuple<Task<string>, Action<HtmlDocument>>[] temp = _tasks.ToArray();
foreach (Tuple<Task<string>, Action<HtmlDocument>> task in temp)
{
if (task.Item1.IsCompleted)
{
if (!task.Item1.IsFaulted)
{
if (_log != null)
_log(string.Format("[{0}] {1} | OK", _counter++, task.Item1.AsyncState));
HtmlDocument doc = new HtmlDocument();
doc.LoadHtml(Html.ReplaceEntities(task.Item1.Result));
task.Item2(doc);
}
else
{
HttpException exc = (HttpException)task.Item1.Exception.InnerException;
if (_log != null)
{
if (exc != null)
{
switch (exc.Status)
{
case HttpExceptionStatus.ProtocolError:
_log(string.Format("[{0}] {1} | Код состояния: {2}", _counter++, task.Item1.AsyncState, (int)exc.HttpStatusCode));
break;
case HttpExceptionStatus.ConnectFailure:
_log(string.Format("[{0}] {1} | Не удалось соединиться с HTTP-сервером.", _counter++, task.Item1.AsyncState));
break;
case HttpExceptionStatus.SendFailure:
_log(string.Format("[{0}] {1} | Не удалось отправить запрос HTTP-серверу.", _counter++, task.Item1.AsyncState));
break;
case HttpExceptionStatus.ReceiveFailure:
_log(string.Format("[{0}] {1} | Не удалось загрузить ответ от HTTP-сервера.", _counter++, task.Item1.AsyncState));
break;
case HttpExceptionStatus.Other:
_log(string.Format("[{0}] {1} | Неизвестная ошибка.", _counter++, task.Item1.AsyncState));
break;
}
}
else
{
_log(string.Format("[{0}] {1} | {2}", _counter++, task.Item1.AsyncState, task.Item1.Exception.InnerException.Message));
}
}
}
task.Item1.Dispose();
_tasks.Remove(task);
}
}
Array.Clear(temp, 0, temp.Length);
}
for (int i = 0; i < _threadsCount - _tasks.Count; i++)
{
try
{
Tuple<string, Action<HtmlDocument>> t = _urlQueue.Dequeue();
_tasks.Add(new Tuple<Task<string>, Action<HtmlDocument>>(Task.Factory.StartNew<string>(Worker, t.Item1, TaskCreationOptions.LongRunning), t.Item2));
}
catch (InvalidOperationException)
{
break;
}
}
Thread.Sleep(500);
}
}
private string Worker(object url)
{
using (HttpRequest request = new HttpRequest())
{
request.MaximumAutomaticRedirections = 10;
//request.Cookies = new CookieDictionary();
request.ConnectTimeout = 10 * 1000;
request.ReadWriteTimeout = 30 * 1000;
//request.IgnoreProtocolErrors = true;
request["Accept"] = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8";
request["Accept-Language"] = "ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3";
request["User-Agent"] = "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0";
HttpResponse r = request.Get((string)url);
byte[] bytes = r.ToBytes();
if (_encoding != null)
return _encoding.GetString(bytes);
return Encoding.UTF8.GetString(bytes);
}
}
}
}4. Собираем, выбрав в панели инструментов Сборка ==> Собрать решение или просто нажав F6 на клавиатуре.
Мне не очень нравятся реляционные базы данных, поэтому я предпочитаю использовать решения из семейства NoSQL баз. Ярким представителем этого семейства является база данных MongoDB. MongoDB - это объектно-документарная база данных, хранящая данные в формате JSON. Именно ее мы и будем использовать для хранения наших данных.
1. Качаем бинарные файлы по ссылке http://downloads.mongodb.org/win32/mongodb-win32-x86_64-2008plus-3.0.1.zip
2. Разархивируем в любое удобное место
3. Запускаем из командной строки демон базы mongod.exe с параметром --dbpath, указывающего, в какой папке будут храниться непосредственно сами базы с данными. В моем случае эта команда выглядит так:
Код:
e:\Mongo\mongodb-win32-x86_64-2008plus-3.0.1\bin\mongod.exe --dbpath e:\Mongo\data
Код:
public class Contact
{
public string email { get; set; }
public string phone { get; set; }
}
public class User
{
public ObjectId Id { get; set; }
public string name { get; set; }
public string surname { get; set; }
public int age { get; set; }
public Contact contactInfo { get; set; }
}
// Устанавливаем соединение с сервером базы данных
var server = new MongoClient().GetServer();
// Так можно получить названия всех баз данных
var databaseNames = server.GetDatabaseNames();
// Подключаемся к базе данных. Даже если БД с таким названием нет,
// она автоматически будет создана при записи данных в нее
var database = server.GetDatabase("users_database");
// Таким образом можно получить названия всех коллекций в этой БД
var collectionNames = database.GetCollectionNames();
// Выбираем коллекцию, с которой будем работать
// т.к. коллекции с таким названием пока в БД нет, она будет создана
var users = database.GetCollection<User>("users");
var user = new User { name = "John", surname = "Smith", age = 31, contactInfo = new Contact { email = "john.smith@gmail.com", phone = "+7 (987) 654-32-10" } };
// Записываем пользователя в нашу коллекцию users
users.Insert(user);
// Так можно получить всех юзеров в коллекции
var cursor = users.FindAll();
foreach (var userData in cursor)
{
// И проитерироваться по ним, получая доступ к интересующим данным
}
// А так можно выбрать всех людей, с фамилией Smith
cursor = users.Find(Query.EQ("surname", "Smith"));
// Выбираем всех юзеров от 18 лет и старше
cursor = users.Find(Query.GTE("age", 18));
// Условия можно комбинировать
cursor = users.Find(Query.And(Query.EQ("surname", "Smith"), Query.GTE("age", 18)));
// Удалить коллекцию с таким именем, если она существует в этой базе
database.DropCollection("users");
// Удалить базу данных, если база с таким именем существует
server.DropDatabase("users_database");- Тема статьи
- Парсинг
- Номер конкурса статей
- Седьмой конкурс статей
Вложения
-
426,8 КБ Просмотры: 879
-
19,2 КБ Просмотры: 803
Для запуска проектов требуется программа ZennoPoster или ZennoDroid.
Это основное приложение, предназначенное для выполнения автоматизированных шаблонов действий (ботов).
Подробнее...
Для того чтобы запустить шаблон, откройте нужную программу. Нажмите кнопку «Добавить», и выберите файл проекта, который хотите запустить.
Подробнее о том, где и как выполняется проект.
Последнее редактирование: