

- Регистрация
- 20.11.2020
- Сообщения
- 165
- Благодарностей
- 145
- Баллы
- 43
Привет всем! Меня зовут Александр и я впервые участвую в конкурсе статей.
Долго думал на какую тему написать, но многие проекты сейчас в процессе тестирования и возможно станут темами для последующих конкурсов, а сегодня я расскажу о том, как я вздумал спарсить с сайта гос. закупок в Казахстана всех участников тендеров и выгрузить всё это на свой сайт в качестве подпроекта на поддомене к белому сайту близкому по тематике.
Немного предыстории.
-----------
Я сам практикующий SEO специалист и занимаюсь в основном клиентскими проектами и своими белыми контентными сайтами.
Примерно с год назад я решил начать тестировать себя в дорвеях, купив в том числе лицензию Зенки для автоматизации.
На практике среди моих клиентов были в том числе с такого плана сайты - сервисы проверки контрагентов, тендерные площадки и все они так или иначе напрямую или через api парсили данные с гос. сайтов и агрегировали их у себя. Трафика в этой нише в рамках информации доступной на гос. сайтах и её агрегации на внешнем сайте порядка от 50к у слабых и до 500к посетителей в месяц в мощных проектов.
Я четко видел и понимал, что это просто горы трафика по НЧ запросам вроде БИН участника, ФИО, наименование компании и т.д.
У меня появилась идея просто в качестве эксперимента сделать шаблон на Зенке и спарсить, а после опубликовать у себя на сайте всех участников гос. закупок.
По ходу дела я учился в принципе собирать как-то одни из первых шаблонов и параллельно натыкаясь на проблемы с производительностью, ускорял их.
В итоге у меня шаблон получился из 2 частей.
В первой части я собрал урлы на всех участников госзакупа отсюда - их там стабильно 350-400к
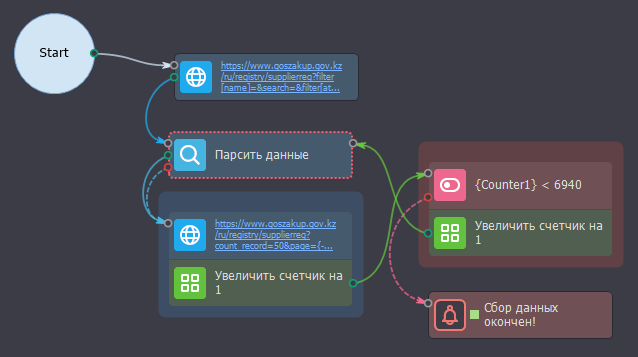
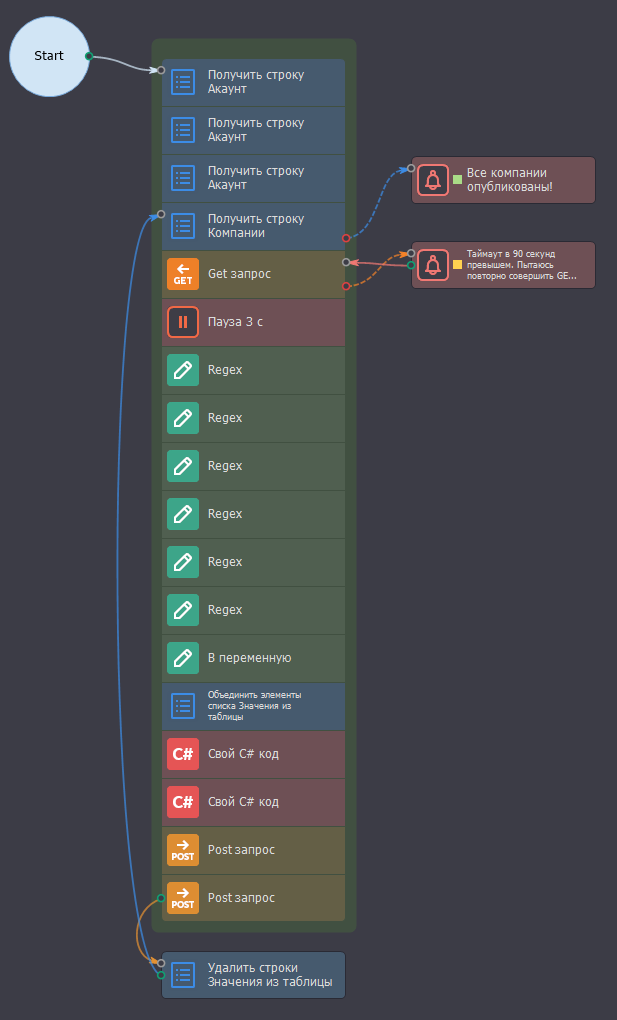
Вторым этапом я на лету переходил по урлу из списка рандомно и собирал внутри информацию - название компании, содержимое таблицы внутри со всеми данными о ней, что есть в данном открытом источнике и отдельными столбцами в таблицу выгружал ФИО и ИИН руководителя.
Здесь же на лету всё это добро публиковалось на сайт на Wordpress через XML-RPC на post-запросах - такое делал впервые и изрядно помучался, настроивая.
Скорость с которой всё начало работать просто восхищала - парсинг и одновременно публикация 1200 записей в час. Меня это более чем устраивало, но через примерно сутки скорость сократилась вдвое и после постепенно замедлилось чуть ли не до 20-50 записей в час.
Дело в том и это опыт №1, что я не учел возможности любимого движка Worpress, где все уперлось в разросшуюся до неприличия базу данных. Всё жутко тормозило именно из-да БД и скорости записи в неё на объёмах.
Я привык делать обычными сайты на сотни, иногда тысячи страниц и банально с таким не сталкивался ранее, хотя и дружу с ВП порядка 10 лет. Начал искать как оптимизировать эти процессы, открыл для себя много нового, но особо ничего не помогло.
В итоге я на какое-то время отложил этот эксперимент, чтобы там все запостилось, закэшировалось и прочие процессы прошли без серьезной нагрузки сверху.
Спустя месяца полтора я вернулся к проекту и немного переделав шаблон с паузами и другими фишками, получил новое свежее дыхание для эксперимента. Скорость одновременного парсинга и публикации сразу достигала в пиковые моменты 3500 записей. Сервер серьезно напрягался, но в целом все выдержал.
В итоге такими итерациями я постепенно опубликовал порядка 250к участников закупок и по 2 тега на каждую запись, что в итоге мне дало примерно 750к посадочных страниц под НЧ. Я всё как положено оптимизировал по шаблону и настроил корректную индексацию.
Постепенно страницы начали залетать в индекс и спустя время трафик вырос до 1000-1500 посетителей в сутки. Повесил туда Adsense и что-то начало капать. Вроде кажется, что всё - больше ничего не нужно - жди пока все страницы проиндексируются, трафик вырастет и денег с рекламы станет больше.
Но не тут-то было и опыт №2 - не шутите с госами.
Первое, что мне прилетело - жалоба на меня от комитета государственных доходов (КГД) т.к. я ради привлечения внимания упомянул на сайте что это база КГД. На самом деле все эти данные между собой связаны и есть в обоих источниках, но на сайте гос. закупа в открытом доступе, а в КГД где-то внутри за 7ю дверьми спрятано и они подумали что я их взломал или как-то еще незаконно получил эти данные.
Всё решились простым телефонным разговором с сотрудником комитета информационной безопасности (или как-то иначе они называются)
Условились на том, что я просто уберу везде упоминание КГД и напишу как есть откуда данные и что они взяты строго из открытого источника без злых намерений - что на самом деле так и есть. Мой интерес в данном эксперименте строго в получении кучи трафика по НЧ запросам - не более.
На какое-то время настала тишина по таким вопросам. Я спокойно смотрел как растет трафик и всё что следует за ним. Но не долго музыка играла.
Здесь начинается мой опыт №3. В отличие от всех сервисов агрегации данных, где всё по нескольку раз на день сверяется и синхронизируется с официальными источниками, у меня на сайте все было статично - я просто разово спарсил кучу данных и опубликовал у себя на сайте.
Если кто-то связан с подобного рода проектами или тендерами, Вы знаете, что данные там постоянно изменяются, появляются новые участники гос. закупок, уходят старые, выкладываются новые лоты и прочая динамичность. Из-за статики в данных у меня на проекте я не переживал, что упущу трафик - мне было достаточно 750к страниц для эксперимента, но не всё так просто.
Мне начали поступать звонки с того же управления, которое рассматривает все жалобы на сайты вокруг гос. и не только. Получалось такое, что кто-то удалял свои данные с сайта госзакупок, а у меня они были опубликованы и меня вежливо просили удалить определенные данные с сайта и после еще написать официальный ответ от имени владельца ресурса, что вот мол данные о таком-то с такого-то сайта удалены.
Также было много обращений вроде такого: поменять почти и номер телефона компании у нас в базе т.к. на официальном сайте и в других места они сами изменили всё, а у нас с статике стоит последние несколько месяцев устаревшая информация.
В конце концов, после очередного такого запроса, я устал отвлекаться и просто снёс проект, посчитав его по-своему успешным экспериментом.
Вы можете попробовать повторить мой опыт - это правда было увлекательно и полезно для опыта, но без нормальной динамики в синхронизации данных из разных источников от такого проекта можно получить больше нервотрепки, чем трафика и денег :-)")
Вот и всё - такая вот получилась история, надеюсь вам понравилось. Жду в комментариях 8-)")
Долго думал на какую тему написать, но многие проекты сейчас в процессе тестирования и возможно станут темами для последующих конкурсов, а сегодня я расскажу о том, как я вздумал спарсить с сайта гос. закупок в Казахстана всех участников тендеров и выгрузить всё это на свой сайт в качестве подпроекта на поддомене к белому сайту близкому по тематике.
Немного предыстории.
-----------
Я сам практикующий SEO специалист и занимаюсь в основном клиентскими проектами и своими белыми контентными сайтами.
Примерно с год назад я решил начать тестировать себя в дорвеях, купив в том числе лицензию Зенки для автоматизации.
На практике среди моих клиентов были в том числе с такого плана сайты - сервисы проверки контрагентов, тендерные площадки и все они так или иначе напрямую или через api парсили данные с гос. сайтов и агрегировали их у себя. Трафика в этой нише в рамках информации доступной на гос. сайтах и её агрегации на внешнем сайте порядка от 50к у слабых и до 500к посетителей в месяц в мощных проектов.
Я четко видел и понимал, что это просто горы трафика по НЧ запросам вроде БИН участника, ФИО, наименование компании и т.д.
У меня появилась идея просто в качестве эксперимента сделать шаблон на Зенке и спарсить, а после опубликовать у себя на сайте всех участников гос. закупок.
По ходу дела я учился в принципе собирать как-то одни из первых шаблонов и параллельно натыкаясь на проблемы с производительностью, ускорял их.
В итоге у меня шаблон получился из 2 частей.
В первой части я собрал урлы на всех участников госзакупа отсюда - их там стабильно 350-400к
Вторым этапом я на лету переходил по урлу из списка рандомно и собирал внутри информацию - название компании, содержимое таблицы внутри со всеми данными о ней, что есть в данном открытом источнике и отдельными столбцами в таблицу выгружал ФИО и ИИН руководителя.
Здесь же на лету всё это добро публиковалось на сайт на Wordpress через XML-RPC на post-запросах - такое делал впервые и изрядно помучался, настроивая.
Скорость с которой всё начало работать просто восхищала - парсинг и одновременно публикация 1200 записей в час. Меня это более чем устраивало, но через примерно сутки скорость сократилась вдвое и после постепенно замедлилось чуть ли не до 20-50 записей в час.
Дело в том и это опыт №1, что я не учел возможности любимого движка Worpress, где все уперлось в разросшуюся до неприличия базу данных. Всё жутко тормозило именно из-да БД и скорости записи в неё на объёмах.
Я привык делать обычными сайты на сотни, иногда тысячи страниц и банально с таким не сталкивался ранее, хотя и дружу с ВП порядка 10 лет. Начал искать как оптимизировать эти процессы, открыл для себя много нового, но особо ничего не помогло.
В итоге я на какое-то время отложил этот эксперимент, чтобы там все запостилось, закэшировалось и прочие процессы прошли без серьезной нагрузки сверху.
Спустя месяца полтора я вернулся к проекту и немного переделав шаблон с паузами и другими фишками, получил новое свежее дыхание для эксперимента. Скорость одновременного парсинга и публикации сразу достигала в пиковые моменты 3500 записей. Сервер серьезно напрягался, но в целом все выдержал.
В итоге такими итерациями я постепенно опубликовал порядка 250к участников закупок и по 2 тега на каждую запись, что в итоге мне дало примерно 750к посадочных страниц под НЧ. Я всё как положено оптимизировал по шаблону и настроил корректную индексацию.
Постепенно страницы начали залетать в индекс и спустя время трафик вырос до 1000-1500 посетителей в сутки. Повесил туда Adsense и что-то начало капать. Вроде кажется, что всё - больше ничего не нужно - жди пока все страницы проиндексируются, трафик вырастет и денег с рекламы станет больше.
Но не тут-то было и опыт №2 - не шутите с госами.
Первое, что мне прилетело - жалоба на меня от комитета государственных доходов (КГД) т.к. я ради привлечения внимания упомянул на сайте что это база КГД. На самом деле все эти данные между собой связаны и есть в обоих источниках, но на сайте гос. закупа в открытом доступе, а в КГД где-то внутри за 7ю дверьми спрятано и они подумали что я их взломал или как-то еще незаконно получил эти данные.
Всё решились простым телефонным разговором с сотрудником комитета информационной безопасности (или как-то иначе они называются)
Условились на том, что я просто уберу везде упоминание КГД и напишу как есть откуда данные и что они взяты строго из открытого источника без злых намерений - что на самом деле так и есть. Мой интерес в данном эксперименте строго в получении кучи трафика по НЧ запросам - не более.
На какое-то время настала тишина по таким вопросам. Я спокойно смотрел как растет трафик и всё что следует за ним. Но не долго музыка играла.
Здесь начинается мой опыт №3. В отличие от всех сервисов агрегации данных, где всё по нескольку раз на день сверяется и синхронизируется с официальными источниками, у меня на сайте все было статично - я просто разово спарсил кучу данных и опубликовал у себя на сайте.
Если кто-то связан с подобного рода проектами или тендерами, Вы знаете, что данные там постоянно изменяются, появляются новые участники гос. закупок, уходят старые, выкладываются новые лоты и прочая динамичность. Из-за статики в данных у меня на проекте я не переживал, что упущу трафик - мне было достаточно 750к страниц для эксперимента, но не всё так просто.
Мне начали поступать звонки с того же управления, которое рассматривает все жалобы на сайты вокруг гос. и не только. Получалось такое, что кто-то удалял свои данные с сайта госзакупок, а у меня они были опубликованы и меня вежливо просили удалить определенные данные с сайта и после еще написать официальный ответ от имени владельца ресурса, что вот мол данные о таком-то с такого-то сайта удалены.
Также было много обращений вроде такого: поменять почти и номер телефона компании у нас в базе т.к. на официальном сайте и в других места они сами изменили всё, а у нас с статике стоит последние несколько месяцев устаревшая информация.
В конце концов, после очередного такого запроса, я устал отвлекаться и просто снёс проект, посчитав его по-своему успешным экспериментом.
Вы можете попробовать повторить мой опыт - это правда было увлекательно и полезно для опыта, но без нормальной динамики в синхронизации данных из разных источников от такого проекта можно получить больше нервотрепки, чем трафика и денег
Вот и всё - такая вот получилась история, надеюсь вам понравилось. Жду в комментариях
- Тема статьи
- SEO / PPC, Парсинг
- Номер конкурса статей
- Шестнадцатый конкурс статей
Вложения
-
39 КБ Просмотры: 315
Для запуска проектов требуется программа ZennoPoster или ZennoDroid.
Это основное приложение, предназначенное для выполнения автоматизированных шаблонов действий (ботов).
Подробнее...
Для того чтобы запустить шаблон, откройте нужную программу. Нажмите кнопку «Добавить», и выберите файл проекта, который хотите запустить.
Подробнее о том, где и как выполняется проект.
Последнее редактирование:

 .
.