В прошлой статье я показал, как парсить на веб. В этой статье разберем парсинг на запросах. Писать будем парсер нашего любимого форума zennolab. Несколько предупреждений:
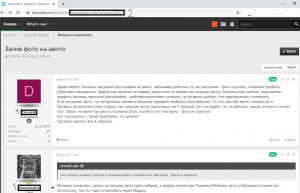
Собирать будем ссылки на профили пользователей. Парсить мы будем активных пользователей, т.е. тех, кто оставляет сообщения. Нужные нам ссылки на профили находятся здесь (1):
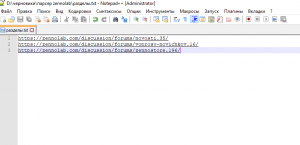
Зальем в txt файл ссылки на разделы, которые хотим парсить. Для примера взял «новости», «партнерская программа», «ZennoStore»
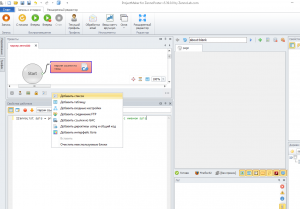
Создаем кубик c# и привязываемся к нашему txt файлу:
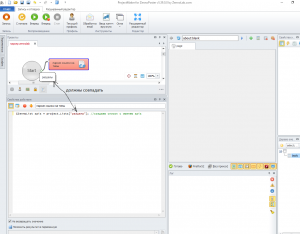
В кубике c# мы создали список (далее к нему будем обращаться по имени spis):
Создадим цикл и возьмем первый раздел:
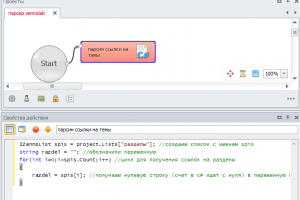
Теперь спарсим html-код страницы. Делается это следующим образом:
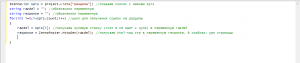
Так, теперь у нас в переменной response хранится код вот этой страницы - https://zennolab.com/discussion/forums/novosti.35/
Сейчас нам надо составить xpath путь до нужных нам ссылок. Идем в гугл хром, открываем страницу, устанавливаем плагин Xpath Helper Wizard (если его нет, устанавливаем). Посмотрим, как можно выцепить нужные нам ссылки. Жмем по ним правой кнопкой мыши, смотрим в код:
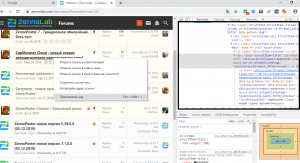
За сами ссылки не зацепиться, будем брать элементы повыше. Видим, что у него есть «родитель» <div class="structItem-title">
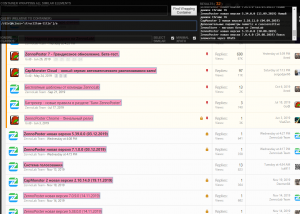
Видим, что данный вариант нам подходит. На всякий случай разберем наш xpath путь (//div[@class='structItem-title']/a). Я сказал, что мне надо найти тег div с классом равным 'structItem-title', а затем найти его «ребенка» тег a.
Ок, xpath путь мы составили. Чтобы нам спарсить эти элементы нам понадобится ещё два списка:
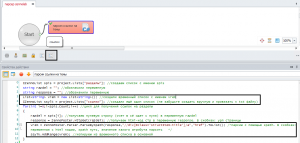
Запустим шаблон. Зайдем в наш файл ссылки.txt и убедимся, что всё норм.
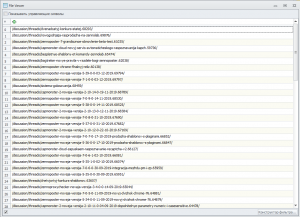
Всё норм, но перед /discussion/ не хватает https://zennolab.com/. Мы это потом поправим.
Сейчас мы с вами получили парсинг только трех страниц, указанных в txt файле. Нам надо собрать остальные. Как мы это сделаем? Мы будем искать кнопку Next до тех пор, пока она не исчезнет.
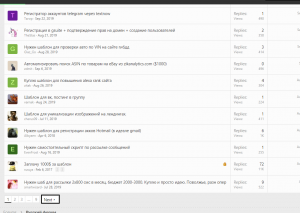
Т.е.логика у нас такая:
Что хочу отметить:
Я в многопотоке не силен, но решил включить в статью, чтобы вы могли с чего-то начать. В общем, у нас есть такая конструкция:
Если вы что-то напишите внутри него, то остальные потоки будут ждать. SyncObjects может быть 3 видов:
SyncObjects.ListSyncer - для списков
SyncObjects.TableSyncer - для таблиц
SyncObjects.InputSyncer - для буфера обмена
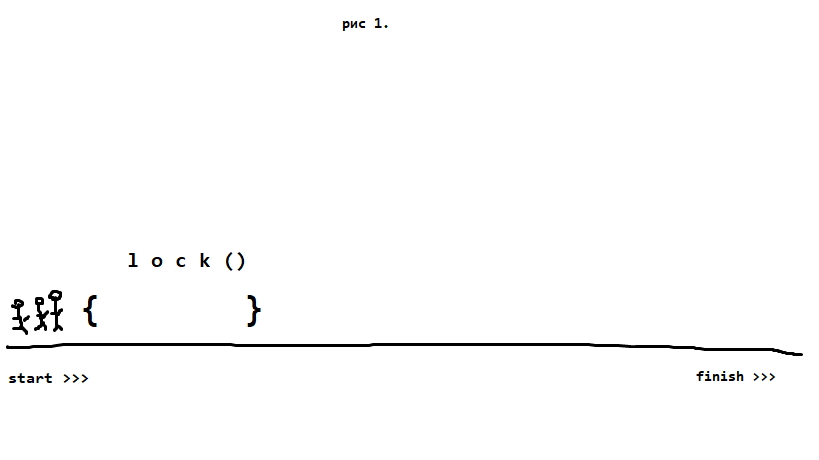
Вот нарисовал для себя как это работает, может кому-то будет полезно. Предположим, что у нас есть 3 спортсмена, которые стартуют одновременно:
Затем кто-то из них (тот, кто первый =) ) заходит в поле lock. Остальные при этом туда зайти не могут и ждут, пока тот выбежет оттуда.
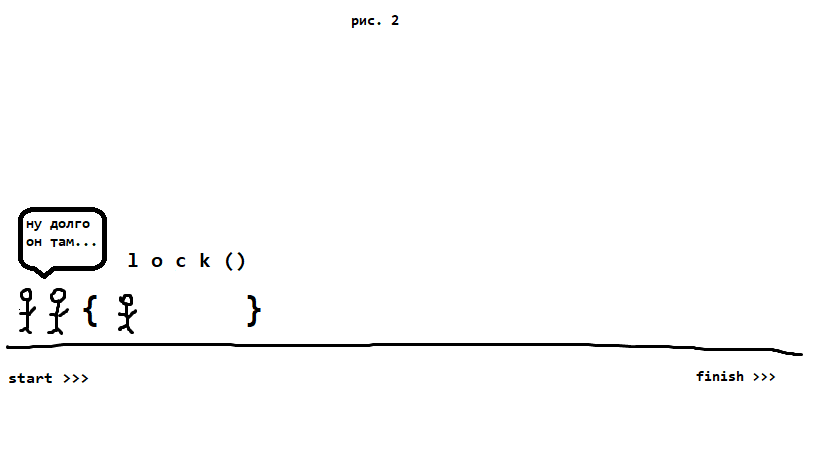
Когда чел выходит из поля lock(){}, туда запускают ещё одного (только одного (!))
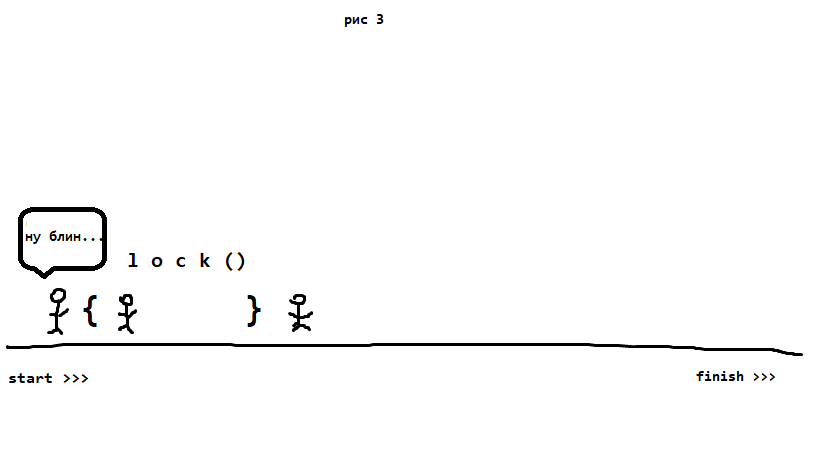
У нас в коде может быть несколько lock(). При этом сколько бы их ни было, в поле может находиться только один чел.
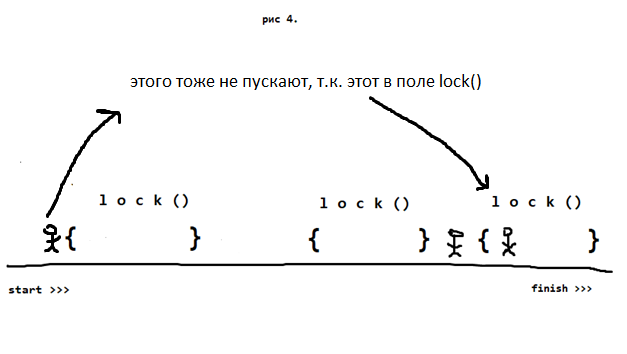
О последнем факте и о том, что бывает не только SyncObjects.ListSyncer, я узнал совсем недавно вот отсюда (рекомендую ознакомиться).
С детским садом закончили, перейдем к практике. Как мы с вами поступим:
Давайте реализуем это:
Ап. Начал тестить шаблон и нашел косяки. Какие нюансы:
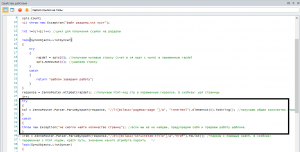
Теперь по второму пункту. Переделаем xpath путь. И добавим проверку. В общем, если зайти на стр то можно увидеть общее количество страниц:
Если наш шаблон вывалился в catch, то делаем проверку: равна ли последняя цифра в урл этой цифре. Если нет, то выведем себе сообщение, что наш xpath путь фуфло. Т.е. мы будем сравнивать вот эти две цифры:
Получаем цифру (где постраничная пагинация)
Сравниваем:
И теперь по третьему пункту:
При работе на запросах можно поставить галочку «без браузера».
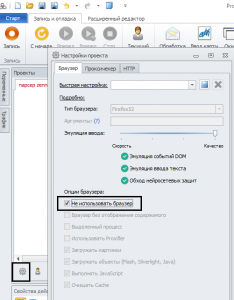
Тут принцип тот же. Создаем новый кубик и действуем по следующей схеме:
Реализацию можно посмотреть в шаблоне. Спасибо за внимание.
- Статья для новичков
- В статье могут быть неточности в терминах ввиду неопытности автора
- Шаблон писался на последней версии (5.39.0.0)
- Не рассматривается вариант, когда какие-либо данные подгружаются скриптом
- В этой статье на логике я останавливаться не буду. Просто покажу, как парсить на запросах простенькие сайты. Если вы пока не понимаете, как писать парсеры, то можете ознакомиться с моей предыдущей статьей.
Подготовка
Собирать будем ссылки на профили пользователей. Парсить мы будем активных пользователей, т.е. тех, кто оставляет сообщения. Нужные нам ссылки на профили находятся здесь (1):
Зальем в txt файл ссылки на разделы, которые хотим парсить. Для примера взял «новости», «партнерская программа», «ZennoStore»
Создаем кубик c# и привязываемся к нашему txt файлу:
В кубике c# мы создали список (далее к нему будем обращаться по имени spis):
C#:
IZennoList spis = project.Lists["разделы"]; //создаем список с именем spisТеперь спарсим html-код страницы. Делается это следующим образом:
Так, теперь у нас в переменной response хранится код вот этой страницы - https://zennolab.com/discussion/forums/novosti.35/
Сейчас нам надо составить xpath путь до нужных нам ссылок. Идем в гугл хром, открываем страницу, устанавливаем плагин Xpath Helper Wizard (если его нет, устанавливаем). Посмотрим, как можно выцепить нужные нам ссылки. Жмем по ним правой кнопкой мыши, смотрим в код:
За сами ссылки не зацепиться, будем брать элементы повыше. Видим, что у него есть «родитель» <div class="structItem-title">
Видим, что данный вариант нам подходит. На всякий случай разберем наш xpath путь (//div[@class='structItem-title']/a). Я сказал, что мне надо найти тег div с классом равным 'structItem-title', а затем найти его «ребенка» тег a.
Ок, xpath путь мы составили. Чтобы нам спарсить эти элементы нам понадобится ещё два списка:
- Один временный - List<string> vrem = new List<string>();
- Другой основной - IZennoList ssylk = project.Lists["ссылки"]
Запустим шаблон. Зайдем в наш файл ссылки.txt и убедимся, что всё норм.
Всё норм, но перед /discussion/ не хватает https://zennolab.com/. Мы это потом поправим.
Парсим остальные страницы
Сейчас мы с вами получили парсинг только трех страниц, указанных в txt файле. Нам надо собрать остальные. Как мы это сделаем? Мы будем искать кнопку Next до тех пор, пока она не исчезнет.
Т.е.логика у нас такая:
- находим кнопку Next
- если она есть, то берем у неё href
- загружаем html-код стр
- парсим что нам нужно
- находим кнопку Next, если она есть, то берем у неё href
- загружаем html-код стр
- и т.д.
Что хочу отметить:
- обратите внимание на 13 строку. Тут мы уже складываем в переменную, отбирая только один элемент (с помощью ElementAt(0))
- Если в результате выполнения ZennoPoster.Parser.ParseBByXpath ничего не найдется, то будет ошибка. Именно поэтому мы обернули данный код в try-catch. Т.е. если ничего не будет найдено, то будет ошибка и шаблон перейдет к выполнению того, что написано внутри catch {}. Там я говорю, что надо выйти из цикла (значит, мы больше не нашли кнопок Next)
- Если xpath пути привязываете к названиям (например, //a[contains(string(), 'ZennoDroid')]), то следите за тем, чтобы на сайте не было нескольких языковых версий (обжегся на этом, пока писал данный код)
Многопоток
Я в многопотоке не силен, но решил включить в статью, чтобы вы могли с чего-то начать. В общем, у нас есть такая конструкция:
Если вы что-то напишите внутри него, то остальные потоки будут ждать. SyncObjects может быть 3 видов:
SyncObjects.ListSyncer - для списков
SyncObjects.TableSyncer - для таблиц
SyncObjects.InputSyncer - для буфера обмена
Вот нарисовал для себя как это работает, может кому-то будет полезно. Предположим, что у нас есть 3 спортсмена, которые стартуют одновременно:
Затем кто-то из них (тот, кто первый =) ) заходит в поле lock. Остальные при этом туда зайти не могут и ждут, пока тот выбежет оттуда.
Когда чел выходит из поля lock(){}, туда запускают ещё одного (только одного (!))
У нас в коде может быть несколько lock(). При этом сколько бы их ни было, в поле может находиться только один чел.
О последнем факте и о том, что бывает не только SyncObjects.ListSyncer, я узнал совсем недавно вот отсюда (рекомендую ознакомиться).
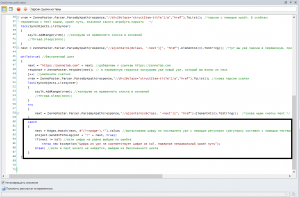
С детским садом закончили, перейдем к практике. Как мы с вами поступим:
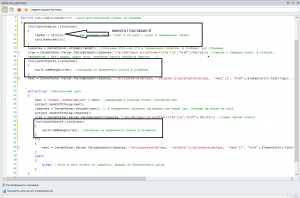
- На 8-й строке мы с вами получаем строку (razdel = spis), в которой содержится категория. Нам нельзя, чтобы несколько потоков её взяли. Поэтому мы её залочим и после взятия удалим
Соответственно, следующий поток уже не сможет взять тот же урл (мы его удалили), он возьмет уже следующий и будет работать с ним.
Следующий лок нам нужен тогда, когда мы записываем в наш основной txt файл, чтобы не получилось так, что несколько потоков одновременно засовывают туда информацию. Это 12 строка и 23 строка
Давайте реализуем это:
Ап. Начал тестить шаблон и нашел косяки. Какие нюансы:
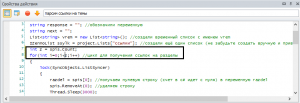
- Во-первых, я забыл поменять шестую строку. Поскольку мы с вами теперь удаляем строки из файла, то spis.Count у нас постоянно уменьшается. Её надо за циклом записать в переменную и в цикле уже подставлять именно переменную
- Во-вторых, при парсинге выяснился такой нюанс: например, на 5 странице мой Xpath путь работает, а на шестой уже нет. Из-за этого собирались не все данные
- При запуске многопотока выходит ошибка, что индекс за пределами диапазона
Теперь по второму пункту. Переделаем xpath путь. И добавим проверку. В общем, если зайти на стр то можно увидеть общее количество страниц:
Если наш шаблон вывалился в catch, то делаем проверку: равна ли последняя цифра в урл этой цифре. Если нет, то выведем себе сообщение, что наш xpath путь фуфло. Т.е. мы будем сравнивать вот эти две цифры:
Получаем цифру (где постраничная пагинация)
Сравниваем:
И теперь по третьему пункту:
При работе на запросах можно поставить галочку «без браузера».
Парсим пользователей
Тут принцип тот же. Создаем новый кубик и действуем по следующей схеме:
- Создаем цикл
- Берем урл
- Удаляем его
- Делаем запрос
- Вытаскиваем профили пользователей
- Перебираем их в цикле
- Складываем в список
Реализацию можно посмотреть в шаблоне. Спасибо за внимание.
- Тема статьи
- Парсинг
- Номер конкурса статей
- Двенадцатый конкурс статей
Вложения
-
20,5 КБ Просмотры: 411
Для запуска проектов требуется программа ZennoPoster или ZennoDroid.
Это основное приложение, предназначенное для выполнения автоматизированных шаблонов действий (ботов).
Подробнее...
Для того чтобы запустить шаблон, откройте нужную программу. Нажмите кнопку «Добавить», и выберите файл проекта, который хотите запустить.
Подробнее о том, где и как выполняется проект.
Последнее редактирование модератором:

 :-)")
 8-)")