



Пишем парсеры в Zennoposter на C#. Инструкция для новичков от новичка
Всем привет. Несколько оговорок перед началом:
Куда будем складывать данные – работа с библиотекой Epplus.dll
Полученный результат я предлагаю складывать в таблицу xls с использованием внешней библиотеки Epplus.dll. Преимущество её в том, что можно работать с несколькими листами. Перейдем к установке.
Установка библиотеки EPPlus.dll
Скачать библиотеку можно отсюда (можете качать с официального сайта, но там целая проблема найти кнопку download =) ).
Берем файл EPPlus.dll и кидаем по этому пути:
"C:\Program Files (x86)\ZennoLab\RU\ZennoPoster Pro\ваша версия\Progs\ExternalAssemblies"
В projectMaker во вкладке «Проекты» создаем «ссылки из Gac» и «Директивы using» (щелкните правой кнопкой мыши)
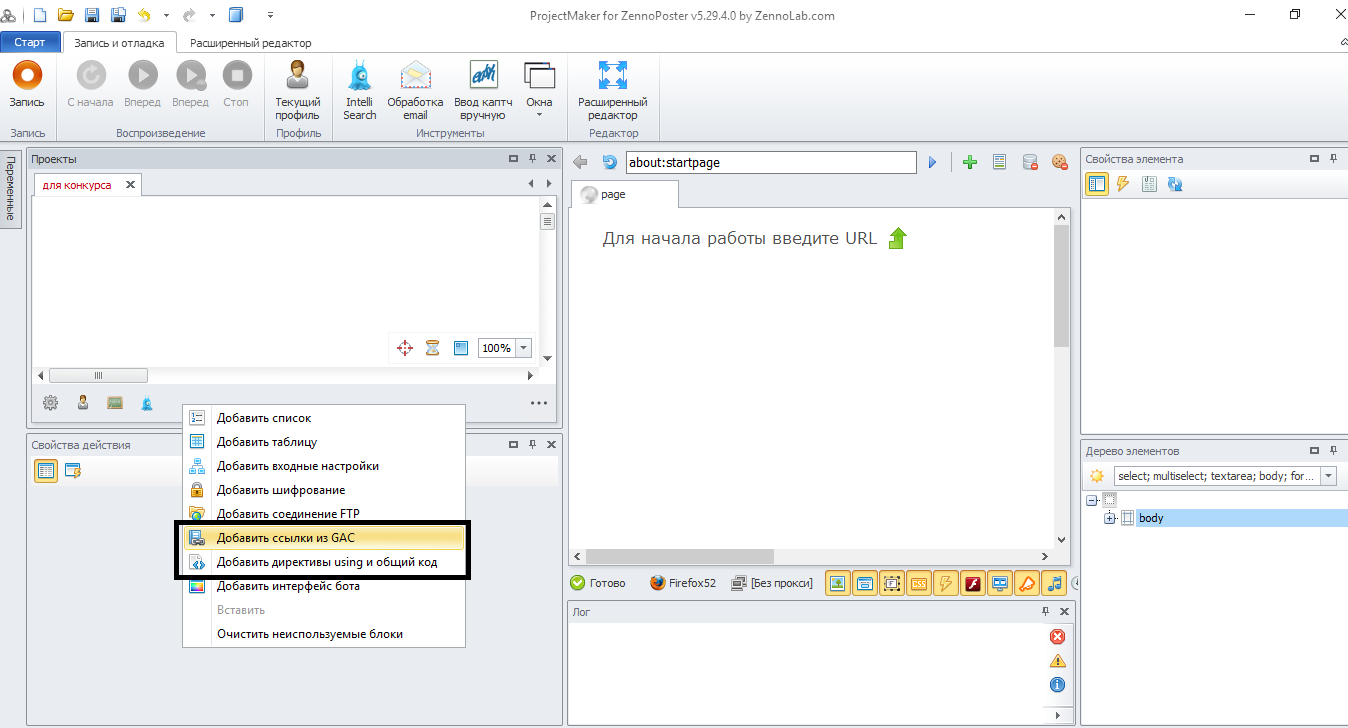
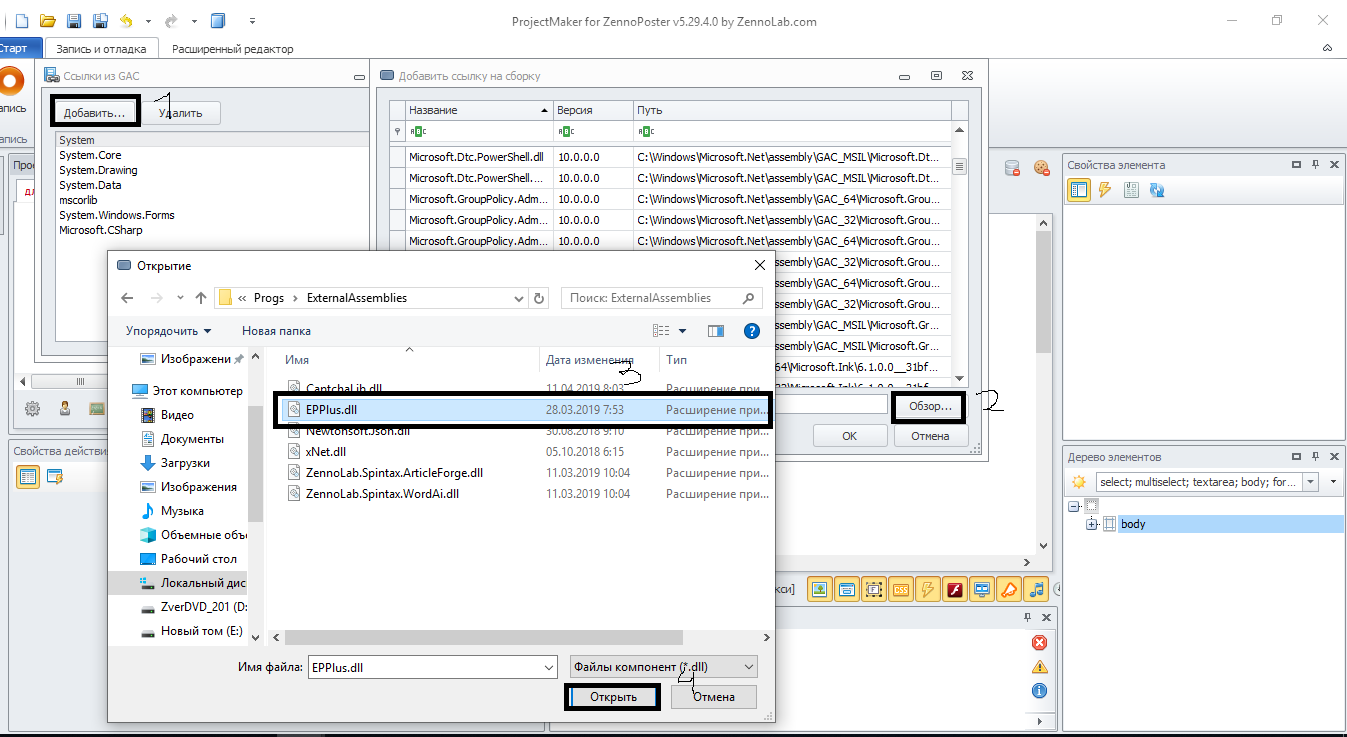
Открываем ссылки из Gac, жмем добавить, жмем обзор, выбираем файл epplus.dll, который должен быть по пути "C:\Program Files (x86)\ZennoLab\RU\ZennoPoster Pro\ваша версия\Progs\ExternalAssemblies"
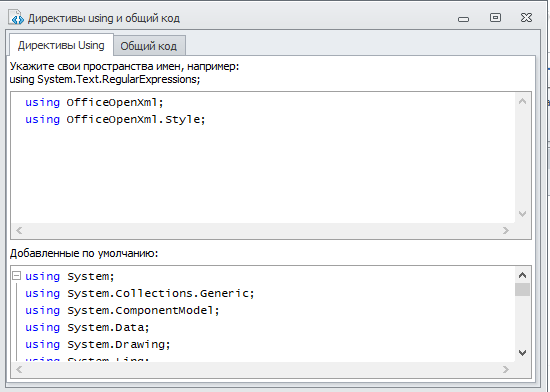
Теперь открываем «директивы using» и вставляем такой код:
Теперь создаем на компьютере xlsx табличку и можно начинать работать с ней в кубике C#.
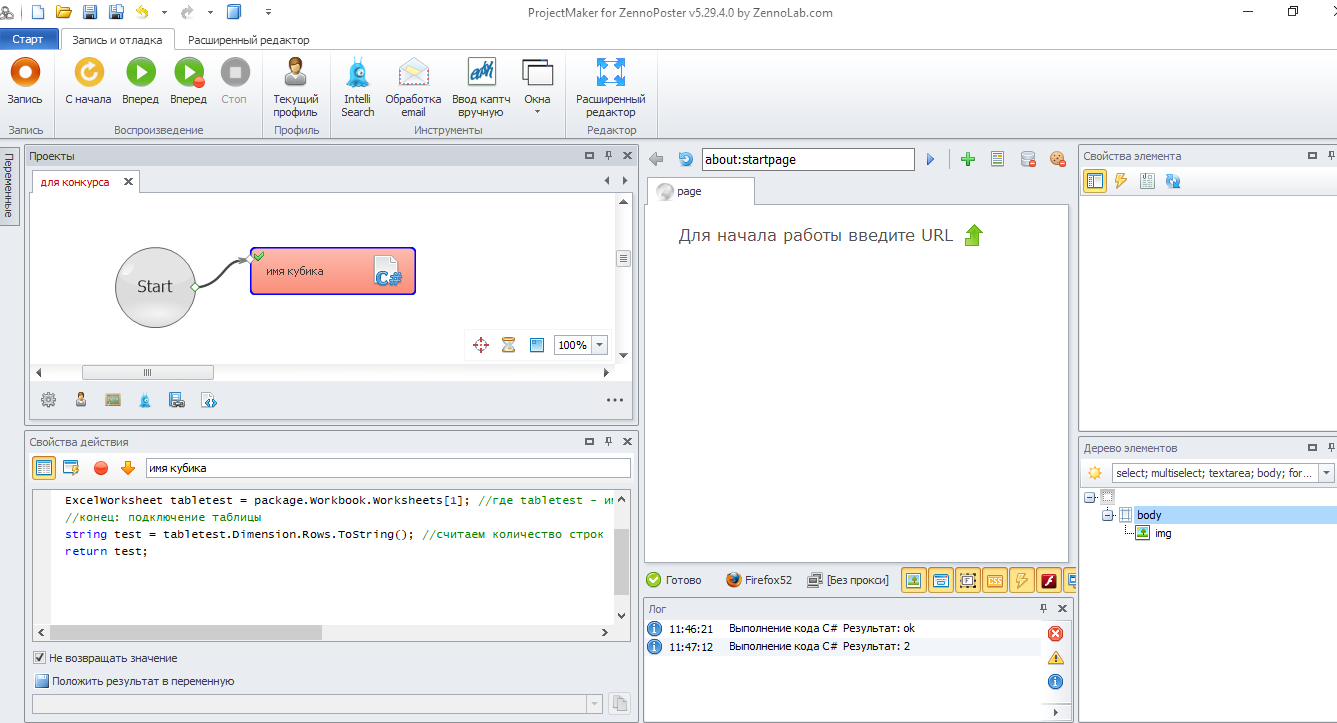
В кубике C# в свойствах действия вверху кода прописываем подключение таблицы:
В этот код вам вникать не надо(я и сам его не понимаю). Пускай стоит в самом верху, он нам не мешает. Вам надо лишь прописать свой путь (т.е. вместо «E:\zennoposter - проекты\наша табличка.xlsx» прописать путь до вашей таблицы xlsx, которую мы создали на предыдущем шаге). И вы можете вместо [1] ставить [2] или [3] и т.д. – это номера листов в Excel
Ок. Теперь научимся работать с нашей таблицей. Сначала заполним её чем-нибудь:
Чтобы получить что-то из таблицы, мы используем такой код:
Чтобы записать что-то в таблицу, мы используем такой код:
Чтобы удалить из таблицы какую-то строку или колонку, мы используем такой код:
Для примера удалил строку:
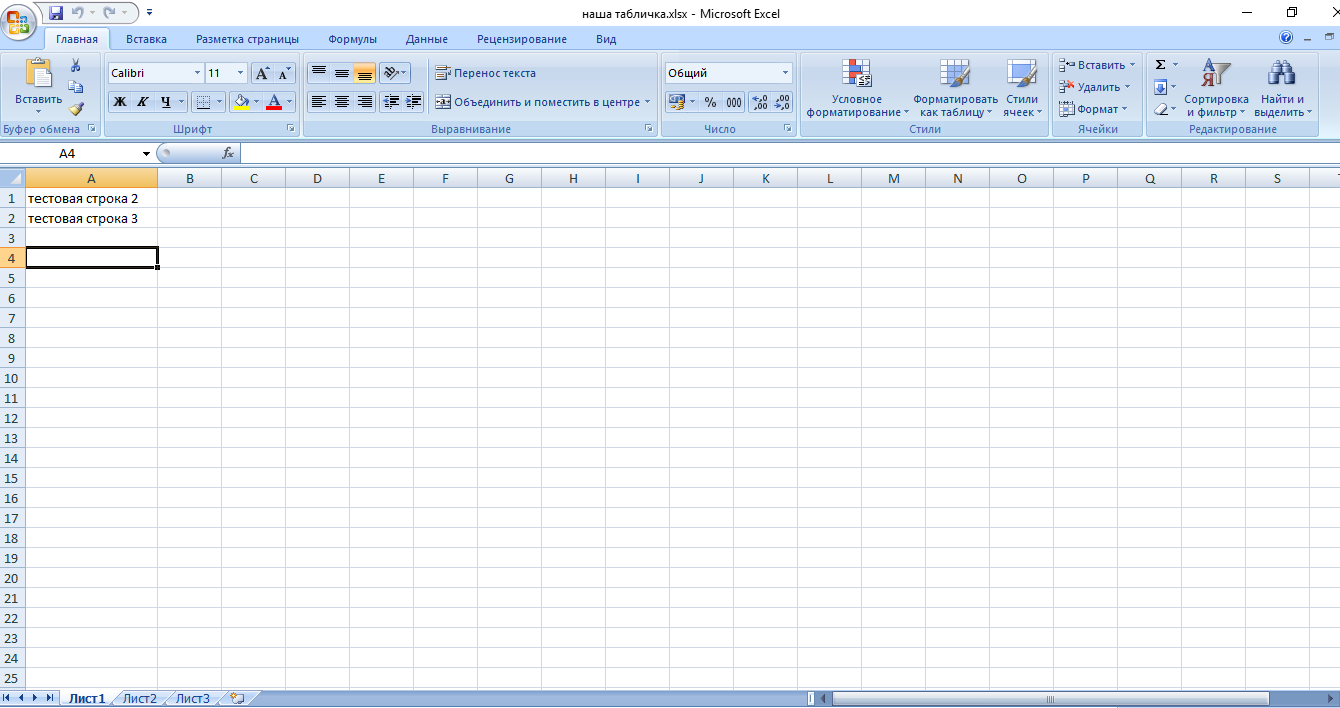
Для подсчета количества строк использовать такой код:
P.S. В Epplus.dll счет начинается не с нуля, а с одного
Учимся находить элементы на странице
Для нахождения элементов будем использовать Xpath. Установите к себе в гугл хром дополнение «Xpath Helper Wizard».
Я вам распишу то, что подходит в 80% случаев. Если захотите капнуть глубже, то почитайте статьи про xpath с предыдущих конкурсов и поизучайте примеры тут - http://www.zvon.org/xxl/XPathTutorial/General_rus/examples.html
Давайте поищем элементы на разных страницах. Начнем с ютуба. Предположим, мы хотим собрать ссылки на видео.
Давайте кратко по теории. Любая страница состоит из html тегов, например:
У этих тегов есть разные атрибуты (чаще всего), например:
Так вот, наша задача – найти нужный нам тег с нужными нам атрибутами. Далее будет понятно.
Итак, наша задача – найти ссылки. Ссылки у нас обозначаются тегом <a>. Идем в хром, жмем по значку xpath helper wizard и во второе поле пишем //a (P.S. Xpath пути всегда начинаются с двух косых черточек //)
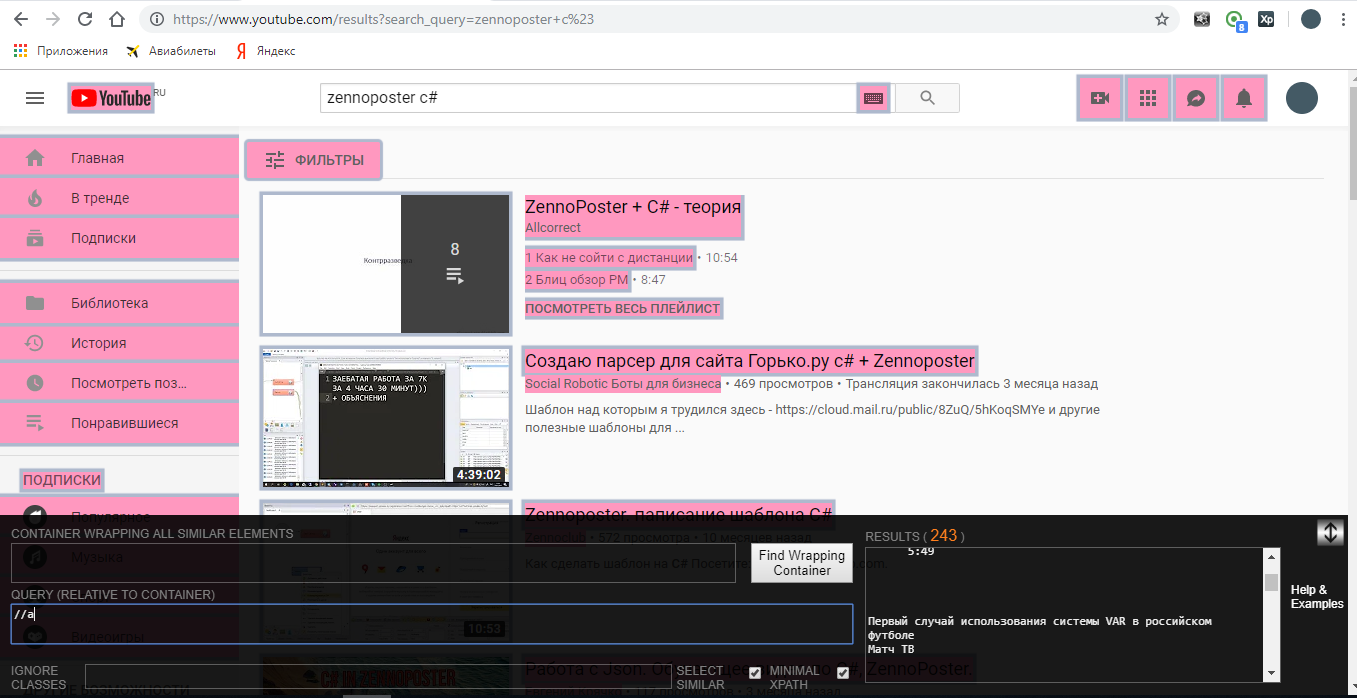
Розовое – это все ссылки на странице. Но нам ведь нужны только ссылки на видео, так? Для этого нам надо указать какой-то уникальный атрибут, который есть только у нужных нам ссылок. Сначала посмотрим, что за атрибуты есть у нужных нам ссылок. Нажмем правой кнопкой мыши по нужному нам элементу и выберем «просмотреть код».
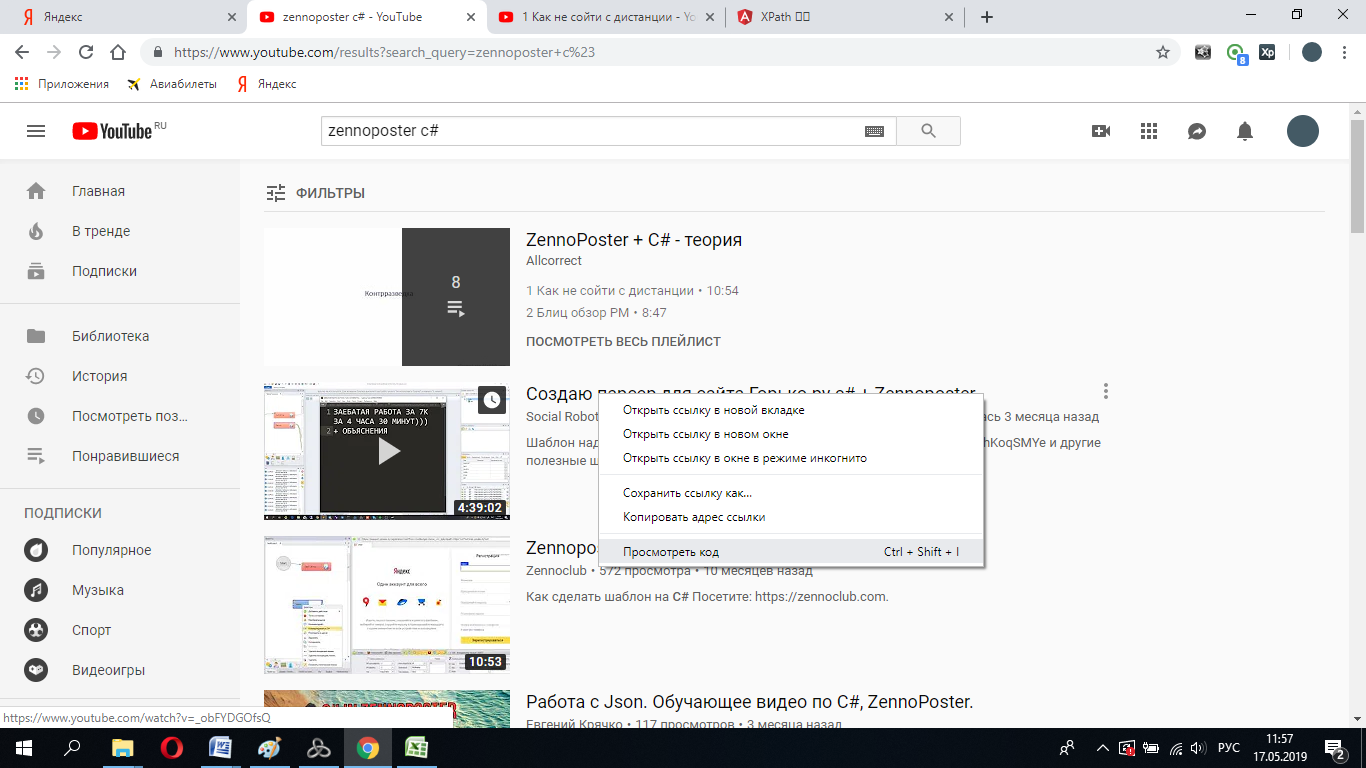
Смотрите, какие атрибуты есть у нашей ссылки: id, class, title, ahref, aria-label
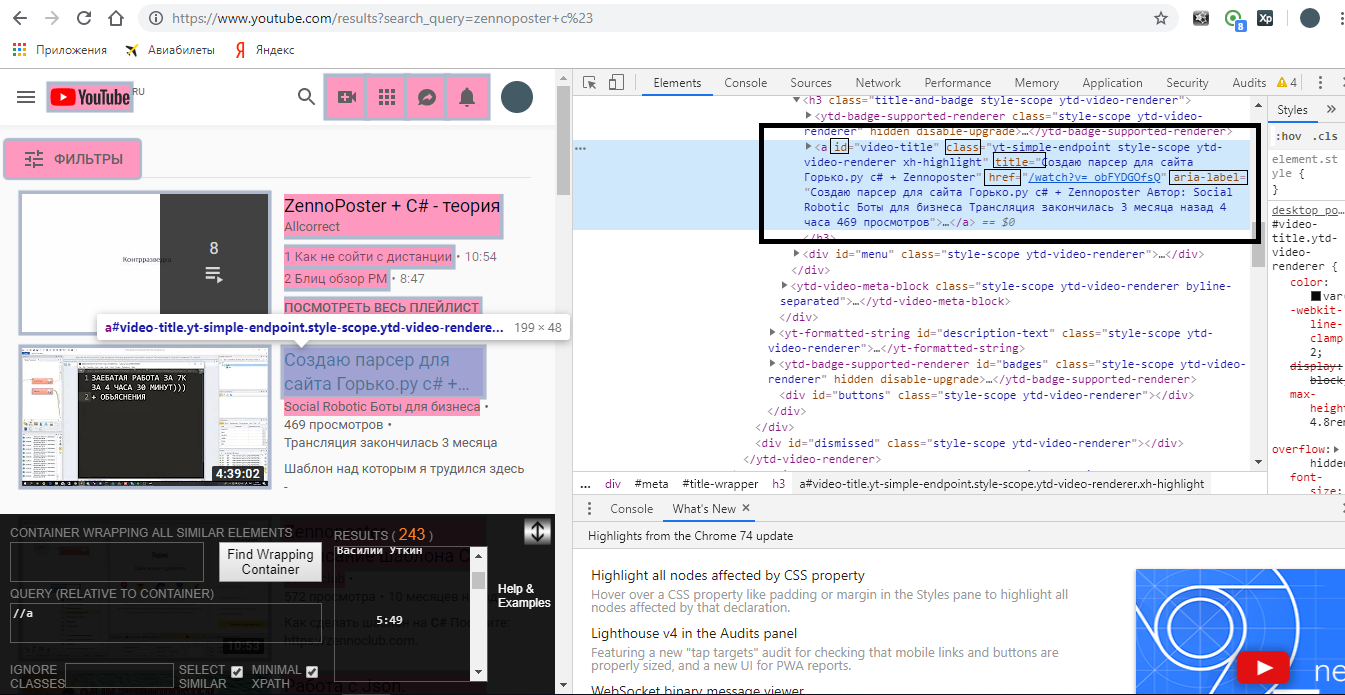
Давайте пробовать искать по ним и смотреть, какие элементы будут выделяться. В Xpath Helper Wizard пишем: //a[@id='video-title']
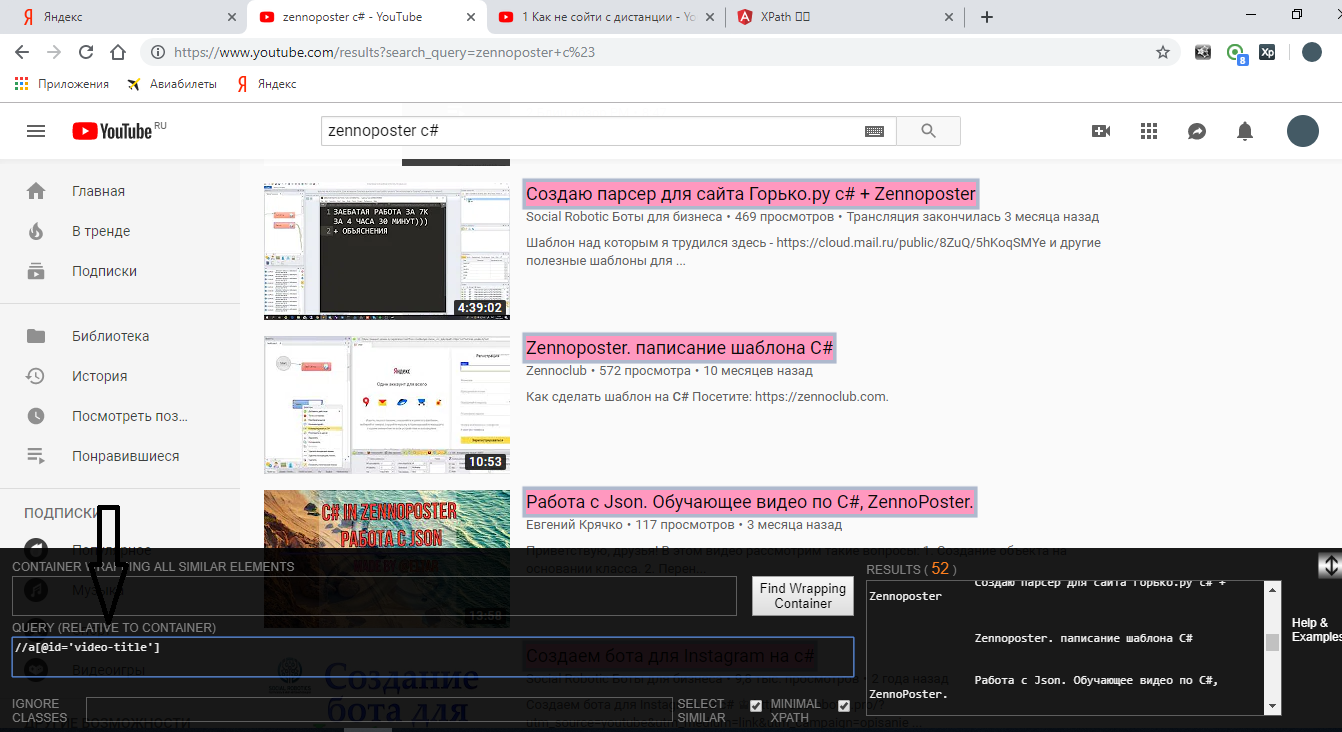
Смотрите, судя по всему выделилось именно то, что нам нужно. Если бы не нашли то, что нужно, то надо было бы пробовать дальше:
Давайте закрепим пройденное. Зайдем сюда (мы хотим спарсить ссылки на ресурсы): https://www.liveinternet.ru/rating/ru/
Жмем правой кнопкой мыши
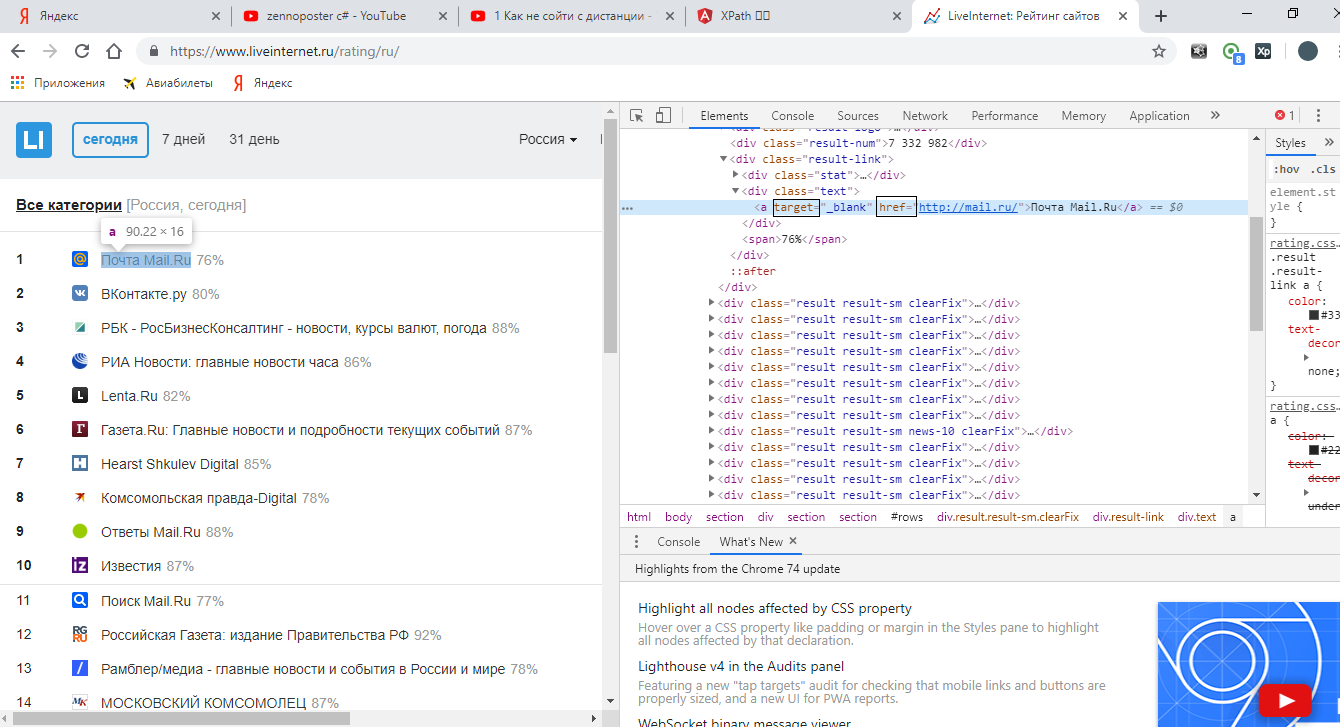
Смотрим на атрибуты и пробуем искать:
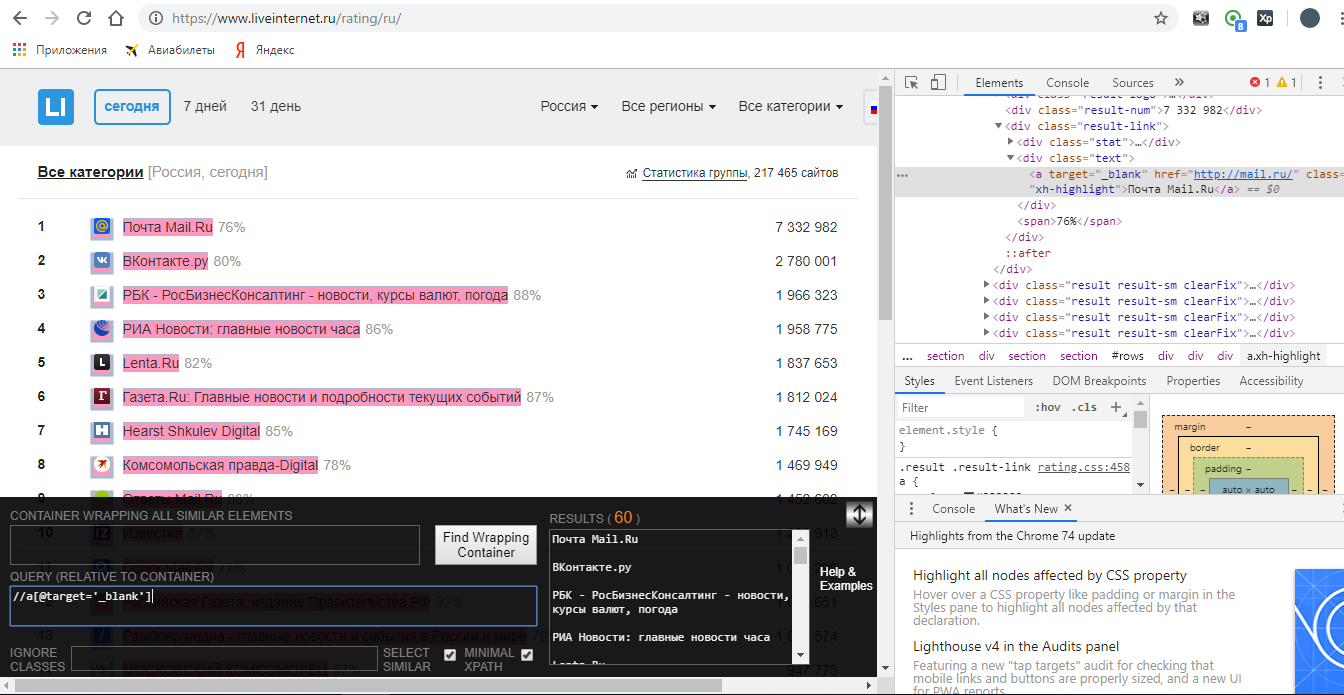
Давайте теперь рассмотрим другие варианты нахождения элемента. Единственное, поясню ещё момент. Вы должны четко понимать, что хотите найти. Давайте зайдем на ozon.ru и опять попробуем найти ссылку:
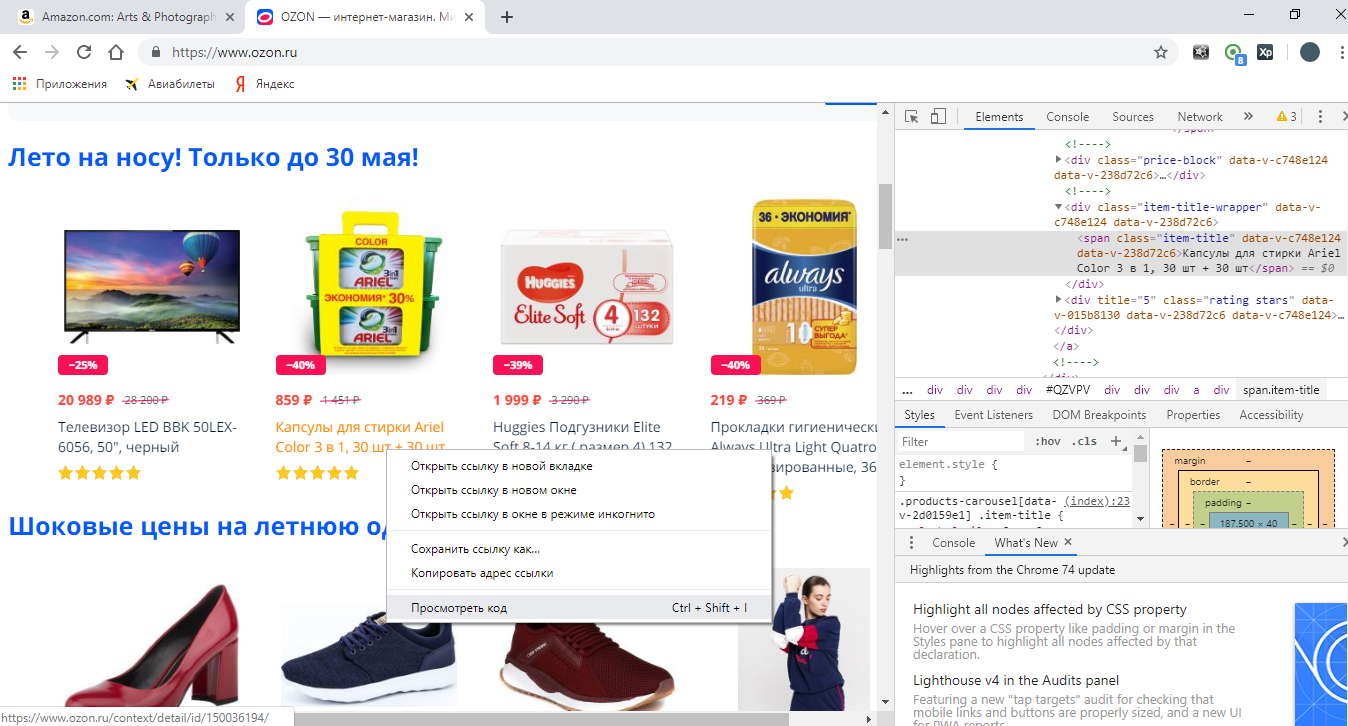
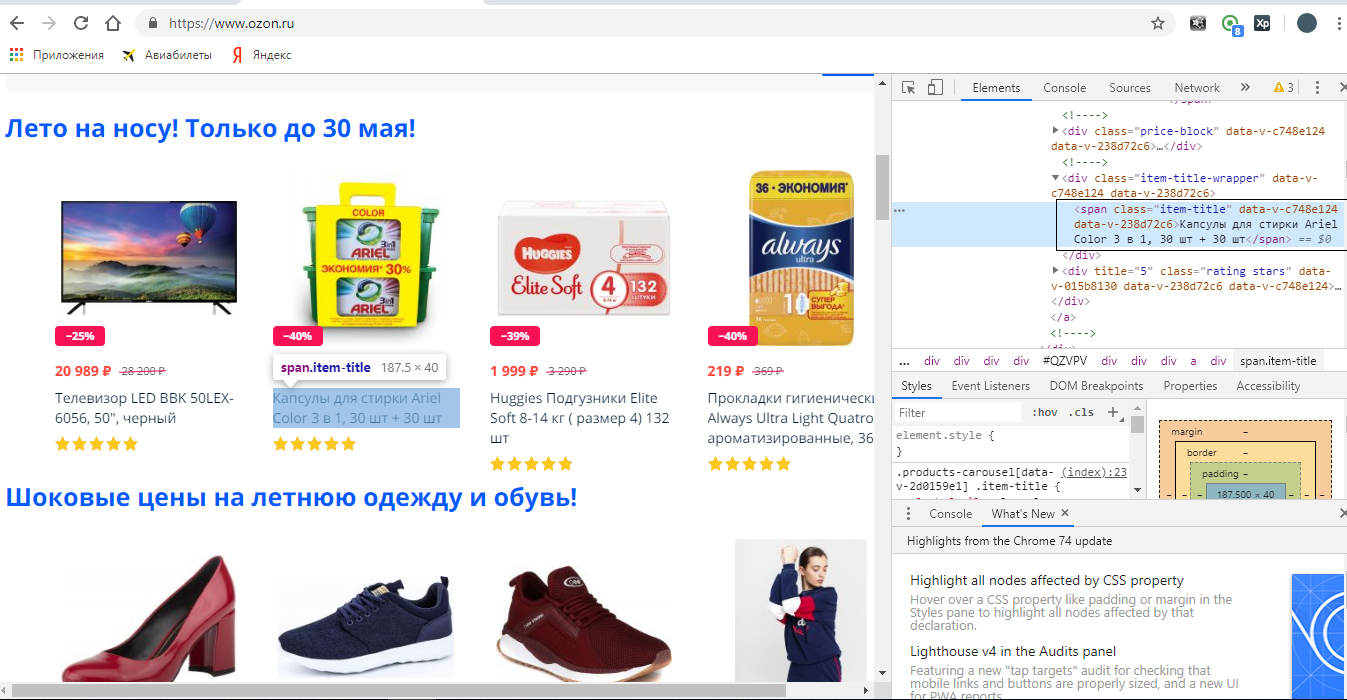
Смотрите, тут у нас тег span, а не <a>. Если нам нужны ссылки на товары, нам нужна именно ссылка, а не тег span. Как её найти в данном случае? Просто перемещаемся по коду выше (или ниже) и смотрим, что у нас выделяется
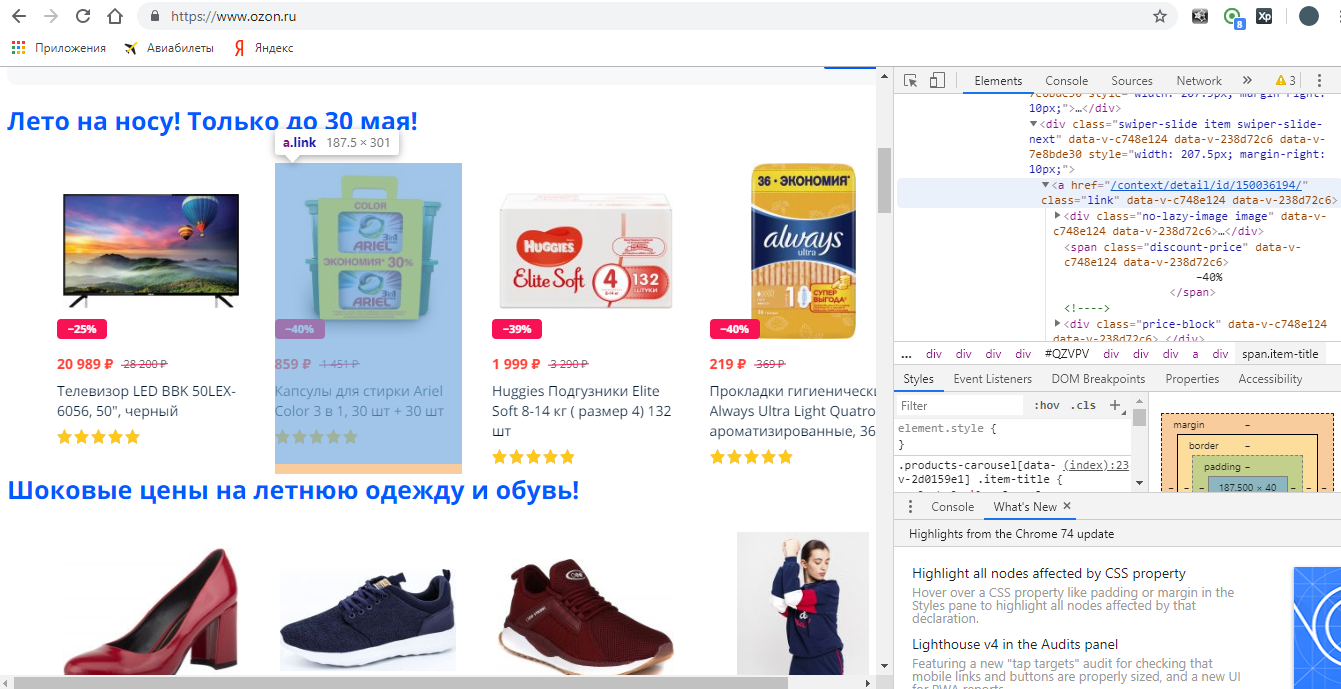
Видите, я промотал чуть выше и нашел нашу ссылку.
С этим разобрались. Покажу ещё пару примеров, которые часто используются (например, по каким-то причинам предыдущий способ не помог). Давайте сначала на примере ютуб:
//a[contains(@id, 'video-title')] – найди тег <a>, у которого в атрибуте id содержится video-title (P.S. Тоже самое, как в предыдущем методе, только там было равно, а здесь содержится)
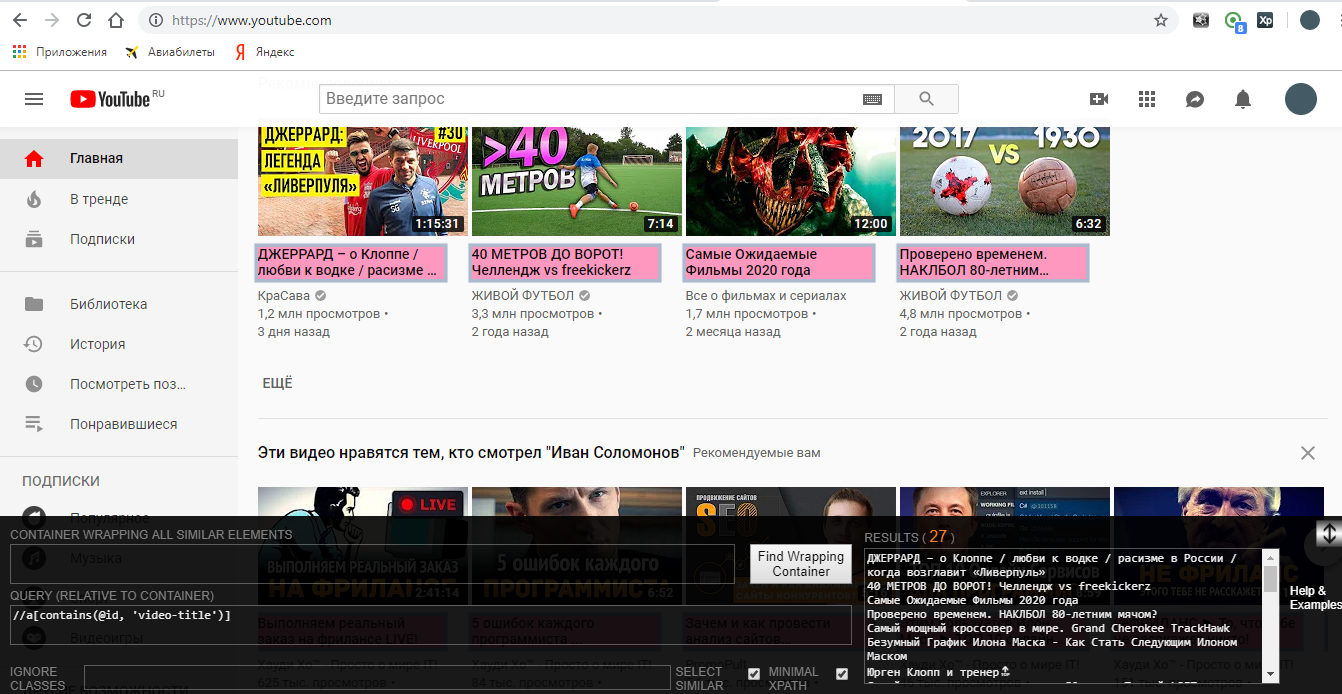
//a[contains(text(), 'ДЖЕРРАРД')] – найди тег a, у которого в тексте есть слово ДЖЕРРАРД
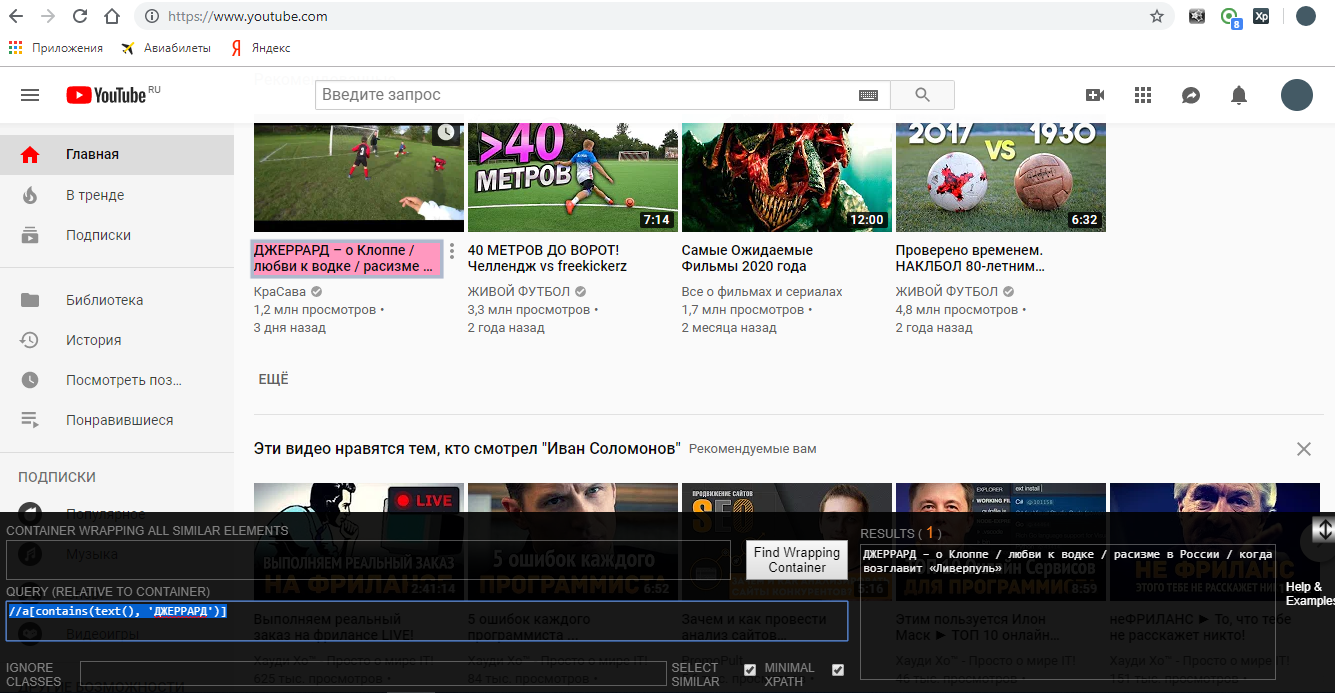
//h3[contains(@class, 'style')]/a[contains(@id, 'video')] – найди сначала тег h3, у которого class содержит style , а затем найди его «ребенка» тег a, у которого id содер жит video. P.S. Под ребенком я подразумеваю, что тег a находится внутри h3.
Вариант для ленивых (предупреждение: пути, сформированные таким образом вряд ли долго проживут)
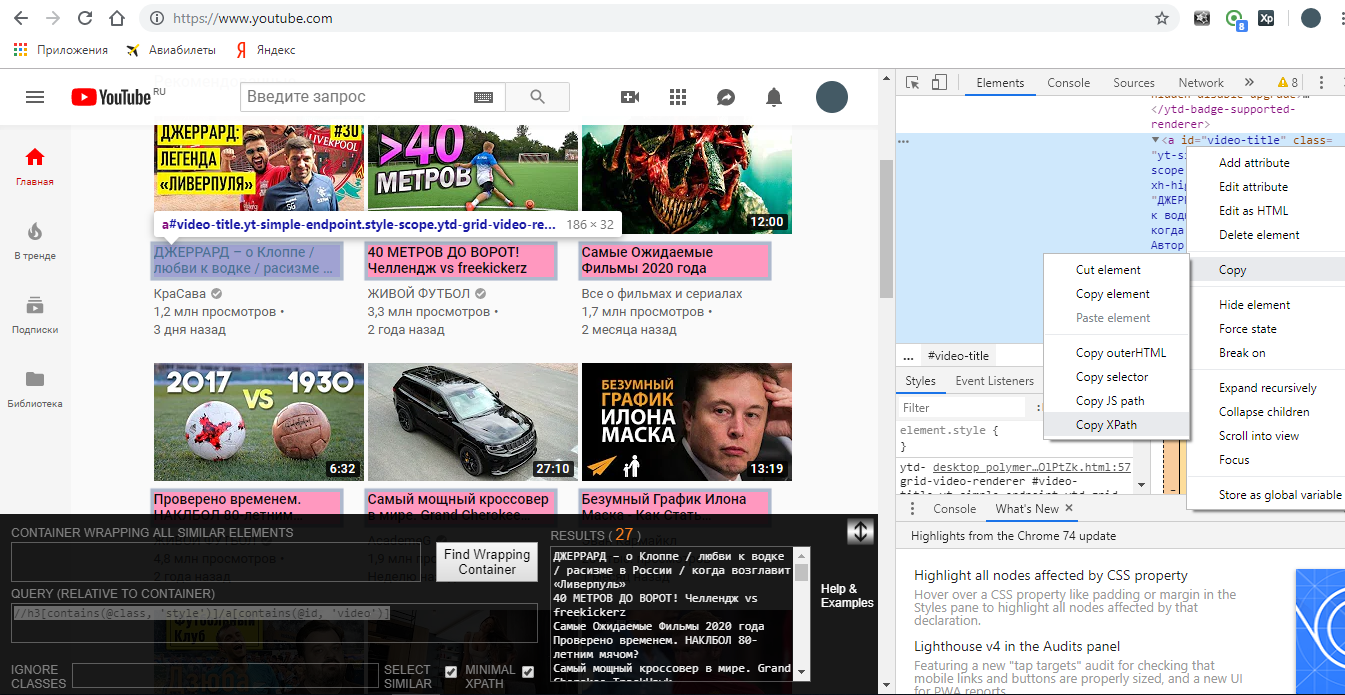
Хотя тут он выдал вполне себе хороший путь:
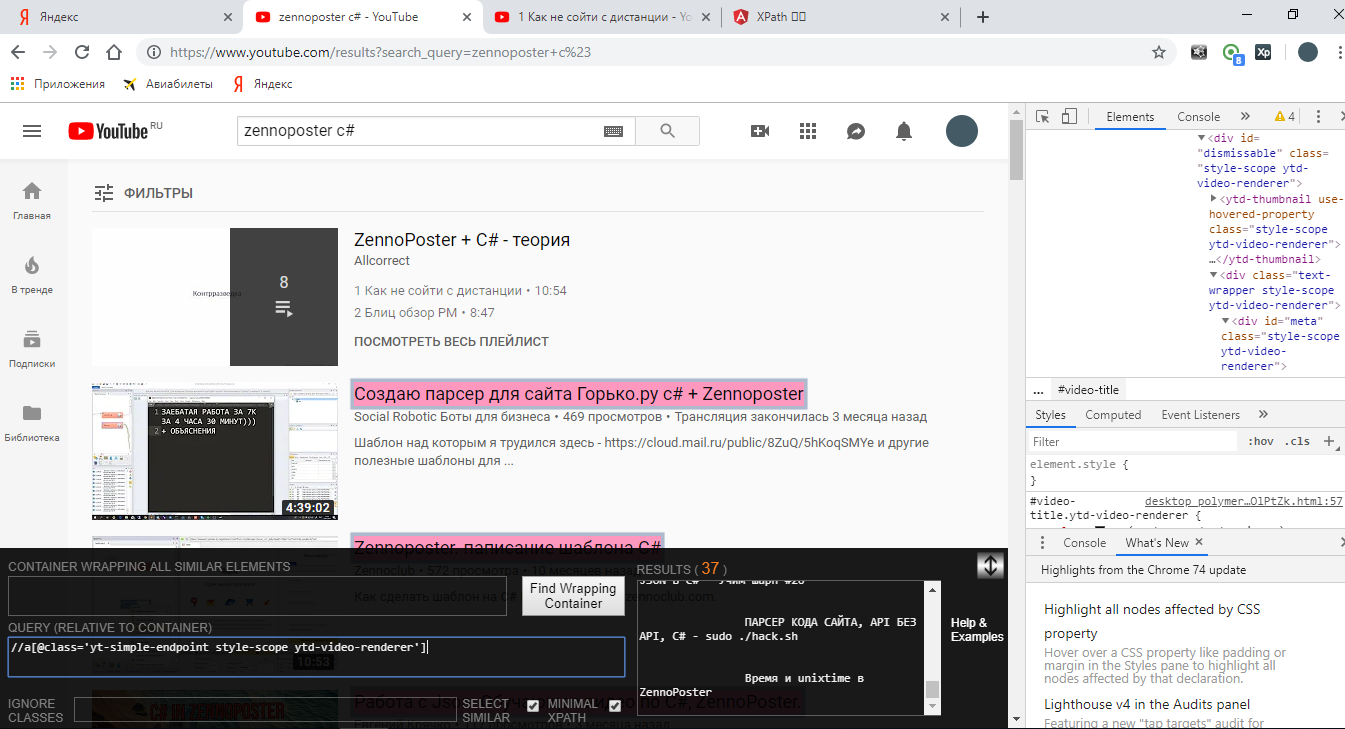
//*[@id="video-title"] – означает найди любой тег, у которого id равен video-title. Только project maker будет ругаться на двойные кавычки, вместо них надо вставить одинарные. Вот так: //*[@id='video-title']
И забыл ещё вот что. Смотрите, тут у нас 27 результатов:
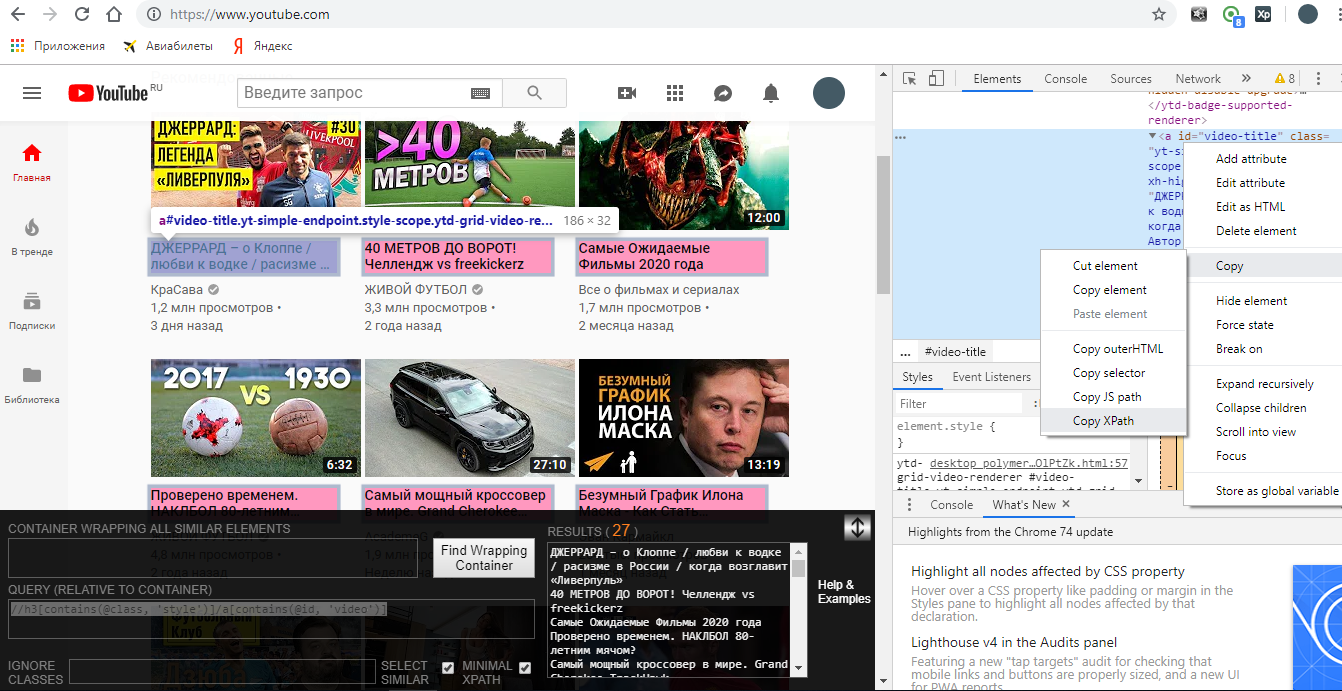
Мы можем выбрать любой из них по номеру, но делать это будем в project maker.
Итак, мы научились находить нужные нам элементы. Давайте теперь их сложим в таблицу. Полностью рабочий код для youtube:
P.S. Не забывайте закрывать xls таблицу на компьютере перед выполнением кода, иначе вылезет ошибка
P.P.S. В процессе написания шаблона столкнулся с такой фигней. Данные не парсились, и я не мог понять почему. В project maker автоматически генерируется профиль:
Так вот, у меня генерировался английский профиль и при заходе на ютуб открывалась англоязычная версия сайта. Оказывается, в англоязычной версии нужен уже совершенно другой Xpath путь. Так что перед запуском убедитесь, что у вас сгенерирован русский профиль и открывается русская версия сайта ютуб.
Пробуем писать парсер
Давайте напишем парсер, который будет собирать названия наушников и цену со всех страниц этой категории - https://doctorhead.ru/catalog/naushniki_moscow/
У нас есть 88 страниц, которые надо спарсить. Как мы получим ссылки? Часто это проще сделать вручную, чем писать под это дело код. Смотрите, как формируются у нас страницы:
Как мы их получим? Идем в excel и делаем следующим образом:
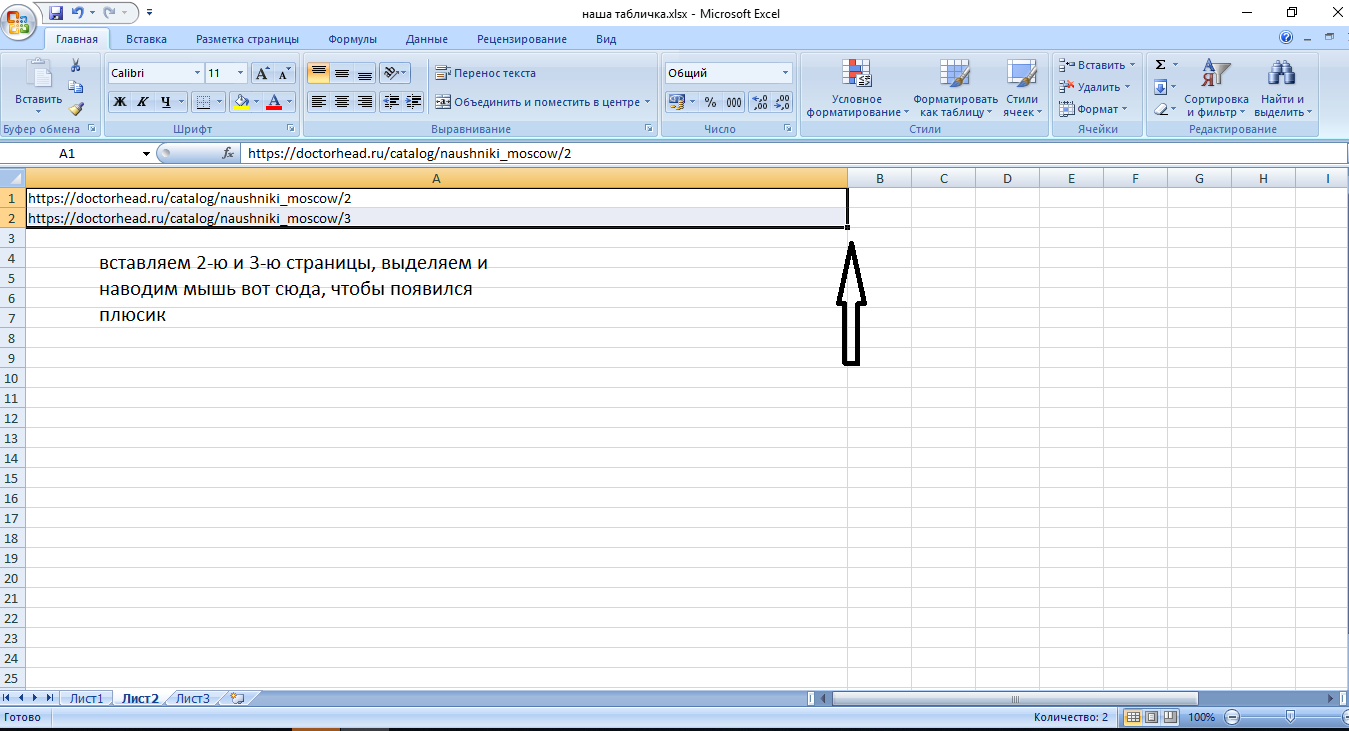
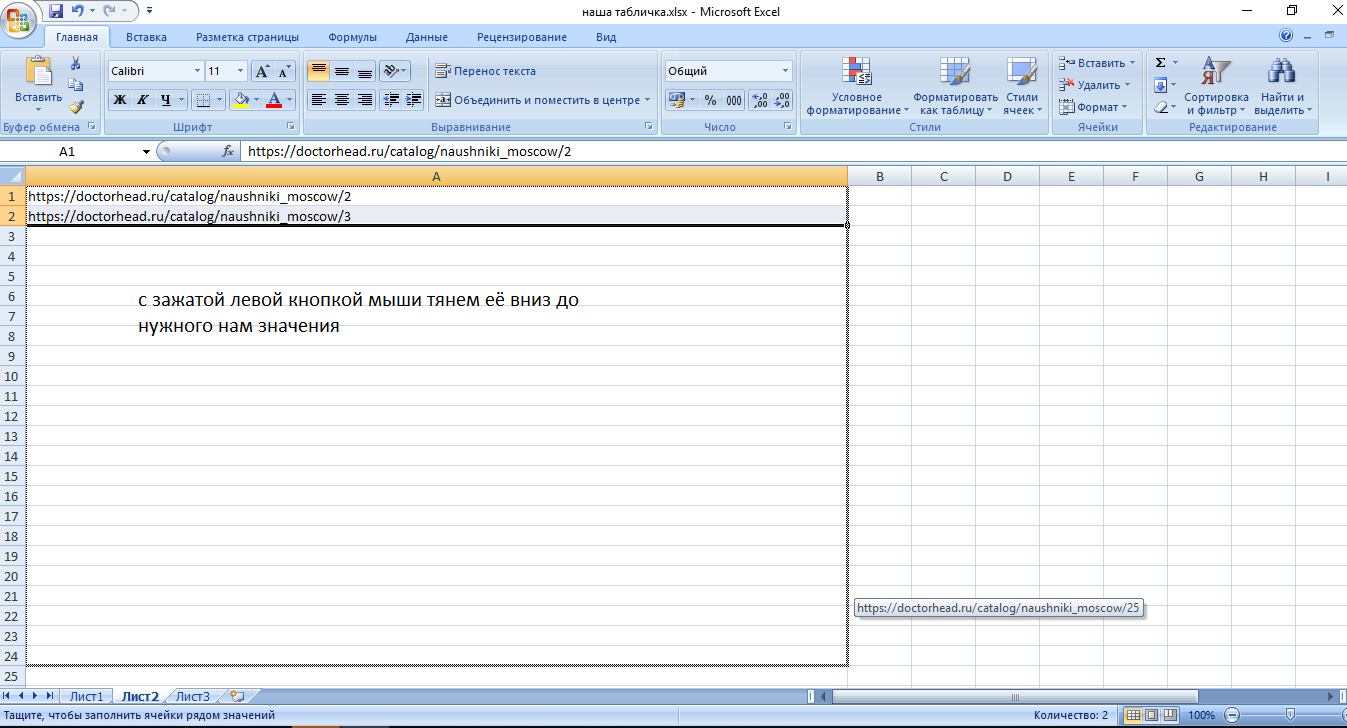
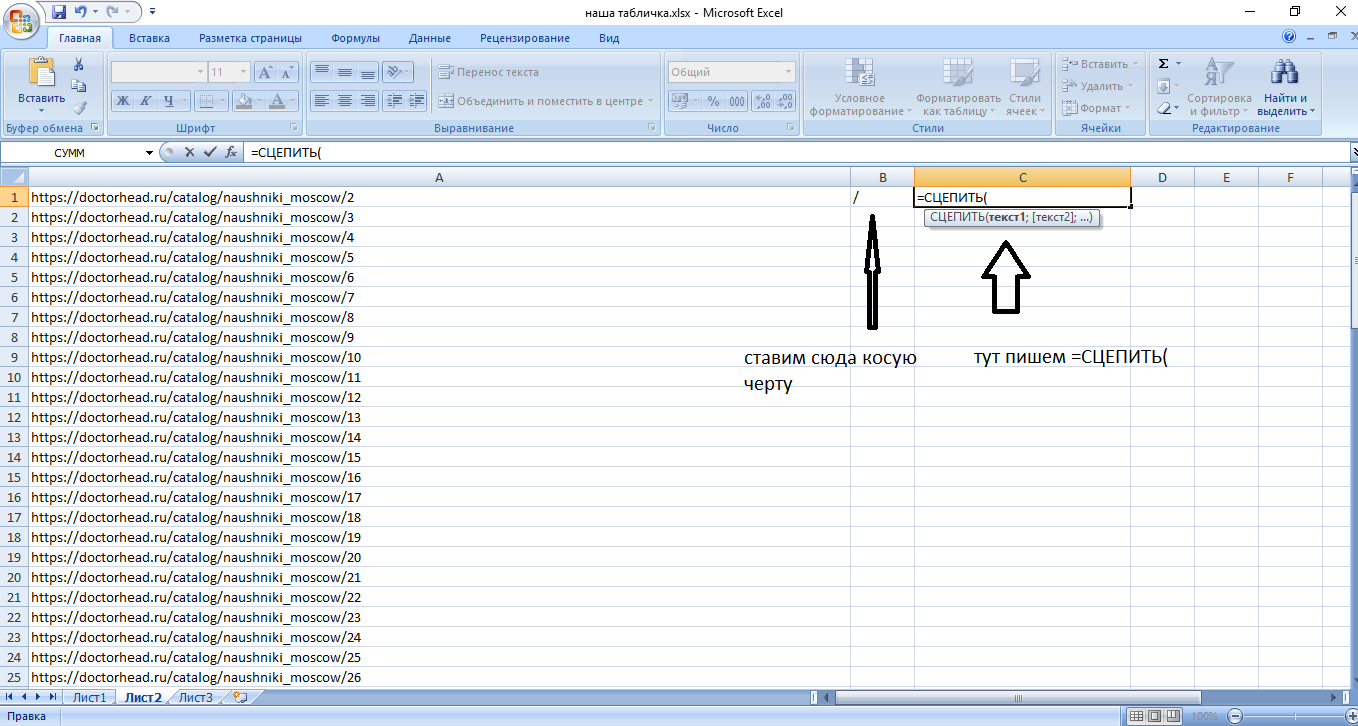
Если вы обратили внимание, то тут я убрал косую черту на конце:
Это нужно для размножения в excel. Обычно у сайтов настроен редирект и проблем не возникает, однако здесь такое не катит. Т.е. тут нам нужны ссылки именно такого вида https://doctorhead.ru/catalog/naushniki_moscow/88/. Как мы их получим:
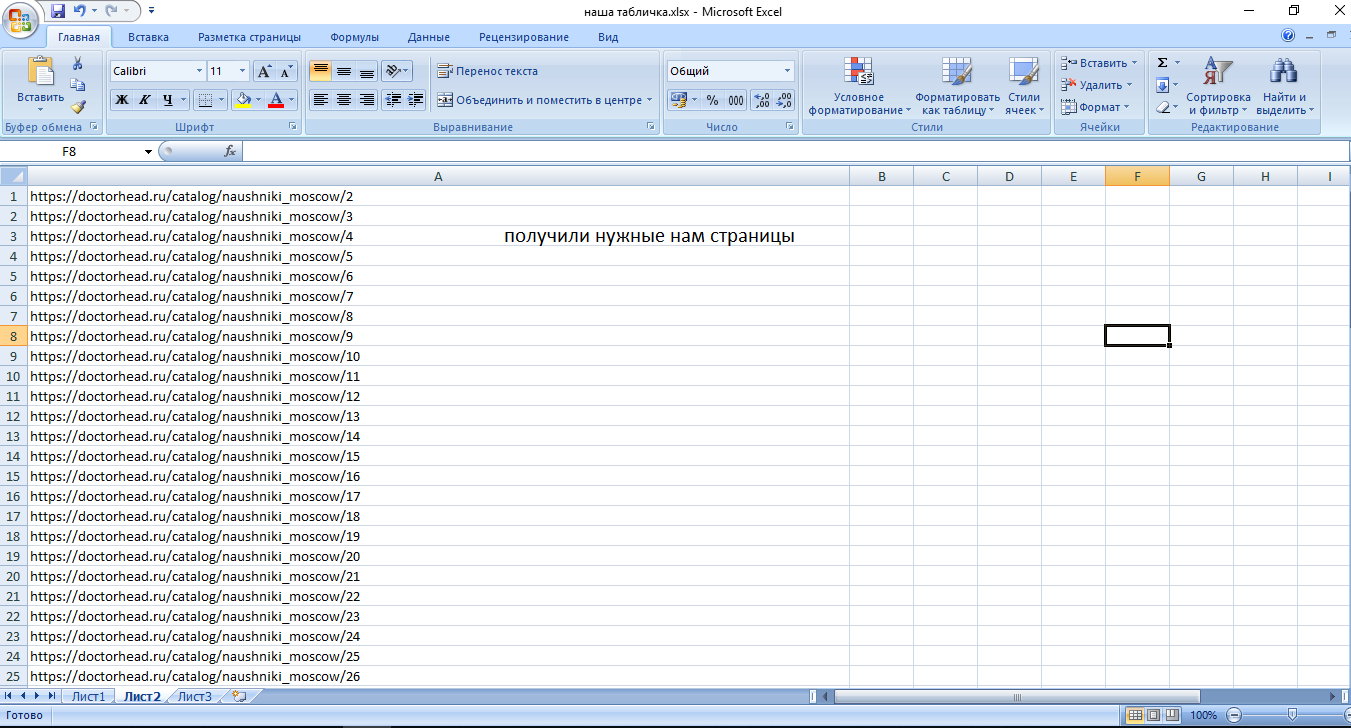
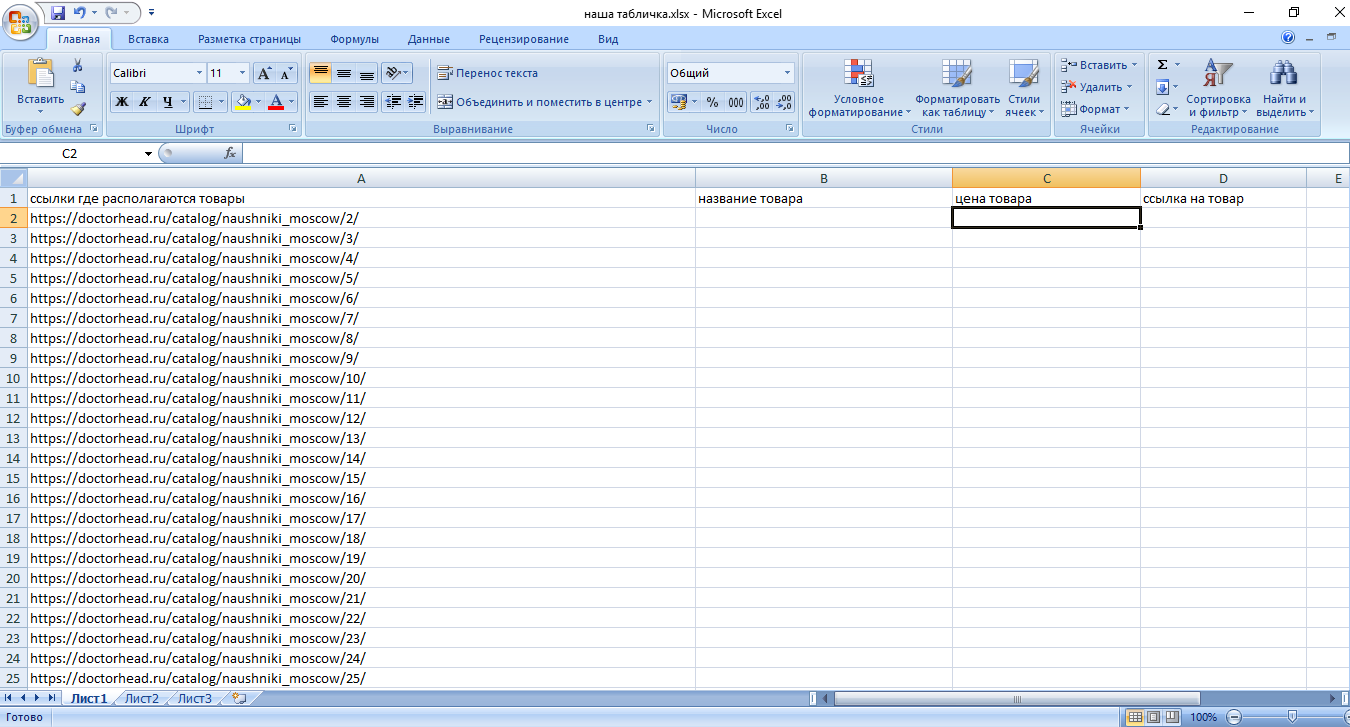
Теперь создадим новый xls файл, дадим названия для столбцов и вставим полученные ссылки в первый столбец:
Этап 2
Итак, мы с вами получили ссылки, с которых будем парсить. Давайте теперь перейдем в Project Maker и напишем код, который будет переходить по этим ссылкам и находить те элементы, что мы хотим спарсить.
Добавим кубик C# код:
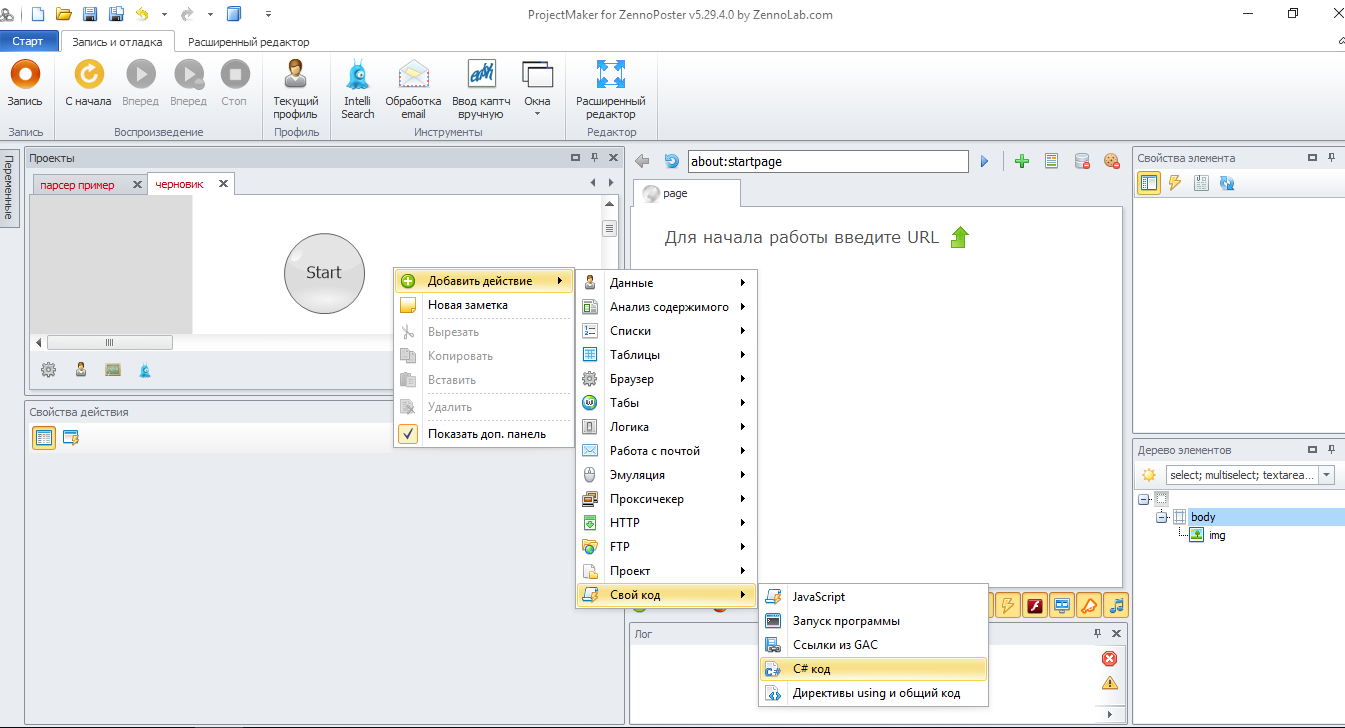
Добавим ссылки из gac и директивы Using:
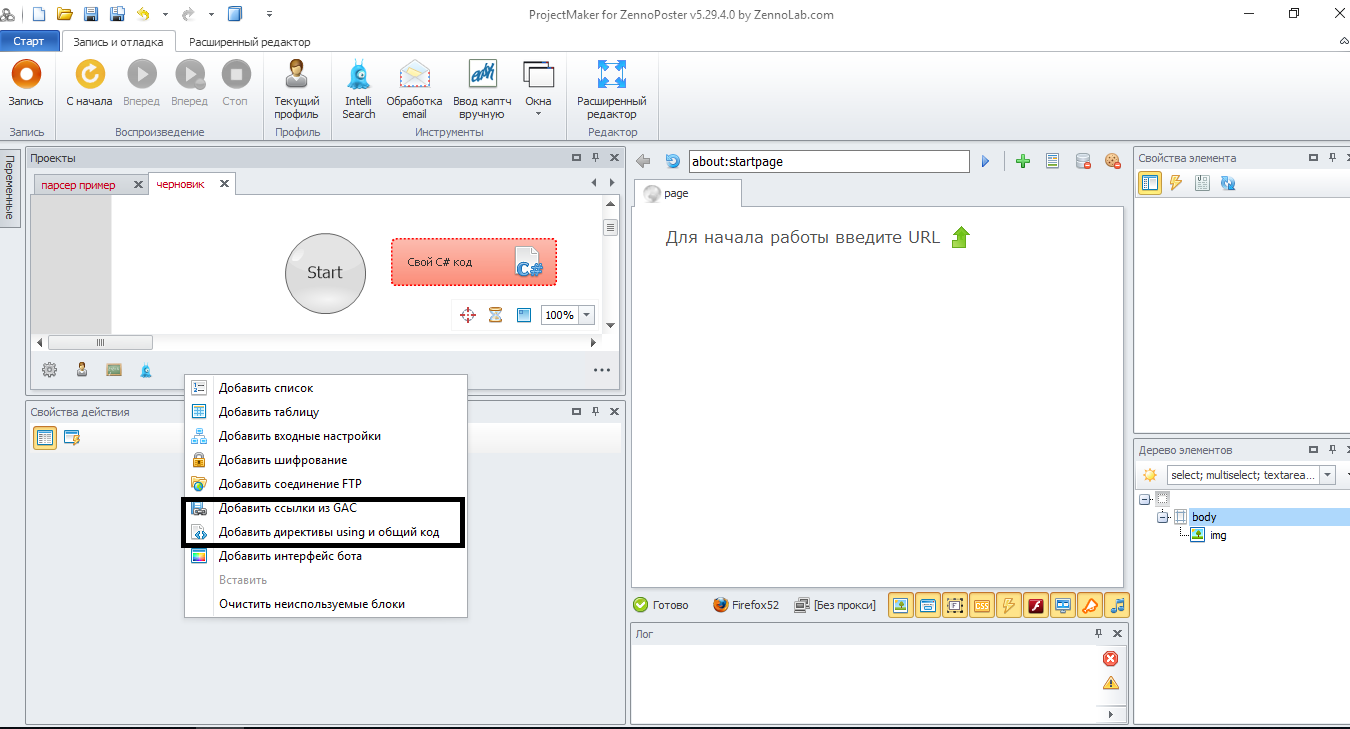
В ссылки из Gac добавим библиотеку epplus.dll
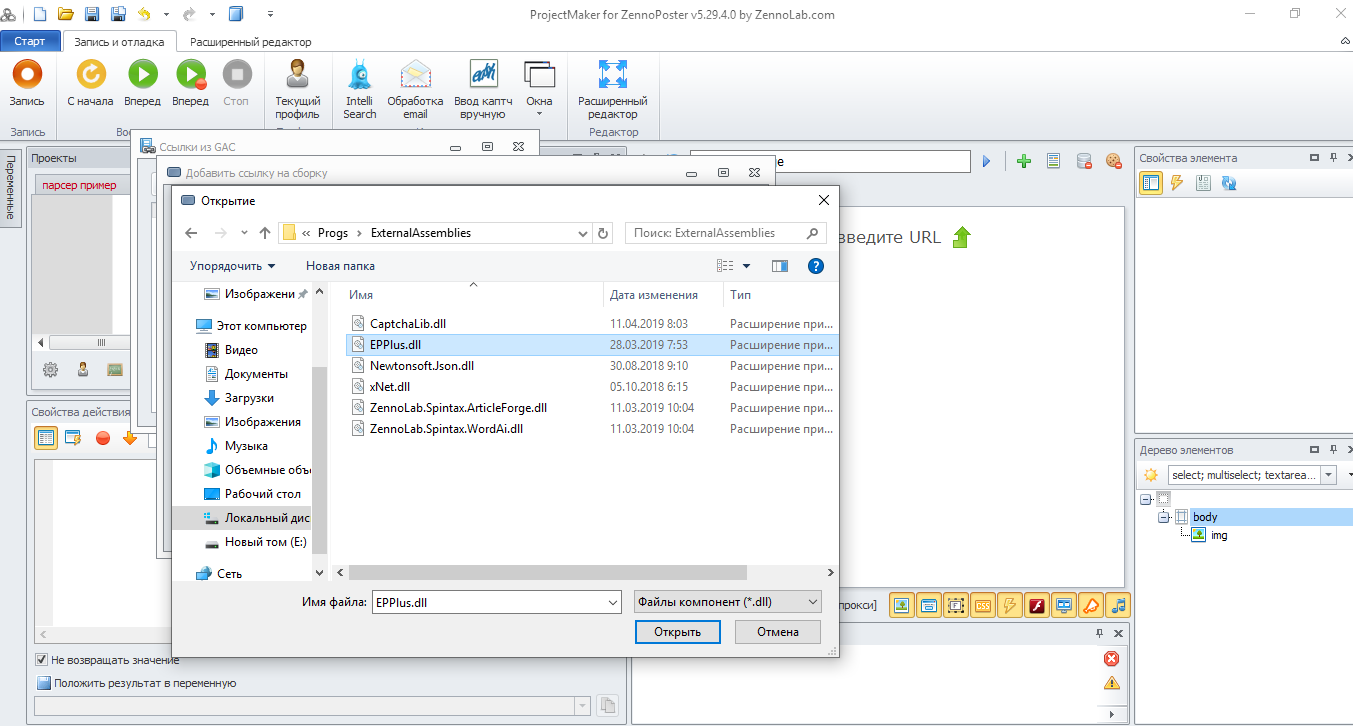
И подключим её, прописав в директивы using:
Теперь в кубике C# подключим таблицу:
Так, теперь нам надо написать код, который будет переходить по ссылкам и находить нужные нам элементы. Логика такая:
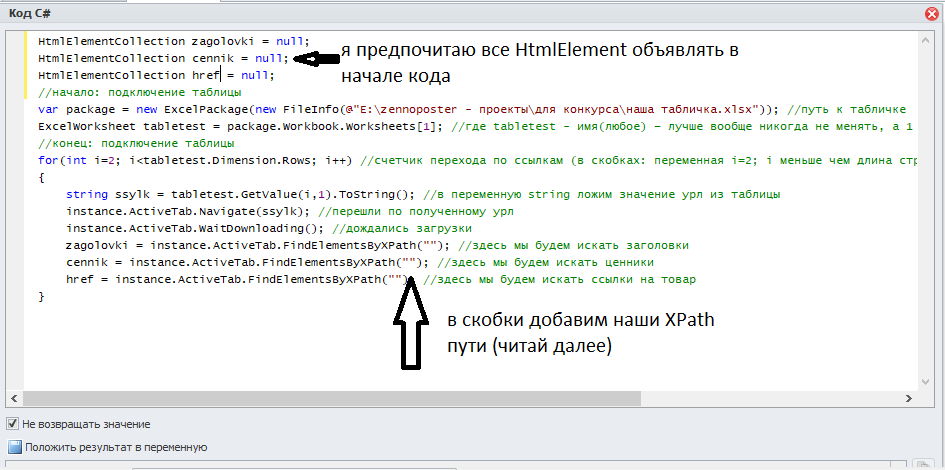
Теперь нам надо составить Xpath пути, которые мы пропишем в скобках.
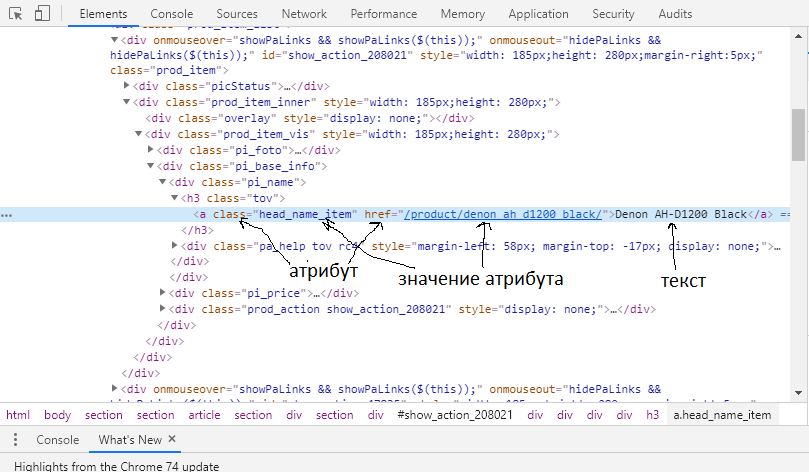
Давайте сначала найдем названия товаров (в коде у нас это zagolovki). Переходим на сайт в гугл хроме, жмем по нужному нам элементу правой кнопкой мыши и выбираем просмотреть код:
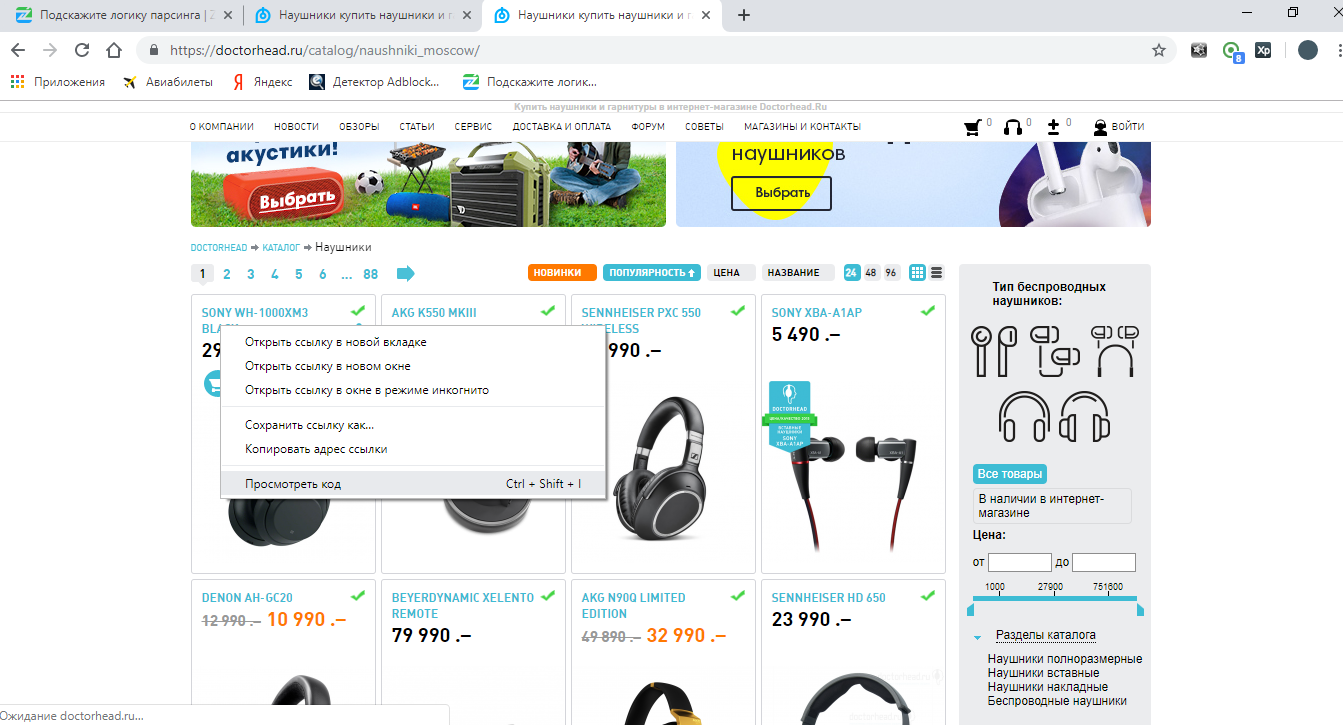
Вот мы сразу её нашли:
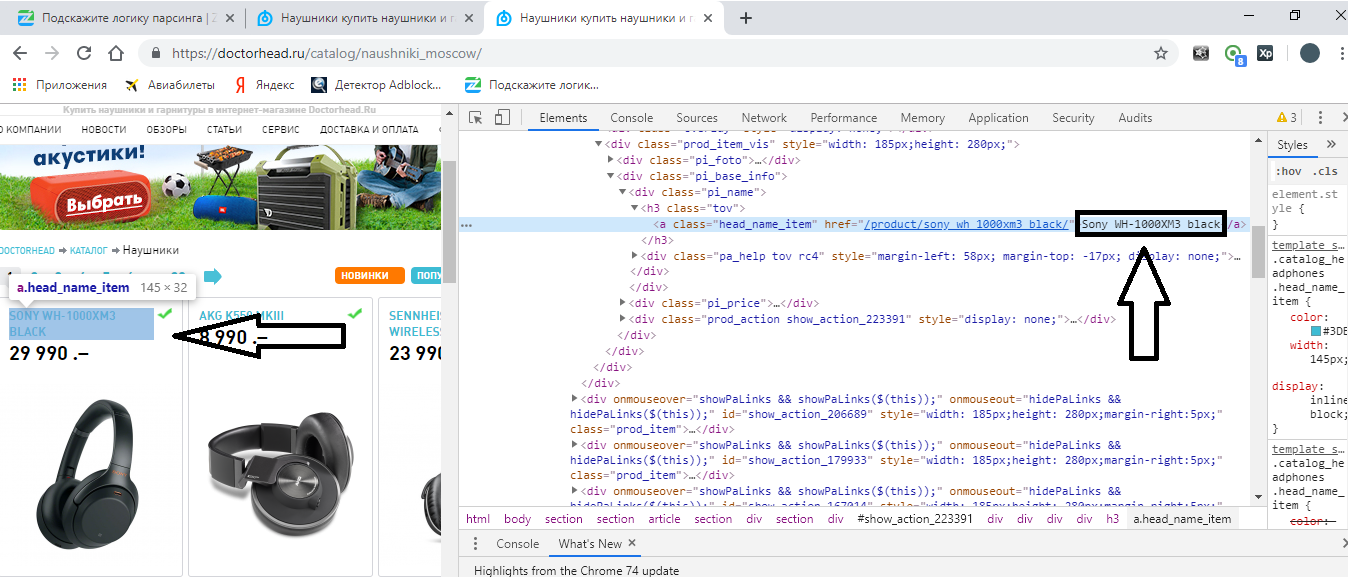
Мы видим, что нам нужна ссылка (тег <a>) у которой есть атрибут class со значением head_name_item. Пробуем составить Xpath путь (используется плагин для гугл хром Xpath Helper Wizard):
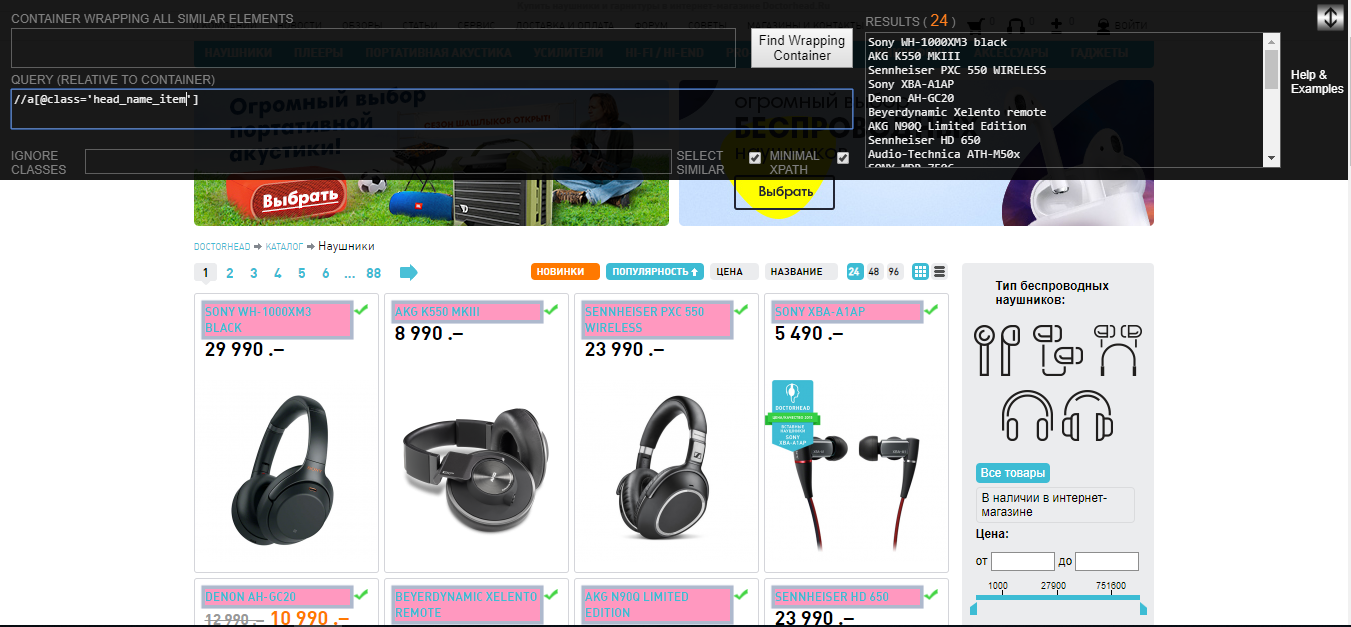
Видим, что нам сходу удалось выделить те элементы, что нужно. Проверим этот XPath путь на других страницах:
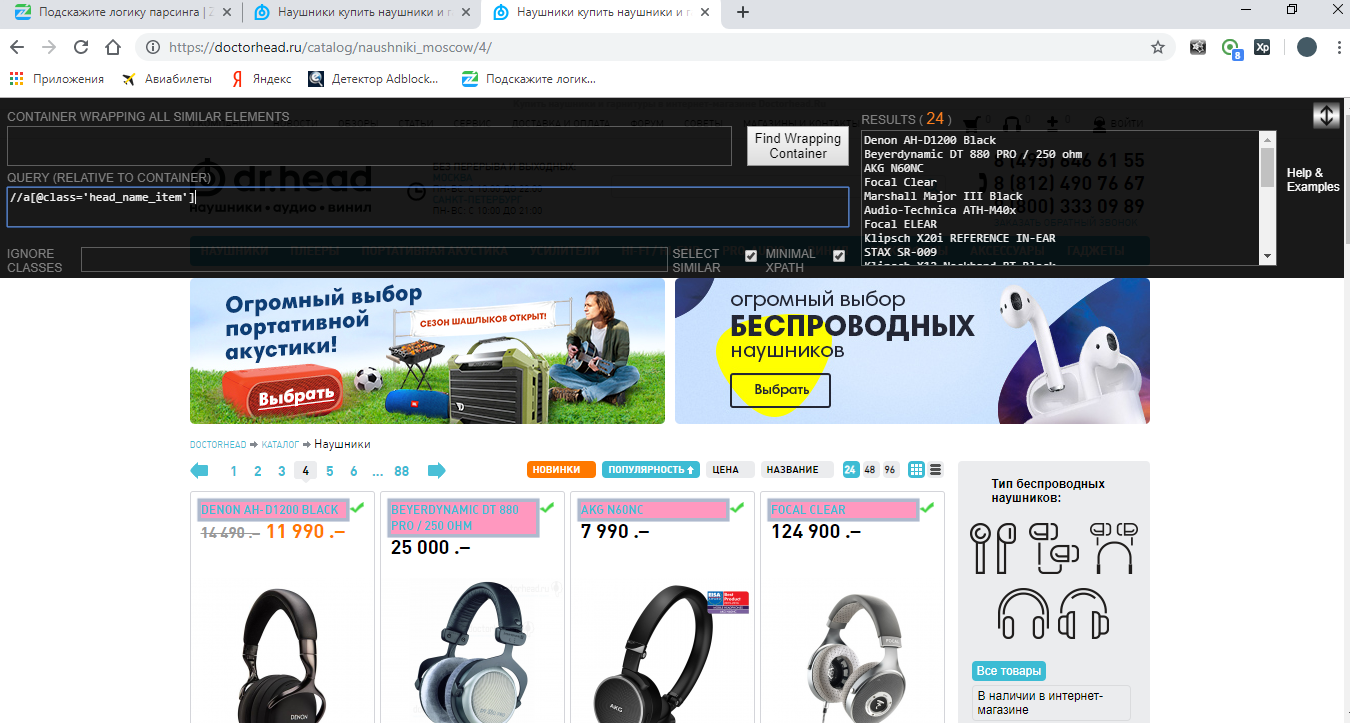
Видим, что и здесь всё хорошо. Это мы составили Xpath путь для поиска названий товаров. Давайте пропишем его в коде:
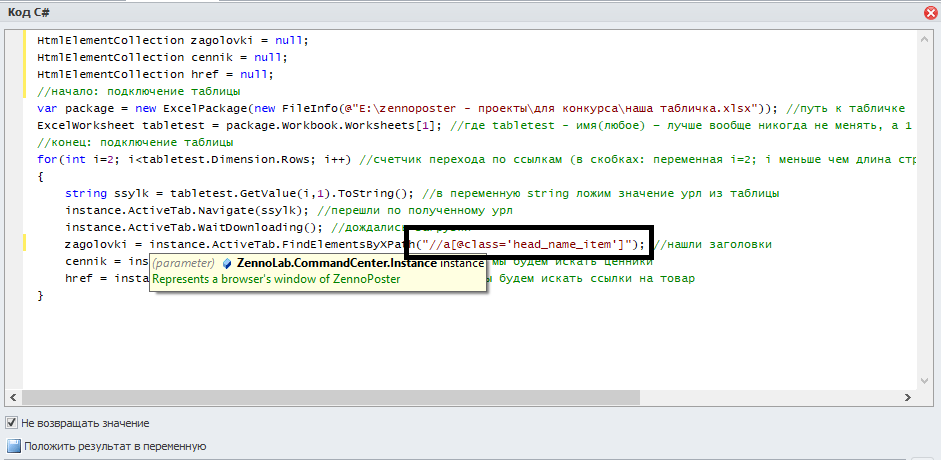
И давайте сразу запоминать, что нам нужно будет получить из найденного элемента: значение какого-то атрибута или текст? В данном случае это текст
Идем дальше. Давайте теперь составим Xpath путь для ценника. Тоже самое: наводимся на ценник, жмем правую кнопку мыши, просмотреть код и находим его в коде:
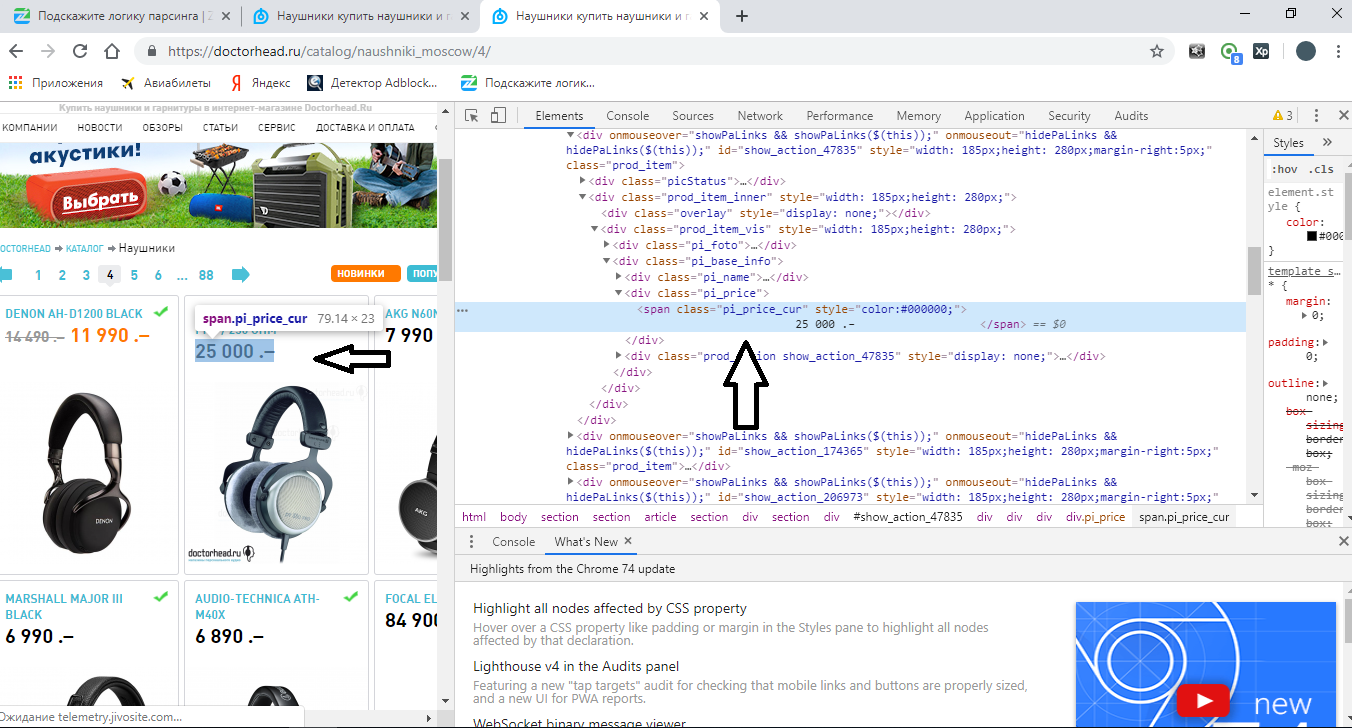
Видим, что тут тег span, у которого есть class="pi_price_cur". Пробуем составить Xpath путь:
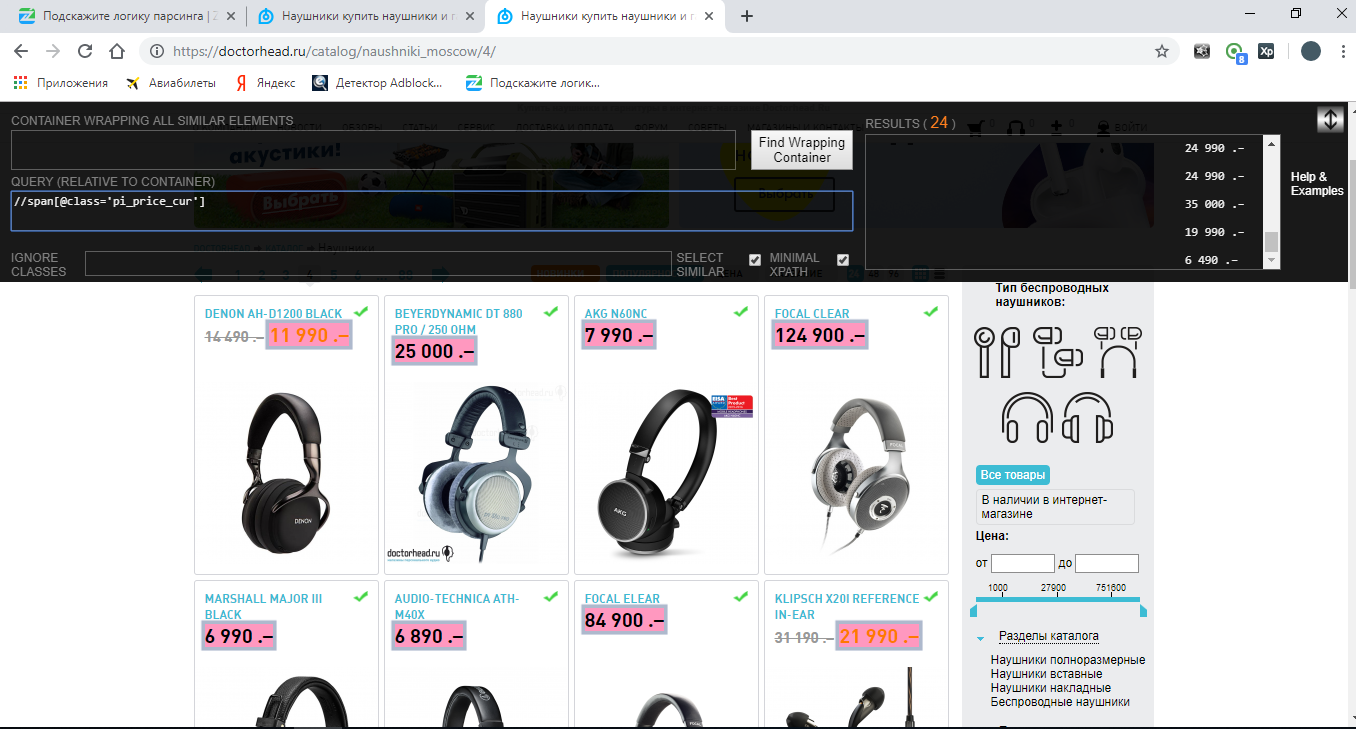
Видим, что всё норм. Добавляем его в код:
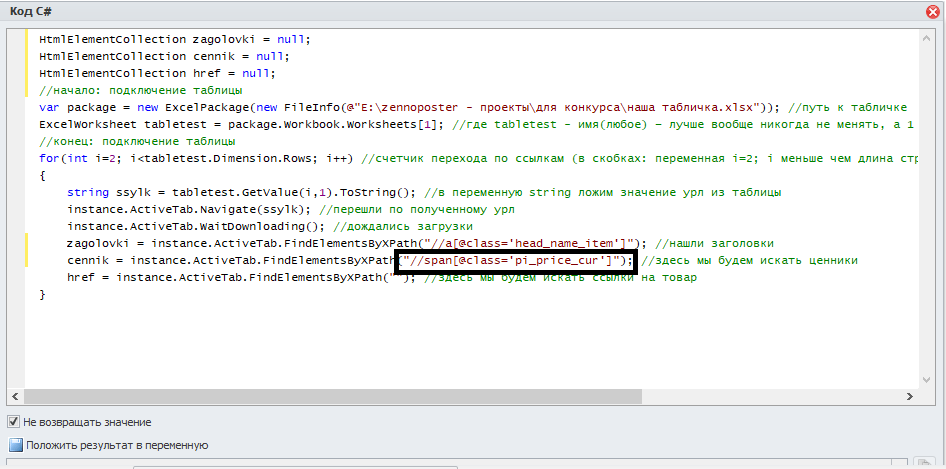
Также отметили для себя, что нам нужен будет текст, а не значение какого-то атрибута.
Теперь найдем нашу ссылку. Наводимся, жмем правую кнопку мыши, просмотреть код и находим её в коде:
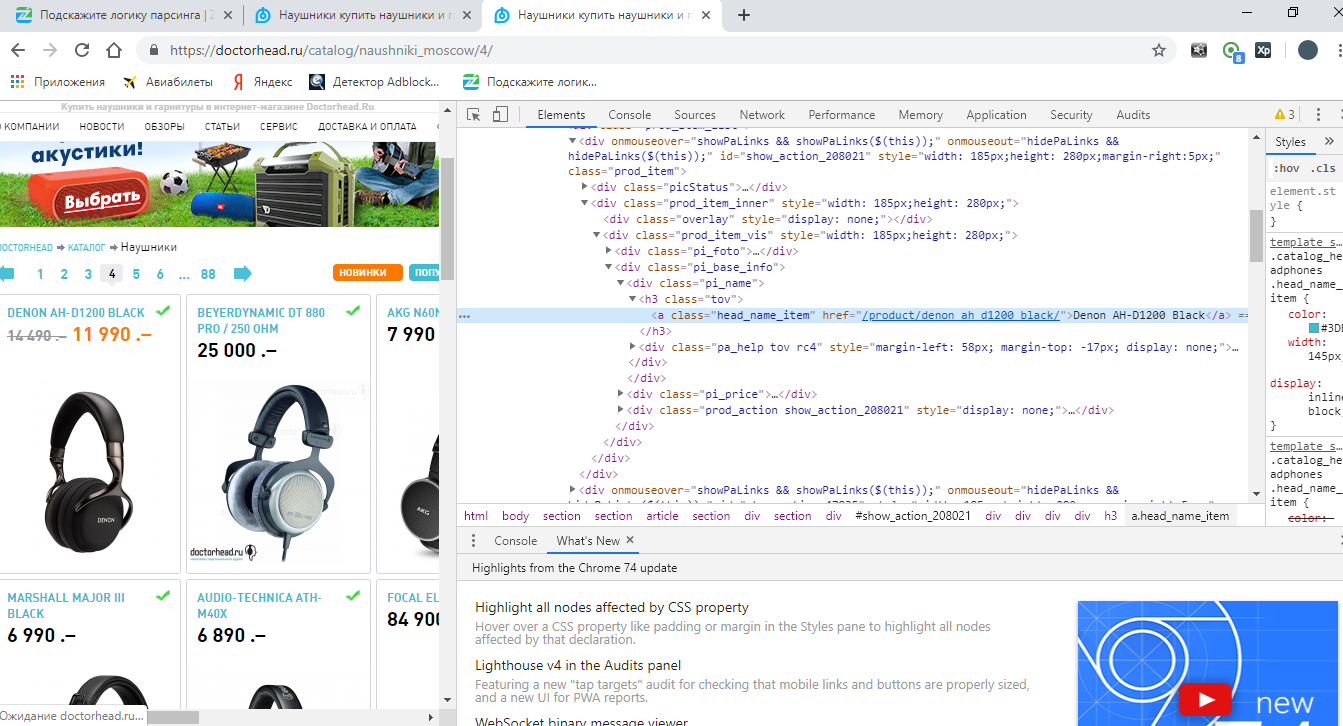
Код не кажется вам знакомым? Мы его уже находили, когда искали заголовок. Только тогда нам нужен был ТЕКСТ, а теперь нам нужно ЗНАЧЕНИЕ АТРИБУТА HREF.
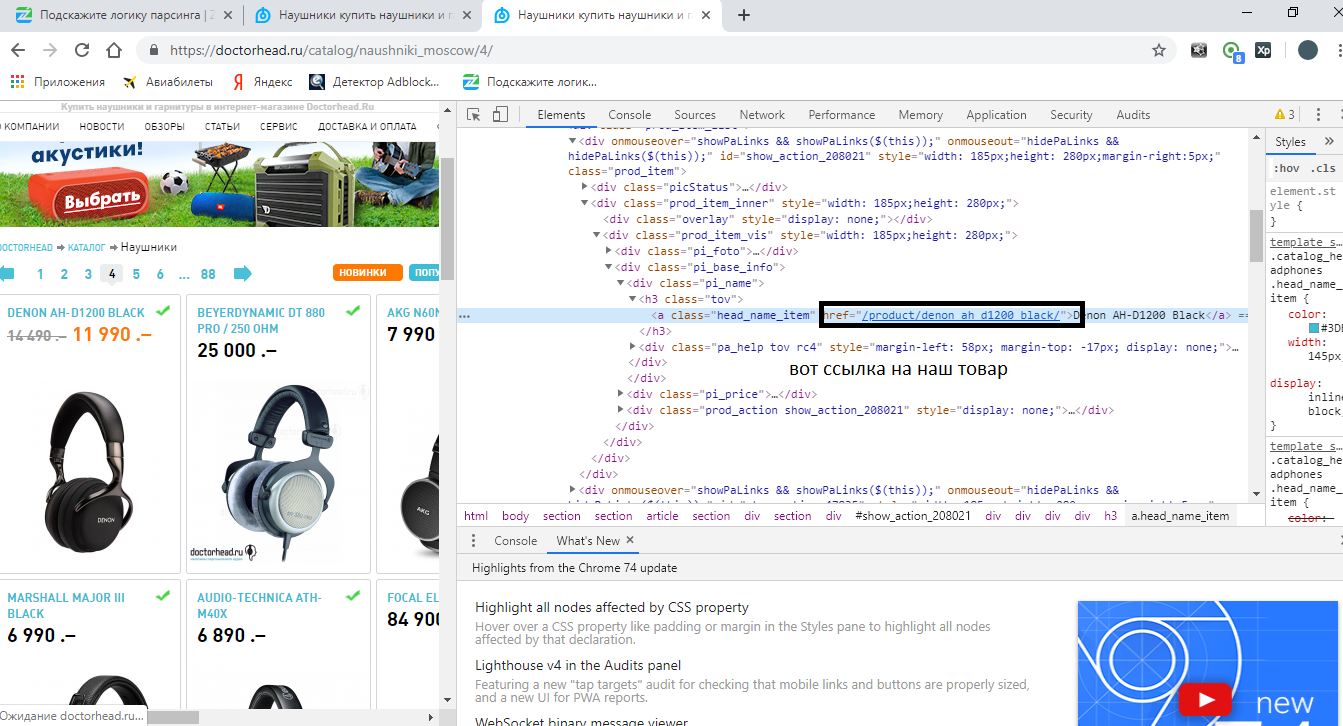
Раз мы его уже находили, удаляем из кода последнюю строчку, т.к. она лишняя.
В итоге у нас получился вот такой код:
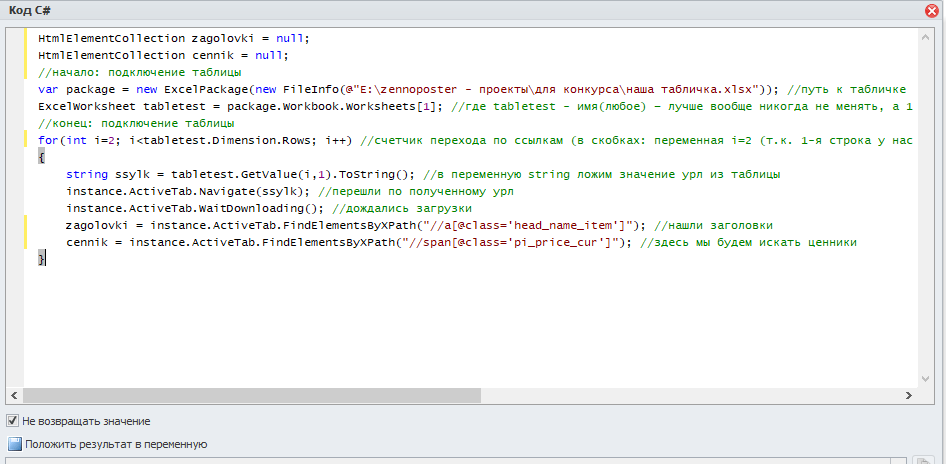
Давайте протестируем, нет ли каких-либо ошибок. Только вместо tabletest.Dimension.Rows поставим, например, 10 (иначе нам придется ждать, пока он обойдет все 88 страниц). Что он должен делать: брать ссылку из таблицы, переходить по ней, находить нужный элемент.
Вроде бы всё норм, ошибок не видно:
Этап 3
Так, идем дальше. Теперь нам надо перебрать в цикле собранные нами данные и сохранить в таблицу.
Для этого прям внутри этого цикла создадим ещё один цикл для перебора наших коллекций. Какая его логика:
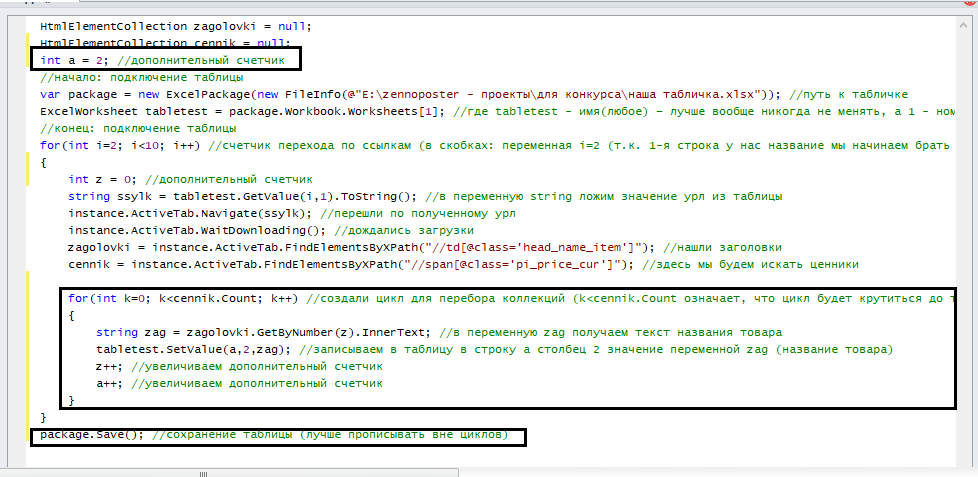
Давайте разберем каждую строчку:
Тут вам надо понять логику кода.
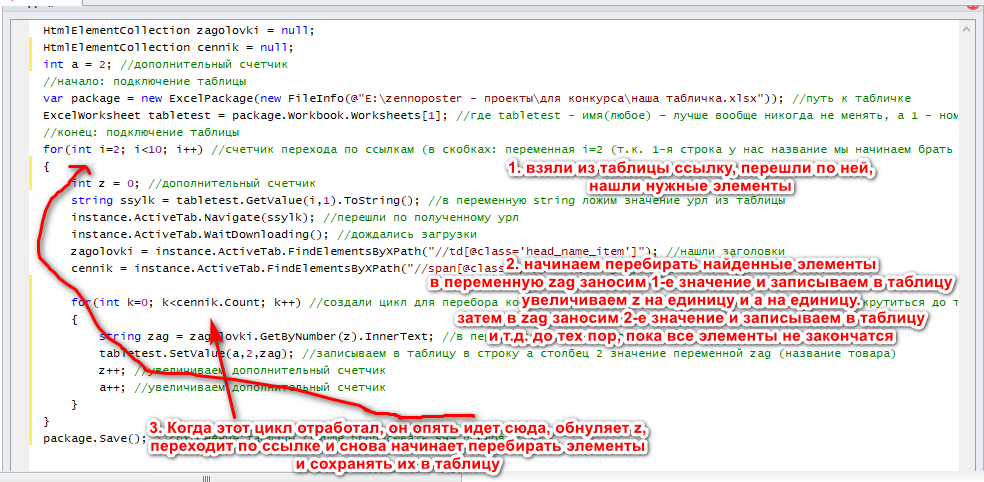
Так, это мы с вами сложили названия товаров. Нам также надо сложить с вами ценники и ссылки на сами товары. Давайте это сделаем.
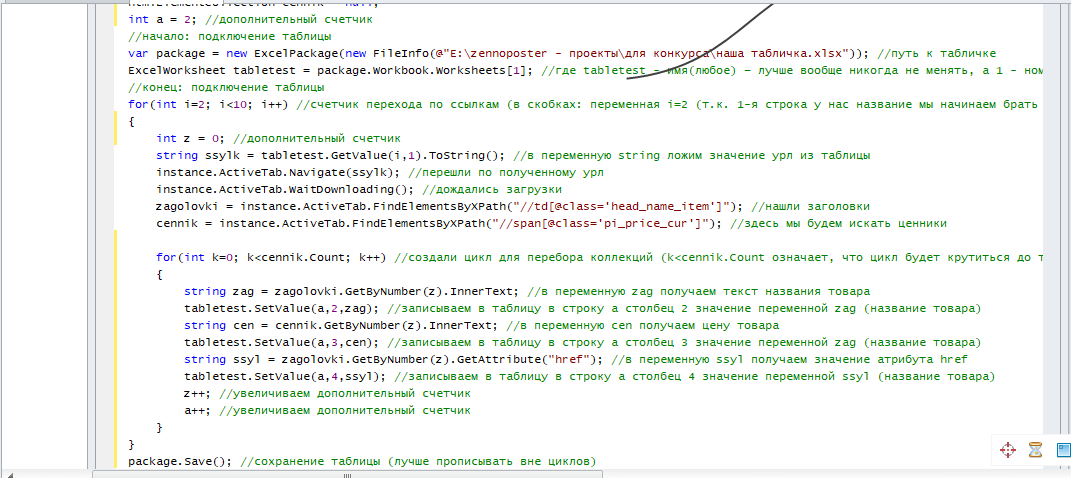
Обратите внимание на получение ссылки. Помните, я говорил, что нам надо запомнить, что мы планируем изъять текст или значение какого атрибута? Так вот, тут нам нужно как раз значение атрибута href найденного нами элемента, а не текст ссылки. Поэтому мы и написали .GetAttribute(“”);
По сути всё, мы закончили. Обязательно закройте на компьютере таблицу xls, иначе project maker выдаст ошибку при попытке сохранения данных.
Давайте пробовать запускать.
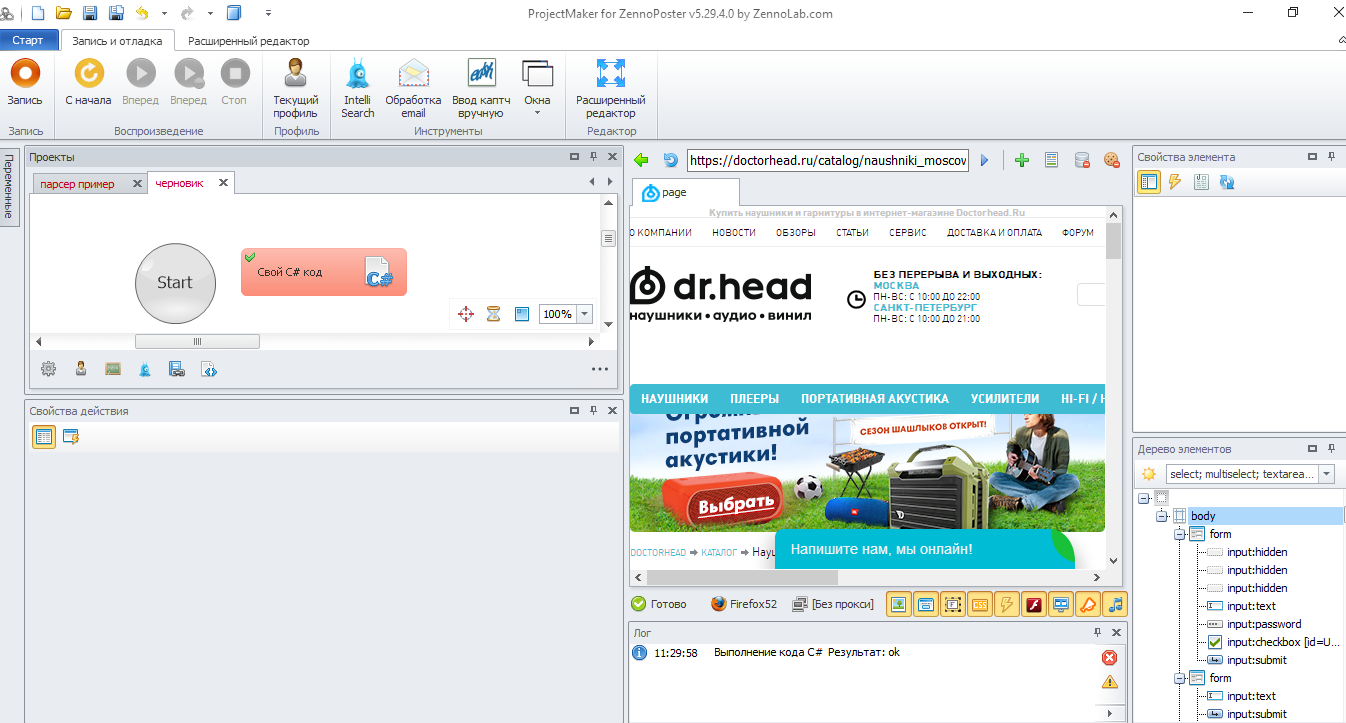
У меня не спарсилось название товара и ссылка на товар? Где проблема? Она в Xpath пути. Я там проверял кое-что и специально сделал неправильный XPath путь (а затем забыл изменить обратно), поэтому так. У вас всё должно было отработать норм. Сейчас покажу где (а то вдруг кто-то запутается)
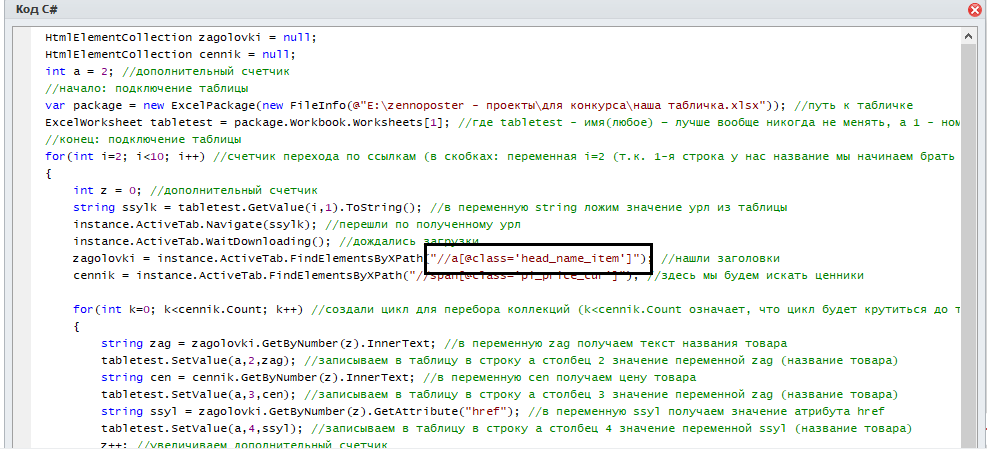
Так, пробуем запустить ещё раз:
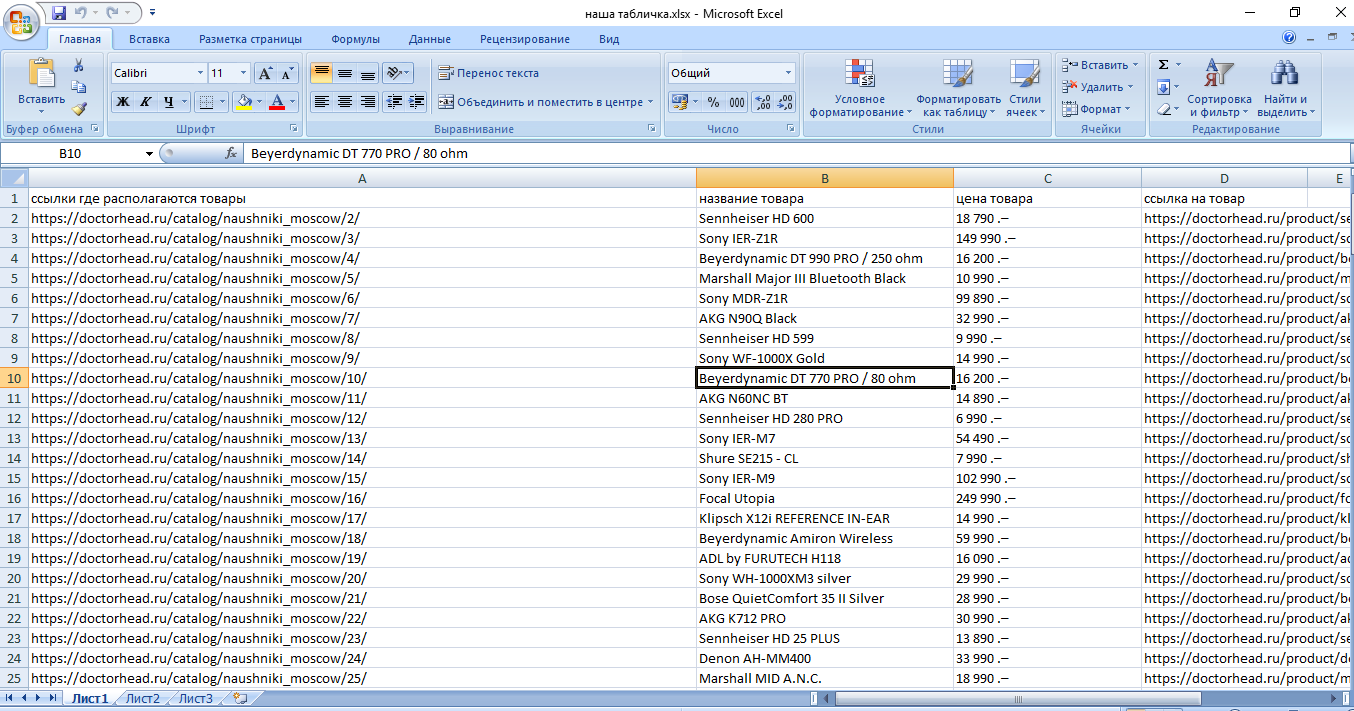
Вот теперь всё норм. Осталось нам на 7 строке вместо i<10 написать i<89; чтобы спарсились все страницы.
P.S. Конкретно в этом шаблоне не так как нужно (имею ввиду мне) отрабатывает команда tabletest.Dimension.Rows. Я уже подустал, нету сил разбираться, где я там накосячил, поэтому просто вручную задаем нужное количество страниц и не паримся.
В видео представлена переделка шаблона под себя на примере парсинга вот этой категории - https://zennolab.com/discussion/forums/voprosy-novichkov.16/. Видео записывалось в режиме Live на ноутбуке, поэтому звук не очень и подача довольно хаотична. Косяки вырезать не стал, ставил на паузу когда уж совсем упирался в стену.
Всем привет. Несколько оговорок перед началом:
- Я новичок и статья также предназначена для новичков. Если вы никогда не писали на C#, то можете начать пробовать с этой статьи
- Парсятся довольно простые ресурсы. На более сложных сайтах бывают свои нюансы, но принцип один и тот же.
- Для понимания статьи вам желательно знать самые основы C#. Как вариант можно посмотреть вот эти уроки на ютубе (не мои) - youtube.com/watch?v=DKJIG6LAK6E&list=PLVMmweigHAdrvQAny9LC1C1B8Sw4IcaXL
- Шаблоны написаны на последней версии Project Maker (5.29.4.0), так что не знаю, как они будут отрабатывать на более ранних версиях
- Не рассмотрен многопоток (что конечно плохо), ввиду того, что у меня версия Lite и у меня нет возможности его протестить
- Шаблоны на web (post-get наверняка лучше, но этими знаниями я также не обладаю)
- Код открытый и закомментированный. Можете пользоваться, экспериментировать и т.д.
Куда будем складывать данные – работа с библиотекой Epplus.dll
Полученный результат я предлагаю складывать в таблицу xls с использованием внешней библиотеки Epplus.dll. Преимущество её в том, что можно работать с несколькими листами. Перейдем к установке.
Установка библиотеки EPPlus.dll
Скачать библиотеку можно отсюда (можете качать с официального сайта, но там целая проблема найти кнопку download =) ).
Берем файл EPPlus.dll и кидаем по этому пути:
"C:\Program Files (x86)\ZennoLab\RU\ZennoPoster Pro\ваша версия\Progs\ExternalAssemblies"
В projectMaker во вкладке «Проекты» создаем «ссылки из Gac» и «Директивы using» (щелкните правой кнопкой мыши)
Открываем ссылки из Gac, жмем добавить, жмем обзор, выбираем файл epplus.dll, который должен быть по пути "C:\Program Files (x86)\ZennoLab\RU\ZennoPoster Pro\ваша версия\Progs\ExternalAssemblies"
Теперь открываем «директивы using» и вставляем такой код:
C#:
using OfficeOpenXml;
using OfficeOpenXml.Style;Теперь создаем на компьютере xlsx табличку и можно начинать работать с ней в кубике C#.
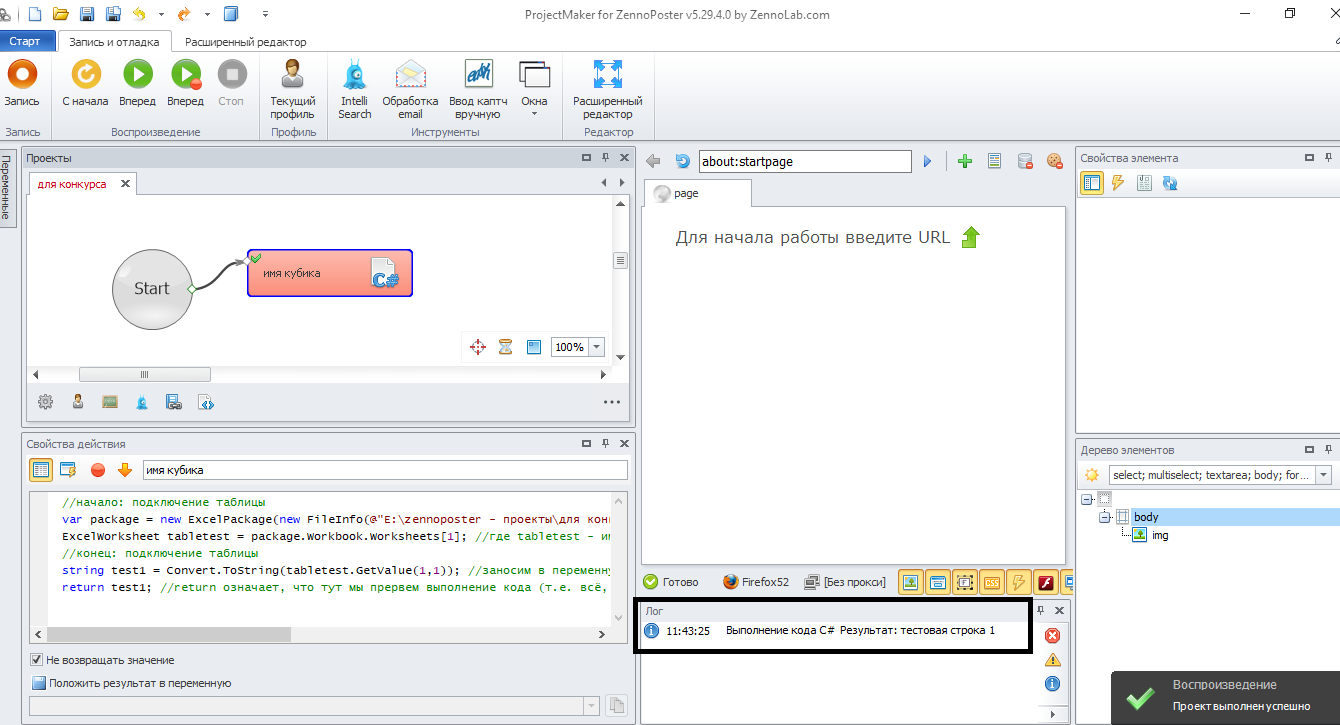
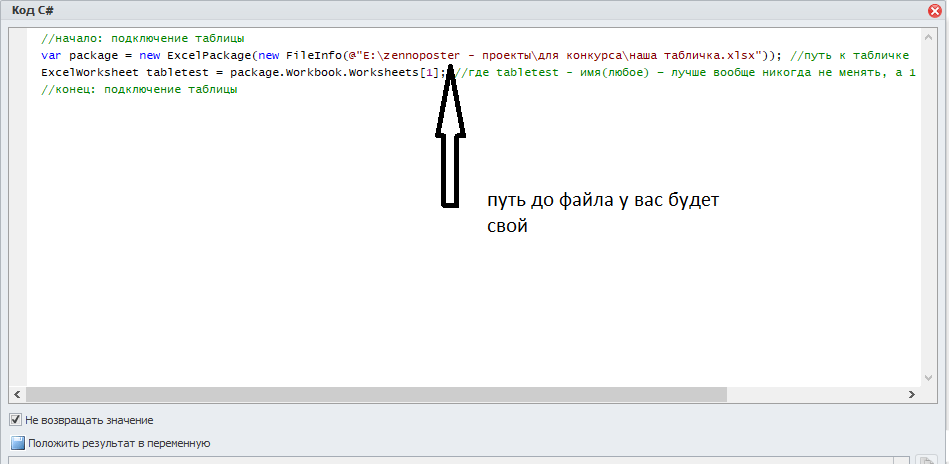
В кубике C# в свойствах действия вверху кода прописываем подключение таблицы:
C#:
//начало: подключение таблицы
var package = new ExcelPackage(new FileInfo(@"E:\zennoposter - проекты\для конкурса\наша табличка.xlsx")); //путь к табличке
ExcelWorksheet tabletest = package.Workbook.Worksheets[1]; //где tabletest - имя(любое) – лучше вообще никогда не менять, а 1 - номер листа в excel
//конец: подключение таблицыОк. Теперь научимся работать с нашей таблицей. Сначала заполним её чем-нибудь:
Чтобы получить что-то из таблицы, мы используем такой код:
C#:
string test1 = Convert.ToString(tabletest.GetValue(1,1)); //заносим в переменную test1 значение в 1 строке 1 столбце
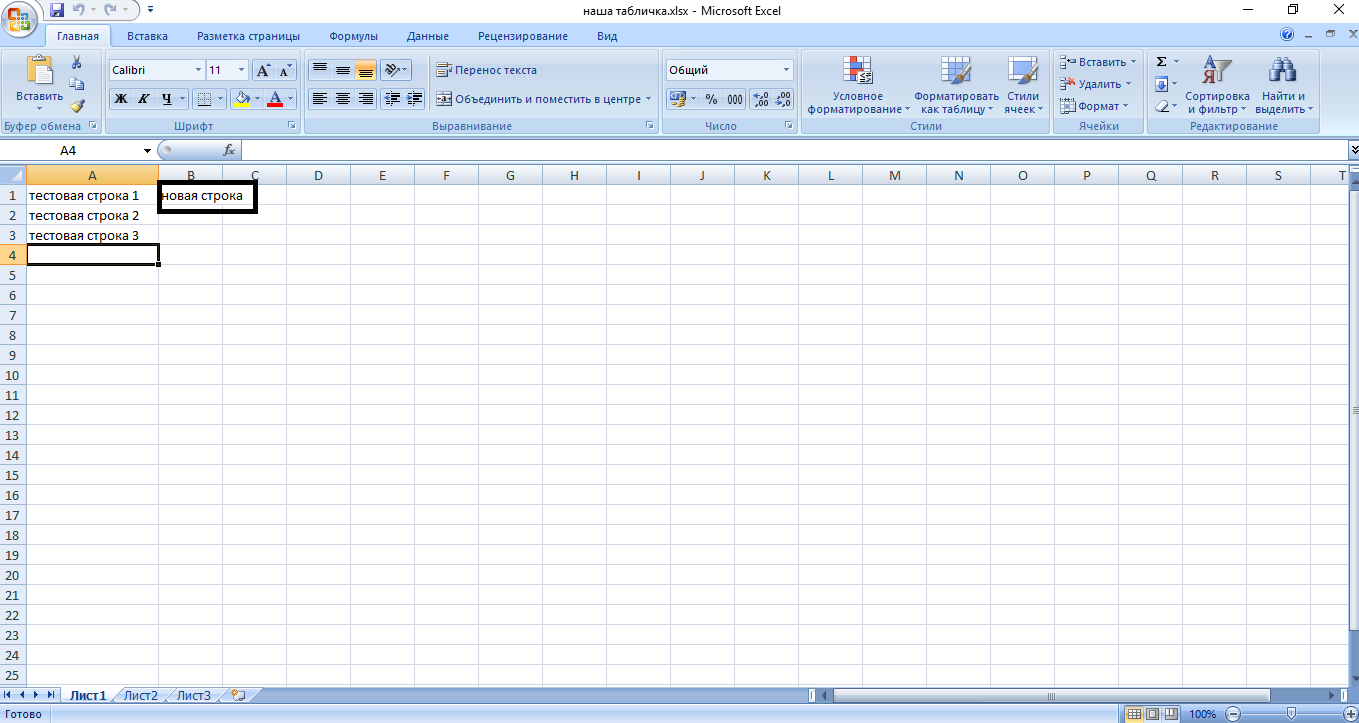
return test1; //return означает, что тут мы прервем выполнение кода (т.е. всё, что идет после return выполняться не будет) и выведем в лог значение переменной test1Чтобы записать что-то в таблицу, мы используем такой код:
C#:
tabletest.SetValue(1,2,"новая строка"); //в 1 строку 2 столбец запиши фразу новая строка
package.Save(); //сохрани измененияЧтобы удалить из таблицы какую-то строку или колонку, мы используем такой код:
C#:
tabletest.DeleteRow(1); //удалить строку
tabletest.DeleteColumn(1); //удалить колонку
package.Save(); //сохранение измененийДля подсчета количества строк использовать такой код:
C#:
string test = tabletest.Dimension.Rows.ToString(); //считаем количество строк
return test;P.S. В Epplus.dll счет начинается не с нуля, а с одного
Учимся находить элементы на странице
Для нахождения элементов будем использовать Xpath. Установите к себе в гугл хром дополнение «Xpath Helper Wizard».
Я вам распишу то, что подходит в 80% случаев. Если захотите капнуть глубже, то почитайте статьи про xpath с предыдущих конкурсов и поизучайте примеры тут - http://www.zvon.org/xxl/XPathTutorial/General_rus/examples.html
Давайте поищем элементы на разных страницах. Начнем с ютуба. Предположим, мы хотим собрать ссылки на видео.
Давайте кратко по теории. Любая страница состоит из html тегов, например:
- <p>
- <a>
- <span>
- <div> и т.д.
У этих тегов есть разные атрибуты (чаще всего), например:
- <p class=”vacy”>какой-то текст </p>
- <a href=”http://site.ru” id=”ssylk” class=”tver”>ссылка</a>
Так вот, наша задача – найти нужный нам тег с нужными нам атрибутами. Далее будет понятно.
Итак, наша задача – найти ссылки. Ссылки у нас обозначаются тегом <a>. Идем в хром, жмем по значку xpath helper wizard и во второе поле пишем //a (P.S. Xpath пути всегда начинаются с двух косых черточек //)
Розовое – это все ссылки на странице. Но нам ведь нужны только ссылки на видео, так? Для этого нам надо указать какой-то уникальный атрибут, который есть только у нужных нам ссылок. Сначала посмотрим, что за атрибуты есть у нужных нам ссылок. Нажмем правой кнопкой мыши по нужному нам элементу и выберем «просмотреть код».
Смотрите, какие атрибуты есть у нашей ссылки: id, class, title, ahref, aria-label
Давайте пробовать искать по ним и смотреть, какие элементы будут выделяться. В Xpath Helper Wizard пишем: //a[@id='video-title']
Смотрите, судя по всему выделилось именно то, что нам нужно. Если бы не нашли то, что нужно, то надо было бы пробовать дальше:
Давайте закрепим пройденное. Зайдем сюда (мы хотим спарсить ссылки на ресурсы): https://www.liveinternet.ru/rating/ru/
Жмем правой кнопкой мыши
Смотрим на атрибуты и пробуем искать:
Давайте теперь рассмотрим другие варианты нахождения элемента. Единственное, поясню ещё момент. Вы должны четко понимать, что хотите найти. Давайте зайдем на ozon.ru и опять попробуем найти ссылку:
Смотрите, тут у нас тег span, а не <a>. Если нам нужны ссылки на товары, нам нужна именно ссылка, а не тег span. Как её найти в данном случае? Просто перемещаемся по коду выше (или ниже) и смотрим, что у нас выделяется
Видите, я промотал чуть выше и нашел нашу ссылку.
С этим разобрались. Покажу ещё пару примеров, которые часто используются (например, по каким-то причинам предыдущий способ не помог). Давайте сначала на примере ютуб:
//a[contains(@id, 'video-title')] – найди тег <a>, у которого в атрибуте id содержится video-title (P.S. Тоже самое, как в предыдущем методе, только там было равно, а здесь содержится)
//a[contains(text(), 'ДЖЕРРАРД')] – найди тег a, у которого в тексте есть слово ДЖЕРРАРД
//h3[contains(@class, 'style')]/a[contains(@id, 'video')] – найди сначала тег h3, у которого class содержит style , а затем найди его «ребенка» тег a, у которого id содер жит video. P.S. Под ребенком я подразумеваю, что тег a находится внутри h3.
Вариант для ленивых (предупреждение: пути, сформированные таким образом вряд ли долго проживут)
Хотя тут он выдал вполне себе хороший путь:
//*[@id="video-title"] – означает найди любой тег, у которого id равен video-title. Только project maker будет ругаться на двойные кавычки, вместо них надо вставить одинарные. Вот так: //*[@id='video-title']
И забыл ещё вот что. Смотрите, тут у нас 27 результатов:
Мы можем выбрать любой из них по номеру, но делать это будем в project maker.
Итак, мы научились находить нужные нам элементы. Давайте теперь их сложим в таблицу. Полностью рабочий код для youtube:
C#:
HtmlElementCollection luboe_imy = null; //все HtmlElementCollection лучше объявлять в самом верху
//начало: подключение таблицы
var package = new ExcelPackage(new FileInfo(@"E:\zennoposter - проекты\для конкурса\наша табличка.xlsx")); //путь к табличке
ExcelWorksheet tabletest = package.Workbook.Worksheets[1]; //где tabletest - имя(любое) – лучше вообще никогда не менять, а 1 - номер листа в excel
//конец: подключение таблицы
instance.ActiveTab.Navigate("https://youtube.com"); //переходим на сайт
instance.ActiveTab.WaitDownloading(); //дожидаемся загрузки страницы
luboe_imy = instance.ActiveTab.FindElementsByXPath("//a[@id='video-title']"); //парсим данные: Xpath путь
for(int i=1; i<luboe_imy.Count; i++) //цикл перебора найденных элементов. luboe_imy.Count означает, что цикл будет крутиться до тех пор, пока не закончатся все найденные нами элементы
{
string ssylk = luboe_imy.GetByNumber(i).GetAttribute("href"); //ложим в переменную ssylk атрибут href нашего элемента
project.SendInfoToLog(ssylk); //выводим в лог для самопроверки
tabletest.SetValue(i,2, ssylk); //записываем данные в таблицу: строка, столбец, что записываем
}
package.Save(); //сохраняем в таблицуP.P.S. В процессе написания шаблона столкнулся с такой фигней. Данные не парсились, и я не мог понять почему. В project maker автоматически генерируется профиль:
Так вот, у меня генерировался английский профиль и при заходе на ютуб открывалась англоязычная версия сайта. Оказывается, в англоязычной версии нужен уже совершенно другой Xpath путь. Так что перед запуском убедитесь, что у вас сгенерирован русский профиль и открывается русская версия сайта ютуб.
Пробуем писать парсер
Давайте напишем парсер, который будет собирать названия наушников и цену со всех страниц этой категории - https://doctorhead.ru/catalog/naushniki_moscow/
У нас есть 88 страниц, которые надо спарсить. Как мы получим ссылки? Часто это проще сделать вручную, чем писать под это дело код. Смотрите, как формируются у нас страницы:
- https://doctorhead.ru/catalog/naushniki_moscow/2/
- https://doctorhead.ru/catalog/naushniki_moscow/3/
- https://doctorhead.ru/catalog/naushniki_moscow/4/
- и т.д. до 88 страницы (https://doctorhead.ru/catalog/naushniki_moscow/88/)
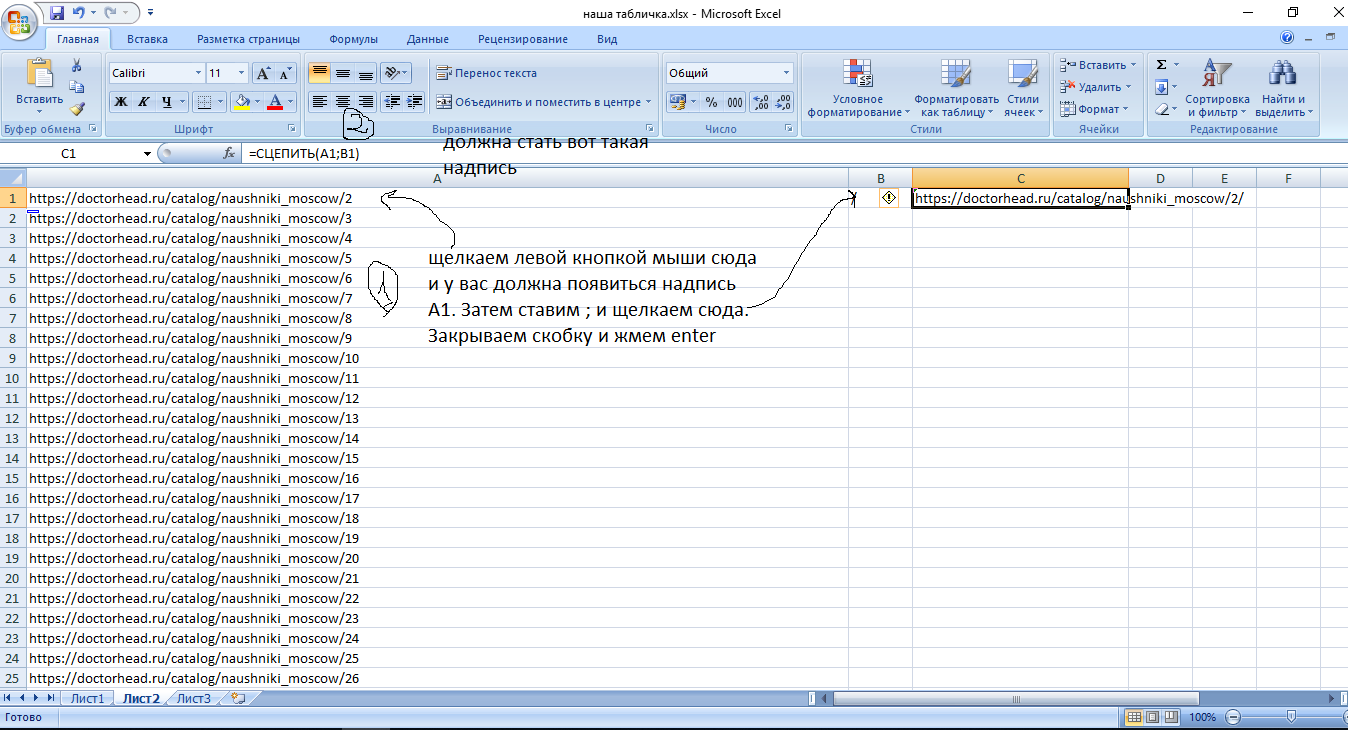
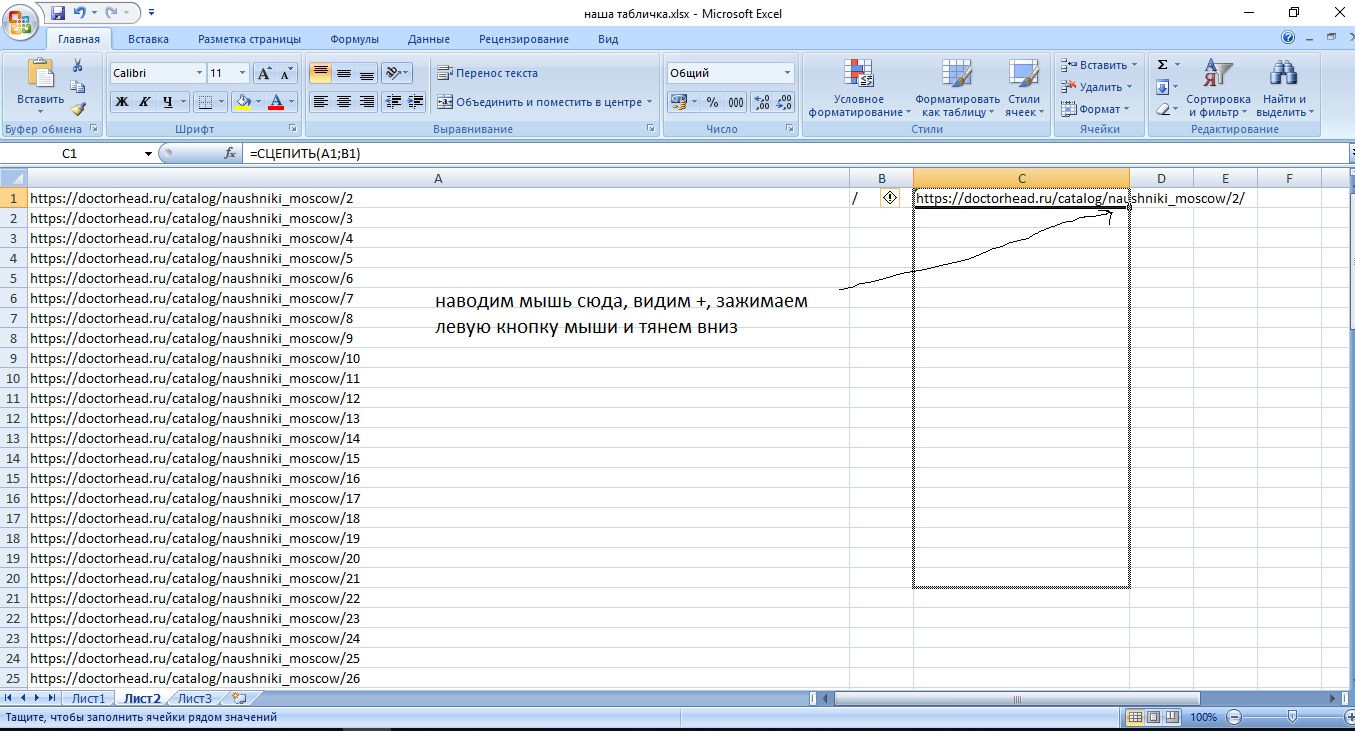
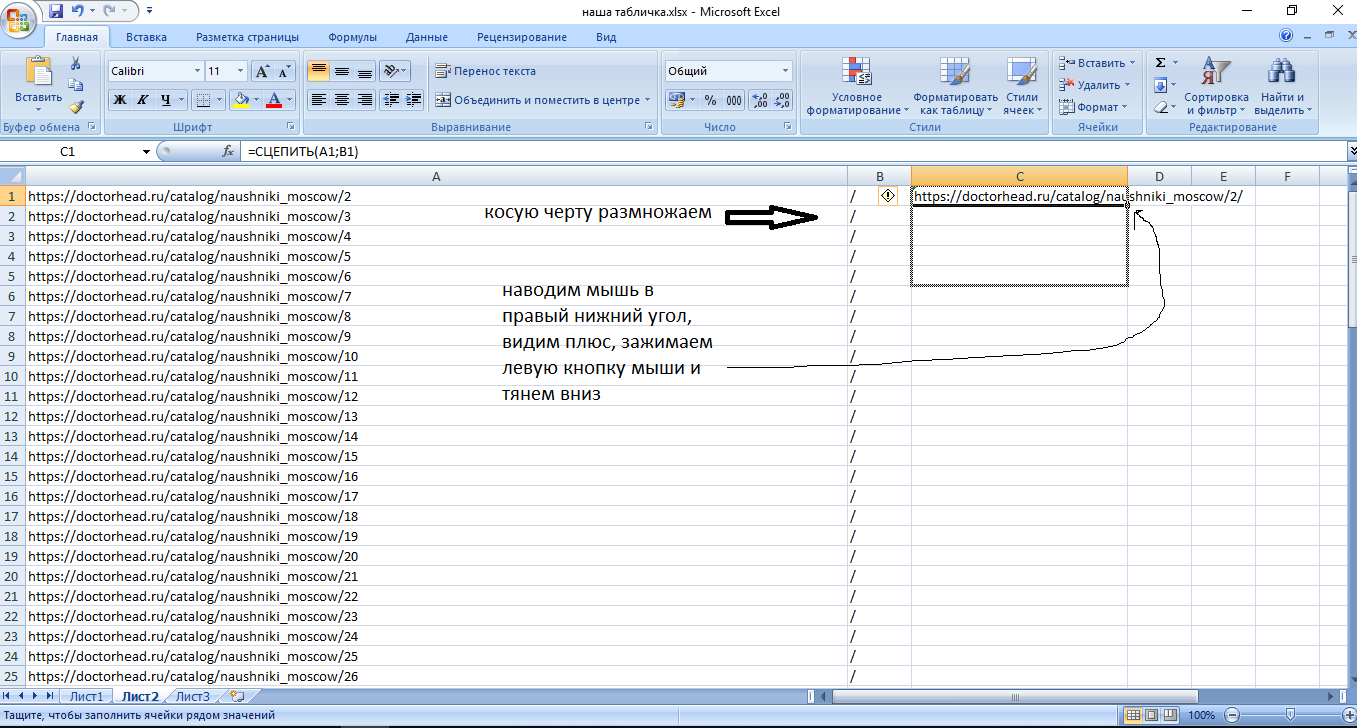
Как мы их получим? Идем в excel и делаем следующим образом:
Если вы обратили внимание, то тут я убрал косую черту на конце:
- было https://doctorhead.ru/catalog/naushniki_moscow/88/
- а я сделал https://doctorhead.ru/catalog/naushniki_moscow/88
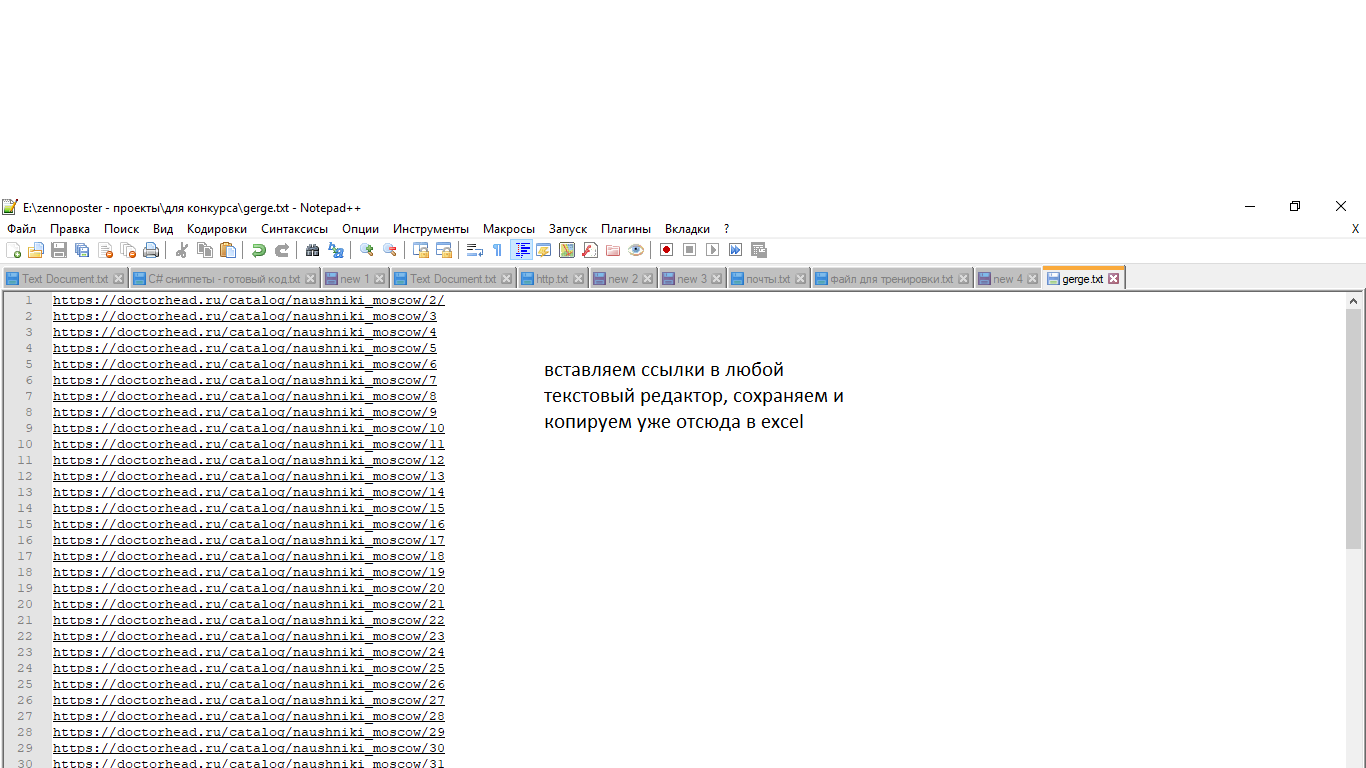
Это нужно для размножения в excel. Обычно у сайтов настроен редирект и проблем не возникает, однако здесь такое не катит. Т.е. тут нам нужны ссылки именно такого вида https://doctorhead.ru/catalog/naushniki_moscow/88/. Как мы их получим:
Теперь создадим новый xls файл, дадим названия для столбцов и вставим полученные ссылки в первый столбец:
Этап 2
Итак, мы с вами получили ссылки, с которых будем парсить. Давайте теперь перейдем в Project Maker и напишем код, который будет переходить по этим ссылкам и находить те элементы, что мы хотим спарсить.
Добавим кубик C# код:
Добавим ссылки из gac и директивы Using:
В ссылки из Gac добавим библиотеку epplus.dll
И подключим её, прописав в директивы using:
C#:
using OfficeOpenXml;
using OfficeOpenXml.Style;Так, теперь нам надо написать код, который будет переходить по ссылкам и находить нужные нам элементы. Логика такая:
- берем ссылку из таблицы
- переходим по ней
- находим название наушников, цену наушников, ссылку на наушники
- повторяем снова, пока не кончатся все наши ссылки
Теперь нам надо составить Xpath пути, которые мы пропишем в скобках.
Давайте сначала найдем названия товаров (в коде у нас это zagolovki). Переходим на сайт в гугл хроме, жмем по нужному нам элементу правой кнопкой мыши и выбираем просмотреть код:
Вот мы сразу её нашли:
Мы видим, что нам нужна ссылка (тег <a>) у которой есть атрибут class со значением head_name_item. Пробуем составить Xpath путь (используется плагин для гугл хром Xpath Helper Wizard):
Видим, что нам сходу удалось выделить те элементы, что нужно. Проверим этот XPath путь на других страницах:
Видим, что и здесь всё хорошо. Это мы составили Xpath путь для поиска названий товаров. Давайте пропишем его в коде:
И давайте сразу запоминать, что нам нужно будет получить из найденного элемента: значение какого-то атрибута или текст? В данном случае это текст
Идем дальше. Давайте теперь составим Xpath путь для ценника. Тоже самое: наводимся на ценник, жмем правую кнопку мыши, просмотреть код и находим его в коде:
Видим, что тут тег span, у которого есть class="pi_price_cur". Пробуем составить Xpath путь:
Видим, что всё норм. Добавляем его в код:
Также отметили для себя, что нам нужен будет текст, а не значение какого-то атрибута.
Теперь найдем нашу ссылку. Наводимся, жмем правую кнопку мыши, просмотреть код и находим её в коде:
Код не кажется вам знакомым? Мы его уже находили, когда искали заголовок. Только тогда нам нужен был ТЕКСТ, а теперь нам нужно ЗНАЧЕНИЕ АТРИБУТА HREF.
Раз мы его уже находили, удаляем из кода последнюю строчку, т.к. она лишняя.
В итоге у нас получился вот такой код:
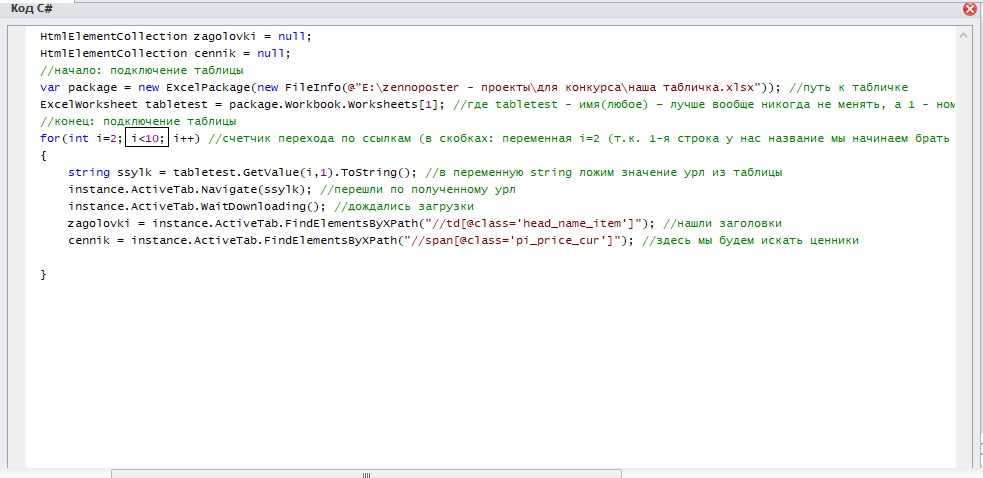
Давайте протестируем, нет ли каких-либо ошибок. Только вместо tabletest.Dimension.Rows поставим, например, 10 (иначе нам придется ждать, пока он обойдет все 88 страниц). Что он должен делать: брать ссылку из таблицы, переходить по ней, находить нужный элемент.
Вроде бы всё норм, ошибок не видно:
Этап 3
Так, идем дальше. Теперь нам надо перебрать в цикле собранные нами данные и сохранить в таблицу.
Для этого прям внутри этого цикла создадим ещё один цикл для перебора наших коллекций. Какая его логика:
- берем первый элемент из коллекции, достаем оттуда нужное значение
- записываем это значение в таблицу
- повторяем до тех пор, пока не закончатся элементы в коллекции
Давайте разберем каждую строчку:
- for(int k=0; k<cennik.Count; k++) {} – поскольку у нас в коллекции содержится множество элементов, чтобы их вытащить, нужен счетчик. При этом счетчик крутиться до тех пор, пока k меньше чем количество элементов в коллекции (k<cennik.Count)
- string zag = zagolovki.GetByNumber(z).InnerText; - тут мы с вами вытаскиваем конкретную строчку из нашей коллекции. Изначально z = 0. Т.е. мы получаем нулевую строку. При следующей итерации z станет равным 1, и мы получим следующую строку и т.д. Обратите внимание, где именно мы объявили этот счетчик (в предыдущем цикле).
- tabletest.SetValue(a,2,zag); - тут мы записываем в таблицу. Вместо a будет подставлено 2, значит, при первой итерации мы запишем с вами в 2 строку 2 столбец. При следующей итерации a станет равной 3 и данные запишутся в 3 строку 2 столбец
- package.Save(); - нужно для сохранение данных в таблицу на компьютере
- z++ - нам надо увеличить значение z на единицу, чтобы в следующем круге он взял уже следующий элемент
- a++ - нам надо увеличить значение a на единицу, чтобы в следующем круге он записывал уже на следующую строку
Тут вам надо понять логику кода.
Так, это мы с вами сложили названия товаров. Нам также надо сложить с вами ценники и ссылки на сами товары. Давайте это сделаем.
Обратите внимание на получение ссылки. Помните, я говорил, что нам надо запомнить, что мы планируем изъять текст или значение какого атрибута? Так вот, тут нам нужно как раз значение атрибута href найденного нами элемента, а не текст ссылки. Поэтому мы и написали .GetAttribute(“”);
По сути всё, мы закончили. Обязательно закройте на компьютере таблицу xls, иначе project maker выдаст ошибку при попытке сохранения данных.
Давайте пробовать запускать.
У меня не спарсилось название товара и ссылка на товар? Где проблема? Она в Xpath пути. Я там проверял кое-что и специально сделал неправильный XPath путь (а затем забыл изменить обратно), поэтому так. У вас всё должно было отработать норм. Сейчас покажу где (а то вдруг кто-то запутается)
Так, пробуем запустить ещё раз:
Вот теперь всё норм. Осталось нам на 7 строке вместо i<10 написать i<89; чтобы спарсились все страницы.
P.S. Конкретно в этом шаблоне не так как нужно (имею ввиду мне) отрабатывает команда tabletest.Dimension.Rows. Я уже подустал, нету сил разбираться, где я там накосячил, поэтому просто вручную задаем нужное количество страниц и не паримся.
В видео представлена переделка шаблона под себя на примере парсинга вот этой категории - https://zennolab.com/discussion/forums/voprosy-novichkov.16/. Видео записывалось в режиме Live на ноутбуке, поэтому звук не очень и подача довольно хаотична. Косяки вырезать не стал, ставил на паузу когда уж совсем упирался в стену.
- Тема статьи
- Парсинг
- Номер конкурса статей
- Одиннадцатый конкурс статей
Вложения
-
14,5 КБ Просмотры: 626
-
13,4 КБ Просмотры: 589
-
412,4 КБ Просмотры: 1 367
Для запуска проектов требуется программа ZennoPoster или ZennoDroid.
Это основное приложение, предназначенное для выполнения автоматизированных шаблонов действий (ботов).
Подробнее...
Для того чтобы запустить шаблон, откройте нужную программу. Нажмите кнопку «Добавить», и выберите файл проекта, который хотите запустить.
Подробнее о том, где и как выполняется проект.
Последнее редактирование модератором:

 :-)") )
)