- Регистрация
- 20.04.2015
- Сообщения
- 6 243
- Благодарностей
- 6 561
- Баллы
- 113
ку, пришло время работать с большим количеством строк, TXT файлы тут явно не прокатят как раньше )
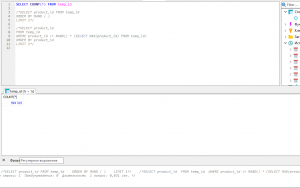
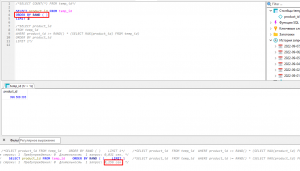
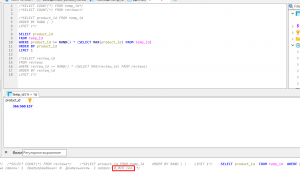
короче говоря есть БД на 40гб в ней куча строк, надо взять каждую и сделать запрос по урлу в строке.
вопросы:
1. как лучше брать строки? есть также уникальные id в бд у каждой строки, если это важно
2. как НЕ взять туже строчку, которая уже в работе?
3. как лочить запросы к бд? гуглеж по форуму, дал инфу но я не разобрался в шарпах
моя логика
берем строку, обновляем статус строки на "в работе", делаем то что надо, в конце снова обновляем стату на "готово"
предложите свой вариант работы с бд, если он лучше и/или быстрее моего
прошу отписаться кто имел опыт.
спасибо
короче говоря есть БД на 40гб в ней куча строк, надо взять каждую и сделать запрос по урлу в строке.
вопросы:
1. как лучше брать строки? есть также уникальные id в бд у каждой строки, если это важно
2. как НЕ взять туже строчку, которая уже в работе?
3. как лочить запросы к бд? гуглеж по форуму, дал инфу но я не разобрался в шарпах
моя логика
берем строку, обновляем статус строки на "в работе", делаем то что надо, в конце снова обновляем стату на "готово"
предложите свой вариант работы с бд, если он лучше и/или быстрее моего
прошу отписаться кто имел опыт.
спасибо

 ну пусть работает
ну пусть работает :-)")