Смотрите видео ниже, чтобы узнать, как установить наш сайт в качестве веб-приложения на домашнем экране.
Примечание: Эта возможность может быть недоступна в некоторых браузерах.
Вы используете устаревший браузер. Этот и другие сайты могут отображаться в нём некорректно. Вам необходимо обновить браузер или попробовать использовать другой.
Навредит. Из-за индексов увеличивается время вставки/удаления из таблицы. Чем больше индексов - тем дольше будет вставлять новую строчку (т.к. обрабатывает индекс каждую вставку).
На мелких базах это будет незаметно, но когда данных будет много - вы почувствуете, что явно что-то тормозит))
Поэтому индексы нужно создавать с умом. Это целая наука и тут вряд ли кто-то точно скажет как быть, в идеальном мире нужно анализировать запросы в базе с индексами и без индексов, но мало кто так делает.
Поэтому просто не перебарщивайте с количеством индексов и делайте только те, которые нужны. И не дублируйте индексы (речь о индексе из нескольких полей).
Вот про такое я не писал ))
Тут от данных сильно зависит, но не думаю, что в конкретно этом примере будет какой-то прирост, если удалять дубли самому как-то
- на id оно же уникальное/ autoincrement / UNSIGNED ?
и вообще с этого начинается организация базы данных ))
status - enum или set
timestamp - такое же и поле должно быть (timestamp) у меня везде datatime
login - есть выборки по нему точно т.к. это var или varchar небось?
От части, дело в том что индексы в оперативе хранятся для как раз быстрого поиска... https://habr.com/post/66684/
key_buffer_size — крайне важная настройка при использовании MyISAM-таблиц. Установите её равной около 30-40% от доступной оперативной памяти, если используете только MyISAM. Правильный размер зависит от размеров индексов, данных и нагрузки на сервер — помните, что MyISAM использует кэш операционной системы (ОС), чтобы хранить данные, поэтому нужно оставить достаточно места в ОЗУ под данные, и данные могут занимать значительно больше места, чем индексы. Однако обязательно проверьте, чтобы всё место, отводимое директивой key_buffer_size под кэш, постоянно использовалось — нередко можно видеть ситуации, когда под кэш индексов отведено 4 ГБ, хотя общий размер всех .MYI-файлов не превышает 1 ГБ. Делать так совершенно бесполезно, Вы только потратите ресурсы. Если у Вас практически нет MyISAM-таблиц, то key_buffer_size следует выставить около 16-32 МБ — они будут использоваться для хранения в памяти индексов временных таблиц, создаваемых на диске.
innodb_buffer_pool_size — не менее важная настройка, но уже для InnoDB, обязательно обратите на неё внимание, если собираетесь использовать в основном InnoDB-таблицы, т.к. они значительно более чувствительны к размеру буфера, чем MyISAM-таблицы. MyISAM-таблицы в принципе могут неплохо работать даже с большим количеством данных и при стандартном значении key_buffer_size, однако mySQL может сильно «тормозить» при неверном значении innodb_buffer_pool_size. InnoDB использует свой буфер для хранения и индексов, и данных, поэтому нет необходимости оставлять память под кэш ОС — устанавливайте innodb_buffer_pool_size в 70-80% доступной оперативной памяти (если, конечно, используются только InnoDB-таблицы). Относительно максимального размера данной опции — аналогично key_buffer_size — не стоит увлекаться, нужно найти оптимальный размер, найдите лучшее применение доступной памяти.
я спрашивал нужно ли ставить на timestamp индекс или он (timestamp) по-умолчанию при создании типа 'timestamp' добавляется в индекс, и привёл пример как primary key я же на него индекс (на primary key) не создаю, а он есть )))
login у меня varchar, какой ещё тип подойдёт под login@mail.ru?
Выборки по нему нету, но в индекс его приходится добавлять, чтобы не было дублей. Если можно как-то сделать уникальность логина без создания индекса то сделал бы с радостью.
p.s. полезно ли будет создать индекс на 'timestamp', 'date', 'datetime' ?
или на датах лучше от этого воздержаться?
Индексы нужно делать в первую очередь на столбцах, по которым идет активные выборки (WHERE ...).
Тип - не имеет значения, главное чтоб там были данные конечной длинны (чем короче - тем лучше, идеального варианта не существует, но явно никто не догадается сделать индекс на поле, где будет 1МБ данных).
Так что если делаете выборки по этим полям, то делайте индекс. Причем если используете поле в запросах активно, а не так, что это поля, по которым выборка делается раз в день, а по остальным каждую секунду, то есть чтоб не вышло, что этот индекс по большому счёту и не нужен.
Вообще, по хорошему - индексы делаются уже когда в базе чуть-чуть данных появилось и уже более-менее запросы какие-то написаны, а не сразу при создании базы придумывать индексы на все случаи жизни (вот так точно делать не надо, а то потом индексы будут весить кучу места и тормозить).
О том и речь, что оперативка - конечна ) Но, к слову, вроде там сейчас уже всё сложнее, и не всегда индекс напрямую в ОЗУ хранится полностью (если не путаю с архитектурой PostgreSQL).
да само собой нужен index (не uniq и не primary key) тем более вес у них небольшой при этой переменной, я ставлю на них если есть выборка или сортировка...
Вообще, по хорошему - индексы делаются уже когда в базе чуть-чуть данных появилось и уже более-менее запросы какие-то написаны, а не сразу при создании базы придумывать индексы на все случаи жизни (вот так точно делать не надо, а то потом индексы будут весить кучу места и тормозить).
ищи в гугле индексирование таблиц mysql
также изучи курс, который я рекомендовал ранее https://geekbrains.ru/courses/86 можешь поискать на торрентах. там как раз узнаешь про объединение таблиц
Доброго времени суток. Опять пишу сюда с вопросом. Изучил рекомендуемый курс и в целом немного разобрался что к чему. Переделал все с примерно такой же логикой, о которой вы говорили. Запросы исполняются быстро, но теперь возникает другая ошибка.
Код:
Выполнение действия CSharp OwnCode Authentication to host 'xxxx' for user 'xxx' using method 'mysql_native_password' failed with message: User admin_denis already has more than 'max_user_connections' active connections
Я увеличил max_connections с 70ти до 400, но это не сильно помогло. Причем люди на разных форумах пишут, что 400 для работы средненького сайта очень много. Конечно у меня база не для сайта, но все же не пойму что не так
Причем люди на разных форумах пишут, что 400 для работы средненького сайта очень много. Конечно у меня база не для сайта, но все же не пойму что не так
Вы скорее всего открываете соединения, но не закрываете их. Они накапливаются и висят пока не сдохнут по таймауту. Сложно сказать что-то более точное, не зная как именно вы подключаетесь и работаете с базой.
Вы скорее всего открываете соединения, но не закрываете их. Они накапливаются и висят пока не сдохнут по таймауту. Сложно сказать что-то более точное, не зная как именно вы подключаетесь и работаете с базой.
Я сам именно об этом и думал, но хоть убей не могу найти ошибку. Если не сложно, гляньте свежим взглядом на шаблон. Он простейший, я специально убрал все лишнее и оставил только 4 кубика с запросами к базе.
Я сам именно об этом и думал, но хоть убей не могу найти ошибку. Если не сложно, гляньте свежим взглядом на шаблон. Он простейший, я специально убрал все лишнее и оставил только 4 кубика с запросами к базе.
Глянул по быстрому, работа идет через обертку, поэтому может быть и там что-то..
На первый взгляд возможны следующие моменты:
1)
Код:
cmd.Connection.Open();
cmd.DbLock("Users_parse WRITE");//блокирую таблицу
cmd.ExNonQ(@"INSERT INTO `Users_parse`(`uid`) VALUES ("+project.Variables["User"].Value+@")");
cmd.DbUnLock();//разблокировка всех таблиц
cmd.Connection.Close(); //закрываем сессию
в подобном сниппете, если произойдет вылет между открытием и закрытием (например при запросе ExNonQ)- возникнет проблема - соединение не будет закрыто. Такие блоки надо заключать в try finally. и аналогично с блокировками, т.е.
2) Второй спорный момент - блокировка на уровне таблицы. В работе это выглядит так - один поток пишет, а все остальные ждут. Часть ожидающих может вылететь по таймауту и соответственно в вашем коде не будет проведено закрытие соединения.
Глянул по быстрому, работа идет через обертку, поэтому может быть и там что-то..
На первый взгляд возможны следующие моменты:
1)
Код:
cmd.Connection.Open();
cmd.DbLock("Users_parse WRITE");//блокирую таблицу
cmd.ExNonQ(@"INSERT INTO `Users_parse`(`uid`) VALUES ("+project.Variables["User"].Value+@")");
cmd.DbUnLock();//разблокировка всех таблиц
cmd.Connection.Close(); //закрываем сессию
в подобном сниппете, если произойдет вылет между открытием и закрытием (например при запросе ExNonQ)- возникнет проблема - соединение не будет закрыто. Такие блоки надо заключать в try finally. и аналогично с блокировками, т.е.
2) Второй спорный момент - блокировка на уровне таблицы. В работе это выглядит так - один поток пишет, а все остальные ждут. Часть ожидающих может вылететь по таймауту и соответственно в вашем коде не будет проведено закрытие соединения.
Протестировал шаблон с учетом ваших замечаний. Все так же на 50ти потоках начинают сыпаться эти ошибки. Я так понял ,что ваш код "страхует" шаблон при возникновении различных ошибок и вылетов. Но других ошибок кроме этой у меня не возникает. Вчера шаблон работал пол дня в 30 потоков. Вылетов по таймауту не было, но как только я увеличиваю потоки, появляется ошибка соединений, при этом других ошибок так же не наблюдается. Исходя из этого, все сниппеты должны закрывать открытые сессии.
Я уже думаю попробовать изменить логику и за один запрос брать не одну строку из таблицы, а сразу например 10, но это вызовет другие неудобства в работе. И это уже наверное костыли какие-то.... Мне казалось, что базы данных созданы, чтобы ускорять какой-либо перебор данных. Может быть я вообще пытаюсь использовать все это не по назначению?
За ссылку спасибо. Не все знал, что там написано, но моей проблемы это не решает. У меня база с таблицей в 3 столбца и я не знаю как там можно дико накосячить, что бы сыпались ошибки подключения.
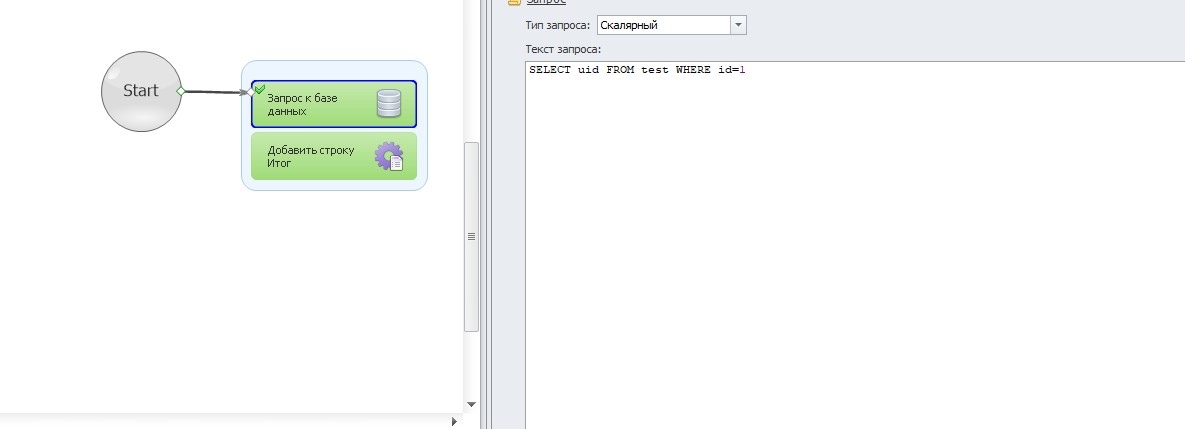
Я ради эксперимента сделал шаблон, который кубиком просто считывает первую строчеку из моей базы и заносит в список.
Этот шаблон я сразу запустил в 100 потоков, из них 90 успехов, а остальное опять ошибка подключения Может это вообще норма?))
Честно говоря совершенно не понимаю где это посмотреть.... Я сделал еще один тест. Создал такую же базу на моем виртуальном хостинге и запустил вышеупомянутый шаблон с двумя кубиками в 100 потоков и все они отработали успешно. То есть на виртуальном хостинге все работает, а на VPS нет.... Значит уровень проблемы не тот о котором я изначально думал и может быть вы правы, но я не понимаю, что делать и как это вообще гуглить.
Оптимизировать/настраивать БД на ВПС. Частая проблема - оверселлинг. Когда ре урсов продается больше, чем железо может вытянуть в пике производительности на самом деле. В таком случае можно теребить саппорт или поменять хостера.
Оптимизировать/настраивать БД на ВПС. Частая проблема - оверселлинг. Когда ре урсов продается больше, чем железо может вытянуть в пике производительности на самом деле. В таком случае можно теребить саппорт или поменять хостера.
Решил разобраться с шаблоном. Выдает:
"Компиляция кода проекта Ошибка в действии "CS0006" "Не удалось найти файл метаданных "C:\Program Files\ZennoLab\RU\ZennoPoster Pro V7\7.1.4.0\Progs\ExternalAssemblies\RecaptchaSolution.dll". Где взять эту библиотеку? Навскидку не нашел ни у себя на компе, ни в Интернете.
Решил разобраться с шаблоном. Выдает:
"Компиляция кода проекта Ошибка в действии "CS0006" "Не удалось найти файл метаданных "C:\Program Files\ZennoLab\RU\ZennoPoster Pro V7\7.1.4.0\Progs\ExternalAssemblies\RecaptchaSolution.dll". Где взять эту библиотеку? Навскидку не нашел ни у себя на компе, ни в Интернете.