

Привет! Ребят не подскажите , есть ли универсальное регулярное выражение для парсинга ссылок и email-ов со страницы? . Пока пользуюсь этим (?<=href=")http://.*?(?=") и этим [\.\-_A-Za-z0-9]+?@[\.\-A-Za-z0-9]+?[\.A-Za-z0-9]{2,}, но это для конкретного сайта, неизвестно как на других будет работать. И еще вопрос как сделать, чтобы бот не уходил за пределы сайта?
Регулярка для парсинга ссылок
- Автор темы vitbn58
- Дата начала
- Регистрация
- 05.11.2014
- Сообщения
- 22 638
- Благодарностей
- 5 963
- Баллы
- 113
для ссылок - http://.*?(?=")
для e-mail - (\w+@.*?\.\w+)
Поясните, что значит бот уходит за пределы сайта.
для e-mail - (\w+@.*?\.\w+)
Поясните, что значит бот уходит за пределы сайта.

Мне допустим надо чтоб он собирал ссылки непосредственно например в пределах форума, а не выходил на сторонние ресурсы, рекламу там и прочие ненужные мне страницы. Походу это не решается, ссылка на рекламы хоть как проходит... Еще сразу спрошу. Если возможно опишите вкратце как сделать шаб, чтоб он работал многопоточно. Чет никак не соображу - не додумаюсь как как сделать чтоб каждый поток повторно ссылки не брал уже отсканированые предыдущим потоком.для ссылок - http://.*?(?=")
для e-mail - (\w+@.*?\.\w+)
Поясните, что значит бот уходит за пределы сайта.
Последнее редактирование:
- Регистрация
- 05.11.2014
- Сообщения
- 22 638
- Благодарностей
- 5 963
- Баллы
- 113
Бот собирает ссылки на той странице, на которой указываете в качестве сурса. Если парсятся лишние ссылки - это точность регулярки.Мне допустим надо чтоб он собирал ссылки непосредственно например в пределах форума, а не выходил на сторонние ресурсы, рекламу там и прочие ненужные мне страницы. Походу это не решается, ссылка на рекламы хоть как проходит...
Да эт я понял. Я имею ввиду. Допустим на странице есть полезные ссылки и ссылки бесполезные (реклама, ит.д.). Нет способа отсеять ненужное? Я пока майлы отсеиваю которые содержат support)Бот собирает ссылки на той странице, на которой указываете в качестве сурса. Если парсятся лишние ссылки - это точность регулярки.
- Регистрация
- 05.11.2014
- Сообщения
- 22 638
- Благодарностей
- 5 963
- Баллы
- 113
А как их понять, полезные они или нет?)Да эт я понял. Я имею ввиду. Допустим на странице есть полезные ссылки и ссылки бесполезные (реклама, ит.д.). Нет способа отсеять ненужное? Я пока майлы отсеиваю которые содержат support)
)) Ну как вариант - полезные точно те что содержат в себе URL главной страницы! Наверно так тока и остается отсеивать, хотя и полезное будет уходить. Ну как говориться лучше меньше , но качественней!)А как их понять, полезные они или нет?)
LexxWork
Client
- Регистрация
- 31.10.2013
- Сообщения
- 1 190
- Благодарностей
- 792
- Баллы
- 113
когда я делал для себя такой парсер то первым делом опредял доменое имя ресурса чтобы понять какие ссылки внешние, а какие внутренние. Потом просто рекусривно ходил по ссылкам и смотрел изменился ли домен после перехода. Если изменился, то значит эту ссылку удаляем если нужно. Еще лучше сразу же при получении контентайпа отсекать лишний контент, чтобы не захламлять трафик всякими картинками и прочей фигней.
для зенопостера такие задачи очень непродуктивны. Лучше пользоваться сторонним софтом без ограничений на потоки и возможностью использовать внешний пул задач и внешнее хранилище уникальных ссылок .
для зенопостера такие задачи очень непродуктивны. Лучше пользоваться сторонним софтом без ограничений на потоки и возможностью использовать внешний пул задач и внешнее хранилище уникальных ссылок .
Да пробовал я датакол, епочта и др. - они вообще не парсят нифига большинство сайтов, какието ошибки выдают и все, а зенка тока в путь. Можешь порекомендовать нормальный сторонний?когда я делал для себя такой парсер то первым делом опредял доменое имя ресурса чтобы понять какие ссылки внешние, а какие внутренние. Потом просто рекусривно ходил по ссылкам и смотрел изменился ли домен после перехода. Если изменился, то значит эту ссылку удаляем если нужно. Еще лучше сразу же при получении контентайпа отсекать лишний контент, чтобы не захламлять трафик всякими картинками и прочей фигней.
для зенопостера такие задачи очень непродуктивны. Лучше пользоваться сторонним софтом без ограничений на потоки и возможностью использовать внешний пул задач и внешнее хранилище уникальных ссылок .
LexxWork
Client
- Регистрация
- 31.10.2013
- Сообщения
- 1 190
- Благодарностей
- 792
- Баллы
- 113
я делаю парсеры на грабе https://github.com/lorien/grab
первоклассный проект и абсолютно бесплатный.
первоклассный проект и абсолютно бесплатный.
Ну ты продвинутый чувак - энглишь знаешь, а мне как ватнику быть?)я делаю парсеры на грабе https://github.com/lorien/grab
первоклассный проект и абсолютно бесплатный.
LexxWork
Client
- Регистрация
- 31.10.2013
- Сообщения
- 1 190
- Благодарностей
- 792
- Баллы
- 113
ZennoScript
Moderator
- Регистрация
- 04.03.2011
- Сообщения
- 4 452
- Благодарностей
- 1 888
- Баллы
- 113
Так а в коде страницы есть домен? Можно собирать только те ссылки, которые начинаются на нужный домен.
Т.е. регулярка, которая собирает ссылки должна выглядеть как то так:
(?<=href=")http://domen.com.*?(?=")
Т.е. регулярка, которая собирает ссылки должна выглядеть как то так:
(?<=href=")http://domen.com.*?(?=")
Ну
Спасибо. Ну как я понял netpeak spider ссылки грабит. А дальше, чтобы получить мыло, загонять полученные страницы опять же в зенну и собирать мыло?Граб - вещь! Сам уже 2 года гоняю.
Посмотрите xenu или netpeak spider
7make
Client
- Регистрация
- 25.06.2011
- Сообщения
- 1 547
- Благодарностей
- 1 312
- Баллы
- 113
Обращаем Ваше внимание на то, что данный пользователь заблокирован.
Не рекомендуем проводить с 7make какие-либо сделки.
https://developer.mozilla.org/ru/docs/Web/API/Document/links
JS => Выполнить на текущей странице
===
Можно еже фантом заюзать.
http://phantomjs.org/
п.с
JS => Выполнить на текущей странице
JavaScript:
var links = document.links;
var list = new Array(links.length);
for(var i = 0; i < links.length; i++) {
list[i] = links[i].href;
}
return list.join("\n");Можно еже фантом заюзать.
http://phantomjs.org/
п.с
вобщето граб русский и доки на русском )
как у граба с JS дела и сколько памяти жрет в среднем на 1 поток?Граб - вещь! Сам уже 2 года гоняю.
Оптимально для себя решил, ссылки парсю netpeak spider, затем обычной епочтой мыло собираю по ссылкам. netpeak spider примерно 40-80 минут 20000 ссылок парсит, что неплохо. А вот со сбором мыла со спарсенных страниц, епочта быстрей оказалась чем зенна, хотя тоже медленно. Не знаешь какой парсер мыл пошустрей со страниц?ну да
Имхо вообще xenu поудобнее будет она прям в txt файл это все выгружает, но смотрите сами как вам проще
Lexicon
Client
- Регистрация
- 27.12.2012
- Сообщения
- 1 775
- Благодарностей
- 901
- Баллы
- 113
C JS у него плохо, но как то я обхожусь без него. Постер из него конечно так себе, но парсер хорошийкак у граба с JS дела и сколько памяти жрет в среднем на 1 поток?
Если честно - никогда не забивал себе голову сколько жрет на один поток. Я обычно гоняю спайдер а он однопоточный но асинхронный. Задания выдаю из генератора, сохраняю или в файл или в БД... 600 потоков - летает только в путь, а в памяти лежит... ну допусть пусть те же 600 lxml объектов страницы не думаю что это сильно больше 100 метров
Как допилить код чтобы через запятую не парсил ссылку если в ней содержится определенный текст напримерhttps://developer.mozilla.org/ru/docs/Web/API/Document/links
JS => Выполнить на текущей странице
JavaScript:var links = document.links; var list = new Array(links.length); for(var i = 0; i < links.length; i++) { list[i] = links[i].href; } return list.join("\n");
/xml
/#
и.т.д...
Нужно дописать условие и регулярку вот только с js никогда не работаю...Как допилить код чтобы через запятую не парсил ссылку если в ней содержится определенный текст например
/xml
/#
и.т.д...
---
+ еще допилить домен для парсинга именно внутренних ссылок а не внешних
Andi88
Client
- Регистрация
- 17.10.2015
- Сообщения
- 228
- Благодарностей
- 26
- Баллы
- 28
Подскажите, как сделать, чтобы сохранялся результат в список?https://developer.mozilla.org/ru/docs/Web/API/Document/links
JS => Выполнить на текущей странице
===JavaScript:var links = document.links; var list = new Array(links.length); for(var i = 0; i < links.length; i++) { list[i] = links[i].href; } return list.join("\n");
Можно еже фантом заюзать.
http://phantomjs.org/
п.с
как у граба с JS дела и сколько памяти жрет в среднем на 1 поток?
Andi88
Client
- Регистрация
- 17.10.2015
- Сообщения
- 228
- Благодарностей
- 26
- Баллы
- 28
Добавляет вот так- в 1 группуТо что получилось добавляйте в список экшеном Операции с текстом - В список
Вложения
-
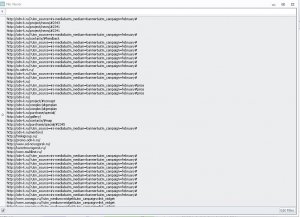 182 КБ Просмотры: 818
182 КБ Просмотры: 818
Redsmokky
Client
- Регистрация
- 06.10.2015
- Сообщения
- 320
- Благодарностей
- 197
- Баллы
- 43
Не совсем понял как работает такая регулярка, я например пытаюсь им сграбить ссылки с сайта http://www.domik-v-derevne.comТак а в коде страницы есть домен? Можно собирать только те ссылки, которые начинаются на нужный домен.
Т.е. регулярка, которая собирает ссылки должна выглядеть как то так:
(?<=href=")http://domen.com.*?(?=")
Результат нулевой(
Вложения
-
13,5 КБ Просмотры: 238
Спасибо за регулярку для e-mail ! Только попался на глаза e-mail (fkfshjfhjh-3@yandex.ru) с которым она не справилась( может можно ее доработать и под такой случай?для ссылок - http://.*?(?=")
для e-mail - (\w+@.*?\.\w+)
Поясните, что значит бот уходит за пределы сайта.
Dimionix
Moderator
- Регистрация
- 09.04.2011
- Сообщения
- 3 068
- Благодарностей
- 3 135
- Баллы
- 113
Спасибо за регулярку для e-mail ! Только попался на глаза e-mail (fkfshjfhjh-3@yandex.ru) с которым она не справилась( может можно ее доработать и под такой случай?
Код:
[\w\-]+@[\w\-]+\.\w+