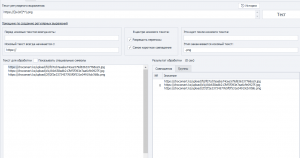
Берёшь Page.Dom . Копируешь его в Notepad++. Находишь в Notepad++ .jpg и рассматриваешь, что вокруг .jpg
Разглядывая строку, в которой ссылка, обнаруживаешь, что никаких https:// там нет. Причём обычное дело, что нет начала ссылки.
Видимо сайту не нужно https:// , чтобы ссылаться на самого себя.
Вот кусок строки с ссылкой:
title="Блок питания Thermaltake Smart RGB 700W (PS-SPR-0700NHSAWE-1)" src="/upload/2b/128x128/2bdf21519310e2d9dad1a7a75d6aac01_128x128.jpg" height="128" width="128">
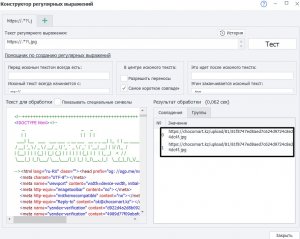
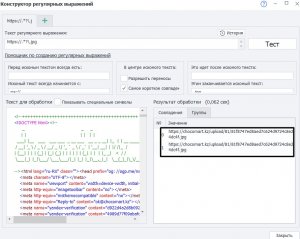
И далее смотришь на строку и делаешь регулярку:
Перед искомым текстом всегда есть: src="
Искомый текст всегда начинается с: /upload/
Этим заканчивается искомый текст: g ( Должна парсить и jpg и png, ей без разницы.)
Это идёт после искомого текста: " height (Возможно лучше изменить мою регулярку, оставив просто кавычку с пробелом.)
У меня получилась вот такая регулярка: (?<=src=")/upload/[\w\W]*?g(?="\ height)
Hа всякий случай с переносами, хоть их и не будет.
А что sergodjan66 говорит, вообще всё делай, он никогда не ошибается: попробуй парсить в список и удаляй дубли.




 135,6 КБ Просмотры: 75
135,6 КБ Просмотры: 75