doc
Client
- Регистрация
- 30.03.2012
- Сообщения
- 8 685
- Реакции
- 4 652
- Баллы
- 113
Не работает
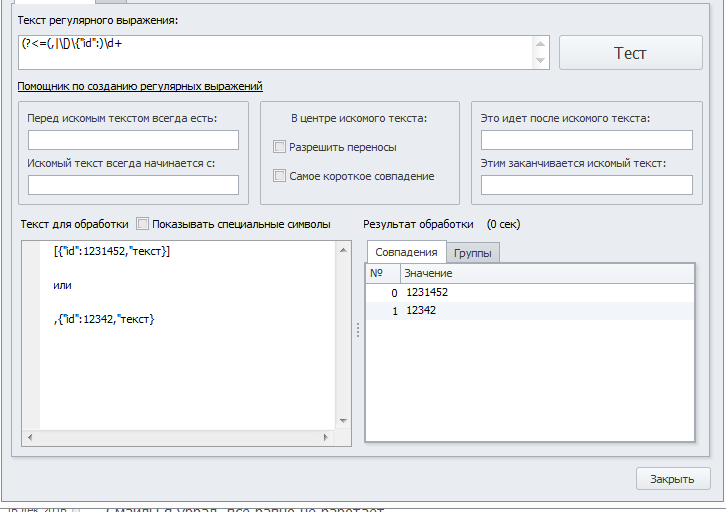
Вот пример конструкции:
Код:[{"id":1231452,"текст}] или ,{"id":12342,"текст}

Код:
(?<=(,|\[)\{"id":)\d+Не работает
Вот пример конструкции:
Код:[{"id":1231452,"текст}] или ,{"id":12342,"текст}
(?<=(,|\[)\{"id":)\d+Смайлы я убрал, все равно не работает.не посмотрел, что смайлы повылазилиКод:(?<=(,|\[)\{"id":)\d+
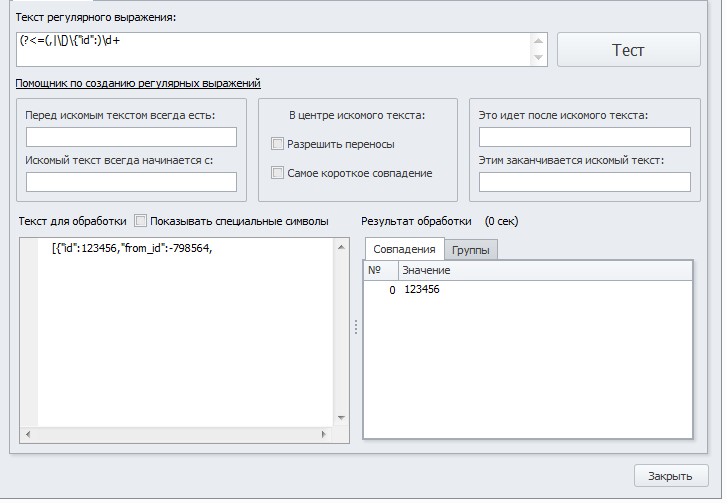
Вот ещё что неправильно собирается.
В тексте есть конструкции вида:
Мне нужно собрать только в данному случае : 123456Код:[{"id":123456,"from_id":-798564,
А регулярка, почему то и from_id тоже цепляет
Сори.
хватит в самом деле
Как вытащить из текста
7773PaРсEDIМG7773count\d+http://zennolab.com/discussion/threads/vopros-po-bezopasnosti-v-vk.35698/#post-266760подскажите пожалуйста регулярку
спасибо) вот сам сляпал в тестере регулярок (?<=\+370).*(?=\d\d) - в тестере работает как надо))) вместо +370 остается только переменную поставить )
но этот вариант идеален! спасибо)
Отрабатывает все , но почему то ошибку выдаетC#:var list = project.Lists["Rezult"]; list.Clear(); var response = project.Variables["response"].Value; var regex = new Regex(@".+.*"); regex.Matches(response).Cast<Match>().ToList().ForEach(m=>list.Add(m.Value.Split(':')[0] + ":" + m.Value.Split(':')[1]));
Посмотреть вложение 18945

потому что берётся первый обратный слеш как начало регулярки, далее ближайшее .jpg Так что берёт всё верно. Если нужно имя файла взять, то это ([^\\]+$)Почему самое короткое совпадение не выделяет именно самый короткий фрагмент, а берёт самый большой?
Посмотреть вложение 20094
Почему самое короткое совпадение не выделяет именно самый короткий фрагмент, а берёт самый большой?
а замена всех значений по регулярке это не цикл думаешь?)Друзья, подскажите, пожалуйста, как сделать замену:
Все слова, состоящие только из заглавных букв, заменить на эти же слова из строчных букв.
Пример:
"Есть разные СЛОВА. Бывают и ТАКИЕ. А также просто текст обычный."
Вот нужно заменить:
СЛОВА ---> слова
ТАКИЕ ----> такие
P.S.: Можно конечно через костыль типа взятия по регулярке слова из заглавных букв и потом экшеном Tolower его заменить. И потом так в цикле. Но это как-то совсем нерационально получается.
Не проще взять весь текст целиком, перевести в нижний регистр экшеном ToLower и перезаписать? Или не все слова нужно заменять?P.S.: Можно конечно через костыль типа взятия по регулярке слова из заглавных букв и потом экшеном Tolower его заменить. И потом так в цикле. Но это как-то совсем нерационально получается.
Или не все слова нужно заменять?
Я имел ввиду, что может какие-то аббревиатуры не нужно переводить. В твоем случае, используй ToLower для всего текста и не парься, что те слова, который уже в нижнем регистре станут такими, просто весь текст станет в нижнем регистре.В этом-то и проблема )
Нужно не все слова заменять. А только те, которые состоят из заглавных букв.
Полагаю, предложение с большой буквы играет рольЯ имел ввиду, что может какие-то аббревиатуры не нужно переводить. В твоем случае, используй ToLower для всего текста и не парься, что те слова, который уже в нижнем регистре станут такими, просто весь текст станет в нижнем регистре.
Потому-что оно и есть самое короткое, для вашего примера можно использовать такой RegexПочему самое короткое совпадение не выделяет именно самый короткий фрагмент, а берёт самый большой?
Посмотреть вложение 20094
Почему самое короткое совпадение не выделяет именно самый короткий фрагмент, а берёт самый большой?
(?<=\\)[^\\]*?\.jpg1. Разделить " FootUmbrellaCarEye " на строки списка:Всем привет нуждаюсь в вашей помощи вопрос такой есть текст каторый находится в переменой текст такой " FootUmbrellaCarEye " в другой переменой стоит слово " Umbrella " как получить номер слова ? в данном тексте четыре слова все начинаются с заглавной буквы думаю что тут можно применить регулярки толика какую понятие не имеею буду признателен за помоши)
Foot
Umbrella
Car
Eye
Всем привет нуждаюсь в вашей помощи вопрос такой есть текст каторый находится в переменой текст такой " FootUmbrellaCarEye " в другой переменой стоит слово " Umbrella " как получить номер слова ? в данном тексте четыре слова все начинаются с заглавной буквы думаю что тут можно применить регулярки толика какую понятие не имеею буду признателен за помоши)
string str = project.Variables["Text"].Value;
string str2 = project.Variables["Text2"].Value;
MatchCollection mCol = Regex.Matches(str, @"[A-ZА-ЯЁ][a-zа-яё]+");
for (int i = 0; i < mCol.Count; i++)
if (str2 == mCol[i].Value)
return i;