



- Регистрация
- 04.10.2011
- Сообщения
- 1 056
- Благодарностей
- 720
- Баллы
- 113
Всем привет!
Это быстро настраиваемый парсер, который позволяет получать нужные данные с сайтов и передавать их на обработку в одну из более чем 30 ИИ-моделей через бесплатный API.
Теперь не нужно мучиться с regex и XPath - достаточно указать примерный HTML-блок (или даже всю страницу), и искусственный интеллект сам аккуратно выпарсит всё, что вам нужно.

Что можно спарсить?
- Описания товаров из интернет-магазинов (цены, описание, фото)
- Ссылки из поисковой выдачи
- Ключевые слова и теги из текста
- Телефоны, email и другая контактная инфа с сайтов
- Ссылки на файлы (документы, видео и т.д.) и их описания
- Отзывы и оценки с разных площадок
- Информацию о событиях — даты, места
- И вообще всё, что только сможете придумать — шаблон и ИИ подстроятся!
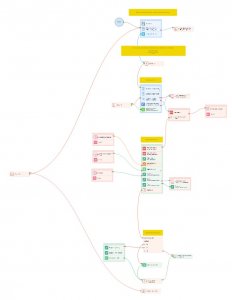
- Загрузка URL-адресов.
Шаблон последовательно обрабатывает каждый URL из указанного списка.
- Извлечение HTML-фрагментов.
С помощью заданных XPath-выражений шаблон выделяет одну или несколько нужных частей HTML-кода с страницы. Это может быть как конкретный элемент (например, блок с описанием товара), так и вся страница целиком — если вам так удобнее.
Желательно указывать только те фрагменты, где содержатся нужные данные (это ускоряет анализ и повышает точность).
- Передача в ИИ-модель.
Полученные HTML-фрагменты отправляются в выбранную ИИ-модель через бесплатный API с указанием, что нужно найти в коде (заголовки, ссылки, кнопки и т.д.) и в каком формате вывести результат.
- Анализ с помощью ИИ.
ИИ-модель анализирует содержимое в соответствии с параметрами, заданными в настройках. Разные модели показывают разную эффективность -одни справляются лучше с обработкой текстов, другие -с извлечением конкретных данных или сложных структур. Я часто использую модель DeepSeek-R1, которая отлично подходит для большинства задач парсинга.
Лимиты считаются отдельно для каждой модели, так что можно просто переключаться между ними и не бояться упереться в ограничения. Все подробности можно глянуть здесь. - Формирование структурированных данных.
На выходе вы получаете результат в том формате, который указали в шаблоне (например, JSON, CSV и др.).
- Сохранение результата.
Данные сохраняются туда, куда вы указали в настройках - файл, базу, папку. Всё это настраивается прямо в шаблоне.
Пример использования
- Скачайте и разархивируйте Newtonsoft.Json в папку:
Там где установлен Ваш ZP
Например:
C:\Program Files\ZennoLab\RU\ZennoPoster Pro V7\Progs\ExternalAssemblies - Создаём файл с URL-адресами, например:
Код:https://www.aliexpress.com/item/1005007662322947.html https://www.aliexpress.com/item/1005001234567890.html ... и так далее, по одному URL на строку
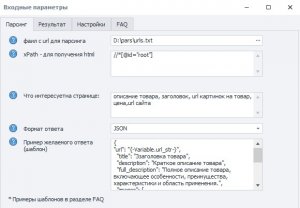
- Задаём XPath для основных блоков страницы:
Можно указывать несколько блоков - каждый с новой строкиКод://*[@class="pdp-info"] # блок с основной информацией о товаре; //div[@id="nav-description"] # блок с описанием товара.
Также можно взятьКод:/html # даже всю страницу; /html/body # или только тело; - Указываем, какие данные хотим получить со страницы — название, цену, ссылки на фото, описание и прочее.
- Выбираем формат результата:
Код:
JSON XML SQL CSV YAM TOML или строка с разделителем - Задаём шаблон ответа — то, как должны выглядеть данные после обработки. Примеры можно найти во вкладке FAQ в настройках.
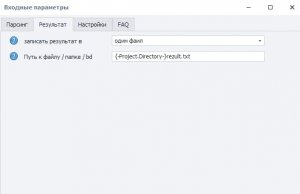
- На вкладке «Результат» выбираем, куда сохранять данные — например, в один файл.
Там же указываем путь к файлу, куда будет записан результат парсинга.
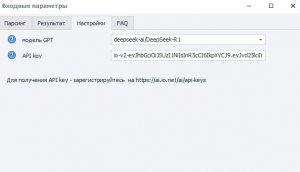
- На вкладке «Настройки» выбираем ИИ-модель и указываем свой API key — он универсальный и подходит для всех моделей.
Получить API ключ можно после регистрации на сайте.
Вот и всё - запускаем шаблон, он последовательно пройдётся по всем URL из списка, выпарсит нужные данные и сохранит их в указанном формате.
Заключение
Этот универсальный парсер с поддержкой бесплатного API и более 30 ИИ-моделей - мощный инструмент для автоматизации сбора данных с веб-ресурсов. Он подходит как для новичков, так и для профессионалов, экономит время и позволяет быстро получать структурированную и точную информацию с любых сайтов.
Чуть не забыл
 :-)")
Как получить бесплатный API key для всех 30 моделий ИИ ?
- Регистрируйтесь на io.net через акк - google или x.com или Apple
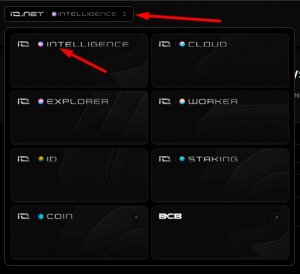
НЕ надо подтверждать телефон, или закреплять банковскую карту! - В верхнем правом углу жмем INTELLIGENCE
- Переходим в раздел API Keys
- Ищем кнопку Create New Secret Key
- Заполняем форму
- Копируем и сохраняем в надежное место API key
P.S. Если у вас есть идеи, где ещё можно применить этот универсальный парсер — пишите, обсудим!
Вложения
-
27,5 КБ Просмотры: 266
-
261,8 КБ Просмотры: 195
Последнее редактирование модератором:

 8-)")