



- Регистрация
- 28.10.2019
- Сообщения
- 406
- Благодарностей
- 253
- Баллы
- 63
В 2020-м редко встретишь SEO-шника и/или МаниМейкера который хоть как-то не пробовал себя в рынке информационных сайтов.
Я не есть исключение. Свой путь начал в далеком 2014-м с собственного инфосайта аля “блог” (который позже продал), и с тех пор информационный кластер так или иначе всегда сопровождает мой путь. Были на этом отрезке как мелкие одностраничные ГСы, так и крупные клиентские медиа с контент-планом >300 публикаций в месяц и трафом в районе 2М уников из органики.
И всякий раз (прям в 100% случаев) мешает одна маленькая, но очень весомая мелочь — экономика затеи.
Например так сегодня выглядит экономика одного “белого” инфосайта который я запускал года эдак три назад:

Вроде и неплохие показатели, но -1.7М/руб за три года работы... С одной стороны — это бесценный опыт, с другой — это фиаско, братан!
Не исключено что на этих попытках мой путь манимейкера информационного трафа закончился бы, если бы год назад я не купил ЗенноПостер.
Сразу стоит отметить что методологию, описанную в этом посте строил “под себя”, не для конкурса и не для продажи (во всяком случае пока). Поэтому в ней нет вариативности, процесс не кастомизируется — строгая линейка свода методов и конкретных сервисов. Это работает как процесс, но если убрать любую переменную — всё сломается.
Где деньги?
Процесс создания информационных сайтов выглядит примерно так:
И где-то в вышеперечисленном списке находится ключевая статья расходов, сократив которую можно очень заметно вырастить экономику.
Экономим на разработке
Статейный рынок сегодня делится на несколько типовых групп:
Блоги коммерческих ресурсов (интернет-магазины, услуги, продукты) — это немного другая история. Такие проекты в большинстве своем также не окупаемы сами по себе, но благополучно существуют за счет коммерческого ресурса. При этом коммерческий ресурс (услуга/продукт) за счет информационного трафика знакомит аудиторию со своими товарами/услугами, повышает лояльность к бренду и бонусом собирает контакты аудитории которые позже монетизирует через иные каналы. Взаимовыгодная синергия.
Трендовым же направлением манимейкинга информационного трафика сегодня являются малостраничники. Такие сайты требуют небольших инвестиций, делаются сравнительно просто, окупаются сравнительно быстро.
Текущая статья (и инсайты которые Вы из неё достанете) применима ко всем трем типам информационных сайтов, но максимально таргетированна именно под рынок малостраничников.
Копипаст сайта ресурсами поддержки хостинга
Преобладающее большинство вебов в инфо-сайтах по-прежнему предпочитают старый добрый Wordpress. Типа “взял шаблон → натянул интент → профит”.
И в этом месте на практике возможно немного забустить процесс.
Предположим у вас есть сетка из 10 сайтов. Каждый сайт делал разработчик, что обходилось Вам условные $ 200. Соответственно (по логике) сделать 10 новых сайтов обойдется Вам те же $ 2000 что и предыдущие.
Но (!) эту статью расходов можно заметно сократить за счет смекалки в комплекте с ЗенноПостером.
Я храню свои сайты на Бегете (рефка), где просто фантастическая служба поддержки. И каждый раз решив создавать новый сайт я выбираю какой старый буду копипастить. И под это дело есть отдельный шаблон в настройках которого задаются.
Шаблон 1. Копипаст сайта ресурсами поддержки хостинга.zp прикладываю.
Выполняется через веб, настройки интуитивно-понятны:
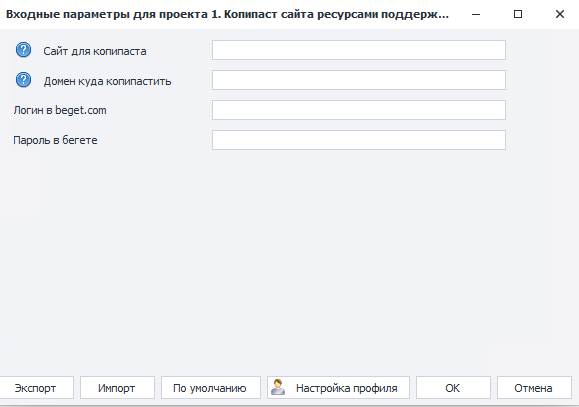
На выходе запрос в службу поддержки выглядит примерно так:
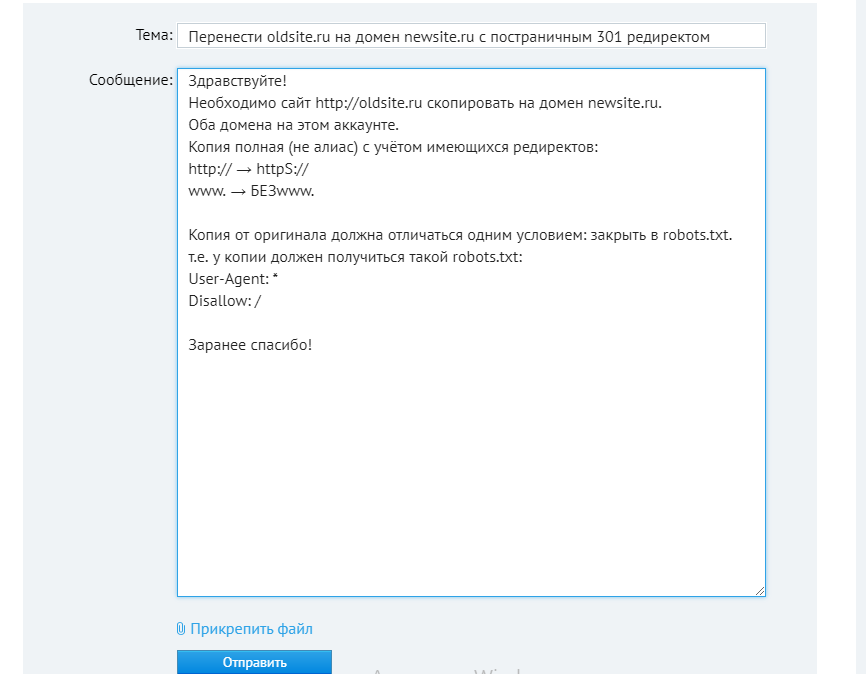
Саппорт Бегета копирует от 1 до 3 дней. Уведомление о копии получите по почте.
Скопированный сайт намеренно закрывается в robots.txt — чтобы копия не попала в индекс. После копирования делаются легкие манипуляции с базой данных: удаление старых записей/страниц/комментариев (под это тоже подготовлю шаблон ЗенноПостера, пока в очереди — поэтому руками), после чего небольшая униканизация шаблона (стили подкрутить, фон поменять, текст в футере, шапку чуть иначе).
На всё про всё в сумме уходит от 30 минут до пары часов (зависит от вдохновения). Вместо $ 2000 получается < 15 часов на 10 новых сайтов.
Важно: оба домена должны быть добавлены в один аккаунт Бегета + у обоих должен быть установлен SSL-сертификат (у Бегета он бесплатен, но сделать нужно).
Экономим на семантике
Какое-то время мы в рамках команды на работу семантиков под информационные сайты тратили целое состояние. Редкие ретроспективы перерасчета в одно ТЗ иногда приводили в ужас, но найти решение как системно пофиксить не получалось. Да и в то время я был на роли ПМа, на ставке, экономика вроде как входила в фокус должностных обязанностей, но до знакомства с ЗенноПостером методологии явно не хватало (а может еще и мотивации).
Когда начал работать над своими сайтами за свои деньги — фокус сильно сместился в сторону экономики.
Правда тоже не сразу: сначала я слил в минус 204 тыс. рублей на разные попытки, после взял паузу, и примерно пол года назад вернулся с новой попыткой — на этот раз успешной.
Первый эксперимент с семантикой прошел так: взял нишу в которой хотел делать сайт, закопался на день… и сделал семантики на 50+ страниц. Криво, не так глубоко как требовали от специально-обученных людей, #наколенке. И к большому моему удивлению KPI-SEO у этих статей на долгосроке в среднем вышло х4 в сравнении с рабочими проектами.
Совпадение или нет сложно однозначно сказать, но хороший повод задуматься…
Постепенно, шаг за шагом, экспериментируя с сервисами и подходами я изобрел некий условно-универсальный путь, который сегодня, благодаря ЗенноПостеру, позволяет тратить на семантику к ТЗ одной статьи в среднем минут 10 времени. Этого достаточно чтобы собрать семантику основных конкурентов в кучу, кластеризовать с помощью софта KeyAssort (ссылка) и разложить на интенты по таблице. Грубо, с точки зрения классического подхода к SEO — непрофессионально. Но работает!!!
Перед тем как запускать шаблон нужно собрать такую табличку. Обязательные условия для заполнения: интенты должны быть синхронизированны с сервисом КейСо. Если интента нет в точном вхождении в базе KeySo — ничего не выйдет (на такой случай в логике предусмотрен пропуск строки с уведомлением в телеграм).
Всю остальную магию делает ЗенноПостер
Схема выглядит примерно так:
Порядок действия бота на старте:
У каждого ТЗмейкера обязательно должны быть:
а) папка в google.drive — в эту папку будут попадать все созданные ТЗмейкером Технические Задания для копирайтеров. Можно общую папку, можно каждому ТЗмейкеру отдельную — на общую логику никак не повлияет.
б) таблица конкретно этого ТЗмейкера — у каждого ТЗмейкера своя таблица (шаблон таблицы).
в) отдельная папка в бирже Пузата с открытыми этому ТЗмейкеру доступами.
г) id_bot и id_chat для телеграмма — в бонусе к статье есть инструкция как это получить. Делайте отдельный чат с каждым сотрудником (я делаю всегда общий чат, где нахожусь я, ТЗмейкер и бот), далее бот пинает егокогда боту становится скучно когда появляются новые задачи, когда требуется наполнить источниками, и, на всякий случай, уведомляет когда ТЗ принято и отправлено в контент.
Для удобства всех ТЗмейкеров проекта я добавляю в отдельную таблицу внутри папки этого проекта (шаблон таблицы перечисления ТЗмейкеров), в которой у каждого ТЗмейкера есть своя строка. Ссылку именно на эту таблицу нужно добавить в настройки проекта.
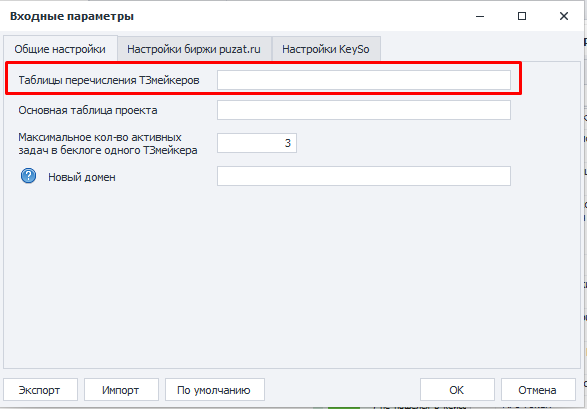
Экономим на контент-менеджменте
После того как ТЗ готово, оно попадает в общую табличку проекта, откуда заливается в биржу etxt.ru (рефка).
Данный этап требует небольшой дополнительной подготовки: Вы должны создать шаблон внутри биржи etxt.ru для конкретного проекта и указать его в настройках шаблона ЗенноПостера. Что будет в этом шаблоне — решать только Вам.Сахар и соль добавляются по вкусу Любые детали по Вашим потребностям и предпочтениям.
Обязательно должно быть: в конце описания к шаблону внутри биржи должно быть ТЗ по конкретному тексту:
Пример на скрине:
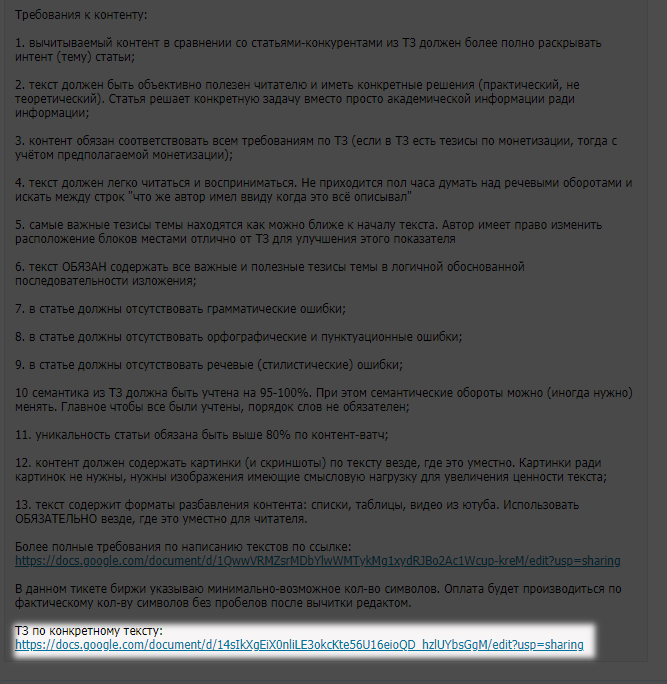
Бот будет искать этот текст и добавлять к нему ссылку на конкретное ТЗ (пример ТЗ). Собственно это и будет основа-основ.
Выбор автора
В шаблон «4. Выбор автора в бирже etxt.ru» вшита система скоринга: бот изучает все заявки, сравнивает ряд характеристик, рассчитывает условный “траст” автора и выбирает автора статьи на основе этого траста (стоит отметить — не в 100% случаев это получается удачно).
При этом в шаблоне выбора автора есть настройка с минимальным порогом траста. Рекомендую ставить её не ниже 30 баллов.
При этом если Вы работаете с нишами банков, страхования, бухгалтерии, юристов или финансов — планку имеет смысл поднять до минимум 50 единиц рейтинга. В случае если из текущих заявок нет автора у которого траст выше минимальной планки — все заявки удаляются и задача переразмещается на бирже (с АПом дедлайна).
Авторы из белого списка внутри биржи (если у вас такие есть и они подали заявку) — рассматриваются приоритетно. К ним требования траста не предъявляются (они ведь уже в белом списке, значит проверенные Вами).
Работа редактора
После того как текст написан и задача на бирже etxt.ru сдана на проверку — бот заливает текст в Гугл Диск и отправляет редактору на вычитывание. Редактор вычитывает/правит/возвращает на доработку с комментами непосредственно в Гугл Документе.
Отсюда рекомендация: необходимо зашить в шаблон ТЗ на бирже требование текст возвращать только в формате Microsoft Word с картинками внутри дока (через функционал “вставка → изображение”). И сразу будьте готовы к тому что большая часть авторов невнимательно читают ТЗ и первый раз будут картинки присылать в отдельном архиве
Мой редактор всегда возвращает тексты таким невнимательным авторам на доработку.
После того как автор сдал текст → текст добавляется в таблицу редактора (шаблон таблицы редактора) и дополнительно бот уведомляет редактора в телеграмме о необходимости вычитать.
Редактор вычитывает и решает дальнейшую судьбу текста (смотрите примечания в первой строке таблицы редактора, там все пояснения).
Финальная цель: довести текст до публикации.
Но не все тексты доходят до публикации, часть идет в отказ.
Поэтому здесь же зашит функционал отказа от статьи через саппорт биржи etxt.ru.
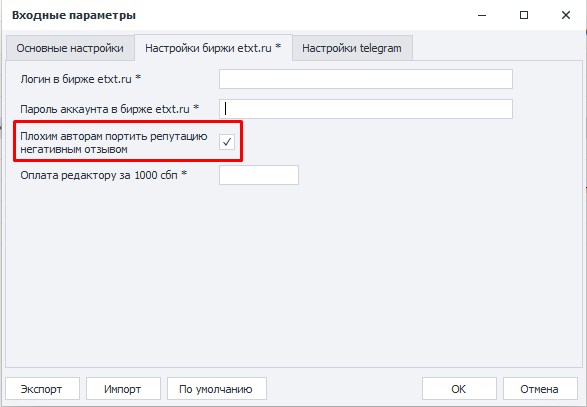
Каждому тексту редактор ставит субъективные оценки. Низкие оценки отправляют автора в черный список (ЧС) — автор больше не может подавать заявки на Ваши работы. И если Вы решите подпортить плохому автору карму: текст редактора, который бот отправляет в арбитраж на снятие автора, также может по Вашему желаю пойти в отрицательный отзыв неугодному автору. Для этого нужно соответствующий чекбокс отметить в настройках проекта «6. Проверка таблицы редактора»:
Высокие оценки наоборот — добавляют автора в БС и его заявки рассматриваются всегда вне очереди. Где-то в задачнике есть задача ранжировать стоимость доплаты того или иного автора из БС в соответствии с этими оценками и трафом который приносит их статьи (поощрять бонусами тех авторов с которыми работаем долго и усердно и чей труд приносит много-много трафа и $), может быть когда-нибудь дойду.
Логики в данном куске инфраструктуры много, шаблоны сложные (в моем исполнении еще и сложночитаемые, заранее отдельный сорян за это адресован тем усидчивым форумчанам, которые решатся разобраться что к чему). Но набравшись терпения Вы обязательно сможете понять как это работает, возможно кастомизировать шаблон под себя.
На сегодня работа с биржей etxt — это самое слабое звено инфраструктуры: всё построено на браузере в старой версии интерфейса биржи (недавно они выкатили редизайн личного кабинета, но пока оставили возможность работать на старом интерфейсе). В задачнике висит большая задача по рефакторингу логики с переводом на API (насколько это возможно, при поверхностном изучении возможностей API сложилось ощущение что не всю логику удастся перевести на post/get запросы).
К тому же здесь тексты заливаются в облако Google Диска, и это еще одно узкое место в котором иногда появляются баги (например где-то меняется название класса в верстке и всё ломается).
Неочевидный нюанс: в каждом возврате/отказе редактору необходимо описывать в столбец I таблицы редактора причину возврата/отказа. При этом описание не должно быть более 924 символов без пробелов — иначе придется вручную обращаться в саппорт биржи. Нюанс неочевидный, выплыл спустя несколько месяцев работы инфраструктуры когда редактор при отказе расписал для арбитража биржи портянку недостатков текстов с примерами.
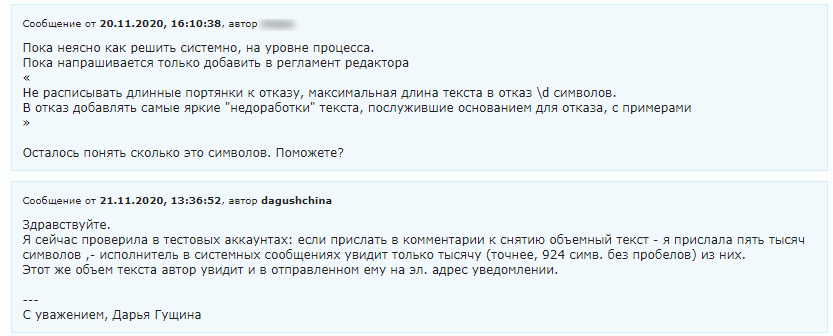
Сейчас в столбце I таблицы редактора зашита формула, которая подсветит ячейку красным цветом в случае если кол-во символов превысит максимально-дозволенное.
После того как редактор вычитал и принял статью — контент оплачивается автору в полном объеме (автоматически происходит доплата) и статья публикуется на сайте. Здесь же происходит расчет оплаты работы редактору: у меня редактор работает с условием “за килознак текста”, соответственно расчет вычисляется из оплаты стоимости килознака готового текста (бракованные не считаем), которая задается в настройках шаблона «6. Проверка таблицы редактора».
При публикации на сайте шаблон сравнительно нехитрый: контент копируется с гуглодока → вставляется в сервис https://html-online.com/editor/ → копируется html (со всеми ссылками, таблицами, списками и даже картинками) → по API отправляется в wordpress.
На этом шаге самое слабое звено = сервис https://html-online.com/editor/. К сожалению здесь бывают баги. Пытался эту итерацию перевести на post/get запросы, не хватило компетенции. Так что если кто-то из Вас, уважаемые ЗенноМены, вызовется помочь перевести этот кусок логики на post/get ради общего блага (или за $) — буду очень признателен!
На ком не экономим
Пока незаменимыми людьми в подходе есть ТЗмейкеры, редакторы и копирайтеры. Последних вроде как в перспективе может потеснить технология GPT-3 (в частности для рунета Сбер вызвался оставить еще и копирайтеров без работы, новость на vc.ru).
Важные нюансы которые нужно помнить прежде чем начать разбираться
Подводя итоги
Преимущества метода:

В планах на ближайшее будущее есть несколько дополнений:
а) тянуть параметры текста (уникальность, тошноту, грамотность) по API из сервисов и добавлять их в таблицу редактора после приемки каждого текста;
б) после выкатки всех текстов делать автоматическую перелинковку отталкиваясь от семанта;
в) монетизировать тексты сразу зашивая кнопки/рекламные коды в контент при добавлении;
г) ну и самое вкусное — избавиться от копирайтеров в пользу сервиса https://sbercloud.ru/ru/warp/gpt-3.
Я не есть исключение. Свой путь начал в далеком 2014-м с собственного инфосайта аля “блог” (который позже продал), и с тех пор информационный кластер так или иначе всегда сопровождает мой путь. Были на этом отрезке как мелкие одностраничные ГСы, так и крупные клиентские медиа с контент-планом >300 публикаций в месяц и трафом в районе 2М уников из органики.
И всякий раз (прям в 100% случаев) мешает одна маленькая, но очень весомая мелочь — экономика затеи.
Например так сегодня выглядит экономика одного “белого” инфосайта который я запускал года эдак три назад:
Вроде и неплохие показатели, но -1.7М/руб за три года работы... С одной стороны — это бесценный опыт, с другой — это фиаско, братан!
Не исключено что на этих попытках мой путь манимейкера информационного трафа закончился бы, если бы год назад я не купил ЗенноПостер.
Сразу стоит отметить что методологию, описанную в этом посте строил “под себя”, не для конкурса и не для продажи (во всяком случае пока). Поэтому в ней нет вариативности, процесс не кастомизируется — строгая линейка свода методов и конкретных сервисов. Это работает как процесс, но если убрать любую переменную — всё сломается.
Где деньги?
Процесс создания информационных сайтов выглядит примерно так:
- Разработчик делает сайт.
- Семантик собирает/чистит/кластеризирует семантику.
- ТЗмейкер делает ТЗ для копирайтеров по семантике.
- Контент-менеджер находит копирайтеров.
- Редактор вычитывает, правит.
- Главный редактор утверждает.
- Контент-менеджер публикует.
- Монетизатор монетизирует.
И где-то в вышеперечисленном списке находится ключевая статья расходов, сократив которую можно очень заметно вырастить экономику.
Экономим на разработке
Статейный рынок сегодня делится на несколько типовых групп:
- белые инфосайты (с уклоном в сторону медиа);
- блоги коммерческих ресурсов;
- малостраничники.
Блоги коммерческих ресурсов (интернет-магазины, услуги, продукты) — это немного другая история. Такие проекты в большинстве своем также не окупаемы сами по себе, но благополучно существуют за счет коммерческого ресурса. При этом коммерческий ресурс (услуга/продукт) за счет информационного трафика знакомит аудиторию со своими товарами/услугами, повышает лояльность к бренду и бонусом собирает контакты аудитории которые позже монетизирует через иные каналы. Взаимовыгодная синергия.
Трендовым же направлением манимейкинга информационного трафика сегодня являются малостраничники. Такие сайты требуют небольших инвестиций, делаются сравнительно просто, окупаются сравнительно быстро.
Текущая статья (и инсайты которые Вы из неё достанете) применима ко всем трем типам информационных сайтов, но максимально таргетированна именно под рынок малостраничников.
Копипаст сайта ресурсами поддержки хостинга
Преобладающее большинство вебов в инфо-сайтах по-прежнему предпочитают старый добрый Wordpress. Типа “взял шаблон → натянул интент → профит”.
И в этом месте на практике возможно немного забустить процесс.
Предположим у вас есть сетка из 10 сайтов. Каждый сайт делал разработчик, что обходилось Вам условные $ 200. Соответственно (по логике) сделать 10 новых сайтов обойдется Вам те же $ 2000 что и предыдущие.
Но (!) эту статью расходов можно заметно сократить за счет смекалки в комплекте с ЗенноПостером.
Я храню свои сайты на Бегете (рефка), где просто фантастическая служба поддержки. И каждый раз решив создавать новый сайт я выбираю какой старый буду копипастить. И под это дело есть отдельный шаблон в настройках которого задаются.
Шаблон 1. Копипаст сайта ресурсами поддержки хостинга.zp прикладываю.
Выполняется через веб, настройки интуитивно-понятны:
На выходе запрос в службу поддержки выглядит примерно так:
Саппорт Бегета копирует от 1 до 3 дней. Уведомление о копии получите по почте.
Скопированный сайт намеренно закрывается в robots.txt — чтобы копия не попала в индекс. После копирования делаются легкие манипуляции с базой данных: удаление старых записей/страниц/комментариев (под это тоже подготовлю шаблон ЗенноПостера, пока в очереди — поэтому руками), после чего небольшая униканизация шаблона (стили подкрутить, фон поменять, текст в футере, шапку чуть иначе).
На всё про всё в сумме уходит от 30 минут до пары часов (зависит от вдохновения). Вместо $ 2000 получается < 15 часов на 10 новых сайтов.
Важно: оба домена должны быть добавлены в один аккаунт Бегета + у обоих должен быть установлен SSL-сертификат (у Бегета он бесплатен, но сделать нужно).
Экономим на семантике
Какое-то время мы в рамках команды на работу семантиков под информационные сайты тратили целое состояние. Редкие ретроспективы перерасчета в одно ТЗ иногда приводили в ужас, но найти решение как системно пофиксить не получалось. Да и в то время я был на роли ПМа, на ставке, экономика вроде как входила в фокус должностных обязанностей, но до знакомства с ЗенноПостером методологии явно не хватало (а может еще и мотивации).
Когда начал работать над своими сайтами за свои деньги — фокус сильно сместился в сторону экономики.
Правда тоже не сразу: сначала я слил в минус 204 тыс. рублей на разные попытки, после взял паузу, и примерно пол года назад вернулся с новой попыткой — на этот раз успешной.
Первый эксперимент с семантикой прошел так: взял нишу в которой хотел делать сайт, закопался на день… и сделал семантики на 50+ страниц. Криво, не так глубоко как требовали от специально-обученных людей, #наколенке. И к большому моему удивлению KPI-SEO у этих статей на долгосроке в среднем вышло х4 в сравнении с рабочими проектами.
Совпадение или нет сложно однозначно сказать, но хороший повод задуматься…
Постепенно, шаг за шагом, экспериментируя с сервисами и подходами я изобрел некий условно-универсальный путь, который сегодня, благодаря ЗенноПостеру, позволяет тратить на семантику к ТЗ одной статьи в среднем минут 10 времени. Этого достаточно чтобы собрать семантику основных конкурентов в кучу, кластеризовать с помощью софта KeyAssort (ссылка) и разложить на интенты по таблице. Грубо, с точки зрения классического подхода к SEO — непрофессионально. Но работает!!!
Перед тем как запускать шаблон нужно собрать такую табличку. Обязательные условия для заполнения: интенты должны быть синхронизированны с сервисом КейСо. Если интента нет в точном вхождении в базе KeySo — ничего не выйдет (на такой случай в логике предусмотрен пропуск строки с уведомлением в телеграм).
Всю остальную магию делает ЗенноПостер
Схема выглядит примерно так:
*похожий семант = “похожая” семантика по алгоритмам КейСо. Иными словами — это схожесть по выдаче. Не знаю в деталях какими алгоритмами это считается, но на практике достаточно удобная фича: в отчет попадают реально похожие фразы. Я не стал заморачиваться с порогом — и взял первые 100 запросов. Для того чтобы сделать проработанную детализированную ТЗ этого вполне достаточно.Зенно забирает интент из таблицы→ по API стучится в КейСо (рефка) и собирает *похожий семант → выбирает свободного ТЗмейкера → создает тикет в бирже https://puzat.ru/tz/ → ТЗмейкер делает структуру и учитывает основные ключи → копирайтер пишет текст → редактор вычитывает → ЗенноПостер публикует
Порядок действия бота на старте:
- Забирает интент из таблицы — подробно расписывать этот шаг не буду. Бот обращается к гугл таблице и забирает интент из столбца С вышеприведенного шаблона.
- По API стучится в КейСо и собирает похожую семантику — API у Кейсо достаточно продвинутое (документация).
Поскольку в бирже Пузата (из пункта 4 текущего списка) максимально-возможное кол-во ключей = 100, полученный из КейСо список сортирую по убыванию *“похожести” и беру первые 100 ключей.
P.S. если в финальном списке меньше 100 ключей → прорабатываю по-аналогии последовательно каждый ключ из списка и собираю похожие запросы пока не соберется 100 ключей для биржи.
Таким образом в дальнейшую работу всегда уходит ровно 100 ключей. Это позволяет не терять основные интенты внутри маркера, и не тратиться при этом на дорогостоящую работу специально-обученных семантиков (аля магия). - Выбирает свободного ТЗмейкера — на этом шаге в какой-то степени тоже зашита фича их практики. ТЗмейкеры у меня не в штате, все проэктно, с оплатой за одно ТЗ. И однажды я столкнулся с проблемой: ТЗмейкер набрал задач, но по каким-то причинам не делал их. На выходе получилось узкое горлышко в производственном конвейере. С этого опыта я вынес инсайт: нужно несколько ТЗмейкеров и процесс который не позволит собираться узкому горлышку в этом месте. Собственно так и сделал: сейчас ТЗмейкеров несколько + есть настройка максимального кол-ва активных задач на каждого.
Число задается опционально. Логика проверяет сколько активных задач в бэклоге каждого ТЗмейкера, и если их меньше чем указанное в настройках проекта число — зенка добавляет в таблицу задачу на создание ТЗ. - Создает тикет в бирже puzat.ru/tz — бот создает тикет и дальше работа ТЗмейкера. Пример инструкции для ТЗмейкера
Этот этап разбит на три последовательных подэтапа:
4.1. ТЗмейкер прорабатывает структуру.
4.2. ПМ проверяет (или делает вид что проверяет, на практике я проверяю одну из 10 работ, рандомно).
4.3. ТЗмейкер наполняет источниками.

У каждого ТЗмейкера обязательно должны быть:
а) папка в google.drive — в эту папку будут попадать все созданные ТЗмейкером Технические Задания для копирайтеров. Можно общую папку, можно каждому ТЗмейкеру отдельную — на общую логику никак не повлияет.
б) таблица конкретно этого ТЗмейкера — у каждого ТЗмейкера своя таблица (шаблон таблицы).
в) отдельная папка в бирже Пузата с открытыми этому ТЗмейкеру доступами.
г) id_bot и id_chat для телеграмма — в бонусе к статье есть инструкция как это получить. Делайте отдельный чат с каждым сотрудником (я делаю всегда общий чат, где нахожусь я, ТЗмейкер и бот), далее бот пинает его
Для удобства всех ТЗмейкеров проекта я добавляю в отдельную таблицу внутри папки этого проекта (шаблон таблицы перечисления ТЗмейкеров), в которой у каждого ТЗмейкера есть своя строка. Ссылку именно на эту таблицу нужно добавить в настройки проекта.
Экономим на контент-менеджменте
После того как ТЗ готово, оно попадает в общую табличку проекта, откуда заливается в биржу etxt.ru (рефка).
Данный этап требует небольшой дополнительной подготовки: Вы должны создать шаблон внутри биржи etxt.ru для конкретного проекта и указать его в настройках шаблона ЗенноПостера. Что будет в этом шаблоне — решать только Вам.
Обязательно должно быть: в конце описания к шаблону внутри биржи должно быть ТЗ по конкретному тексту:
Пример на скрине:
Бот будет искать этот текст и добавлять к нему ссылку на конкретное ТЗ (пример ТЗ). Собственно это и будет основа-основ.
Выбор автора
В шаблон «4. Выбор автора в бирже etxt.ru» вшита система скоринга: бот изучает все заявки, сравнивает ряд характеристик, рассчитывает условный “траст” автора и выбирает автора статьи на основе этого траста (стоит отметить — не в 100% случаев это получается удачно).
При этом в шаблоне выбора автора есть настройка с минимальным порогом траста. Рекомендую ставить её не ниже 30 баллов.
При этом если Вы работаете с нишами банков, страхования, бухгалтерии, юристов или финансов — планку имеет смысл поднять до минимум 50 единиц рейтинга. В случае если из текущих заявок нет автора у которого траст выше минимальной планки — все заявки удаляются и задача переразмещается на бирже (с АПом дедлайна).
Авторы из белого списка внутри биржи (если у вас такие есть и они подали заявку) — рассматриваются приоритетно. К ним требования траста не предъявляются (они ведь уже в белом списке, значит проверенные Вами).
Работа редактора
После того как текст написан и задача на бирже etxt.ru сдана на проверку — бот заливает текст в Гугл Диск и отправляет редактору на вычитывание. Редактор вычитывает/правит/возвращает на доработку с комментами непосредственно в Гугл Документе.
Отсюда рекомендация: необходимо зашить в шаблон ТЗ на бирже требование текст возвращать только в формате Microsoft Word с картинками внутри дока (через функционал “вставка → изображение”). И сразу будьте готовы к тому что большая часть авторов невнимательно читают ТЗ и первый раз будут картинки присылать в отдельном архиве
Мой редактор всегда возвращает тексты таким невнимательным авторам на доработку.
После того как автор сдал текст → текст добавляется в таблицу редактора (шаблон таблицы редактора) и дополнительно бот уведомляет редактора в телеграмме о необходимости вычитать.
Редактор вычитывает и решает дальнейшую судьбу текста (смотрите примечания в первой строке таблицы редактора, там все пояснения).
Финальная цель: довести текст до публикации.
Но не все тексты доходят до публикации, часть идет в отказ.
Поэтому здесь же зашит функционал отказа от статьи через саппорт биржи etxt.ru.
Каждому тексту редактор ставит субъективные оценки. Низкие оценки отправляют автора в черный список (ЧС) — автор больше не может подавать заявки на Ваши работы. И если Вы решите подпортить плохому автору карму: текст редактора, который бот отправляет в арбитраж на снятие автора, также может по Вашему желаю пойти в отрицательный отзыв неугодному автору. Для этого нужно соответствующий чекбокс отметить в настройках проекта «6. Проверка таблицы редактора»:

Высокие оценки наоборот — добавляют автора в БС и его заявки рассматриваются всегда вне очереди. Где-то в задачнике есть задача ранжировать стоимость доплаты того или иного автора из БС в соответствии с этими оценками и трафом который приносит их статьи (поощрять бонусами тех авторов с которыми работаем долго и усердно и чей труд приносит много-много трафа и $), может быть когда-нибудь дойду.
Логики в данном куске инфраструктуры много, шаблоны сложные (в моем исполнении еще и сложночитаемые, заранее отдельный сорян за это адресован тем усидчивым форумчанам, которые решатся разобраться что к чему). Но набравшись терпения Вы обязательно сможете понять как это работает, возможно кастомизировать шаблон под себя.
На сегодня работа с биржей etxt — это самое слабое звено инфраструктуры: всё построено на браузере в старой версии интерфейса биржи (недавно они выкатили редизайн личного кабинета, но пока оставили возможность работать на старом интерфейсе). В задачнике висит большая задача по рефакторингу логики с переводом на API (насколько это возможно, при поверхностном изучении возможностей API сложилось ощущение что не всю логику удастся перевести на post/get запросы).
К тому же здесь тексты заливаются в облако Google Диска, и это еще одно узкое место в котором иногда появляются баги (например где-то меняется название класса в верстке и всё ломается).
Неочевидный нюанс: в каждом возврате/отказе редактору необходимо описывать в столбец I таблицы редактора причину возврата/отказа. При этом описание не должно быть более 924 символов без пробелов — иначе придется вручную обращаться в саппорт биржи. Нюанс неочевидный, выплыл спустя несколько месяцев работы инфраструктуры когда редактор при отказе расписал для арбитража биржи портянку недостатков текстов с примерами.
Сейчас в столбце I таблицы редактора зашита формула, которая подсветит ячейку красным цветом в случае если кол-во символов превысит максимально-дозволенное.
После того как редактор вычитал и принял статью — контент оплачивается автору в полном объеме (автоматически происходит доплата) и статья публикуется на сайте. Здесь же происходит расчет оплаты работы редактору: у меня редактор работает с условием “за килознак текста”, соответственно расчет вычисляется из оплаты стоимости килознака готового текста (бракованные не считаем), которая задается в настройках шаблона «6. Проверка таблицы редактора».
При публикации на сайте шаблон сравнительно нехитрый: контент копируется с гуглодока → вставляется в сервис https://html-online.com/editor/ → копируется html (со всеми ссылками, таблицами, списками и даже картинками) → по API отправляется в wordpress.
На этом шаге самое слабое звено = сервис https://html-online.com/editor/. К сожалению здесь бывают баги. Пытался эту итерацию перевести на post/get запросы, не хватило компетенции. Так что если кто-то из Вас, уважаемые ЗенноМены, вызовется помочь перевести этот кусок логики на post/get ради общего блага (или за $) — буду очень признателен!
На ком не экономим
Пока незаменимыми людьми в подходе есть ТЗмейкеры, редакторы и копирайтеры. Последних вроде как в перспективе может потеснить технология GPT-3 (в частности для рунета Сбер вызвался оставить еще и копирайтеров без работы, новость на vc.ru).
Важные нюансы которые нужно помнить прежде чем начать разбираться
- Описанная логика вся построена вокруг таблиц и доков в Google Drive. Часть из них можно перевести в exel и хранить локально (для этого нужно будет поковырять шаблоны), но все таблицы взаимодействия с другими людьми (ТЗмейкеры, редакторы, копирайтеры) рекомендую хранить в Гугл Диске (не представляю как без этого можно закостылить вышеописанную логику).
- Телеграмм не обязателен в текущей логике. Без него
торт получится без вишенкизадуманная логика будет неполноценной, но (при этом) если Вы поленитесь заморачиваться с созданием бота/чатов в телеграмме и будете работать по иной (привычной Вам) логике коммуникации с сотрудниками — ничего не сломается. - Часть шаблонов решает капчу. Нигде не делал опцию выбора сервиса (т.к. везде Рукапчей всё решаю (рефка)). Если нужно сменить сервис — нужно будет пройтись поиском решения капчи так:
и хардкорно внутри шаблона заменить модуль внутри всех экшнов. - Все настройки кроме настроек телеграмма во всех проектах являются обязательными. Без них не заведется.
- У таблиц-примеров (ссылки в тексте статьи) есть примечания в шапке.
Перед тем как приступать нужно обязательно их изучить, там подсказки что заполнится автоматически, а что нужно вписывать вручную (и кто это должен делать). - Во всех шаблонах зашита уведомлялка в телеграмм на случай поломки. Поэтому если Вы будете подключать логику уведомлений в телеграм не будет лишним у всех шаблонов активировать модуль BadEnd при прерывании проекта:
- Сортировка файлов на Гугл Диске в котором лежит вся инфраструктура должна быть всегда «по дате моих изменений» (иначе будут баги)
- Все обязательные настройки помечены звездочками.
Если хотя-бы одна обязательная настройка не заполнена — шаблон отработает по ошибке (с уведомлением в лог).



Подводя итоги
Преимущества метода:
- Экономика — собственно ради чего мы здесь и собрались. Если раньше на одну детализированную, проработанную страницу контента тратилось 2400-3500 р.(при разных условиях было по-разному), то с применением описанного выше метода мне удалось сократить производство до 800-1300 р. Правда это при условии цены контента чуть ниже рыночного (70 р. / килознак) — мало авторов которые доходят до БС и гонят объемы. Пару малостраничников собрал таким методом, но это не масштабируемо. Буду повышать в ближайшее время до 90-100 р.
- Человеческий фактор — даже самый не ленивый человек факапит. Боты, правда, пока тоже бывает фейлят, но всё-таки этот способ избавляет от человеческого фактора со всеми его недостатками [забыл(а), забил(а)].
- Масштабируемость — пока это скорее теоретичекое чем практическое преимущество. Инфраструктуру собирал постепенно, около полугода, параллельно с другими проектами. За это время есть два микросайта на 30-50 страниц. Экономика сошлась, поэтому дальше будет масштабирывание на котором определенно вылезет много других нюансов собранных из недостатков метода:
- Подход не вариативный — если у вас нет доступа к KeySo, бирже puzat.ru/tz, тексты пишутся не через etxt.ru, сайты не на Бегете или CMS не Wordpress — воспользоваться всей инфраструктурой не получится (но можно взять отдельные модули и работать с ними).
- На браузере — кроме того что инфраструктура получилась достаточно “увестита” и требует сравнительно немало ресурсов, есть еще и недостаток жесткой подвязки к браузеру. Стоит где-то поменяться верстке на странице — всё ломается.
- Визуализация — этот недостаток усиливается недостатком меня как разработчика: я пользуюсь ЗП ровно год (отметка “черная пятница”
 ) — и год назад был на уровне нуля, гуглил запросы вида "как установить зенопостер".
) — и год назад был на уровне нуля, гуглил запросы вида "как установить зенопостер".
Отсюда цель = научиться пользоваться Зенкой. Создание вышеописанной инфраструктуры — один из поводов разобраться что к чему.
В планах на ближайшее будущее есть несколько дополнений:
а) тянуть параметры текста (уникальность, тошноту, грамотность) по API из сервисов и добавлять их в таблицу редактора после приемки каждого текста;
б) после выкатки всех текстов делать автоматическую перелинковку отталкиваясь от семанта;
в) монетизировать тексты сразу зашивая кнопки/рекламные коды в контент при добавлении;
г) ну и самое вкусное — избавиться от копирайтеров в пользу сервиса https://sbercloud.ru/ru/warp/gpt-3.
Конечно сегодня существует масса всевозможных интеграций, task-трекеров, джир и много всякого-разного. Но несмотря на это коммуникация и напоминалки в старых добрых мессенджерах всё еще актуальны, и есть ощущение что так будет всегда.
Какое-то время часть напоминалок было у меня в ручном режиме, и это в целом норм, но немного несовременно. Истинное удовольствие приносит бот который пинает кого-то, напоминает кому-то о чем-то вместо тебя… правда изначально функционал интеграции был в другом — бот напоминал мне о чем-то по различным условиям. Но сегодня он интегрирован во все системы коммуникаций с внешним миром и вышеописанная метода была бы ущербной, если бы не интеграция с телеграммом.
Первое что нужно сделать — зарегать бота.
Для этого стучимся к @BotFatcher — команда /newbot позволит в интерактивном режиме создать бота и получить необходимый токен для работы с HTTP API:
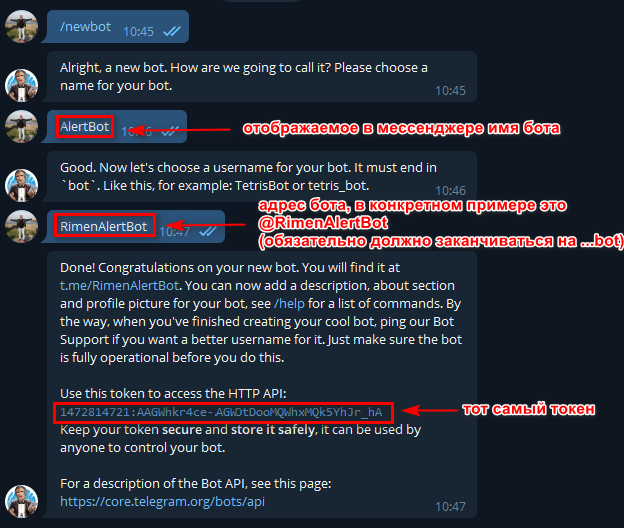
После создания бота нужно выйти с ним на связь — отправьте ему сообщение с произвольным текстом. В ответ... тишина. Беспокоиться не надо: бот маленький и тупой необученный, аля младенец. Это сообщение необходимо в дальнейшем для определения получателя.

После этого идем в браузер и открываем URL: https://api.telegram.org/bot{token}/getUpdates,
где
После этого получится ответ в вида:
(полученный формат не так удобен, человеко-читабельность придаю сервисом dirtymarkup.com)
где
Для того чтобы наладить алерты от бота с редактором / ТЗмейкером необходимо сделать общий чат, добавить туда бота, и по тому же сценарию найти {chatID} группового чата.
У меня под каждого редактора/ТЗмейкера отдельный чат. Все доступы нужные в табличках и настройках. Немного заморочено на этапе освоения, но достаточно удобно в использовании.
Какое-то время часть напоминалок было у меня в ручном режиме, и это в целом норм, но немного несовременно. Истинное удовольствие приносит бот который пинает кого-то, напоминает кому-то о чем-то вместо тебя… правда изначально функционал интеграции был в другом — бот напоминал мне о чем-то по различным условиям. Но сегодня он интегрирован во все системы коммуникаций с внешним миром и вышеописанная метода была бы ущербной, если бы не интеграция с телеграммом.
Первое что нужно сделать — зарегать бота.
Для этого стучимся к @BotFatcher — команда /newbot позволит в интерактивном режиме создать бота и получить необходимый токен для работы с HTTP API:

После создания бота нужно выйти с ним на связь — отправьте ему сообщение с произвольным текстом. В ответ... тишина. Беспокоиться не надо: бот маленький и тупой необученный, аля младенец. Это сообщение необходимо в дальнейшем для определения получателя.

После этого идем в браузер и открываем URL: https://api.telegram.org/bot{token}/getUpdates,
где
- {token} = полученный от BotFather токен (скрин выше)
После этого получится ответ в вида:
Код:
{
"ok": true,
"result": [{
"update_id": 184734484,
"message": {
"message_id": 3,
"from": {
"id": {chatID},
"is_bot": false,
"first_name": "{youName}",
"last_name": "{youFamily}",
"username": "{youNik}",
"language_code": "ru"
},
"chat": {
"id": {chatID},
"first_name": "{youName}",
"last_name": "{youFamily}",
"username": "{youNik}",
"type": "private"
},
"date": 1606985798,
"text": "hi"
}
}]
}где
- {chatID} = идентификатор чата который нужен.
Для того чтобы наладить алерты от бота с редактором / ТЗмейкером необходимо сделать общий чат, добавить туда бота, и по тому же сценарию найти {chatID} группового чата.
У меня под каждого редактора/ТЗмейкера отдельный чат. Все доступы нужные в табличках и настройках. Немного заморочено на этапе освоения, но достаточно удобно в использовании.
- Тема статьи
- SEO / PPC
- Номер конкурса статей
- Четырнадцатый конкурс статей
Вложения
-
749,8 КБ Просмотры: 187
Для запуска проектов требуется программа ZennoPoster или ZennoDroid.
Это основное приложение, предназначенное для выполнения автоматизированных шаблонов действий (ботов).
Подробнее...
Для того чтобы запустить шаблон, откройте нужную программу. Нажмите кнопку «Добавить», и выберите файл проекта, который хотите запустить.
Подробнее о том, где и как выполняется проект.
Последнее редактирование:

 При грамотном подходе, если сделать их не заметными и т.п., может добавить трафика от любителей воровать контент с сайтов.
При грамотном подходе, если сделать их не заметными и т.п., может добавить трафика от любителей воровать контент с сайтов. :-)")


 Или народ начнет это применять так как написано, и эффективность снизится (ведь конкуренция возрастет). Вон, в некоторых соседних темах / конкурсах жалуются, что мол описанное уже не работает?а подумать и модифицировать под свои нужды нет желания или просто не знают как, а хотят готовое.
Или народ начнет это применять так как написано, и эффективность снизится (ведь конкуренция возрастет). Вон, в некоторых соседних темах / конкурсах жалуются, что мол описанное уже не работает?а подумать и модифицировать под свои нужды нет желания или просто не знают как, а хотят готовое.