

- Регистрация
- 11.08.2013
- Сообщения
- 320
- Благодарностей
- 218
- Баллы
- 43
Думаю сейчас уже никому не надо объяснять, что такое дроп. Истекший домен (или дроп-домен) — домен, которым уже пользовались, но владелец решил его не продлевать. После истечения срока аренды такие домены доступны для регистрации любым человеком.
Как заработать на заброшенных доменах?
Есть много способов. Можно использовать его для создания своего сайта и монетизация зависит от тематики. Можно искать такие домены с последующей перепродажей на. Телдери (Реф) ну или Телдери (не реф) Посмотрите скрины нескольких лотов.
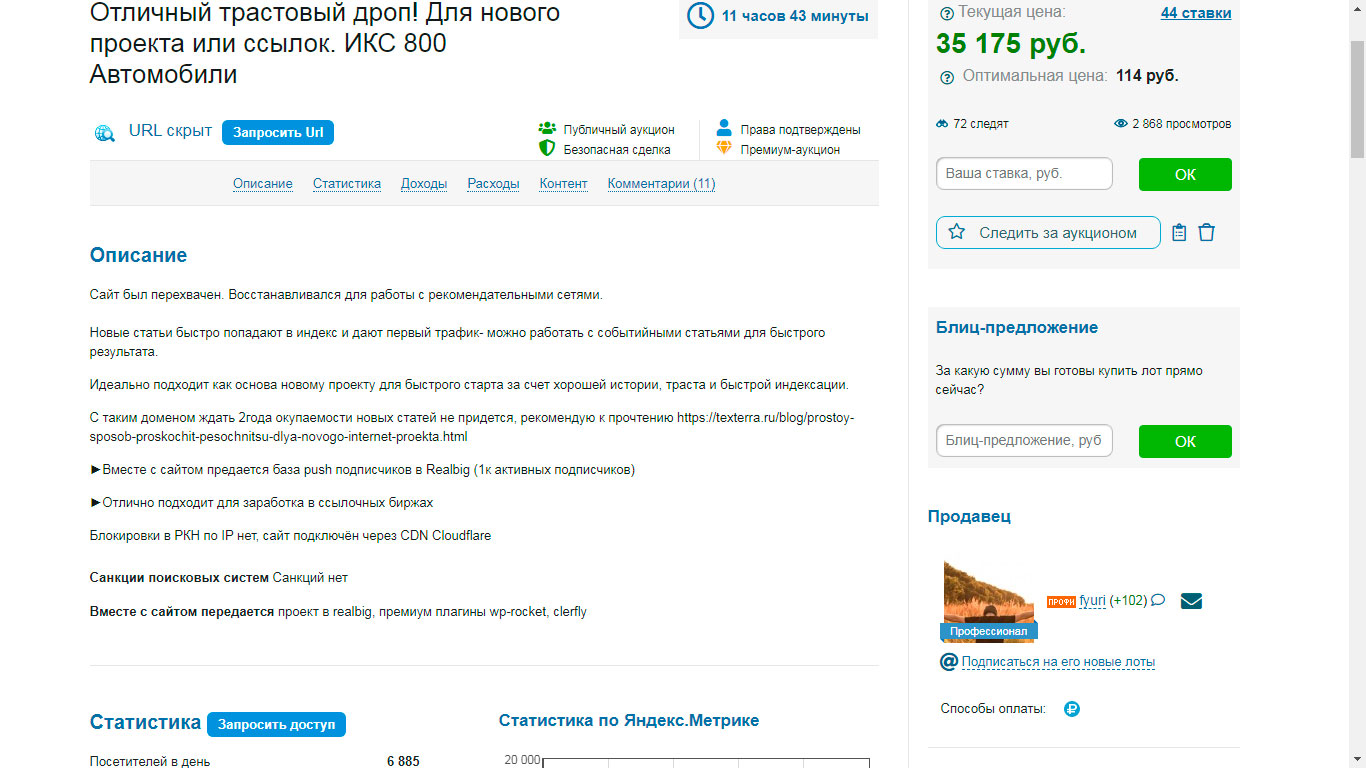
----
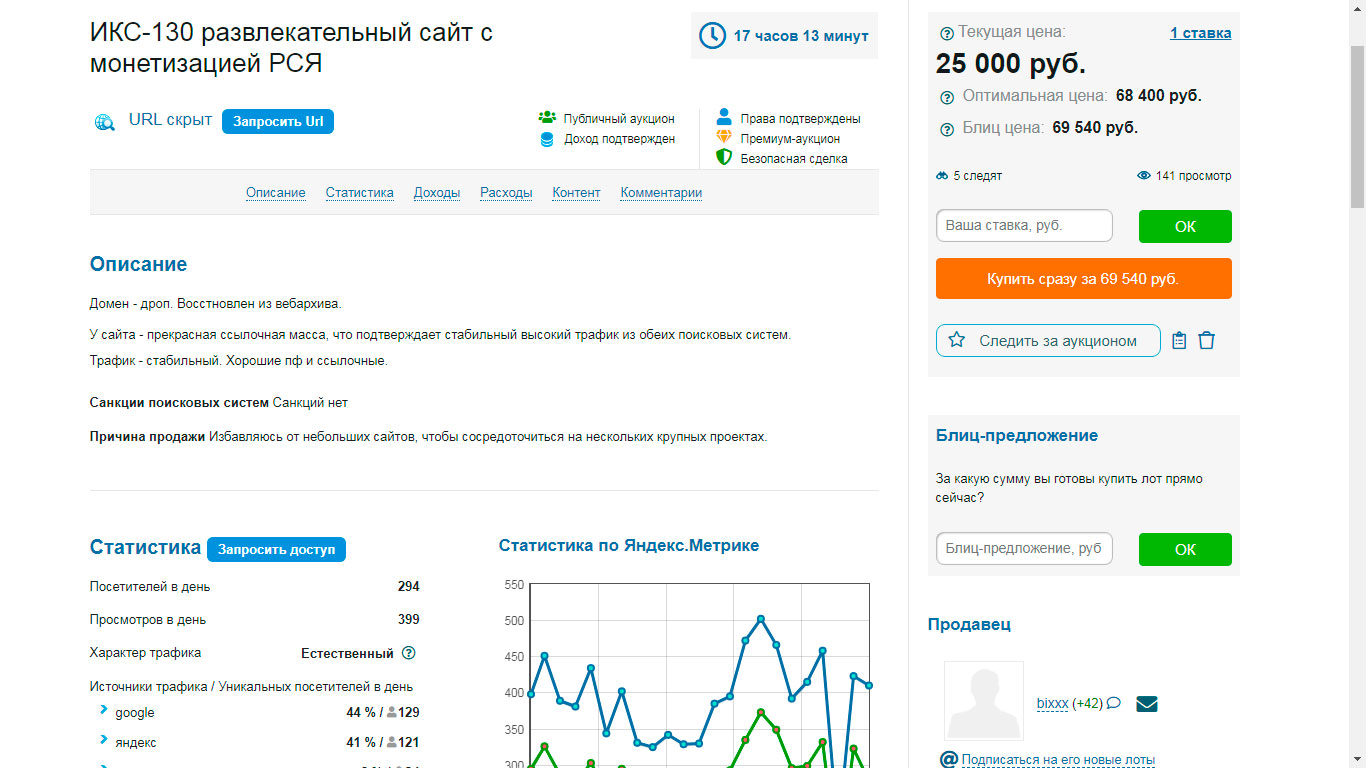
----
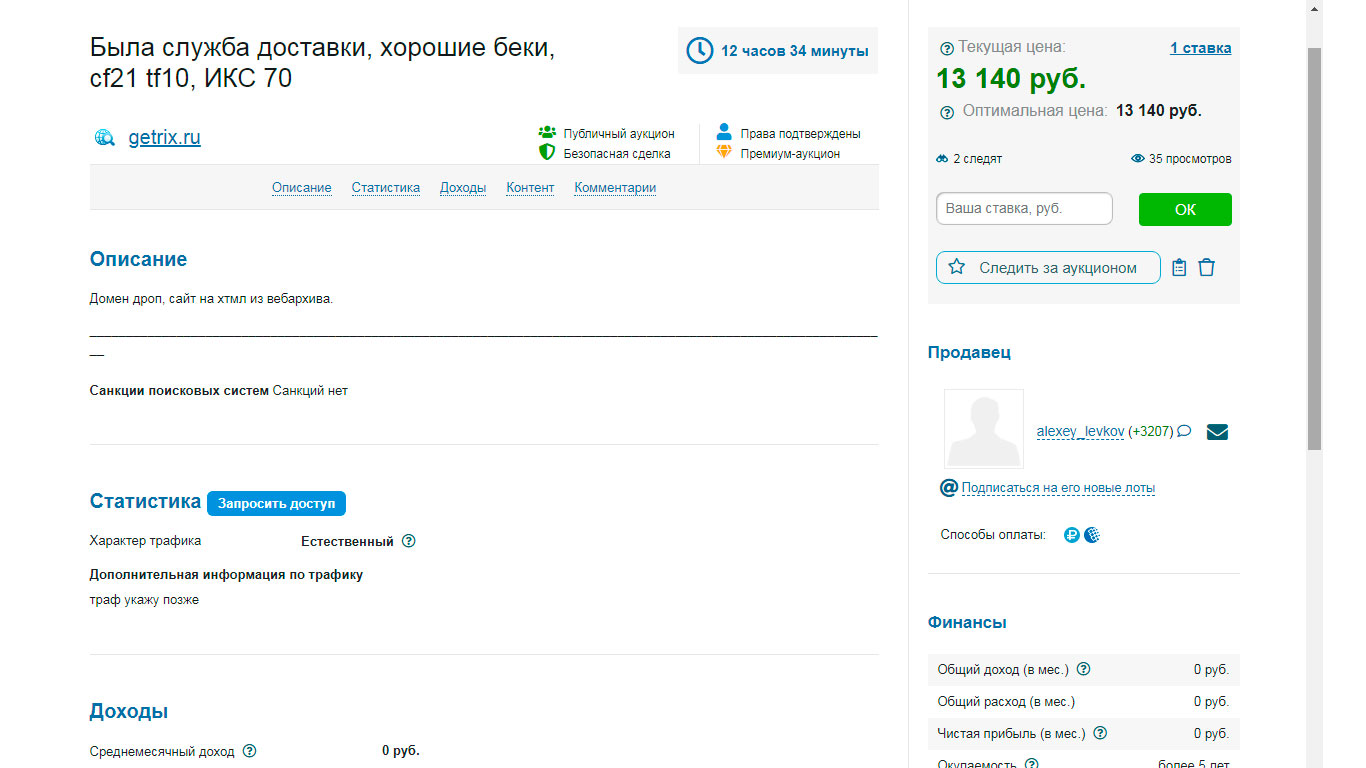
Все наверное видели топик на этом форуме https://zennolab.com/discussion/threads/webarchivemaster-parser-vebarxiva2.45531/ Там товарищ парсит тексты с дропов и зарабатывает на них. Короче дропы доменов – это вещь.
Как искать дропы?
Бывают несколько способов поиска таких доменов. Самый простой метод – идёте на Expired Domains и ищите их там.
Но в этой статье пойдёт речь о поиске дропов по битым ссылкам сайтов конкурентов, с последующим чеком на занятость. То есть мы будем использовать бота, который будет обходить страницы сайтов и парсить с них исходящие ссылки. С этих ссылок будут сграблены домены, для того что бы впоследствии чекнуть их на занятость.
Почему этот метод? Потому что если трастовый сайт на кого-то ссылался, то такая ссылка сама по себе уже много значит. И раз он ссылался, то скорее всего там было что-то интересное и можно будет использовать и нам. Плюс, появляется возможность поиска дропов определённой тематике.
Да я знаю, что не открыл Америку. Существуют программы типа Xenu – или Content Donloaderа, с помощью которых можно выпарсить из сайта внешние ссылки. Но эти программы обрабатывают по одному сайту за раз. Это долго. Это нудно. А мой бот - с изюминкой. Он позволяет сразу же загрузить неограниченное количество сайтов-источников и парсить их все сразу одновременно! Массово, в огромных количествах. Создавая на порядок меньшую нагрузку на компьютер, чем то-же Content Downloader. И используя минимум настроек.
Возможности.
Многопоточность. Да, шаблон её поддерживает. Каков предел? Понятия не имею. У меня очень слабый комп. Это ещё и зависит от того, какие сайты – источники вы будите парсить.
Прокси. Нет, не поддерживает. Я намеренно не добавил их в конкурсный шаблон. Они у всех разные. Но их легко добавить в проект, если они вам понадобятся. Создайте свой список с проксями и берите их оттуда. Там единственный стандартный кубик с GET запросом. Пропишите проксю в нём.
Браузер. Нет, не используется. Только GET запросы. Если понадобится DOM, замените кубик с GET запросом на браузерный.
Защита CloudFlare. Нет, не обходит. Ищите сайты - источники без неё.
Чек на занятость доменов. Нет не чекает. Собирает домены из внешних ссылок как есть.
Алгоритм работы.
Алгоритм простой. Ходим по страницам сайтов. Внутренние ссылки добавляем в очередь для парсинга. Из внешних ссылок извлекаем домены.
Установка.
Скачиваем архив, распаковываем. В шаблоне используется библиотека Html Agility Pack. Это удобный .NET парсер. Его dll находятся в папке Net. Также эти файлы должны быть скопированы в папку %ZennoPosterCurrentPath%\ExternalAssemblies. Иначе «Кина не будет» )) Больше никаких особых требований нет. Никаких баз данных мой шаблон не использует.
Обязательно скопируйте содержимой папки Net в ExternalAssemblies !!!!
И ещё. Парсер не использует баз данных, но информацию о страницах, которые он посетил находится в папке \base\. При работе он постоянно пишет в файлы в этой папке. Поэтому лучше добавить её в исключения антивируса, если он есть на вашем компе. А ещё лучше исключить весь парсер.
Входные настройки.
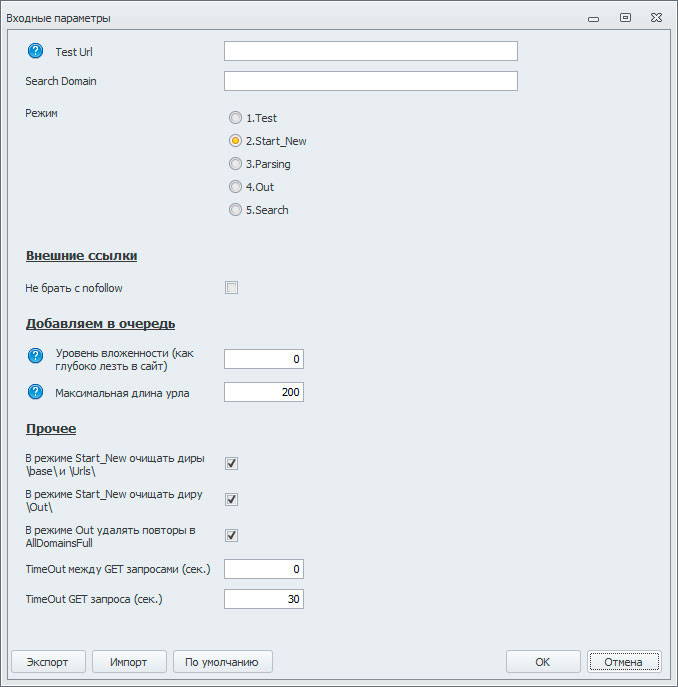
Думаю тут всё понятно и так. Первое поле служит для ввода тестового укла, второе для поиска заданного домена в результатах парсинга. Радиокнопки Mode – выбор режима работы парсера. А ниже идут настройки парсинга.
Остановлюсь только на трёх галках.
Порядок работы шаблоном.
Итак, повторим. Что вы должны делать:
Пример работы шаблоном.
Допустим, мы ищем блоги туристов путешественников. Заходим в гугл. Вбиваем запрос. Что бы было побольше дропов, попросим гугл показать нам выдачу, за несколько лет назад. Дропов в этой выдаче конечно же не будет, но на старых сайтах ссылок на просроченые домены там будет намного больше:
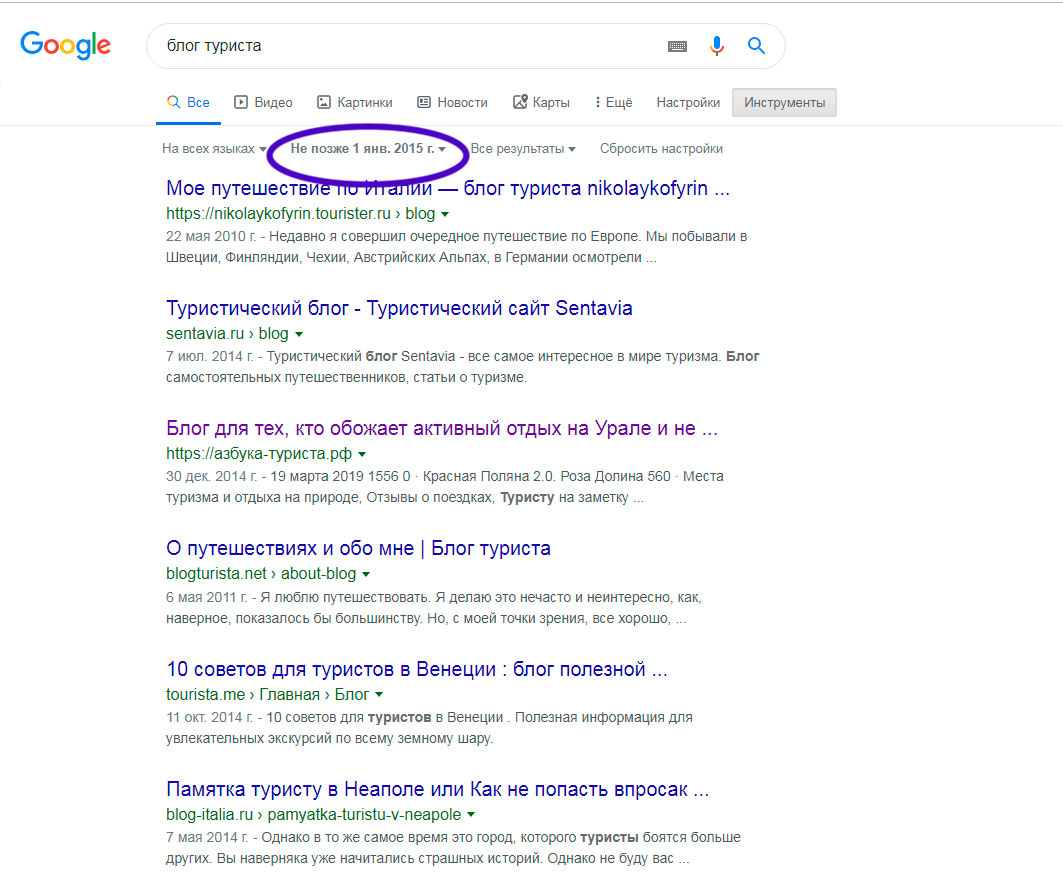
Обходим потенциальные источники ручками, проверяем их в режиме Test. Комбинируя запросы так и эдак, а так же дату выдачи, находим сайты источники, с которых будем собирать домены. Насобирайте их несколько десятков, чем больше, тем лучше и закиньте их в in.txt. И соберите парсером домены. С большой долей вероятности на них будут ссылки на отели, курорты, рестораны, где эти блогеры отдыхали. Бывает, что сменился владелец или вообще закрылся бизнес, а сайт остался. И стал дропом. Собственно, вам только и нужно будет найти такие сайты и выставлять их на продажу. И таких тематик очень много. Авто-Мото, Домашние животные. Адалт и т.д. Если же использовать запросы типа «блоги домашних хозяек» - то там уже будет больше информационных сайтов. Такие больше подойдут для сбора текстов из веб архива.
Понимаете, да? Тяжело найти дроп в сервисе expireddomains.net определённой тематики, если в нём явно не присутствует ключевое слово. А вот гугол может искать такие сайты, которые в свою очередь будут ссылаться на нужные нам дропы. Чем и хорош этот метод.
Напарсили доменов. Дальше что?
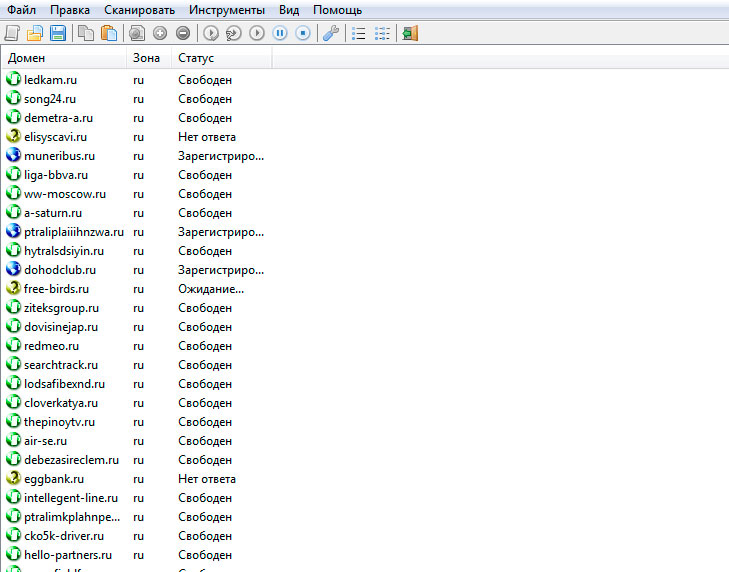
А дальше нужно чекнуть их на занятость. То, что шаблон не делает это сам, это не баг, а так и было задумано. Зачем занимать этим зенку, если есть программы, которые делают это намного лучше. Я делаю это FoxWhois pro. У неё есть как платная так и бесплатная версия, но в бесплатной версии она работает не со всеми зонами. С ру-шками точно работает. Стоит копейки, но вещь нужная. Это вот по-моему лучшая проограмма для чека доменов. Можно конечно использовать сторонние сервисы, можно писать свои шаблоны, а можно один раз купить такую программу и забыть про весь этот гемор. Интерфейс её выглядит вот так: Там колонок много, я оставил только две.
Скачать можно тут: https://foxwhois.com/ (не реф) или купить по ссылке http://whic.ru/?promo=viktor514 (реф) Дадут скидку 20%.
После чека на занятость, свободные проверяем на пузомерки. Данные можно собирать вот с таких сервисов.
http://xseo.in/
https:/expireddomains.net/
https://ru.megaindex.com/backlinks
https://www.similarweb.com/
Яндекс икс, Алекса и т.д.
Ну не руками же, когда есть зенка. Но парсеры под них пишите уже сами. На форуме такие шаблоны уже выкладывали. Всё уже написано, всё уже готово.
После проделанных манипуляций у вас останется самый цимус. Мне этот процесс напоминает добычу золота на канале Дискавери. Мой парсер – это экскаватор. То что он насобирал – 99% - шлак. А остальные парсеры – это промприбор. Ну а на выходе сами понимаете что… Это не шутки, так действительно можно заработать. Люди так работают. Но тема – далеко не из разряда «сел и поехал». Тут море ручной работы, но в этом её и плюс - не скоро сдохнет.
Если вас это каким-то образом простимулирует, то данный способ заработка является абсолютно белым. Что очень редкое явление для Зенки. В большинстве случаев работа зенкой – это воровство. Вы воруете траффик на сайте источнике, собираете чужой контент или занимаетесь спамом. А нацепить в соц сетях женскую аву и продвигать ссылоки с сайтов знакомств – я вообще не понимаю, как таким может заниматься взрослый человек. Тут, конечно же, ничего такого нет.
Струменты для работы с доменами. В хорошей статье должны быть ссылки.
Восстанавливаем сайт из вебархива. У меня машинка самодельная. Вроде, кто-то продавал такой парсер на форуме, но вот https://r-tools.org/ если что, есть платный. То же хорошо работает. Переделать html файлы в какую-то CMS можно самому или найти работника на кворке, что увеличит стоимость при продаже.
Ру домены лучше регать на reg.ru, у него есть онлайн (безбумажная) передача ru - рф доменов. https://www.reg.ru/?rlink=reflink-1383835 (реф) https://www.reg.ru/ (не реф).
https://ru.tld-list.com/ - прекрасный сервис. Сравнивает цены на домены у разных регистаторов. Всегда можно найти, где по-дешевле.
http://www.bannedcheck.com/ Google Banned Check – сервис для проверки, забанен ли сайт в системе Adsense и поисковой системе в Google.
https://ctrlq.org/sandbox/– показывает рекламные блоки для конкретного сайта и страны. Если ресурс забанен в Adsense, то блоки будут пустые. Также полезно можно сайт в кеше Яндекса и Google.
https://yandex.ru/support/partner2/ - Проверка сайта на бан в РСЯ. В отличие от партнерской программы Google Adsense, которая позволяет зарабатывать любому сайту, если он не нарушает правила, в РСЯ каждый сайт проходит модерацию. Требования к качеству сайтов достаточно высокие и попасть туда не так-то просто.
https://eais.rkn.gov.ru/ реестр РКН.
https://www.telderi.ru/ru/check - Проверка сайтов на санкции в GoGetLinks и Miralinks.
https://www.linkpad.ru/ – сервис пригодится для изучения внешних и внутренних ссылок, анкоров, доноров.
https://archive.org/web/ - Вебархив. Вдруг кто-нибудь его не знает.
https://www.telderi.ru/img/book/Buy-websites.pdf - Мануал по покупкам сайтов на теледери . Там про покупку сайтов, но пригодится и продажникам.
Ну и ещё несколько ссылок. Может найдётся, кто-нибудь, кто про них не слышал. – это сервисы монетизации сайтов. Денег с дропов вы на них больших не заработаете. Но потенциальный покупатель увидит, что ваш дроп там не забанен, доход у него есть и цена, соответственно будет совсем другая. Как с ними работать есть куча видосов на ютубе.
https://gogetlinks.net/
https://www.miralinks.ru/
https://www.sape.ru/en
На этом всё. Копайте. Удачной охоты. Немного длинно получилось. Но ведь этож конкурс статей, шаблон тут не главное.
Как заработать на заброшенных доменах?
Есть много способов. Можно использовать его для создания своего сайта и монетизация зависит от тематики. Можно искать такие домены с последующей перепродажей на. Телдери (Реф) ну или Телдери (не реф) Посмотрите скрины нескольких лотов.
----
----
Все наверное видели топик на этом форуме https://zennolab.com/discussion/threads/webarchivemaster-parser-vebarxiva2.45531/ Там товарищ парсит тексты с дропов и зарабатывает на них. Короче дропы доменов – это вещь.
Как искать дропы?
Бывают несколько способов поиска таких доменов. Самый простой метод – идёте на Expired Domains и ищите их там.
Но в этой статье пойдёт речь о поиске дропов по битым ссылкам сайтов конкурентов, с последующим чеком на занятость. То есть мы будем использовать бота, который будет обходить страницы сайтов и парсить с них исходящие ссылки. С этих ссылок будут сграблены домены, для того что бы впоследствии чекнуть их на занятость.
Почему этот метод? Потому что если трастовый сайт на кого-то ссылался, то такая ссылка сама по себе уже много значит. И раз он ссылался, то скорее всего там было что-то интересное и можно будет использовать и нам. Плюс, появляется возможность поиска дропов определённой тематике.
Да я знаю, что не открыл Америку. Существуют программы типа Xenu – или Content Donloaderа, с помощью которых можно выпарсить из сайта внешние ссылки. Но эти программы обрабатывают по одному сайту за раз. Это долго. Это нудно. А мой бот - с изюминкой. Он позволяет сразу же загрузить неограниченное количество сайтов-источников и парсить их все сразу одновременно! Массово, в огромных количествах. Создавая на порядок меньшую нагрузку на компьютер, чем то-же Content Downloader. И используя минимум настроек.
Возможности.
Многопоточность. Да, шаблон её поддерживает. Каков предел? Понятия не имею. У меня очень слабый комп. Это ещё и зависит от того, какие сайты – источники вы будите парсить.
Прокси. Нет, не поддерживает. Я намеренно не добавил их в конкурсный шаблон. Они у всех разные. Но их легко добавить в проект, если они вам понадобятся. Создайте свой список с проксями и берите их оттуда. Там единственный стандартный кубик с GET запросом. Пропишите проксю в нём.
Браузер. Нет, не используется. Только GET запросы. Если понадобится DOM, замените кубик с GET запросом на браузерный.
Защита CloudFlare. Нет, не обходит. Ищите сайты - источники без неё.
Чек на занятость доменов. Нет не чекает. Собирает домены из внешних ссылок как есть.
Алгоритм работы.
Алгоритм простой. Ходим по страницам сайтов. Внутренние ссылки добавляем в очередь для парсинга. Из внешних ссылок извлекаем домены.
Установка.
Скачиваем архив, распаковываем. В шаблоне используется библиотека Html Agility Pack. Это удобный .NET парсер. Его dll находятся в папке Net. Также эти файлы должны быть скопированы в папку %ZennoPosterCurrentPath%\ExternalAssemblies. Иначе «Кина не будет» )) Больше никаких особых требований нет. Никаких баз данных мой шаблон не использует.
Обязательно скопируйте содержимой папки Net в ExternalAssemblies !!!!
И ещё. Парсер не использует баз данных, но информацию о страницах, которые он посетил находится в папке \base\. При работе он постоянно пишет в файлы в этой папке. Поэтому лучше добавить её в исключения антивируса, если он есть на вашем компе. А ещё лучше исключить весь парсер.
Входные настройки.
Думаю тут всё понятно и так. Первое поле служит для ввода тестового укла, второе для поиска заданного домена в результатах парсинга. Радиокнопки Mode – выбор режима работы парсера. А ниже идут настройки парсинга.
Остановлюсь только на трёх галках.
- В режиме Out удалять повторы в AllDomainsFull
Что бы снизить нагрузку на проц, парсер в режиме Parsing не удаляет повторы в результатах парсинга. Что бы удалить повторы служит специальный режим Out. А файл AllDomainsFull.txt, кроме доменов пишутся ещё и страница, на которой находится ссылка на этот домен. Поэтому, если парсер работает длительное время, этот файл может «раздуться» до больших размеров. И зенкка не сможет его загрузить в список и удалить из него повторы. Тогда удалите повторы сторонней програмой. Но это бывает очень редко. - В режиме Start_New очищать диры \base\ и \Urls\
В режиме Start_New очищать диру \Out\
В папке \base\ хранится информация о страницах, которые уже распарсил бот, что бы не заходить на них повторно. А в папке \Urls\ находятся очереди парсига, то есть те страницы источников, на которые ему предстоит зайти. А в папку \Out\ складывает результаты парсинга. И если их очистить, то парсинг начнёнтся сначала. Но бывает моменты, когда нужно просто добавить ещё источники к тем, что крутятся сейчас. Тогда снимаем эти галки, обе, и добавляем ещё источники в in.txt. Потом StartNew и продолжаем Parsing.
Режим работы 1.Test. (Работа в один поток. Выполнить один раз.)
Для чего нужен режим тест? К сожалению, встроенный в зенку кубик с GET запросом, может зависать на некоторых сайтах. Редко, но такое может быть.
Открываем входные настройки. Выбираем режим работы 1. Test. Вверху видим текстовое поле Test Url. Вбиваем в него тестовый урл и запускаем шаблон. В дире с шаблоном появится файл Test.txt. там вы найдёте подробно, то что напарсил бот.
Режим работы 2.Start New. (Работа в один поток. Выполнить один раз.)
Этот режим нужен, для подготовки бота к парсингу. В нём удаляются результаты предыдущего парсинга и создаются служебные файлы и папки для нового.
Вначале нужно подготовить задание для бота. Оно находится в файле in.txt в папке с шаблоном. Формат задания:
В фильтрах реализована логика «И», то есть, для того что бы бот зашёл на определённый урл должны выполнится условия всех фильтров, которые указаны в данном источнике. Если же нужна логика «ИЛИ» тогда добавляем с новой строки ещё источник. Например:
Итак, следуя этим простым правилам составляем задание для бота in.txt и запускаем шаблон в один поток.
Режим работы 3. Parsing (Многопоточная. Работа.)
После того как вы составите задание и выполните процедуру StartNew. Переводим бот в Parsing и запускаем шаблон. Тут шаблон работает в многопотоке. Но каждый поток крутится по кругу. Поэтому слишком много попыток добавлять не нужно. Допустим, если парсинг у вас будет вестись в 10 потоков, то добавте попыток 100 – 200. Результаты парсинга будут находится в папке /Out/. Там появятся файлы Temp.txt, в который будут писаться найденные домены и файл AllDomainsFull.txt в котором кроме доменов, будут ещё и урлы страниц на которых они были найдены. А также флаг(D/N) – какая это была ссылка DoFollow или же NoFollow. Внимание. В режиме парсинга бот не удаляет повторы в выходных файлах, дабы снизить нагрузку на машину. Для удаления повторов в шаблоне предусмотрен специальный режим Out.
Режим работы 4. Out. (Работа в один поток. Выполнить один раз.)
Как я уже писал, мой бот не удаляет повторяющиеся домены в режиме Parsing. С повторами они пишутся в файл Temp.txt. После того как вы прогоните в этом режим парсер один раз повтры удалятся и домены запишутся в файл AllDomains.txt и ещё создстся файл New.txt Вот он-то нам и нужен. Каждый раз когда вы будите выполнять эту процедуру, в этот файл будет записываться новая порция доменов.
Режим работы 5.Search. (Работа в один поток. Выполнить один раз.)
Допустим вы выбрали какой-то домен и вы захотели узнать, а на каком источнике и на каких страницах находятся ссылки содержащие этот домен. А также закрыты они Nofollow или нет. Вбиваем во входных настройках в поле Search Domain и запускаем шаблон в этом режиме один раз, один поток. В папке с шаблоном появится файл Search.txt со списком урлов, где встречается этот домен.
Для чего нужен режим тест? К сожалению, встроенный в зенку кубик с GET запросом, может зависать на некоторых сайтах. Редко, но такое может быть.
Открываем входные настройки. Выбираем режим работы 1. Test. Вверху видим текстовое поле Test Url. Вбиваем в него тестовый урл и запускаем шаблон. В дире с шаблоном появится файл Test.txt. там вы найдёте подробно, то что напарсил бот.
Режим работы 2.Start New. (Работа в один поток. Выполнить один раз.)
Этот режим нужен, для подготовки бота к парсингу. В нём удаляются результаты предыдущего парсинга и создаются служебные файлы и папки для нового.
Вначале нужно подготовить задание для бота. Оно находится в файле in.txt в папке с шаблоном. Формат задания:
Одна строка – один источник и может содержать любое количество фильтров или фильтров не может быть и вовсе. Фильтры нужны в основном, когда вы будите собирать домены с ресурса у которого миллионы страниц, например habr.com или блумберг. А вам нужно парсить только одну его рубрику. Если в сайте - источнике страниц не много, фильтры не нужны, просто закиньте в in.txt стартовые урл, с которых бот начнёт парсинг. Фильтр это подстрока, которую должны содержать урлы в которые полезет бот. Или наоборот запретить ему парсить определённые урлы. Для этого перед подстрокой должен находится знак ^ Например:Стартовый УРЛ|Фильтр1|Фильтр2|Фильтр3…
В этом задании бот будет парсить эти два сайта одновременно без всяких фильров.httрs://gazeta.ru
httрs://picabu.ru
Будут прасится урлы в которых присутствует подстрока /social/https://www.gazeta.ru| /social/
Будут парсится урлы все, кроме тех, котрые содержат /social/https://www.gazeta.ru| ^/social/
Спарсятся урлы в которых присутствует подстрока /social/, но отсутствует подстрока &tag=https://www.gazeta.ru| /social/|^&tag=
В фильтрах реализована логика «И», то есть, для того что бы бот зашёл на определённый урл должны выполнится условия всех фильтров, которые указаны в данном источнике. Если же нужна логика «ИЛИ» тогда добавляем с новой строки ещё источник. Например:
В этом задании бот будет парсить две рубрики /social/ и |/business/https://www.gazeta.ru| /social/
https://www.gazeta.ru|/business/
Итак, следуя этим простым правилам составляем задание для бота in.txt и запускаем шаблон в один поток.
Режим работы 3. Parsing (Многопоточная. Работа.)
После того как вы составите задание и выполните процедуру StartNew. Переводим бот в Parsing и запускаем шаблон. Тут шаблон работает в многопотоке. Но каждый поток крутится по кругу. Поэтому слишком много попыток добавлять не нужно. Допустим, если парсинг у вас будет вестись в 10 потоков, то добавте попыток 100 – 200. Результаты парсинга будут находится в папке /Out/. Там появятся файлы Temp.txt, в который будут писаться найденные домены и файл AllDomainsFull.txt в котором кроме доменов, будут ещё и урлы страниц на которых они были найдены. А также флаг(D/N) – какая это была ссылка DoFollow или же NoFollow. Внимание. В режиме парсинга бот не удаляет повторы в выходных файлах, дабы снизить нагрузку на машину. Для удаления повторов в шаблоне предусмотрен специальный режим Out.
Режим работы 4. Out. (Работа в один поток. Выполнить один раз.)
Как я уже писал, мой бот не удаляет повторяющиеся домены в режиме Parsing. С повторами они пишутся в файл Temp.txt. После того как вы прогоните в этом режим парсер один раз повтры удалятся и домены запишутся в файл AllDomains.txt и ещё создстся файл New.txt Вот он-то нам и нужен. Каждый раз когда вы будите выполнять эту процедуру, в этот файл будет записываться новая порция доменов.
Режим работы 5.Search. (Работа в один поток. Выполнить один раз.)
Допустим вы выбрали какой-то домен и вы захотели узнать, а на каком источнике и на каких страницах находятся ссылки содержащие этот домен. А также закрыты они Nofollow или нет. Вбиваем во входных настройках в поле Search Domain и запускаем шаблон в этом режиме один раз, один поток. В папке с шаблоном появится файл Search.txt со списком урлов, где встречается этот домен.
Порядок работы шаблоном.
Итак, повторим. Что вы должны делать:
- Составляем задание для шаблона. Пишем урлы сайтов источников в файл in.txt
- Запаускаем процедуру Start New. Один раз, один поток.
- Переводи шаблон в режим Parsing. И он работает, парсит, собирает домены. Многопоточно.
- Видите, что набралось достаточное количество доменов в файле \Out\Temp.txt. Прерываете выполнение шаблона.
- Переводите бот в режим Out. Запускаете. Один раз, один поток.
- Забираете файл \Out\New.txt. В нём будет находится новая порция доменов. Его нужно именно забрать: вырезать этот файл и перенести в другое место. Иначе шаблон не запустится в этом режиме в следующий раз. Это своеобразная защита от многопотока. Я забывал убрать количество попыток в настройках зенки и следующий поток затирал этот файл прежде, чем я успевал забрать из него домены.
- Опять переводим шаблон в режим Parsing. То есть переходим к пункту 3. И он парсит себе дальше. А мы в это время чекаем текущую порцию доменов. Файл New.txt. И так по кругу. Парсер насобирал доменов – мы забрали. Он опять парсит, пока он не пройдётся по всем страницам всех сайтов источников.
Пример работы шаблоном.
Допустим, мы ищем блоги туристов путешественников. Заходим в гугл. Вбиваем запрос. Что бы было побольше дропов, попросим гугл показать нам выдачу, за несколько лет назад. Дропов в этой выдаче конечно же не будет, но на старых сайтах ссылок на просроченые домены там будет намного больше:
Обходим потенциальные источники ручками, проверяем их в режиме Test. Комбинируя запросы так и эдак, а так же дату выдачи, находим сайты источники, с которых будем собирать домены. Насобирайте их несколько десятков, чем больше, тем лучше и закиньте их в in.txt. И соберите парсером домены. С большой долей вероятности на них будут ссылки на отели, курорты, рестораны, где эти блогеры отдыхали. Бывает, что сменился владелец или вообще закрылся бизнес, а сайт остался. И стал дропом. Собственно, вам только и нужно будет найти такие сайты и выставлять их на продажу. И таких тематик очень много. Авто-Мото, Домашние животные. Адалт и т.д. Если же использовать запросы типа «блоги домашних хозяек» - то там уже будет больше информационных сайтов. Такие больше подойдут для сбора текстов из веб архива.
Понимаете, да? Тяжело найти дроп в сервисе expireddomains.net определённой тематики, если в нём явно не присутствует ключевое слово. А вот гугол может искать такие сайты, которые в свою очередь будут ссылаться на нужные нам дропы. Чем и хорош этот метод.
Напарсили доменов. Дальше что?
А дальше нужно чекнуть их на занятость. То, что шаблон не делает это сам, это не баг, а так и было задумано. Зачем занимать этим зенку, если есть программы, которые делают это намного лучше. Я делаю это FoxWhois pro. У неё есть как платная так и бесплатная версия, но в бесплатной версии она работает не со всеми зонами. С ру-шками точно работает. Стоит копейки, но вещь нужная. Это вот по-моему лучшая проограмма для чека доменов. Можно конечно использовать сторонние сервисы, можно писать свои шаблоны, а можно один раз купить такую программу и забыть про весь этот гемор. Интерфейс её выглядит вот так: Там колонок много, я оставил только две.
Скачать можно тут: https://foxwhois.com/ (не реф) или купить по ссылке http://whic.ru/?promo=viktor514 (реф) Дадут скидку 20%.
После чека на занятость, свободные проверяем на пузомерки. Данные можно собирать вот с таких сервисов.
http://xseo.in/
https:/expireddomains.net/
https://ru.megaindex.com/backlinks
https://www.similarweb.com/
Яндекс икс, Алекса и т.д.
Ну не руками же, когда есть зенка. Но парсеры под них пишите уже сами. На форуме такие шаблоны уже выкладывали. Всё уже написано, всё уже готово.
После проделанных манипуляций у вас останется самый цимус. Мне этот процесс напоминает добычу золота на канале Дискавери. Мой парсер – это экскаватор. То что он насобирал – 99% - шлак. А остальные парсеры – это промприбор. Ну а на выходе сами понимаете что… Это не шутки, так действительно можно заработать. Люди так работают. Но тема – далеко не из разряда «сел и поехал». Тут море ручной работы, но в этом её и плюс - не скоро сдохнет.
Если вас это каким-то образом простимулирует, то данный способ заработка является абсолютно белым. Что очень редкое явление для Зенки. В большинстве случаев работа зенкой – это воровство. Вы воруете траффик на сайте источнике, собираете чужой контент или занимаетесь спамом. А нацепить в соц сетях женскую аву и продвигать ссылоки с сайтов знакомств – я вообще не понимаю, как таким может заниматься взрослый человек. Тут, конечно же, ничего такого нет.
Струменты для работы с доменами. В хорошей статье должны быть ссылки.
Восстанавливаем сайт из вебархива. У меня машинка самодельная. Вроде, кто-то продавал такой парсер на форуме, но вот https://r-tools.org/ если что, есть платный. То же хорошо работает. Переделать html файлы в какую-то CMS можно самому или найти работника на кворке, что увеличит стоимость при продаже.
Ру домены лучше регать на reg.ru, у него есть онлайн (безбумажная) передача ru - рф доменов. https://www.reg.ru/?rlink=reflink-1383835 (реф) https://www.reg.ru/ (не реф).
https://ru.tld-list.com/ - прекрасный сервис. Сравнивает цены на домены у разных регистаторов. Всегда можно найти, где по-дешевле.
http://www.bannedcheck.com/ Google Banned Check – сервис для проверки, забанен ли сайт в системе Adsense и поисковой системе в Google.
https://ctrlq.org/sandbox/– показывает рекламные блоки для конкретного сайта и страны. Если ресурс забанен в Adsense, то блоки будут пустые. Также полезно можно сайт в кеше Яндекса и Google.
https://yandex.ru/support/partner2/ - Проверка сайта на бан в РСЯ. В отличие от партнерской программы Google Adsense, которая позволяет зарабатывать любому сайту, если он не нарушает правила, в РСЯ каждый сайт проходит модерацию. Требования к качеству сайтов достаточно высокие и попасть туда не так-то просто.
https://eais.rkn.gov.ru/ реестр РКН.
https://www.telderi.ru/ru/check - Проверка сайтов на санкции в GoGetLinks и Miralinks.
https://www.linkpad.ru/ – сервис пригодится для изучения внешних и внутренних ссылок, анкоров, доноров.
https://archive.org/web/ - Вебархив. Вдруг кто-нибудь его не знает.
https://www.telderi.ru/img/book/Buy-websites.pdf - Мануал по покупкам сайтов на теледери . Там про покупку сайтов, но пригодится и продажникам.
Ну и ещё несколько ссылок. Может найдётся, кто-нибудь, кто про них не слышал. – это сервисы монетизации сайтов. Денег с дропов вы на них больших не заработаете. Но потенциальный покупатель увидит, что ваш дроп там не забанен, доход у него есть и цена, соответственно будет совсем другая. Как с ними работать есть куча видосов на ютубе.
https://gogetlinks.net/
https://www.miralinks.ru/
https://www.sape.ru/en
На этом всё. Копайте. Удачной охоты. Немного длинно получилось. Но ведь этож конкурс статей, шаблон тут не главное.
- Тема статьи
- Способы заработка
- Номер конкурса статей
- Двенадцатый конкурс статей
Вложения
-
234 КБ Просмотры: 1 019
Для запуска проектов требуется программа ZennoPoster или ZennoDroid.
Это основное приложение, предназначенное для выполнения автоматизированных шаблонов действий (ботов).
Подробнее...
Для того чтобы запустить шаблон, откройте нужную программу. Нажмите кнопку «Добавить», и выберите файл проекта, который хотите запустить.
Подробнее о том, где и как выполняется проект.


 :-)")