DocSpoc
Client
- Регистрация
- 04.01.2016
- Сообщения
- 295
- Благодарностей
- 176
- Баллы
- 43
Спасибище! Не знал, что можно объединять через "and"как пример, доработаете под себя
//*/button/*[ (@aria-label='Нравится') and (@height='24') ]
Спасибище! Не знал, что можно объединять через "and"как пример, доработаете под себя
//*/button/*[ (@aria-label='Нравится') and (@height='24') ]
где то пролетало что FindChildByXPath не совсем корректно ищет.... возможно это и не так...// собрал коллекцию
HtmlElementCollection itemsCollection = tab.FindElementsByXPath("//div[@class='cabinet']");
HtmlElement item = itemsCollection.GetByNumber(3); // взял элемент из коллекции под №4
// тут хочу получить название из взятого элемента №4
HtmlElement nameItem = item.FindChildByXPath ("//div[@class='description']", 0);
// но вместо этого получаю название от элемента №1
Объясните пожалуйста, что я не правильно делаю.
не одни, а одним.У меня задача взять определённое объявление. Проверить его статусы и в случае соответствия кликнуть по кнопке поднять. Я вижу решение через коллекции и обращение свойствам элемента коллекции. Не совсем понял как сделать "одни xpath"
Спасибо за отклик,не одни, а одним.
ну примерно так //div[@class='cabinet'][3]/div[@class='description']
это как пример, полный путь без документа сложно составить
вместо 3-ки подставить свою переменную при формировании пути
Спасибо за отклик,
Решил задачу через обращение к элементу в виде item.FindChildByAttribute
У меня при постановке переменной вместо 3ки ничего не происходит. Вероятно ошибка в синтаксисе
//div[@class='cabinet'][nomer]/div[@class='description'] Буду признателен, если укажите на ошибку
int nomer = 3;
string xpath = "//div[@class='cabinet']["+nomer.ToString()+"]/div[@class='description']";Там сейчас динамические классы, не как было раньше, но это не самое страшное спарсить можно, но нужно каждую инфу отдельно выпаршивать, весь список не получится сразу, либо как-то поделить.Подскажите пожалуйста как правильно составить запрос и сделать c# сниппет, сохраняющий результат в список, чтобы получить все характеристика товара, на примере: https://market.yandex.ru/product--protsessor-amd-ryzen-5-3600/508275153/spec?track=tabs
модицифицировал запрос таким образом:Там сейчас динамические классы, не как было раньше, но это не самое страшное спарсить можно, но нужно каждую инфу отдельно выпаршивать, весь список не получится сразу, либо как-то поделить.
//div[@data-apiary-widget-name = '@MarketNode/ProductSpecs']
Решился таким образом: //div[@data-apiary-widget-name = '@MarketNode/ProductSpecs']/descendant::dlмодицифицировал запрос таким образом:
//div[@data-apiary-widget-name = '@MarketNode/ProductSpecs']/descendant::dt | //div[@data-apiary-widget-name = '@MarketNode/ProductSpecs']/descendant::dd
парситса все, но в каждую новую строку.
Вопрос как сделать чтобы вывод был таким: Тактовая частота: 3600Мгц?
Или это уже штатными инструментами зенки? Спасибо
Посмотреть вложение 55728
Очень нужно, хелп!Решился таким образом: //div[@data-apiary-widget-name = '@MarketNode/ProductSpecs']/descendant::dl
Подскажите пожалуйста как вывод сохранить в список?
есть же действие - парсить данные по правой кнопке, там есть расширенная настройка и можно поставить свой xpath там же увидишь результат. ну и там есть возможность сразу в список это пихать.Очень нужно, хелп!
непонятно что надо взять. приведенный xpath выбирает 1 span. вроде все нормально. какая конечная цель и какие методы используются для ее достижения ?Подскажите, пожалуйста, как выбрать только определенную строку в узле и больше не брать дочерние html узлы:
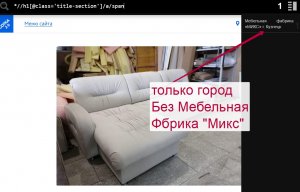
<h1 class="title-section">Раскладной диван-кушетка Фантазия
<a href="/penza/mebelnaya-fabrika-stella-1845">
<span style="font-size: 14px; color: #aaa;">
<br class="xpather-highlight">г. Пенза</span></a>
<br class="xpather-highlight">Мебельная фабрика «Стелла»
</h1>
Страница: www.meb100.ru/livephoto/mebelnaya-fabrika-miks55/4491
В этом коде вторая строка не нужна <br class="xpather-highlight">Мебельная фабрика «Стелла»!
*//h1[@class='title-section']/a/span
У br нет закрывающего тега и тут я не знаю как?
*//h1[@class='title-section']/a/span/text()[2] так попробуйНужно только взять - г. Пенза, без Мебельная Фабрика
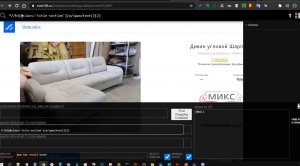
через кубик парсингНаписал запрос http://joxi.ru/823P8dQc8aEYWA Выбираю экшн "Обработка текста". Далее {-Page.Dom-}. Далее во вкладке "Выбрать действия" пытаюсь найти Xpath, но такой опции нет. Как сохранить результаты парсинга в файл?
Cпасибо, помогли разобраться
IZennoList ItemList = project.Lists["Категории"];
IZennoTable table = project.Tables["Таблица 1"];
//Получаем текущу активную вкладку
Tab tab = instance.ActiveTab;
string xpath = "/html[starts-with(@class,'bx-core')]/body[starts-with(@class,'app')]/div[starts-with(@class,'app__wrapper')]/div[starts-with(@class,'b-aside-menu')]/div[@class='b-aside-menu__content']/div[@class='b-aside-menu__navs']/div[@class='b-aside-menu__scroller']/div[@class='b-aside-menu__scroller-content-main-menu']/nav[starts-with(@class,'aside-nav-list')]/ul[1]/li[@class='is-has-child']";
//Соберем все наши элементы используя "//div[starts-with(@data-id, 'model-')]" - xPath запрос. Будьте внимальны и используйте FindElementsByXPath.
HtmlElementCollection itemsCollection = tab.FindElementsByXPath(xpath);
//Лайфхак. Раскомментировать (Чтобы проверить, работает ли xPath) можно отправить в лог информацию о текущем количестве элементов в коллекции
project.SendInfoToLog("Количество элементов на страничке = " + itemsCollection.Count().ToString(), true);
//начинаем перебирать сформированную коллекцию HtmlElement-ов
foreach(HtmlElement item in itemsCollection)
{
//Обращаемся к каждому элементу, как к пездюку через точку.
HtmlElement pathItem = item.FindChildByXPath("./a", 0);
//ItemList.Add(pathItem.InnerText);
string link = new Regex("(?<=href=\").*?(?=\">)").Match(pathItem.OuterHtml).Value;
table.AddRow(pathItem.InnerText+"|"+link);
HtmlElementCollection items2Collection = item.FindChildrenByXPath("./descendant::li");
if {(items2Collection.Count > 0)
foreach(HtmlElement item2 in items2Collection)
{
//Обращаемся к каждому элементу, как к пездюку через точку.
HtmlElement pathItem2 = item2.FindChildByXPath("./a", 0);
string link2 = new Regex("(?<=href=\").*?(?=\">)").Match(pathItem2.OuterHtml).Value;
table.AddRow(pathItem.InnerText+"|"+link+";"+pathItem2.InnerText+"|"+link2);
}
}
}//h2[@class='panel-title']/i[contains(@class,'star')] и потом взять InnerTextПлиз помогите, не могу заставить работать http://xpather.com/8cTCD236
в конструкторе работает а в зенке нет
спасибо
страница для парсингаDibujos en las paredes de la cocina: decoración elegante - pt.onlinesales2021.ru
Dibujos en las paredes de la cocina: decoración elegantept.onlinesales2021.ru
Пробивал выбирал DOM HTML менял InnerText InnerHtml//h2[@class='panel-title']/i[contains(@class,'star')] и потом взять InnerText
Никого не смущает, что сравнение в корне не верное? Тут больше подходит parent и child.
- ancestor (предок, батя)
- descendant (потомок, пезд*к)
Я так понимаю.Никого не смущает, что сравнение в корне не верное? Тут больше подходит parent и child.
А я так.Я так понимаю.
parent это только родительский узел элемента (т.е. на 1 уровень вверх), ancestor это самый верхний возможный узел ветки.
child это вложенный узел (т.е. на 1 уровень ниже), descendant это любой из узлов по ветке ниже без учета глубины вложенности.