Всех приветствую. Есть задача спарсить все innertext'a в коде сайта, но без повторений. Пытался делать через htmlagilitypack:
Но получаю след. итог:
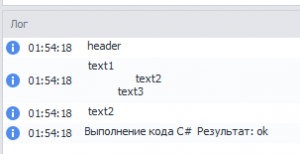
Т.е первый div содержит в себе тег <p> и соответственно его innertext.
Кто может подскажет как сделать, чтобы брались только вхождения без повторов. Может можно проверять наличие потомка и углубляться ниже или как-то еще? Буду благодарен за любой совет )
C#:
var html =
@"<h1>Header</h1>
<div>Text1
<p>Text2</p>
Text3</div>";
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var htmlNodes = htmlDoc.DocumentNode.SelectNodes("//*");
foreach (var node in htmlNodes)
{
//вывод
}
C#:
Header
Text1
Text2
Text3
Text2Кто может подскажет как сделать, чтобы брались только вхождения без повторов. Может можно проверять наличие потомка и углубляться ниже или как-то еще? Буду благодарен за любой совет )