A-Parser Support
Активный пользователь
- Регистрация
- 03.06.2013
- Сообщения
- 348
- Реакции
- 32
- Баллы
- 28
1.2.292 - новый парсер Яндекс ИКС, улучшения в работе с кодировками, оптимизации встроенных парсеров

Улучшения
Улучшения
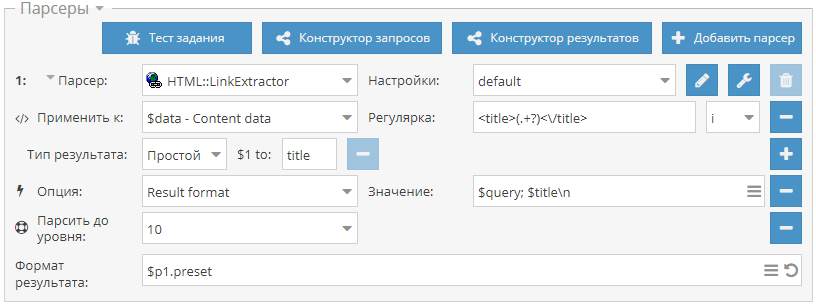
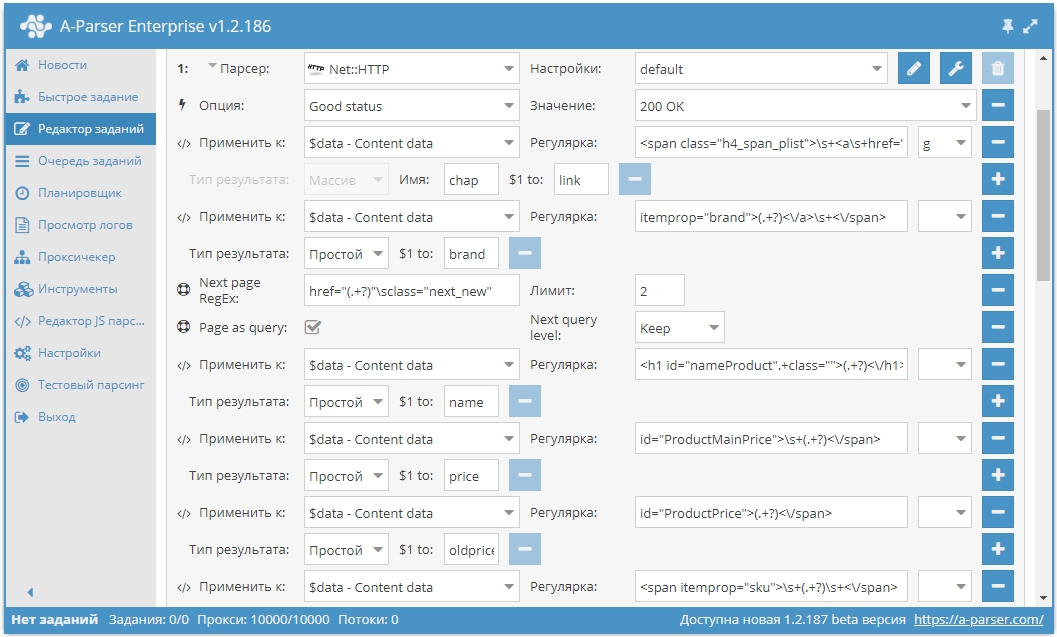
- Добавлен парсер SE::Yandex::SQI - парсер Индекса качества сайта (Яндекс ИКС)

- Оптимизирована работа Очереди заданий
- Добавлена поддержка множества экзотических кодировок китайского языка
- Добавлена опция Save as UTF-8 with BOM, которая решает проблему определения кодировки при открытии сформированного CSV в Excel
- SE::Youtube полностью переписан с использованием современного юзерагента

- SE::AOL::Suggest оптимизирован и переписан на JavaScript

- Улучшена работа SE::Google,
 SE::Google::Modern,
Rank::MajesticSEO,
SE::Google::Modern,
Rank::MajesticSEO, SE::Bing,
SE::Bing, Shop::Amazon
Shop::Amazon
- Исправлен парсинг мобильной выдачи в SE::Google::Modern
- Исправлено определение опечаток в SE::Google и
SE::Google::Modern
- Исправлена ситуация, при которой в SE::Google::Modern в сниппеты могли попадать ненужные ссылки
- Исправлен парсинг рекламы в SE::Yandex

- Исправлен парсинг количества результатов в SE::Youtube
- Удален SE::Yandex::TIC, т.к. больше не актуален
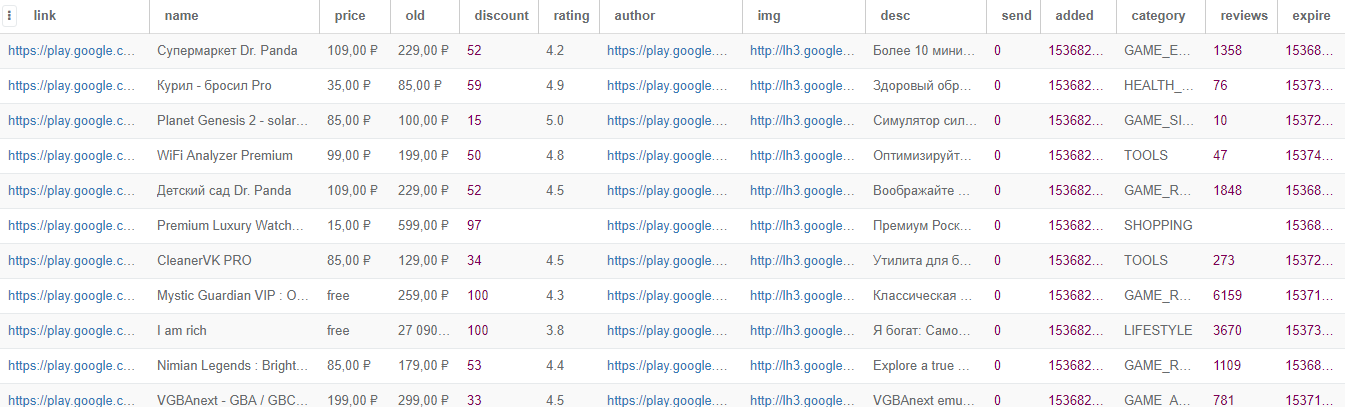
- Исправлен Shop::Yandex::Market,
 SE:
SE:
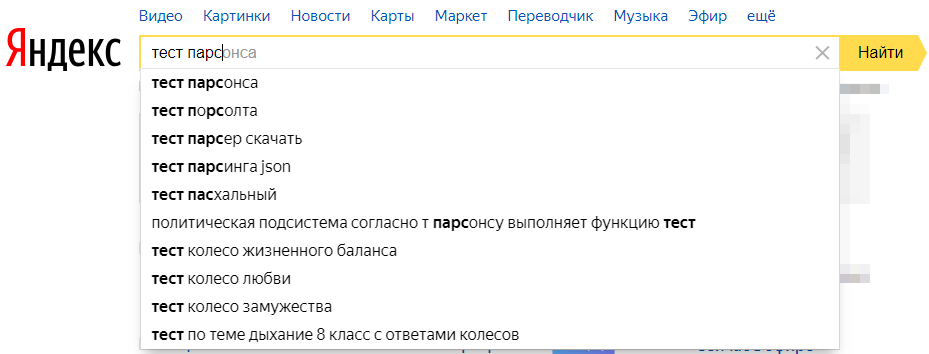
 uckDuckGo,SE::AOL::Suggest
uckDuckGo,SE::AOL::Suggest
- Исправлена работа Net::Whois для некоторых доменных зон

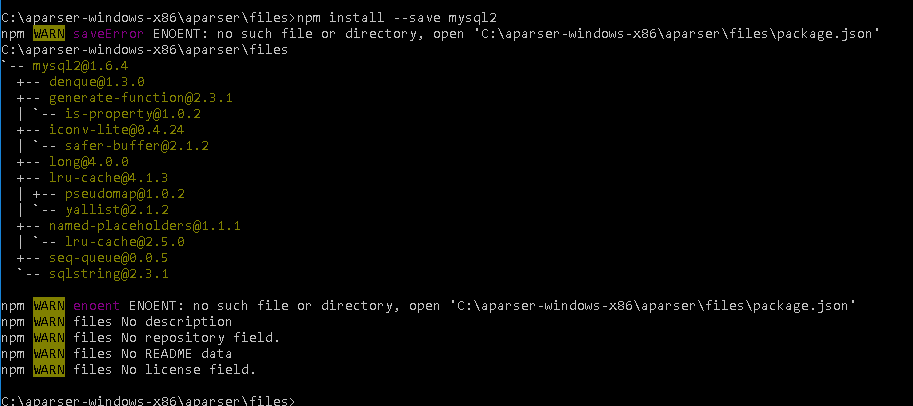
- Исправлена ошибка, при которой не импортировался пресет, если не установлены модули, используемые в нем
- Исправлена кодировка при использовании fs.readdirSync в JS парсерах
 :-)")

























 osition
osition







 8)")