



- Регистрация
- 24.12.2014
- Сообщения
- 616
- Благодарностей
- 442
- Баллы
- 63
Привет, друзья! Давно что-то я не писал статьи на конкурсы, и вот решил исправить это досадное упущение. Честно говоря, не знаю, в какую категорию отнести эту работу. Пусть будет что-то вроде шаблона… или попытки закамуфлировать мой хаос под идею!
В общем, мне в голову пришла мысль создать себе голосового помощника с использованием нейросетей — такого, чтобы и просто, и удобно, и чтобы не приходилось учиться играть на пианино, чтобы им пользоваться. Телеграм оказался идеальным для этого: отправляешь голосовое сообщение боту, он его превращает в текст, шлет ChatGPT, получаешь ответ и — вуаля! — обратно получаешь голосовое сообщение. Всё быстро, без лишней возни, и даже не нужно снимать перчатки зимой, чтобы что-то вбить на клавиатуре.
Так что давайте разбираться по шагам, как же это чудо работает!
Этап 1: Создание бота в ТГ - вот тут думаю все справятся, идём к отцу ботов https://t.me/BotFather и создаём бота. Копируем его токен и вставляем в настройки (об этом позже). Тут главное помнить, что бот не должен использоваться в других проектах, чтобы не было конфликтов.
Этап 2: Получаем/покупаем/ищем токен от ChatGPT - тут думаю тоже особых проблем возникнуть не должно, даже на форуме продаются/продавались. Можно даже простейший древний взять, который 3.5turbo. И тоже пихаем в входные.
Этап 3: Берём любую бурж прокси для работы с чатом - любой сервис прокси поможет, вряд ли кто то с этим не знаком.
На этом всё, можно запускать шаблон и пользоваться функционалом. Но! Давайте всё же разберёмся как это всё работает и почему. А потом перейдём к самим настройкам шаблона.
Техническая сторона
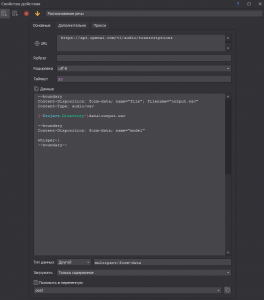
Первым делом, нам нужно выцепить наше сообщение из бота, поэтому пользуясь простой командой API телеграма мы отлавливаем последнее сообщение бота ( тут стоит отметить, что я использую крайне костыльный метод, но в то же время, максимально простой (без вэбхуков и прочего (моя задача, сделать всё максимально просто))
Код обновления сообщений бота:
https://api.telegram.org/botВАШТОКЕНБОТА/getUpdates?offset=-1Дёрнули новое голосовое и нам нужно его скачать. Поэтому делаем запросы:
Получение ссылки на скачивание:
https://api.telegram.org/bot{-Variable.BOT_TOKEN-}/getFile?file_id={-Variable.file_id-}
Скачивание файла:
https://api.telegram.org/file/bot{-Variable.BOT_TOKEN-}/{-Variable.file_path-}
Конвертация в WAV:
-i data\{-Variable.file_name-} data\output.wavУРА! Мы получили нашу голосовуху в WAV формате.
Тут начинается магия! Для распознавания речи я долго выбирал между Яндекс SpeechKit, Google TTS, но решил использовать Whisper от OpenAI. Это их модуль распознавания речи, который, несмотря на простоту использования, предлагает отличное качество распознавания даже для сложных текстов.
Отправляем POST запрос на сервер OpenAI, и в ответе получаем наш текст.
Почитать можно тут. Поэтому составляем просто POST запрос с полученным ранее токеном
В результате получаем качественное распознавание нашего голосового сообщения.
Ну а далее мы отправляем этот текст, суммируя его с текстом дополнительного промта, кол-ва токенов, модели и температуры в сам ChatGPT и получаем результат.
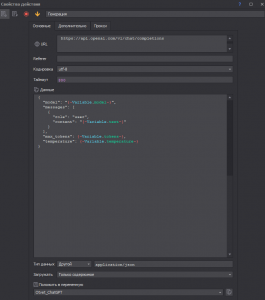
В ответ мы получаем текст. И переходим к самому главному. Синтезу речи, мать его!Я долго искал идеальный вариант, перепробовал многие популярные сервисы, такие как Яндекс и Google, но это оказалось настоящей головной болью. Получение токенов — это вообще отдельный вид пытки. Мне хотелось чего-то максимально простого и удобного. Сначала я обратил внимание на сервис Звукограм (есть обсуждения на форуме), и хотя он платный, голоса там действительно приятные. Но вот скорость работы — ужасная. Даже с ВИП голосом генерация одной фразы занимала больше 30 секунд, что меня жутко раздражало. В итоге, мне всё же нужна была максимальная скорость и желательно бесплатно. Поэтому, как ни странно, мой выбор пал на синтез речи самой Windows. Поэтому простой код на C# и всё готово за секунду.
Код для преобразования текста в речь на Windows:
//-------------------------СОЗДАНИЕ АУДИО--------------------------//
string pathFolder = project.Variables["folder"].Value;
string textAudio = project.Variables["Otvet"].Value;
textAudio = textAudio.Trim();
//Windows синтезатор озвучки
SpeechSynthesizer synch = new SpeechSynthesizer();
if (!Directory.Exists(pathFolder + @"\")) Directory.CreateDirectory(pathFolder + @"\audio\");
//Configure the audio output.
//Имя голоса: Microsoft Irina Desktop
//Имя голоса: Microsoft Zira Desktop
string voiceName = project.Variables["voice"].Value;
if (voiceName != string.Empty) synch.SelectVoice(voiceName);
synch.SetOutputToDefaultAudioDevice();
synch.SetOutputToWaveFile(pathFolder + @"\audio.wav",
new SpeechAudioFormatInfo(32000, AudioBitsPerSample.Sixteen, AudioChannel.Mono));
//Create a SoundPlayer instance to play output audio file.
System.Media.SoundPlayer m_SoundPlayer = new System.Media.SoundPlayer(pathFolder + @"\audio.wav");
//Build a prompt.
PromptBuilder builder = new PromptBuilder();
builder.AppendText(textAudio);
//Speak the prompt.
synch.Speak(builder);
//m_SoundPlayer.Play();
synch.Dispose(); // освобождаем неуправляемые ресурсы, связанные с объектом
// перебираем все файлы в папке и меняем расширение на wav
string audiofile = pathFolder + @"\audio\audio.wav";
foreach (var f in Directory.GetFiles(pathFolder + @"\", "*.mpeg"))
{
File.Move(f, pathFolder + @"\audio.wav");
Thread.Sleep(500);
if(!File.Exists(audiofile)) Directory.Delete(pathFolder);
Thread.Sleep(300);
}
//-----------------------КОНЕЦ СОЗДАНИЯ АУДИО---------------------//Да, он звучит как типичный робот — унылый, будто его кто-то обидел и даже в лицо плюнул. Но что поделать? Он работает максимально быстро и совершенно бесплатно. Конечно, можно заменить этот блок на любой другой, который вам больше по душе. Но для моей задачи он оказался идеальным, даже если звучит, как будто его пригласили на вечеринку, а он пришёл голый.
Остался последний шаг, это снова конвертировать файл в OGG формат и отправить обратно себе в качестве голосового сообщения
FFMPEG - конвертируем:
-i data\audio.wav data\output.ogg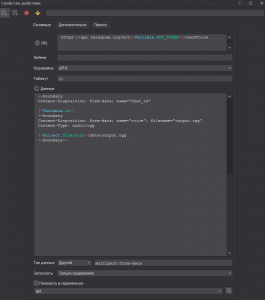
С тех. частью разобрались. УРА!
Теперь немного про входные настройки:
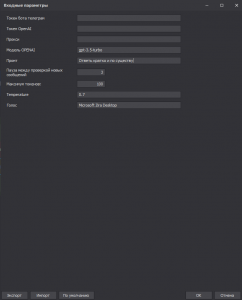
Токены пропустим. С ними понятно
Прокси - это бурж прокси для запросов к OpenAI в зенновском формате
Модель OPENAI - это модель, которая Вам доступна. По дефолту стоит gpt-3.5-turbo. Можно изменить на любую Вам доступную
Промт - это дополнительный запрос к ChatGPT помимо текста Вашего голосового сообщения. Можно оставить пустым, если не нужно
Пауза между проверкой новых сообщений - как часто шаблон будет мониторить новые сообщения в боте (в секундах)
Максимум токенов - сколько токенов вы готовы пожертвовать для ответа (1 слово примерно 4 токена (могу ошибаться))
Temperature -креативность ответа. 0 - модель будет следовать наиболее вероятным вариантам ответов, что делает её предсказания более предсказуемыми и строгими. Это полезно, когда нужна точность или фактическая информация. 1 - модель будет отвечать с большей долей случайности, предлагая более разнообразные и творческие варианты. Это полезно, если вам нужны нестандартные решения или креативные идеи
Голос - голос Windows речи (узнать все доступные можно через PowerShell (подробнее):
Команда PowerShell:
Get-WmiObject -Namespace root\CIMv2 -Class Win32_SpeechVoiceНу что, друзья, вот и финал! Мой простейший голосовой помощник на базе ChatGPT готов. Да, его голос оставляет желать лучшего — звучит так, будто его собрали на скорую руку из старого робота-пылесоса, но зато скорость работы вполне приличная! Может, не для всех он идеален, но для меня он сидит, как тапочки после долгого рабочего дня — удобно и без вопросов! Лично для моих задач это то, что нужно: просто, быстро и без лишних заморочек.
Спасибо всем за внимание и терпение! И помните: главное — не голос, а умные ответы, которые он генерирует!
Спасибо всем за внимание и терпение! И помните: главное — не голос, а умные ответы, которые он генерирует!
Вложения
-
43,4 МБ Просмотры: 220
