

Всем привет. Наткнулся я на днях на такой пост

и решил глянуть, что да как. В этой статье мы разберем написание парсера для сайта https://bamper.by/. ТС вроде как уже помогли, но раз уж я начал…
В общем, в этой статье я опишу, как можно спарсить данный сайт на запросах. Опишу проблемы, с которыми столкнулся и как решил. Надеюсь, что новичкам будет полезно. @ial1408, если ещё актуально, можешь почитать. А мы начнем.
Первое, что я сделал - это просто зашел на сайт через браузер. Никакого cloudflare я не увидел. Удивился, ну да ладно.
Следующим шагом я отключил в браузере JS и снова зашёл на сайт.

Удивился ещё раз, т.к. контент оказывается тут отдается даже с отключенным JavaScript. Был бы cloudflare, по идее не должен был отдаться.

Ну, это хорошие новости. Если вы видите нужную вам информацию с отключенным JS, то значит наверняка сможете накатать парсер на запросах.
Далее полез делать тестовый запрос. Ответ 200, very good.
Скрин вкладки "трафик"

Однако в ответе какие-то кракозябры вместо html.
Что за дичь, думаю? Полез делать запрос через Python, получил 403.

Так думаю. Раз в зенке запрос проходит, то и здесь должен. Подставил User-Agent. Запрос прошёл нормально, ответ 200. Сам ответ содержит нормальный html.

Значит указание User-Agent обязательно. Учтём.
А что же не так в зеннопостер? Начал гуглить и методом тыка понял, что проблема в дефолтных заголовках. Если их убрать, то получаем нормальный ответ. Главное User-Agent не забыть прописать.


Так, попробуем теперь подставить прокси. Опа, не проходит запрос.

Я использовал серверные ipv4. Значит прокси сайт не любит. Возможно не нравится страна или то, что прокси серверные. Иду на ZennoProxy, выбираю резидентские ру, пробую выполнить запрос

Отлично, значит зенковские прокси нам подходят.
Окей, теперь посмотрим, как у нас формируется пагинация. Я решил парсить эту категорию - https://bamper.by/shiny/ .
Если начать переходить по страницам, то мы увидим следующее:
https://bamper.by/shiny/?PAGEN_1=2
https://bamper.by/shiny/?PAGEN_1=3
и т.д.
Значит, надо будет просто увеличивать счётчик для урл https://bamper.by/shiny/?PAGEN_1=
Ну а какая же страница последняя? В навигации этого не увидеть

Самый простой вариант - это метод тыка. Мы видим, что выводится по 20 карточек на странице. Мы также видим, что найдено 49544 шины. Путем нехитрой математики получаем порядка 2477 страниц. Пробуем.

И действительно, 2478 страница последняя. Как видим, даже тут сайт нас ни в чем не ограничивает. Иногда бывает, что сайт отказывается давать более 100 страниц или более 1000 страниц и остается только разбиение по фильтрам. Тут нас от этого избавили.
Теперь посмотрим что будет, если открыть 2479 страницу (т.к. в будущем количество страниц может измениться).

Ответ приходит 200, но появляется надпись "Объявлений не найдено". Значит, можно привязаться к ней или же к отсутствию карточек, дабы затормозить наш парсер.
Теперь надо потестировать, как сайт будет вести себя при множестве запросов. Создадим простейший цикл и оставим его на некоторое время. Посмотрим, не вернется ли нам 403. Прокси я буду использовать зенковские.


Видим, что в целом нормально, но иногда пустой ответ, реже 403. Это надо будет учесть. Скорость конечно не супер, но пойдет. Резидентские вроде все такие. Вот для сравнения сколько занимает запрос без прокси

Я решил не заходить "внутрь" карточек, ограничившись тем, что есть.
Мы с вами соберем:

Реализуем парсер
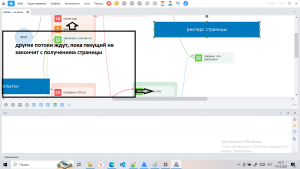
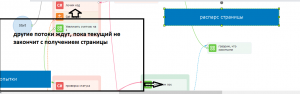
Заводим счётчик, отвечающий за номер страницы. При такой логике реализовать нормальный многопоток на кубиках у меня не вышло (дубли / пропуски стр). Поэтому наш шаблон будет работать в 1 поток.
Если вы хотите многопоточный шаблон, то как вариант - заранее сложить все урл в список / бд и брать оттуда.
Формируем урл, отправляем запрос. В случае неудачи отправляем повторные запросы.
После получения страницы получаем карточки в список.

Далее этот список перебираем, из каждой карточки достаем нужные нам данные. Для этого мы пользуемся кубиком "парсить страницу".

Для поиска элементов можно использовать CSS селекторы или XPath пути (темы XPath я уже касался в этой статье).
В качестве источника данных указываем "переменная".
Также не забываем указать диапазон, иначе в кубике будет ошибка.

Ещё отмечу, что если элемент найден не будет, то кубик уйдет по красной ветке. Имейте ввиду.
После получения данных, мы их чистим от мусора (в основном пробелы по бокам), приводим в нужный нам вид и сохраняем куда надо (из коробки нам доступно сохранение в txt, csv, xlsx, гугл таблицы, БД).
Далее переходим к следующей странице и так по кругу, пока не закончим. Реализацию можно посмотреть в прикрепленном шаблоне. Если будут вопросы, то отвечу.
На этом у меня всё. Если вам интересна тема парсинга и автоматизации в целом, подписывайтесь на мой телеграмм канал. P.S. Реклама оставлена с разрешения администрации.
и решил глянуть, что да как. В этой статье мы разберем написание парсера для сайта https://bamper.by/. ТС вроде как уже помогли, но раз уж я начал…
В общем, в этой статье я опишу, как можно спарсить данный сайт на запросах. Опишу проблемы, с которыми столкнулся и как решил. Надеюсь, что новичкам будет полезно. @ial1408, если ещё актуально, можешь почитать. А мы начнем.
Анализ сайта
Первое, что я сделал - это просто зашел на сайт через браузер. Никакого cloudflare я не увидел. Удивился, ну да ладно.
Следующим шагом я отключил в браузере JS и снова зашёл на сайт.
Удивился ещё раз, т.к. контент оказывается тут отдается даже с отключенным JavaScript. Был бы cloudflare, по идее не должен был отдаться.
Ну, это хорошие новости. Если вы видите нужную вам информацию с отключенным JS, то значит наверняка сможете накатать парсер на запросах.
Далее полез делать тестовый запрос. Ответ 200, very good.
Скрин вкладки "трафик"
Однако в ответе какие-то кракозябры вместо html.
Что за дичь, думаю? Полез делать запрос через Python, получил 403.
Так думаю. Раз в зенке запрос проходит, то и здесь должен. Подставил User-Agent. Запрос прошёл нормально, ответ 200. Сам ответ содержит нормальный html.
Значит указание User-Agent обязательно. Учтём.
А что же не так в зеннопостер? Начал гуглить и методом тыка понял, что проблема в дефолтных заголовках. Если их убрать, то получаем нормальный ответ. Главное User-Agent не забыть прописать.
| Когда я начал писать статью, то хотел воспроизвести ответ с кракозябрами. Но на моё удивление, даже при использовании дефолтных заголовков ответ приходил в правильной кодировке. Что это за "самопочинка" я так и не понял. Но я всё же решил вставить этот момент в статью, вдруг пригодится. |
Так, попробуем теперь подставить прокси. Опа, не проходит запрос.
Я использовал серверные ipv4. Значит прокси сайт не любит. Возможно не нравится страна или то, что прокси серверные. Иду на ZennoProxy, выбираю резидентские ру, пробую выполнить запрос
Отлично, значит зенковские прокси нам подходят.
Окей, теперь посмотрим, как у нас формируется пагинация. Я решил парсить эту категорию - https://bamper.by/shiny/ .
Если начать переходить по страницам, то мы увидим следующее:
https://bamper.by/shiny/?PAGEN_1=2
https://bamper.by/shiny/?PAGEN_1=3
и т.д.
Значит, надо будет просто увеличивать счётчик для урл https://bamper.by/shiny/?PAGEN_1=
Ну а какая же страница последняя? В навигации этого не увидеть
Самый простой вариант - это метод тыка. Мы видим, что выводится по 20 карточек на странице. Мы также видим, что найдено 49544 шины. Путем нехитрой математики получаем порядка 2477 страниц. Пробуем.
И действительно, 2478 страница последняя. Как видим, даже тут сайт нас ни в чем не ограничивает. Иногда бывает, что сайт отказывается давать более 100 страниц или более 1000 страниц и остается только разбиение по фильтрам. Тут нас от этого избавили.
Теперь посмотрим что будет, если открыть 2479 страницу (т.к. в будущем количество страниц может измениться).
Ответ приходит 200, но появляется надпись "Объявлений не найдено". Значит, можно привязаться к ней или же к отсутствию карточек, дабы затормозить наш парсер.
Теперь надо потестировать, как сайт будет вести себя при множестве запросов. Создадим простейший цикл и оставим его на некоторое время. Посмотрим, не вернется ли нам 403. Прокси я буду использовать зенковские.
Видим, что в целом нормально, но иногда пустой ответ, реже 403. Это надо будет учесть. Скорость конечно не супер, но пойдет. Резидентские вроде все такие. Вот для сравнения сколько занимает запрос без прокси
Что будем собирать
Я решил не заходить "внутрь" карточек, ограничившись тем, что есть.
Мы с вами соберем:
- Заголовок
- Ссылку на объявление
- Описание
- Артикул
- Дату
- Город
- Ссылку на картинку
- Цену.
Реализуем парсер
Заводим счётчик, отвечающий за номер страницы. При такой логике реализовать нормальный многопоток на кубиках у меня не вышло (дубли / пропуски стр). Поэтому наш шаблон будет работать в 1 поток.
Если вы хотите многопоточный шаблон, то как вариант - заранее сложить все урл в список / бд и брать оттуда.
Формируем урл, отправляем запрос. В случае неудачи отправляем повторные запросы.
После получения страницы получаем карточки в список.
Далее этот список перебираем, из каждой карточки достаем нужные нам данные. Для этого мы пользуемся кубиком "парсить страницу".
Для поиска элементов можно использовать CSS селекторы или XPath пути (темы XPath я уже касался в этой статье).
В качестве источника данных указываем "переменная".
Также не забываем указать диапазон, иначе в кубике будет ошибка.
Ещё отмечу, что если элемент найден не будет, то кубик уйдет по красной ветке. Имейте ввиду.
После получения данных, мы их чистим от мусора (в основном пробелы по бокам), приводим в нужный нам вид и сохраняем куда надо (из коробки нам доступно сохранение в txt, csv, xlsx, гугл таблицы, БД).
Далее переходим к следующей странице и так по кругу, пока не закончим. Реализацию можно посмотреть в прикрепленном шаблоне. Если будут вопросы, то отвечу.
На этом у меня всё. Если вам интересна тема парсинга и автоматизации в целом, подписывайтесь на мой телеграмм канал. P.S. Реклама оставлена с разрешения администрации.
Вложения
-
 141,2 КБ Просмотры: 45
141,2 КБ Просмотры: 45 -
 49,8 КБ Просмотры: 44
49,8 КБ Просмотры: 44 -
58,2 КБ Просмотры: 48
Последнее редактирование:
