



- Регистрация
- 08.11.2015
- Сообщения
- 1 912
- Благодарностей
- 2 658
- Баллы
- 113
Здравствуйте!
Меня зовут Юрий Йосифович.
Живу в селе и в реальной жизни не работаю.
Если бы мне кто-то когда-то сказал, что я буду одалживать кучу денег на покупку лицензии на какую-то программу - я бы спросил этого человека, что он курил...
Меня зовут Юрий Йосифович.
Живу в селе и в реальной жизни не работаю.
Если бы мне кто-то когда-то сказал, что я буду одалживать кучу денег на покупку лицензии на какую-то программу - я бы спросил этого человека, что он курил...
Но... Все меняется! В один день я взял калькулятор и подсчитал свой суточный заработок с iMacros. Умножил данное число на 10. И тогда я понял, что если сейчас найду деньги на Зеннопостер, то у меня появится "палка-копалка" которая будет приносить деньги в несколько раз быстрее. Если же не рискну - то так и буду топтаться в копеечных заработках. В результате - я одолжил денег и уже 9 ноября 2015 года вступил в ряды сообщества счастливых обладателей программ от ZennoLab.
Первые несколько дней я разбирался с тем как установить программы и как писать первые шаблоны и уже через месяц с момента покупки я окупил вложения в лицензии и прокси.
Сразу пришла мысль масштабировать доход - был куплен еще один комплект (ZennPosterPRO + CapMonstr2)... И так в течении пол года я стал обладателем 6 лицензий на Зеннопостер ПРО и прокачал КапМонстр2 до 180 потоков и окупил вложения.
Сразу пришла мысль масштабировать доход - был куплен еще один комплект (ZennPosterPRO + CapMonstr2)... И так в течении пол года я стал обладателем 6 лицензий на Зеннопостер ПРО и прокачал КапМонстр2 до 180 потоков и окупил вложения.
У меня есть свой блог, есть канал на YouTube - там я и стараюсь сделать так, чтобы о данных программах узнало как можно больше людей. Кому-то рассказываю, зачем ему Зеннопостер, кому-то - как написать шаблон, кому-то как научить шаблоны работать с базами данных - а помощь людям не может оставаться незамеченной: кто-то копеечкой благодарит, кто-то добрым словом, кто-то темку для заработка подбросит.
Если меня кто-то спросит, какой программой лучше всего автоматизировать какой-то процесс работы в интернете - я однозначно порекомендую Зеннопостер, так как сейчас не представляю, как можно зарабатывать в интернете без данной программы!
Если меня кто-то спросит, какой программой лучше всего автоматизировать какой-то процесс работы в интернете - я однозначно порекомендую Зеннопостер, так как сейчас не представляю, как можно зарабатывать в интернете без данной программы!
Когда речь идет об автоматизации - то в первую очередь приходится задать изначальные вводные данные, выставить требования к будущей системе и определить будущий результат работы.
В разрезе темы данной статьи под вводными данными мы можем подразумевать ключ API, ID канала, ID видео, временные токены, адрес сервера с установленой базой данных MySQL, логин к базе данных, пароль к базе данных, имя базы данных, таблицы базы данных, список значений которые будут получены в процессе работы и подобное...
Наша система автоматизации должна будет без использования браузера с помощью API YouTube (и/или POST/GET запросов) и программы Зеннопостер получать общедоступные данные о канале и видео (включая комментарии к видео) и сохранять полученные результаты работы в таблицы базы данных MySQL.
Удовлетворительным результатом будем считать решение, которое получив вводные данные, на выходе будет записывать результат в базу данных MySQL с возможностю многопоточной работы.
Впринципе уже имея эту информацию можно приступать к разработке шаблонов, котоыре будут выполнять данную работу. Но, я понимаю, что не все читатели данной статьи вплотную встречались с сбором информации на YouTube (а может вообще никогда не занимались парсингом информации с помощью Зеннопостера) - из-за чего прежде всего постараюсь ответить на несколько вопросов.
В разрезе темы данной статьи под вводными данными мы можем подразумевать ключ API, ID канала, ID видео, временные токены, адрес сервера с установленой базой данных MySQL, логин к базе данных, пароль к базе данных, имя базы данных, таблицы базы данных, список значений которые будут получены в процессе работы и подобное...
Наша система автоматизации должна будет без использования браузера с помощью API YouTube (и/или POST/GET запросов) и программы Зеннопостер получать общедоступные данные о канале и видео (включая комментарии к видео) и сохранять полученные результаты работы в таблицы базы данных MySQL.
Удовлетворительным результатом будем считать решение, которое получив вводные данные, на выходе будет записывать результат в базу данных MySQL с возможностю многопоточной работы.
Впринципе уже имея эту информацию можно приступать к разработке шаблонов, котоыре будут выполнять данную работу. Но, я понимаю, что не все читатели данной статьи вплотную встречались с сбором информации на YouTube (а может вообще никогда не занимались парсингом информации с помощью Зеннопостера) - из-за чего прежде всего постараюсь ответить на несколько вопросов.
Кто владеет информацией, тот владеет миром - сказал когда-то Натан Ротшильд. А YouTube - это то место, в которое каждую минуту залетает более 400 часов видео!
Неужели среди такого количества различной информации с помощью автоматизации не получится извлечь хоть какую-то личную выгоду?
За несколько минут я набросал список идей, которые хотелось бы расширить. Так что если у вас есть идеи для чего можно еще использовать выборку общедоступной информации с YouTube – напишите, пожалуйста!
Неужели среди такого количества различной информации с помощью автоматизации не получится извлечь хоть какую-то личную выгоду?
За несколько минут я набросал список идей, которые хотелось бы расширить. Так что если у вас есть идеи для чего можно еще использовать выборку общедоступной информации с YouTube – напишите, пожалуйста!
У меня на канале много роликов. Я честно уже не помню, какие описания я оставлял в этих роликах, и какие теги прописывал. После сбора информации о своем канале я смогу без проблем посмотреть в одной табличке, к каким видео, какие теги были присвоены и какие описания сейчас у роликах.
Может быть, что посмотрев результаты, я сделаю вывод, что в каких-то роликах нужно добавить теги, а в каких-то изменить, возможно, где-то нужно будет описание переписать, а где-то заменить нерабочие ссылки, на рабочие.
Просмотрев информацию о том, кто и где комментировал больше всего на канале – смогу, например, пройтись по этих каналах прокомментировать их ролики (обратить на свой канал внимание), либо смогу провести конкурс комментаторов на канале (так как четко смогу определить количество комментариев любым конкретным комментатором).
Собрав все ID своих видео, я смогу быстро скачать все превьюшки к роликам - потом посмотреть их, при желании переделать - и тем самым сделать канал более приветливым к новым зрителям.
Собрав всю информацию о роликах, я смогу структурировать информацию и, например, относительно этого создать несколько плейлистов с тематическими роликами.
Без проблем можно разбить все ролики на разделы на своем канале (плейлистами) - чтобы пользователям удобнее было находить необходимый материал.
Может быть, что посмотрев результаты, я сделаю вывод, что в каких-то роликах нужно добавить теги, а в каких-то изменить, возможно, где-то нужно будет описание переписать, а где-то заменить нерабочие ссылки, на рабочие.
Просмотрев информацию о том, кто и где комментировал больше всего на канале – смогу, например, пройтись по этих каналах прокомментировать их ролики (обратить на свой канал внимание), либо смогу провести конкурс комментаторов на канале (так как четко смогу определить количество комментариев любым конкретным комментатором).
Собрав все ID своих видео, я смогу быстро скачать все превьюшки к роликам - потом посмотреть их, при желании переделать - и тем самым сделать канал более приветливым к новым зрителям.
Собрав всю информацию о роликах, я смогу структурировать информацию и, например, относительно этого создать несколько плейлистов с тематическими роликами.
Без проблем можно разбить все ролики на разделы на своем канале (плейлистами) - чтобы пользователям удобнее было находить необходимый материал.
Когда мы просто заходим на YouTube - мы не видим сразу, по каким ключевым словам нам выдаются результаты. Таким образом, мы просматриваем вагон разного мусора, прежде чем найдем что-то дельное.
Но, когда, к примеру, мы добавили в базу данных пару десятков тематичных каналов и собираем видео с них - то у нас есть возможность выбирать только ролики, например, с тегом ДЕНЬГИ и, например, с более чем 1000 лайков (и не более 100 дизлайков). Таким образом, просмотрев бегло свою базу данных можно находить как идеи для записи роликов (если тема актуальная - будут набирать просмотры), либо для заработка Зеннопостером.
Я сам, когда определялся с тем, какие превьюшки делать на своем канале, прежде пролистал огромное количество разных популярных роликов, отсортированных по признаку количества лайков и отсутствия дизлайков.
Но, когда, к примеру, мы добавили в базу данных пару десятков тематичных каналов и собираем видео с них - то у нас есть возможность выбирать только ролики, например, с тегом ДЕНЬГИ и, например, с более чем 1000 лайков (и не более 100 дизлайков). Таким образом, просмотрев бегло свою базу данных можно находить как идеи для записи роликов (если тема актуальная - будут набирать просмотры), либо для заработка Зеннопостером.
Я сам, когда определялся с тем, какие превьюшки делать на своем канале, прежде пролистал огромное количество разных популярных роликов, отсортированных по признаку количества лайков и отсутствия дизлайков.
Для продвижения разных серых каналов и серых блогов очень важно набирать большое количество комментариев, при чем, релевантных комментариев. Но где их брать? Правильно!
Собрав прежде базу данных, с YouTube, мы можем без проблем сделать выборку комментариев только с роликов с определенным нами тегом. Дальше можем отправить задание на рерайт с размещением в нужном месте (или поручить сам постинг Зеннопостеру).
Сбор комментариев на YouTube пригодится и тогда, когда нам нужно придумывать отзывы о товаре (выполняя прихоти заказчиков на фрилансе) - просто выборку с базы данных обратно берем по нужным тегам с условием длины не менее столько-то знаков.
А если нам на многих каналах попадаются одни и те же авторы комментариев это говорит о том, что это активные пользователи? Может, мы сможем, как-то обратить их внимание и превратить в подписчиков/клиентов?
Собрав прежде базу данных, с YouTube, мы можем без проблем сделать выборку комментариев только с роликов с определенным нами тегом. Дальше можем отправить задание на рерайт с размещением в нужном месте (или поручить сам постинг Зеннопостеру).
Сбор комментариев на YouTube пригодится и тогда, когда нам нужно придумывать отзывы о товаре (выполняя прихоти заказчиков на фрилансе) - просто выборку с базы данных обратно берем по нужным тегам с условием длины не менее столько-то знаков.
А если нам на многих каналах попадаются одни и те же авторы комментариев это говорит о том, что это активные пользователи? Может, мы сможем, как-то обратить их внимание и превратить в подписчиков/клиентов?
Когда мы ведем какой-то сайт или блог для людей - то нам важно не только подавать текстовый материал, но и сопровождать его разными уникальными картинками и видео. Но самостоятельно записывать видео под каждую тему - это не всегда хорошо - да и не всегда имеет смысл.
В таком случае, возможно, было бы не плохо просто искать видео без описаний и тегов (благо у нас есть база данных с необходимой нам информацией) - и добавлять эти ролики себе в статьи - это повысит доверие поисковых систем к сайту/блогу.
Да и картинки уникальные получать не беда - ведь многие пользователи YouTube не заморачиваются рисованием превьюшек, и в качестве превью становится какой-то случайный кадр с видео. При желании на эту превьюшку можно просто добавить размытость и наложить крупный текст по центру - и уникальная картинка готова!
В таком случае, возможно, было бы не плохо просто искать видео без описаний и тегов (благо у нас есть база данных с необходимой нам информацией) - и добавлять эти ролики себе в статьи - это повысит доверие поисковых систем к сайту/блогу.
Да и картинки уникальные получать не беда - ведь многие пользователи YouTube не заморачиваются рисованием превьюшек, и в качестве превью становится какой-то случайный кадр с видео. При желании на эту превьюшку можно просто добавить размытость и наложить крупный текст по центру - и уникальная картинка готова!
Имея базу данных роликов с YouTube, мы можем делать выборки роликов по нужным нам тематикам и тегам, естественно, что мы можем выбирать самые популярные и самые понравившиеся ролики для пользователей.
А потом с помощью Зеннопостера мы можем скачивать, например, субтитры и, конечно же, потом проверять их на уникальность. После того, как проверили и убедилить в уникальности можно отдавать на рерайт/корректировку и наполнять свои сайты (хотя, думаю, что даже без рерайта и корректировки данные тексты должны попадать в индекс поисковых систем).
А потом с помощью Зеннопостера мы можем скачивать, например, субтитры и, конечно же, потом проверять их на уникальность. После того, как проверили и убедилить в уникальности можно отдавать на рерайт/корректировку и наполнять свои сайты (хотя, думаю, что даже без рерайта и корректировки данные тексты должны попадать в индекс поисковых систем).
Одно дело создавать автонаполняемые сайты, просто используя какие-то скрипты, которые парсят все что угодно, чисто с поиска YouTube. А уже совсем другое дело, когда мы собираем большое множество контента, вырезаем весь мусор, возможно синонимизируем описания и заголовки, и формируем уже более интересные сайтики (и да, никто не мешает еще и превьюшки маленько уникализировать Зеннопостером - уникальные картинки это хорошо для поисковых систем).
В сравнение с другими автонаполняемыми сайтами - данный подход позволит еще и комментировать ролики на наших сайтах - ведь материала в базе данных соберется вполне достаточно, чтобы оставлять только релевантные комментарии (благо Зеннопостер умеет постить хоть в WordPress, хоть в любой другой движок).
В сравнение с другими автонаполняемыми сайтами - данный подход позволит еще и комментировать ролики на наших сайтах - ведь материала в базе данных соберется вполне достаточно, чтобы оставлять только релевантные комментарии (благо Зеннопостер умеет постить хоть в WordPress, хоть в любой другой движок).
Для ведения групп главное контент. А где брать вирусный контент? Правильно! Пролайканные ролики или самые комментируемые ролики будут как раз в тему!
Тут вообще все предельно просто - создаем пачку групп типа "Котики улыбаются" и размещаем на автомате выборку по котикам. Создаем группу "Доберманы" - и у нас вагон как фоток (превьюшки к видео) и видео с Доберманами. И да, мы ведь можем с помощью Зеннопостера накладывать свои надписи на изображениях.
Сколько можно вести групп, к примеру, ВКонтакте с одного аккаунта? Но мы же не ищем легких путей, можем не брезговать и Фейсбуком и другими сетями.
Тут вообще все предельно просто - создаем пачку групп типа "Котики улыбаются" и размещаем на автомате выборку по котикам. Создаем группу "Доберманы" - и у нас вагон как фоток (превьюшки к видео) и видео с Доберманами. И да, мы ведь можем с помощью Зеннопостера накладывать свои надписи на изображениях.
Сколько можно вести групп, к примеру, ВКонтакте с одного аккаунта? Но мы же не ищем легких путей, можем не брезговать и Фейсбуком и другими сетями.
И вот, мы определились, что нам необходимо собирать общедоступную информацию с YouTube. И конечно мы можем просто самостоятельно сидеть и в браузере вручную нажимать поочередно комбинации клавиш Ctrl+C и Ctrl+V. Но на сколько, времени хватит нашего терпения? А сколько информации мы сможем таким способом собрать?
Можно выделить три способа получения информации и не важно, с какого сервиса мы будем её собирать, при этом они имеют свои особенности, положительные и отрицательные стороны. Давайте рассмотрим их подробнее и на одном из них остановимся для сбора общедоступной информации с YouTube.
Можно выделить три способа получения информации и не важно, с какого сервиса мы будем её собирать, при этом они имеют свои особенности, положительные и отрицательные стороны. Давайте рассмотрим их подробнее и на одном из них остановимся для сбора общедоступной информации с YouTube.
Когда мы просто открываем браузер, открываем страничку, на которой находится необходимая нам информация, выделяем фрагмент, потом копируем и вставляем, например, в блокнот - это и будет сбор информации в браузере. Этот процесс можно автоматизировать каким-либо автокликером (например, Tasker или АвтоКликЭкстрим) - но в таком случае мы уже не сможем пользоваться компьютером, так как автокликер просто заберет у нас мышку и будет выполнять поставленную задачу.
Чтобы как-то обеспечить многопоточность я когда-то просто устанавливал несколько виртуальных машин, и на каждой запускал одну копию (браузер + автокликер). Вот только такое решение по автоматизации сложно было переносить, потребляло много ресурсов - из-за чего страдала и скорость работы.
Дальше я уже научился использовать iMacros, и он мог бегать в браузере и собирать информацию. Вот только бывало так, что браузер подвисал, макрос прерывался с ошибкой, данные терялись. При этом данное решение уже можно было запускать в нескольких браузерах одновременно.
И когда я уже начал работать программой Зеннопостер, то большинство проблем пропало сразу - многопоточность поддерживается с коробки, возможность записывать информацию с многих потоков в один файл. Обработка ошибок и возможность наглядно проектировать логику шаблона. При этом есть возможность отключения отображения браузера (что экономит ресурсы) и отключения всех ненужных фишек браузера (загрузку стилей, флеш, аудио и видео).
Так как при сборе общедоступной информации с YouTube важна скорость получения данных и использование браузера не обязательно (нет каптчи и других защит) - то я буду писать шаблоны, которые не используют браузер.
Чтобы как-то обеспечить многопоточность я когда-то просто устанавливал несколько виртуальных машин, и на каждой запускал одну копию (браузер + автокликер). Вот только такое решение по автоматизации сложно было переносить, потребляло много ресурсов - из-за чего страдала и скорость работы.
Дальше я уже научился использовать iMacros, и он мог бегать в браузере и собирать информацию. Вот только бывало так, что браузер подвисал, макрос прерывался с ошибкой, данные терялись. При этом данное решение уже можно было запускать в нескольких браузерах одновременно.
И когда я уже начал работать программой Зеннопостер, то большинство проблем пропало сразу - многопоточность поддерживается с коробки, возможность записывать информацию с многих потоков в один файл. Обработка ошибок и возможность наглядно проектировать логику шаблона. При этом есть возможность отключения отображения браузера (что экономит ресурсы) и отключения всех ненужных фишек браузера (загрузку стилей, флеш, аудио и видео).
Так как при сборе общедоступной информации с YouTube важна скорость получения данных и использование браузера не обязательно (нет каптчи и других защит) - то я буду писать шаблоны, которые не используют браузер.
Браузер взаимодействует с сайтами посредством нескольких типов запросов, в частности POST и GET (есть и другие...). Когда мы открываем какую-то страничку - браузер отправляет серию запросов, загружая нужный нам контент, потом разные стили, скрипты, формы, рекламу, аналитику.
Так вот, когда мы сами отправляем в наших шаблонах целенаправленно запросы к сайту - то мы отправляем только запросы, на которые сайт выдает нам нужную информацию - ничего лишнего.
Таким образом, шаблоны на запросах работают намного стабильнее и быстрее (не нужно ждать програзки всех элементов, браузер ведь не используется).
Для сбора информации с помощью POST/GET запросов можно использовать разные специализированные парсеры, например Ccontent Downloader, А-Парсер, а можно к примеру с помощью скриптов VBA, JS, PHP, C# и даже можно напрямую парсить информацию в Google Table используя скрипты для данных таблиц. Но, тут нужно уже обладать знаниями программирования.
А у нас есть Зеннопостер – значит, мы можем построить себе парсер любой сложности, просто складывая кубики в логические цепочки. Из-за простоты построения решений и возможности сразу обработать необходимым образом полученные данные я с момента покупки Зеннопостера пишу сборщики информации только в данной программе.
Так вот, когда мы сами отправляем в наших шаблонах целенаправленно запросы к сайту - то мы отправляем только запросы, на которые сайт выдает нам нужную информацию - ничего лишнего.
Таким образом, шаблоны на запросах работают намного стабильнее и быстрее (не нужно ждать програзки всех элементов, браузер ведь не используется).
Для сбора информации с помощью POST/GET запросов можно использовать разные специализированные парсеры, например Ccontent Downloader, А-Парсер, а можно к примеру с помощью скриптов VBA, JS, PHP, C# и даже можно напрямую парсить информацию в Google Table используя скрипты для данных таблиц. Но, тут нужно уже обладать знаниями программирования.
А у нас есть Зеннопостер – значит, мы можем построить себе парсер любой сложности, просто складывая кубики в логические цепочки. Из-за простоты построения решений и возможности сразу обработать необходимым образом полученные данные я с момента покупки Зеннопостера пишу сборщики информации только в данной программе.
Большие сайты, такие как YouTube, Vk, FB и подобные предоставляют инструменты для разработчиков приложений - API. Это практически те же самые POST/GET запросы, только отправляются по четко определенным правилам.
На каждом сайте, который предоставляет API, есть техническая документация, в которой рассказывается о том, как использовать данные инструменты в своих приложениях (а свои приложения - это могут быть как свои сайты, мобильные приложения или даже шаблоны Зеннопостера).
Удобность использования инструментов для разработчиков в сравнении с обычными запросами в том, что в обычном запросе мы можем получить только то, что обычно отображается в браузере. А через API - мы можем получить, например, выборку сразу из 50 страниц всего одним запросом без лишнего мусора (в виде оформления).
Для работы с API необходимо получить ключ доступа. Этим ключем определяется, что нам можно делать, что нельзя. Также для каждого ключа определяется индивидуальное количество запросов в сутки, в час, в минуту - так называймая квота.
Как получить API ключ YouTube можно посмотреть здесь (видео). Именно этот ключик мы будем использовать дальше для наших шаблонов. Мне было достаточно одного ключа - но, в зависимости от целей можно получить несколько.
Хочу также отметить, что бывает такое, что часть информации мы не можем (не предусмотрено) получить с помощью API (на YouTube это количество зрителей на онлайн трансляции или, например, видео в разделе "В тренде"). В таком случае можно просто воспользоваться обычными POST/GET запросами.
В документации YouTube API v3 говорится о том, что мы можем получить общедоступную информацию (свойство) о любом ресурсе (под ресурсом подразумеваются каналы, видео, плейлисты) отправив обычный GET запрос, в котором будет указан ID ресурса (например, ID канала или видео), API KEY и группа свойств (список полей) которые желаем получить.
Пример из документации (основная ссылка:
Данным запросом мы и будем пользоваться в разных вариациях для получения общедоступных данных с YouTube.
На каждом сайте, который предоставляет API, есть техническая документация, в которой рассказывается о том, как использовать данные инструменты в своих приложениях (а свои приложения - это могут быть как свои сайты, мобильные приложения или даже шаблоны Зеннопостера).
Удобность использования инструментов для разработчиков в сравнении с обычными запросами в том, что в обычном запросе мы можем получить только то, что обычно отображается в браузере. А через API - мы можем получить, например, выборку сразу из 50 страниц всего одним запросом без лишнего мусора (в виде оформления).
Для работы с API необходимо получить ключ доступа. Этим ключем определяется, что нам можно делать, что нельзя. Также для каждого ключа определяется индивидуальное количество запросов в сутки, в час, в минуту - так называймая квота.
Как получить API ключ YouTube можно посмотреть здесь (видео). Именно этот ключик мы будем использовать дальше для наших шаблонов. Мне было достаточно одного ключа - но, в зависимости от целей можно получить несколько.
Хочу также отметить, что бывает такое, что часть информации мы не можем (не предусмотрено) получить с помощью API (на YouTube это количество зрителей на онлайн трансляции или, например, видео в разделе "В тренде"). В таком случае можно просто воспользоваться обычными POST/GET запросами.
В документации YouTube API v3 говорится о том, что мы можем получить общедоступную информацию (свойство) о любом ресурсе (под ресурсом подразумеваются каналы, видео, плейлисты) отправив обычный GET запрос, в котором будет указан ID ресурса (например, ID канала или видео), API KEY и группа свойств (список полей) которые желаем получить.
Пример из документации (основная ссылка:
HTML:
https://www.googleapis.com/youtube/v3/videos?id=ID_VIDEO&key=YOUR_API_KEY )
&part=snippet,contentDetails,statistics,status
&part=snippet,statistics
&part=snippet,statistics&fields=items(id,snippet,statistics)
&fields=items(id,snippet(channelId,title,categoryId),statistics)&part=snippet,statisticsКогда я пишу шаблон для Зеннопостера, то мне важно понимать что я буду использовать в процессе работы. Я точно знаю, что буду писать парсер в Project Maker, в основном буду использовать пост/гет запросы и API v3 – значит, понадобится ключик YouTube API v3. А вот с сохранением результатов необходимо определиться. У меня есть несколько вариантов, которые я могу без проблем использовать:
jpg могут использоваться для создания видео например с помощью кодека ffmpeg с подальшей заливкой на YouTube.
Так как информации о работе Зеннопостером в комплексе с базами данных столько, что на пальцах можно подсчитать материалы - то думаю, будет полезно описать работу шаблонов именно с базой данных.
- Шаблон Зеннопостер + txt файлы
- Шаблон Зеннопостер + csv файлы
- Шаблон Зеннопостер + excel файлы
- Шаблон Зеннопостер + html файлы
- Шаблон Зеннопостер + pdf файлы
- Шаблон Зеннопостер + jpg файлы
jpg могут использоваться для создания видео например с помощью кодека ffmpeg с подальшей заливкой на YouTube.
- Шаблон Зеннопостер + база данных MySQL
Так как информации о работе Зеннопостером в комплексе с базами данных столько, что на пальцах можно подсчитать материалы - то думаю, будет полезно описать работу шаблонов именно с базой данных.
На YouTube нет какого-то конкретного топа или рейтинга каналов, куда бы мы могли зайти, и просто собрать весь список - после чего уже переходить к анализу данных. Так что нам необходимо определиться с точкой, от которой мы будем начинать наш сбор общедоступной информации с YouTube.
Так как первая моя цель - это анализ собственного канала - именно его я устанавливаю в качестве точки СТАРТ в моих шаблонах. И логика сбора будет примерно следующая - получил информацию о канале, потом получил информацию о роликах. Потом получил комментарии и добавил владельцев комментариев в базу данных. Потом получаю информацию о комментаторе, получаю список его видео и информацию. Получаю комментаторов, и цикл повторяется.
Думаю это не особо правильная стратегия, так как владельцы каналов миллионников очень редко оставляют комментарии и таким образом они могут просто не попасть в нашу базу данных - тут нужно выбрать какую-то другую стратегию пополнения базы новыми каналами.
Второй источник пополнения базы данных новыми каналами – это, к примеру, парсинг сервиса socialblade.com - там уже есть готовая информация, которую нужно только собрать, а уже отработать по цепочке описанной выше. С другой стороны рассчитывать только на данный сервис нельзя - так как в таком случае можно отбросить львиную долю маленьких каналов.
Третья стратегия пополнения базы данных новыми каналами - это создание шаблона, который каждых несколько минут отправлял бы запрос на страничку "В Тренде" с разных IP (выдача с разных стран отличается) и получал бы оттуда список каналов, после чего добавлял бы их в базу и дальше эти каналы обрабатывались бы по цепочке.
Можно придумать какие-то другие схемы - и я уверен, что вам это получится лучше, чем мне! А я выбрал для себя первую и пока не расширял количество шаблонов - нет пока экстерной необходимости в этом.
Так как первая моя цель - это анализ собственного канала - именно его я устанавливаю в качестве точки СТАРТ в моих шаблонах. И логика сбора будет примерно следующая - получил информацию о канале, потом получил информацию о роликах. Потом получил комментарии и добавил владельцев комментариев в базу данных. Потом получаю информацию о комментаторе, получаю список его видео и информацию. Получаю комментаторов, и цикл повторяется.
Думаю это не особо правильная стратегия, так как владельцы каналов миллионников очень редко оставляют комментарии и таким образом они могут просто не попасть в нашу базу данных - тут нужно выбрать какую-то другую стратегию пополнения базы новыми каналами.
Второй источник пополнения базы данных новыми каналами – это, к примеру, парсинг сервиса socialblade.com - там уже есть готовая информация, которую нужно только собрать, а уже отработать по цепочке описанной выше. С другой стороны рассчитывать только на данный сервис нельзя - так как в таком случае можно отбросить львиную долю маленьких каналов.
Третья стратегия пополнения базы данных новыми каналами - это создание шаблона, который каждых несколько минут отправлял бы запрос на страничку "В Тренде" с разных IP (выдача с разных стран отличается) и получал бы оттуда список каналов, после чего добавлял бы их в базу и дальше эти каналы обрабатывались бы по цепочке.
Можно придумать какие-то другие схемы - и я уверен, что вам это получится лучше, чем мне! А я выбрал для себя первую и пока не расширял количество шаблонов - нет пока экстерной необходимости в этом.
Когда мы определились с способом сбора общедоступной информации с YouTube и наш выбор остановился на работе с API - то как раз пришло время подумать над тем, как мы будем осуществлять данную работу.
Прежде всего, нам нужно закопаться в техническую документацию YouTube для разработчиков и найти там те запросы, которые будут выдавать нам необходимый результат.
После чего полученный результат необходимо будет разобрать регулярными выражениями по переменных (либо сразу в списки и таблицы).
Когда информация уже содержится в переменных, мы можем сформировать запрос на добавление этих данных в базу данных. И вот здесь мы обнаружили, что базы данных у нас еще нет - значит, придется спроектировать базу данных, и уже потом вернуться к данному шагу.
Нельзя также забывать о том, что в процессе работы у нас могут появляться различные ошибки. Да и вообще, не только ошибки, например, на канале нет видео - как мы его будем добавлять в базу? Или, например, для данного ролика нет комментариев, не отправлять же запрос в базу данных?
Не замысловатый план действий, не так ли? И все же предлагаю остановиться на данных пунктах подробнее.

Если вы остановились на хранении и работе с данными с помощью базы данных - то можете себя поздравить, вы подписали себя как минимум на базовое изучение SQL. С одной стороны в данном языке нет ничего сложного, ведь по большому счету нужно всего лишь знать как добавить, как получить, как обновить, как сортировать и как групировать данные, а еще стоит ли в конце строки ставить точку с запятой или нет. Но с другой стороны я сам около года откладывал приспособление баз данных к Зеннопостеру и все мучился с списками и таблицами и их пересечениями.
Так вот сейчас я могу сказать, что для создания базы данных для хранения данных которые будут собирать мои шаблоны с YouTube используя APIv3 мне понадобилось знать всего лишь где читать справку по MySQL.
Конечно же, что еще я четко определился с тем какие данные я буду хранить в базе, какие служебные поля я буду создавать для работы Зеннопостера в многопоточном режиме, как я вообще буду создавать эту базу данных если вдруг мне придется кому-то передать шаблоны, и самое важное какие запросы я буду отправлять к базе данных и с какой целью.
Сейчас я попытаюсь обяснить суть всех этих вопросов.
Прежде всего, нам нужно закопаться в техническую документацию YouTube для разработчиков и найти там те запросы, которые будут выдавать нам необходимый результат.
После чего полученный результат необходимо будет разобрать регулярными выражениями по переменных (либо сразу в списки и таблицы).
Когда информация уже содержится в переменных, мы можем сформировать запрос на добавление этих данных в базу данных. И вот здесь мы обнаружили, что базы данных у нас еще нет - значит, придется спроектировать базу данных, и уже потом вернуться к данному шагу.
Нельзя также забывать о том, что в процессе работы у нас могут появляться различные ошибки. Да и вообще, не только ошибки, например, на канале нет видео - как мы его будем добавлять в базу? Или, например, для данного ролика нет комментариев, не отправлять же запрос в базу данных?
Не замысловатый план действий, не так ли? И все же предлагаю остановиться на данных пунктах подробнее.
Для работы с общедоступными данными YouTube через API v3 мы должны прежде всего получить ключ (видеоинструкция получения API KEY YouTube
) и сохранить его себе в переменную, после чего подставлять переменную в запросах, которые его требуют. Хранить ключ я буду в переменной {-Variable.api_key-}.
Также нам понадобится идентификатор ресурса (например, ИД канала, ИД плейлиста или ИД видео). Например если мы работаем только с одним каналом - то ИД канала мы можем задать в входящих настройках. ИД плейлиста мы получим в результате получения информации о канале, а уже ИД видео получим в результате выполнения запроса на получение списка видео с плейлиста.
Также нам понадобится идентификатор ресурса (например, ИД канала, ИД плейлиста или ИД видео). Например если мы работаем только с одним каналом - то ИД канала мы можем задать в входящих настройках. ИД плейлиста мы получим в результате получения информации о канале, а уже ИД видео получим в результате выполнения запроса на получение списка видео с плейлиста.
И так, для первого запроса, который будет возвращать информацию о канале, ИД канала я буду хратить в переменной: {-Variable.id_channel-}, а API KEY YouTube в переменной: {-Variable.api_key-}.
Отправив обычный GET запрос, я смогу получить необходимую мне информацию о канале и сохранить результат, например в переменную {-Variable.get-}.
Кстати, при желании я могу таким образом получить информацию о нескольких каналах, указав ИД каналов в запросе через запятую.
Запрос
Отправив обычный GET запрос, я смогу получить необходимую мне информацию о канале и сохранить результат, например в переменную {-Variable.get-}.
Кстати, при желании я могу таким образом получить информацию о нескольких каналах, указав ИД каналов в запросе через запятую.
Запрос
Код:
https://www.googleapis.com/youtube/v3/channels?part=id,snippet,statistics,contentDetails,brandingSettings,contentOwnerDetails&id={-Variable.id_channel-}&key={-Variable.api_key-}После получения информации о выбранном канале среди разных прочих параметров есть такой:
В нем хранятся все загруженные на канал видео. Именно данный идентификатор мы и будем использовать в текущем запросе и хранить его будем в переменной {-Variable.uploads-}.
Вот только есть каналы на которых 10 видео, а есть у которых 10 000 видео. Так вот, если в плейлисте находится много роликов, то при запросе мы получим только первую страничку с роликами (максимально 50 роликов за раз). Но результат выполнения запроса будет содержать еще и токен на вторую страничку с роликами. Таким образом первый запрос мы будем отправлять без токена, а если после выполнения запроса токен обнаружен - будем пытаться получить следующую страничку с видео. Токен сохраним в переменную {-Variable.token_list_video-}.
Собственно пришли мы к тому, что у нас будет два разных запроса, которые будут возвращать примерно одинаковый результат (за исключением самих роликов).
Запрос с токеном
Запрос без токена
Код:
"uploads": "UUGVQdcoALJ_YoNOy_TtJWMQ"Вот только есть каналы на которых 10 видео, а есть у которых 10 000 видео. Так вот, если в плейлисте находится много роликов, то при запросе мы получим только первую страничку с роликами (максимально 50 роликов за раз). Но результат выполнения запроса будет содержать еще и токен на вторую страничку с роликами. Таким образом первый запрос мы будем отправлять без токена, а если после выполнения запроса токен обнаружен - будем пытаться получить следующую страничку с видео. Токен сохраним в переменную {-Variable.token_list_video-}.
Собственно пришли мы к тому, что у нас будет два разных запроса, которые будут возвращать примерно одинаковый результат (за исключением самих роликов).
Запрос с токеном
Код:
https://www.googleapis.com/youtube/v3/playlistItems?part=snippet&playlistId={-Variable.uploads-}&maxResults=50&key={-Variable.api_key-}&pageToken={-Variable.token_list_video-}
Код:
https://www.googleapis.com/youtube/v3/playlistItems?part=snippet&playlistId={-Variable.uploads-}&maxResults=50&key={-Variable.api_key-}И вот, после получения списка роликов мы можем встретить параметр "videoId": "4AQ9UamPN6E" который отвечает за ИД видео. Имея данный параметр мы уже можем обратиться к API Youtube за возвратом дополнительной информации о ролике. Хранить данный параметр я буду в переменной {-Variable.id_video_table-}. И в результате выполнения запроса буду получать подробную информацию о ролике.
Запрос
Запрос
Код:
https://www.googleapis.com/youtube/v3/videos?id={-Variable.id_video_table-}&part=id,snippet,status,statistics&key={-Variable.api_key-}И последний запрос который нам понадобится - это запрос, который будет получать комментарии к видео. Для получения комментариев будет использоваться тот же ИД видео, который использовался в предыдущем запросе. Вы можете спросить конечно, почему мы эти данные не собрали сразу? Все просто - есть ролики у которых по 100 000 комментариев. Если зациклить это в одном шаблоне - то мы будем собирать только комментарии - а нам ведь базу данных нужно наполнять более-менее равномерно.
Так как комментарии мы также будем получать по несколько штук одновременно, то обратно будем использовать два запроса - один с токеном, другой - без токена. Это позволит естественно ускорить процесс парсинга информации.
Запрос без токена
Запрос с токеном
Так как комментарии мы также будем получать по несколько штук одновременно, то обратно будем использовать два запроса - один с токеном, другой - без токена. Это позволит естественно ускорить процесс парсинга информации.
Запрос без токена
Код:
https://www.googleapis.com/youtube/v3/commentThreads?part=snippet,replies&videoId={-Variable.id_video_comment-}&key={-Variable.api_key-}&maxResults=100&textFormat=plainText
Код:
https://www.googleapis.com/youtube/v3/commentThreads?part=snippet,replies&videoId={-Variable.id_video_comment-}&key={-Variable.api_key-}&maxResults=100&textFormat=plainText&pageToken={-Variable.token_list_comment-}В результате выполнения наших GET запросов к API YouTube мы получим масив данных о канале, плейлисте, видео, комментариях в формате JSON. Зеннопостер конечно умеет работать с данными JSON, вот только мне удобнее работать регулярными выражениями - но уверен, что при необходимости вы сможете переписать себе решение с использованием этого нового инструмента в Зеннопостере.
Так как данных будет много, то использование стандартных кубиков приведет к увеличению шаблона (как следствие - сложнее разобраться, что и как работает и где допустил ошибку). Из-за чего я решил использовать сниппеты и общий код.
Так как данных будет много, то использование стандартных кубиков приведет к увеличению шаблона (как следствие - сложнее разобраться, что и как работает и где допустил ошибку). Из-за чего я решил использовать сниппеты и общий код.
Впринципе, общий код конечно можно не использовать, и дублировать каждый раз код в сниппете в необходимом месте, но, как и со стандартными кубиками (экшинами) я решил, что вынесу основную функцию сюда, а с сниппетов буду просто вызывать метод и получать сразу готовый результат.
Данный фрагмент кода принимает на вход строку. Проверяет пустая ли она и если да, то заменяет нулевым значением и удаляет кавычки.
Данный фрагмент кода принимает две строки (в одной текст в котором будем искать что-либо, во второй - регулярное выражение) и на выходе возвращает либо ноль (если ничего не найдено) либо результат поиска по данному регулярному выражению.
Данный фрагмент кода принимает на вход строку. Проверяет пустая ли она и если да, то заменяет нулевым значением и удаляет кавычки.
Код:
public static string Ziro (string x) {
if(string.IsNullOrEmpty(x)) x = "0";
x=x.Replace("\'","").Replace("\"","").Trim();
return x.ToString();
}
Код:
public static string re (string text, string reg) {
var rez = new System.Text.RegularExpressions.Regex(@reg);
var rezult= rez.Match(text);
if (rezult.Success) {
return rezult.Value.Trim();
}
else {
return "0";
}
}Чтобы работать в сниппете с данными необходимо создать переменные, в которых будут храниться регулярные выражения, которые будут использованы для извлечения необходимых данных, да и переменные в которых будет храниться результат. Приведу пример на первом шаблоне (в остальных все сделано практически по аналогии):
Таким образом, все необходимые регулярные выражения находятся в одном месте, и в случае необходимости можно быстро изменить их. Чтобы понимать, что в данной переменной хранится регулярное выражение, я в названии переменной использовал приставку re_.
Код:
// Забрасываю результат нашего запроса в переменную
var parse = project.Variables["get"].Value;
// Создаю переменные, которые содержат регулярные выражения
string re_json = @"""kind""[\w\W]*?000Z""\s+}";
string re_featuredChannelsUrls = @"(?<=""featuredChannelsUrls"": "").*?(?="")";
string re_id = @"(?<=""id"": "").*(?="")";
string re_title = @"(?<=""title"": "").*(?="")";
string re_description = @"(?<=""description"": "").*(?="")";
string re_customUrl = @"(?<=""customUrl"": "").*(?="")";
string re_publishedAt = @"(?<=""publishedAt"": "").*(?="")";
string re_url = @"(?<=""url"": "").*(?="")";
string re_uploads = @"(?<=""uploads"": "").*(?="")";
string re_likes = @"(?<=""likes"": "").*(?="")";
string re_favorites = @"(?<=""favorites"": "").*(?="")";
string re_viewCount = @"(?<=""viewCount"": "").*(?="")";
string re_commentCount = @"(?<=""commentCount"": "").*(?="")";
string re_subscriberCount = @"(?<=""subscriberCount"": "").*(?="")";
string re_hiddenSubscriberCount = @"(?<=""hiddenSubscriberCount"": "").*(?="")";
string re_videoCount = @"(?<=""videoCount"": "").*(?="")";
string re_showRelatedChannels = @"(?<=""showRelatedChannels"": "").*(?="")";
string re_featuredChannelsTitle = @"(?<=""featuredChannelsTitle"": "").*(?="")";
string re_Count = @"(?<=""Count"": "").*(?="")";
string re_unsubscribedTrailer = @"(?<=""unsubscribedTrailer"": "").*(?="")";
string re_profileColor = @"(?<=""profileColor"": "").*(?="")";
string re_bannerTvHighImageUrl = @"(?<=""bannerTvHighImageUrl"": "").*(?="")";Таким образом, все необходимые регулярные выражения находятся в одном месте, и в случае необходимости можно быстро изменить их. Чтобы понимать, что в данной переменной хранится регулярное выражение, я в названии переменной использовал приставку re_.
Код:
// Создаю переменные, которые должны хранить результат поска по регулярному выражению
string id = String.Empty;
string title = String.Empty;
string description = String.Empty;
string customUrl = String.Empty;
string publishedAt = String.Empty;
string url = String.Empty;
string uploads = String.Empty;
string likes = String.Empty;
string favorites = String.Empty;
string viewCount = String.Empty;
string commentCount = String.Empty;
string subscriberCount = String.Empty;
string hiddenSubscriberCount = String.Empty;
string videoCount = String.Empty;
string showRelatedChannels = String.Empty;
string featuredChannelsTitle = String.Empty;
string Count = String.Empty;
string unsubscribedTrailer = String.Empty;
string profileColor = String.Empty;
string bannerTvHighImageUrl = String.Empty;Дальше осталось получить результат в созданные переменные:
Переменной id присваиваю результат вызова метода re который создал в общем коде, в который передаю содержимое переменной результата запроса к API и регулярное выражение. Метод вернет готовый результат, обрезав пробелы вначале и вконце строки и если ничего не обнаружит - вернет ноль.
Аналогичным образом получаю результат для всех остальных необходимых мне переменных.
Так как список подобных каналов это несколько значений одного и того же поля ИД канала - то я решил его забросить сразу в список для дальнейшего добавления в базу данных.
Переменной id присваиваю результат вызова метода re который создал в общем коде, в который передаю содержимое переменной результата запроса к API и регулярное выражение. Метод вернет готовый результат, обрезав пробелы вначале и вконце строки и если ничего не обнаружит - вернет ноль.
Код:
id = CommonCode.re(parse, re_id);
Код:
title = CommonCode.re(parse, re_title);
description = CommonCode.re(parse, re_description);
customUrl = CommonCode.re(parse, re_customUrl);
publishedAt = CommonCode.re(parse, re_publishedAt);
url = CommonCode.re(parse, re_url);
uploads = CommonCode.re(parse, re_uploads);
likes = CommonCode.re(parse, re_likes);
favorites = CommonCode.re(parse, re_favorites);
viewCount = CommonCode.re(parse, re_viewCount);
commentCount = CommonCode.re(parse, re_commentCount);
subscriberCount = CommonCode.re(parse, re_subscriberCount);
hiddenSubscriberCount = CommonCode.re(parse, re_hiddenSubscriberCount);
videoCount = CommonCode.re(parse, re_videoCount);
showRelatedChannels = CommonCode.re(parse, re_showRelatedChannels);
featuredChannelsTitle = CommonCode.re(parse, re_featuredChannelsTitle);
Count = CommonCode.re(parse, re_Count);
unsubscribedTrailer = CommonCode.re(parse, re_unsubscribedTrailer);
profileColor = CommonCode.re(parse, re_profileColor);
bannerTvHighImageUrl = CommonCode.re(parse, re_bannerTvHighImageUrl);
Код:
// Беру список подобных каналов если такие есть
var regex = new Regex(re_featuredChannelsUrls);
var zp_list = project.Lists["Каналы"];
regex.Matches(parse).Cast<Match>().ToList().ForEach(m=>zp_list.Add(m.Value));Для добавления данных в базу я буду использовать запрос
Данный запрос позволяет добавлять в базу данные, при чем обнаруживая дубликат база данных автоматически обновит все значения полей новыми данными (что позволит не дублировать данные в базе).
Собственно формирование запроса будет сводиться к тому, чтобы сформировать строку с значениями в виде: ("val", "val", ..., "val") - это я и сделаю сразу же после разбора результата по переменных.
Конечно можно было сделать по другому - прежде получить ИД канала с базы - и если получили - тогда отправлять запрос на обновление данных, а если ничего не получили - тогда добавлять. Но, использование данного запроса мне показалось более корректным (хотя, я могу ошибаться).
SQL:
INSERT INTO table(field,field..field)
VALUES ("val", "val", ..., "val")
ON DUPLICATE KEY UPDATE val=VALUES(val),
val=VALUES(val),..,val=VALUES(val)Собственно формирование запроса будет сводиться к тому, чтобы сформировать строку с значениями в виде: ("val", "val", ..., "val") - это я и сделаю сразу же после разбора результата по переменных.
Код:
string z = "\", \"";
project.Variables["query_channel_info"].Value = "(\""
+id + z
+title + z
+description + z
+customUrl + z
+publishedAt+ z
+url + z
+uploads + z
+likes + z
+favorites + z
+viewCount + z
+commentCount + z
+subscriberCount + z
+hiddenSubscriberCount + z
+videoCount + z
+showRelatedChannels + z
+featuredChannelsTitle + z
+Count + z
+unsubscribedTrailer + z
+profileColor + z
+bannerTvHighImageUrl + "\")";После подготовки данных для добавления в базу данных необходимо сформировать сам запрос, который будет отправлен для добавления данных. Как я уже выше написал - использоваться будет запрос:
Но, кто не работал с базой данных возможно ничего не понял и не представляет как будет выглядеть данный запрос. Специально для этого копирую содержимое запроса, который использую я в одном шаблоне (по аналогии и в других только поля таблицы базы данных отличаются).
В данном случае в переменной {- Variable.query_channel_info -} будут находиться данные сформированные зарание в ввиде ("val", "val", ..., "val").
Так как база данных нам ничего возвращать не должна - то установим тип запроса в экшине Без ответа - и после выполнения запроса в переменную получим количество добавленных строк в базу данных (при желании можно будет относительно этого каким-то образом строить логику).
SQL:
INSERT INTO... ON DUPLICATE KEY UPDATE
SQL:
INSERT INTO channel (channel.id,
channel.title,
channel.description,
channel.customUrl,
channel.publishedAt,
channel.thumbnails_high_url,
channel.relatedPlaylists_uploads,
channel.relatedPlaylists_likes,
channel.0x300relatedPlaylists.favorites0x300,
channel.viewCount,
channel.commentCount,
channel.subscriberCount,
channel.hiddenSubscriberCount,
channel.videoCount,
channel.showRelatedChannels,
channel.featuredChannelsTitle,
channel.featuredChannelsUrls_Count,
channel.unsubscribedTrailer,
channel.profileColor,
channel.bannerTvHighImageUrl)
VALUES {- Variable.query_channel_info -}
ON DUPLICATE KEY UPDATE
channel.title=VALUES(channel.title),
channel.description=VALUES(channel.description),
channel.customUrl=VALUES(channel.customUrl),
channel.publishedAt=VALUES(channel.publishedAt),
channel.thumbnails_high_url=VALUES(channel.thumbnails_high_url),
channel.relatedPlaylists_uploads=VALUES(channel.relatedPlaylists_uploads),
channel.relatedPlaylists_likes=VALUES(channel.relatedPlaylists_likes),
channel.0x300relatedPlaylists.favorites0x300=VALUES(channel.0x300relatedPlaylists.favorites0x300),
channel.viewCount=VALUES(channel.viewCount),
channel.commentCount=VALUES(channel.commentCount),
channel.subscriberCount=VALUES(channel.subscriberCount),
channel.hiddenSubscriberCount=VALUES(channel.hiddenSubscriberCount),
channel.videoCount=VALUES(channel.videoCount),
channel.showRelatedChannels=VALUES(channel.showRelatedChannels),
channel.featuredChannelsTitle=VALUES(channel.featuredChannelsTitle),
channel.featuredChannelsUrls_Count=VALUES(channel.featuredChannelsUrls_Count),
channel.unsubscribedTrailer =VALUES(channel.unsubscribedTrailer),
channel.profileColor =VALUES(channel.profileColor),
channel.bannerTvHighImageUrl=VALUES(channel.bannerTvHighImageUrl);Так как база данных нам ничего возвращать не должна - то установим тип запроса в экшине Без ответа - и после выполнения запроса в переменную получим количество добавленных строк в базу данных (при желании можно будет относительно этого каким-то образом строить логику).
Если мы научились собирать информацию, но не определились, куда мы её будем сохранять (и будем ли сохранять вообще) - то это говорит о том, что еще не вся миссия выполнена.
Есть несколько вариантов, которые можно использовать для сохранения данных - это таблицы, списки, облако и базы данных. Нет, я не говорю что мы не можем формировать html документы и сразу же заливать по FTP на хостинги либо сразу через API BLOGGER на блоги или как уже описывали другие участники форума на фрихосты и блоги WordPress - это все можно и даже нужно по необходимости.
Только обычно получается так - собрали мы информацию. Провели анализ этих данных, сделали для себя выборку только необходимых данных - все остальное удалили и продолжили работать уже с узконаправленным количеством материала.
Впринципе я для себя определился, что буду работать с базой данных MySQL - но описание возможных вариантов я все же предоставлю (мало ли, вдруг кому-то пригодится).
Есть несколько вариантов, которые можно использовать для сохранения данных - это таблицы, списки, облако и базы данных. Нет, я не говорю что мы не можем формировать html документы и сразу же заливать по FTP на хостинги либо сразу через API BLOGGER на блоги или как уже описывали другие участники форума на фрихосты и блоги WordPress - это все можно и даже нужно по необходимости.
Только обычно получается так - собрали мы информацию. Провели анализ этих данных, сделали для себя выборку только необходимых данных - все остальное удалили и продолжили работать уже с узконаправленным количеством материала.
Впринципе я для себя определился, что буду работать с базой данных MySQL - но описание возможных вариантов я все же предоставлю (мало ли, вдруг кому-то пригодится).
Сохранение полученных данных в таблицу возможно очень даже просто - так как в переменных у нас уже есть данные - то мы можем допустим сформировать строку с разделителями, после чего добавить эту строку в таблицу хоть стандартным экшином, что и сниппетом, например таким:
Возможно такой вариант при работе с одним или десятком каналов будет более предпочтительным, но при большом количестве данных работать с таблицами не очень удобно.
Код:
//таблица, в которую сохранять результат
var table= project.Tables["table"];
//var строка, подготовленная для добавления в таблицу
table.AddRow(var);Сохранение полученных данных в список возможно очень даже просто, как и с сохранением в таблицу - так как в переменных у нас уже есть данные - то мы можем, допустим, сформировать строку с разделителями, после чего добавить эту строку в список хоть стандартным экшином, что и сниппетом, например таким:
Возможно, такой вариант при работе с одним или десятком каналов будет более предпочтительным, аналогично, как и с сохранением данных в обычную таблицу, но при большом количестве данных работать со списками не очень удобно.
Код:
//список, в который будем сохранять результат
var list = project.project.Lists["list"];
list.Add(var); //var строка, подготовленная для добавления в списокМожно не доверять локальным файлам, и отправлять запросами данные например в таблицы Google. Естественно, что это достаточно удобный вариант, так как на компьютере тогда ничего не сохраняется - результат в любой момент можно посмотреть с любого устройства. Я когда-то именно так и делал. Как сохранять данные в таблицы запросами можно посмотреть в видео:
... и адаптировать под свои конкретные нужды.
Вот только проблемой таких таблицы (для меня) является сам факт, что хранить в них можно только 2 000 000 ячеек. Это в свою очередь говорит что при парсинге данных нам придется очень часто менять эти таблицы. Да, как вариант просто хранить в каждой отдельной таблице информацию об одном канале (но в таком случае если на канале 100 000 видео всеравно придется делать несколько таблиц).
Вот только проблемой таких таблицы (для меня) является сам факт, что хранить в них можно только 2 000 000 ячеек. Это в свою очередь говорит что при парсинге данных нам придется очень часто менять эти таблицы. Да, как вариант просто хранить в каждой отдельной таблице информацию об одном канале (но в таком случае если на канале 100 000 видео всеравно придется делать несколько таблиц).
Наиболее предпочтительным для сохранения результата я выбрал базу данных MySQL ( http://zennolab.com/discussion/threads/primer-proektirovanija-bazy-dannyx-mysql-dlja-raboty-s-shablonami-zennopostera.35715/ ). Дело в том, что с одной стороны количество данных, которые будут собираться со временем, будет просто огромным (40ГБ+) и никакие текстовые файлы и таблицы Excel с этим не справлятся.
С другой стороны база данных у меня установлена на выделенном сервере, и ничего не мешает взять её за основу создания, например миллиона автонаполняемых сайтов с видео (каждому сайту, к примеру, один канал на YouTube). При этом с базы данных очень просто получить выборку данных по различным параметрам (например, получить только ролики пользователей, у которых меньше 1000 подписчиков, но видео с количеством просмотров более 100 000 и при этом чтобы количество лайков на видео было не меньше 10 000 и дизлайков не больше 1000), а вот такую выборку сделать из списков/таблиц я считаю, будет более проблематично.
С другой стороны база данных у меня установлена на выделенном сервере, и ничего не мешает взять её за основу создания, например миллиона автонаполняемых сайтов с видео (каждому сайту, к примеру, один канал на YouTube). При этом с базы данных очень просто получить выборку данных по различным параметрам (например, получить только ролики пользователей, у которых меньше 1000 подписчиков, но видео с количеством просмотров более 100 000 и при этом чтобы количество лайков на видео было не меньше 10 000 и дизлайков не больше 1000), а вот такую выборку сделать из списков/таблиц я считаю, будет более проблематично.
Если вы остановились на хранении и работе с данными с помощью базы данных - то можете себя поздравить, вы подписали себя как минимум на базовое изучение SQL. С одной стороны в данном языке нет ничего сложного, ведь по большому счету нужно всего лишь знать как добавить, как получить, как обновить, как сортировать и как групировать данные, а еще стоит ли в конце строки ставить точку с запятой или нет. Но с другой стороны я сам около года откладывал приспособление баз данных к Зеннопостеру и все мучился с списками и таблицами и их пересечениями.
Так вот сейчас я могу сказать, что для создания базы данных для хранения данных которые будут собирать мои шаблоны с YouTube используя APIv3 мне понадобилось знать всего лишь где читать справку по MySQL.
Конечно же, что еще я четко определился с тем какие данные я буду хранить в базе, какие служебные поля я буду создавать для работы Зеннопостера в многопоточном режиме, как я вообще буду создавать эту базу данных если вдруг мне придется кому-то передать шаблоны, и самое важное какие запросы я буду отправлять к базе данных и с какой целью.
Сейчас я попытаюсь обяснить суть всех этих вопросов.
Когда я принял решение собирать данные на YouTube, я знал что мне необходимо знать, кто ведет канал, сколько у него роликов, сколько просмотров и когда зарегистрирован канал. Но, когда я уже обратился через API к YouTube - то увидел, что он предоставляет по каналу дополнительные данные, которые я также решил сохранить. Итого - сам канал оброс огромным количеством параметров (кто знает, вдруг в будущем пригодятся).
Дальше уже каждый канал имеет свои плейлисты - при необходимости наверно было бы правильно их собирать, но, я подумал, что это для меня не слишком важно - и ограничился плейлистом, в котором хранятся все загруженные ролики автора канала (которые есть в публичном доступе естественно). Но, если плейлист один - то выделять для него отдельную табличку было бы слишком жирно - из-за чего оставил я его в табличке пользователя.
Дальше я решил собрать информацию о самих видео. И когда уже обратился к YouTube, то увидел огромное количество информации - естественно я решил её сохранить. В частном случае это теги, которые автор видео указывает, чтобы его ролик смогли найти зрители. Так как роликов в интернете много, то я предположил, что в некоторых роликах теги будут дублироваться. А значит - сохранять копии тегов было бы не правильно.
Из-за этого я вынес все теги в отдельную табличку, и создал таблицу, которая уже хранит только номер тега и номер видео. Одно что я забыл сделать в этой базе данных - так это связать теги с видео и каналами - но возможно, если продолжу работать над этим проектом - переделаю.
Дальше уже каждый канал имеет свои плейлисты - при необходимости наверно было бы правильно их собирать, но, я подумал, что это для меня не слишком важно - и ограничился плейлистом, в котором хранятся все загруженные ролики автора канала (которые есть в публичном доступе естественно). Но, если плейлист один - то выделять для него отдельную табличку было бы слишком жирно - из-за чего оставил я его в табличке пользователя.
Дальше я решил собрать информацию о самих видео. И когда уже обратился к YouTube, то увидел огромное количество информации - естественно я решил её сохранить. В частном случае это теги, которые автор видео указывает, чтобы его ролик смогли найти зрители. Так как роликов в интернете много, то я предположил, что в некоторых роликах теги будут дублироваться. А значит - сохранять копии тегов было бы не правильно.
Из-за этого я вынес все теги в отдельную табличку, и создал таблицу, которая уже хранит только номер тега и номер видео. Одно что я забыл сделать в этой базе данных - так это связать теги с видео и каналами - но возможно, если продолжу работать над этим проектом - переделаю.
Собственно что я подразумеваю под служебными полями? Допустим, работает у нас шаблон. Если он работает без базы данных, то он берет из списка первую строчку, удаляет её и сохраняе в конец списка. Так обеспечивается многопоточность.
Так вот для работы с базой данных данный момент я реализовал таким способом - добавил поле STATUS, в котором хранится значение занятости строчки (0,1,2,3...). И добавил поле TIMESTAMP в котором хранится дата и время последнего изменения данной строки в базе данных.
Таким образом, когда шаблон обращается к базе данных с запросом получения строки с статусом равным 0, и следующим запросом изменения этого статуса с 0 на 1 (если статус не равен 1). Если какой-то другой более шустрый поток получил эту же строку и раньше изменил статус - то наш поток просто пойдет и попытается получить следующую строку с базы.
А так как при изменении статуса временная метка изменится - то наша строчка улетит в нашей сортировке в конец таблицы (а мы с базы всегда будем брать именно первую строчку). Так потоки работают и не пересекаются (пересекаются, конечно, если поток отрабатывает очень быстро - но они у меня работают без браузера - а значит, места занимают мало и мне при необходимости не сложно добавить 2-3 секунды принудительной паузы, чтобы поток зря не долбился в базу данных запросами).
Вот собственно и все служебные поля, которые мне нужны для создания работоспособных шаблонов. Но, когда я уже начал работать с API, и встретил токены страничек, то пришлось добавить поле, которое хранило бы данный токен для каждого отдельного канала или видео (к примеру, чтобы не зацикливать шаблон при парсинге 100 000 комментариев к видео).
Это позволило шаблону быстрее заканчивать работу - а другой (следующий) поток мог без проблем продолжить скачивать комментарии к этому видео.
Так вот для работы с базой данных данный момент я реализовал таким способом - добавил поле STATUS, в котором хранится значение занятости строчки (0,1,2,3...). И добавил поле TIMESTAMP в котором хранится дата и время последнего изменения данной строки в базе данных.
Таким образом, когда шаблон обращается к базе данных с запросом получения строки с статусом равным 0, и следующим запросом изменения этого статуса с 0 на 1 (если статус не равен 1). Если какой-то другой более шустрый поток получил эту же строку и раньше изменил статус - то наш поток просто пойдет и попытается получить следующую строку с базы.
А так как при изменении статуса временная метка изменится - то наша строчка улетит в нашей сортировке в конец таблицы (а мы с базы всегда будем брать именно первую строчку). Так потоки работают и не пересекаются (пересекаются, конечно, если поток отрабатывает очень быстро - но они у меня работают без браузера - а значит, места занимают мало и мне при необходимости не сложно добавить 2-3 секунды принудительной паузы, чтобы поток зря не долбился в базу данных запросами).
Вот собственно и все служебные поля, которые мне нужны для создания работоспособных шаблонов. Но, когда я уже начал работать с API, и встретил токены страничек, то пришлось добавить поле, которое хранило бы данный токен для каждого отдельного канала или видео (к примеру, чтобы не зацикливать шаблон при парсинге 100 000 комментариев к видео).
Это позволило шаблону быстрее заканчивать работу - а другой (следующий) поток мог без проблем продолжить скачивать комментарии к этому видео.
Когда я создаю базу данных MySQL, которой буду пользоваться самостоятельно, то просто в программе Navicat добавляю необходимые мне таблицы и поля. Ничего сложного - как в Excel или Access.
Просто выписываю себе все переменные, содержимое которых хочу хранить в базе данных, выписываю, какие там будут данные (строки, цифры, даты) и количество символов при необходимости, какие будут поля иметь значения по умолчанию, если не будет никаких данных передано в запросе.
Но, когда приходится создавать решение, которое в дальнейшем придется запускать у кого-либо другого - то было бы не правильно озадачивать человека изучением баз данных.
И тут конечно есть два варианта. Первый вариант - просто создать копию своей базы данных и предоставить файл, который человеку придется импортировать в свою базу данных. Но и тут, бывает, приходится потом тратить время на объяснения что да как сделать.
И я пришел к выводу, что куда правильней будет просто создать шаблон, в котором будет этих несколько запросов, которые будут выполняться один раз по очереди - создадут необходимые таблички.
Просто выписываю себе все переменные, содержимое которых хочу хранить в базе данных, выписываю, какие там будут данные (строки, цифры, даты) и количество символов при необходимости, какие будут поля иметь значения по умолчанию, если не будет никаких данных передано в запросе.
Но, когда приходится создавать решение, которое в дальнейшем придется запускать у кого-либо другого - то было бы не правильно озадачивать человека изучением баз данных.
И тут конечно есть два варианта. Первый вариант - просто создать копию своей базы данных и предоставить файл, который человеку придется импортировать в свою базу данных. Но и тут, бывает, приходится потом тратить время на объяснения что да как сделать.
И я пришел к выводу, что куда правильней будет просто создать шаблон, в котором будет этих несколько запросов, которые будут выполняться один раз по очереди - создадут необходимые таблички.
Исходя из данных, которые я собрался хранить в базе, формирую запрос, для создания каждой из придуманных таблиц. Ничего сложного в этом нет. При желании такой запрос формируется просто нажатием на экспорт в базе данных (если уже хотя бы один раз была создана такая база) и открытием в блокноте файла - оттуда и вытаскиваем необходимые нам запросы.
Данные запросы мы сохраняем в переменные и добавляем столько экшинов по работе с базой данных, сколько у нас есть таблиц. Во входящих настройках, конечно же, добавляем возможность задать данные для доступа к базе данных (сервер, базу, логин, пароль) - это позволит предоставлять данный шаблон так сказать в "коробочном" решении - а пользователю не придется открывать ПроджектМейкер, не придется устанавливать даже Навикат. Удобно...
Для работы с базой данных в основном используются запросы SELECT, INSERT, UPDATE и сейчас я начал использовать и DELETE (раньше как-то не приходилось его использовать). Естественно, что данные запросы не сложные - вполне себе обычные запросы... Но мне, когда я разбирался с тем, как работать с базами данных, нехватало информации о том, как конкретно должны выглядеть запросы к базе данных, для работы с ней шаблонами Зеннопостера. Везде примеры в основном на PHP с учитыванием особенности языка, например формирование запроса в цикле, вывод строк в цикле и так далее.
Так что - отталкиваясь от того, чего мне нехватало, я предоставлю запросы полностью, чтобы их при желании можно было использовать в качестве примера и понимать, зачем они используются.
Впринципе, вся цепочка шаблонов работает со статусами разных таблиц. Например, статус канала проходит изменения от 0 до 9 пока не будет выполнена вся работа. Мне показался удобным такой контроль работы на каждом шаге. В случае, если где-то что-то подвисло, не докачалось - то каналы будут иметь промежуточные статусы занятости (например: 1, 3, 5) - и их можно одним запросом освободить после чего шаблоны их подхватят и выполнят работу полностью как было запланировано.
Замечу, что в шаблонах не предусмотрены выходы по красным и зеленым веткам - возможно, этот момент нужно продумать и доработать, вот только такой необходимости у меня пока небыло.
Так что - отталкиваясь от того, чего мне нехватало, я предоставлю запросы полностью, чтобы их при желании можно было использовать в качестве примера и понимать, зачем они используются.
Впринципе, вся цепочка шаблонов работает со статусами разных таблиц. Например, статус канала проходит изменения от 0 до 9 пока не будет выполнена вся работа. Мне показался удобным такой контроль работы на каждом шаге. В случае, если где-то что-то подвисло, не докачалось - то каналы будут иметь промежуточные статусы занятости (например: 1, 3, 5) - и их можно одним запросом освободить после чего шаблоны их подхватят и выполнят работу полностью как было запланировано.
Замечу, что в шаблонах не предусмотрены выходы по красным и зеленым веткам - возможно, этот момент нужно продумать и доработать, вот только такой необходимости у меня пока небыло.
Первый SQL запрос, который будет использоваться - это получение ИД канала, информацию о котором мы желаем получить. У меня все каналы, которые добавляются в базу данных, получают статус 0 - итого - я собираю информацию обо всех каналах. При желании можно, например, всем каналам, которые добавляются присвоить какой-то другой статус, а уже по определенным параметрам менять этот статус в значение ноль - после чего шаблон будет подхватывать его.
Дальше мне необходимо изменить статус канала с 0 на 1, чтобы никакой другой поток Зеннопостера случайно не подхватил данную строчку (чтобы несколько потоков не выполняло одну и ту же работу). Для этого будет использоваться запрос, который меняет значение в поле статус на 1 при условии, что ИД канала соответствует значению, которое мы получили предыдущим запросом и в поле статус не содержится значение 1.
Если после выполнения первого запроса мы ничего не получили - значит можно выполнить удаление пустых строчек (мало ли где-то не уследили - не хотел я вводить дополнительную проверку во всех шаблонах). Естественно - данный шаблон удалит все пустые строчки в указанной нами таблице.
И вот, после того как мы уже получили данные с YouTube то можно смело добавлять данны в базу. Для этого используется следующий запрос:
Естественно, что после того, как мы закончили работать с данным каналом (получили необходимые данные) то можем изменить статус в значение 2 - это даст право следующим шаблонам продолжать собирать информацию о видео на данном канале.
Код:
SELECT channel.id FROM channel WHERE channel.0x300status0x300 = 0 LIMIT 1
Код:
UPDATE channel SET channel.0x300status0x300 = 1 WHERE channel.id = "{-Variable.id_channel-}" AND channel.0x300status0x300 <> 1 LIMIT 1
Код:
DELETE FROM channel WHERE channel.id="";
Код:
INSERT into channel( channel.id, channel.title, channel.description, channel.customUrl, channel.publishedAt, channel.thumbnails_high_url, channel.relatedPlaylists_uploads, channel.relatedPlaylists_likes, channel.0x300relatedPlaylists.favorites0x300, channel.viewCount, channel.commentCount, channel.subscriberCount, channel.hiddenSubscriberCount, channel.videoCount, channel.showRelatedChannels, channel.featuredChannelsTitle, channel.featuredChannelsUrls_Count, channel.unsubscribedTrailer, channel.profileColor, channel.bannerTvHighImageUrl) VALUES {-Variable.query_channel_info-} ON DUPLICATE KEY UPDATE channel.title=VALUES(channel.title), channel.description=VALUES(channel.description), channel.customUrl=VALUES(channel.customUrl), channel.publishedAt=VALUES(channel.publishedAt), channel.thumbnails_high_url=VALUES(channel.thumbnails_high_url), channel.relatedPlaylists_uploads=VALUES(channel.relatedPlaylists_uploads), channel.relatedPlaylists_likes=VALUES(channel.relatedPlaylists_likes), channel.0x300relatedPlaylists.favorites0x300=VALUES(channel.0x300relatedPlaylists.favorites0x300), channel.viewCount=VALUES(channel.viewCount), channel.commentCount=VALUES(channel.commentCount), channel.subscriberCount=VALUES(channel.subscriberCount), channel.hiddenSubscriberCount=VALUES(channel.hiddenSubscriberCount), channel.videoCount=VALUES(channel.videoCount), channel.showRelatedChannels=VALUES(channel.showRelatedChannels), channel.featuredChannelsTitle=VALUES(channel.featuredChannelsTitle), channel.featuredChannelsUrls_Count=VALUES(channel.featuredChannelsUrls_Count), channel.unsubscribedTrailer=VALUES(channel.unsubscribedTrailer), channel.profileColor=VALUES(channel.profileColor), channel.bannerTvHighImageUrl=VALUES(channel.bannerTvHighImageUrl);
Код:
UPDATE channel SET channel.0x300status0x300 = 2 WHERE channel.id = "{-Variable.id_channel-}" LIMIT 1Как и в предыдущем шаблоне - мы будем получать ИД канала, со значением статуса 2, но при этом убедимся, что количество видео на канале больше 0 (нет смысла скачивать видео на канале, на котором нет видео).
Так вот, если мы что-либо получили - значит, можем изменить статус канала с 2 на 3, тем самим, обозначив, что мы в текущий момент уже работаем с данным каналом, и что в данный момент другой поток уже не может его брать в обработку.
Как и в предыдущем шаблоне если после выполнения первого запроса мы ничего не получили в ответ от базы данных - попытаемся удалить пустые строки.
Дальше мы можем получить значение количества видео на канале, которое храниться в табличке со списком каналов. Делается это обычным запросом, который вернет нам необходимое значение.
И получить количество видео, уже добавленных в базу данных с данного канала - для этого будем использовать функцию Count, которая подсчитает количество строк в базе данных по указанным нами параметрам.
После того, как мы определились с тем, что видео в базе данных недостаточно, и нам необходимо докачать новые ролики - мы можем получить с базы данных плейлист, в котором хранятся все загруженные ролики на канале и токен странички (возможно уже другой поток скачал первых парочку роликов и сохранил для нас токен).
Дальше идет изменение статусов относительно условий - если видео скачано уже, и нам необходимо прекратить работать с каналом - один статус, если же необходимо скачивать видео, но токен обнаружен - то наверно необходимо обнулить токен (чтобы другой поток не мог подхватить его и выполнял бесполезную работу).
И вот, когда мы уже скачали список видео - то мы можем его добавить в базу данных - запрос будет иметь следующий вид.
При этом, видим, что если появляются дубли - то обновляется временная метка. В данном случае не принципиально важно обновлять другие поля - так как статистика не содержится в наших данных - статистику будет собирать следующий шаблон.
И вот если в результатах запроса к API был обнаружен токен странички - значит, нам необходимо установить статус канала так, чтобы он был доступным для других потоков, и указать актуальный токен. Собственно дальше следующий поток уже сможет проверить докачать следующую страничку со списком видео.
Но когда токен не обнаружен - это значит, что мы уже скачали все видео - а значит, можем установить статус канала в значение, при котором с ним уже сможет работать другой шаблон. Не забываем обнулить токен.
Код:
SELECT channel.id FROM channel WHERE channel.0x300status0x300 = 2 AND channel.videoCount > 0 LIMIT 1
Код:
UPDATE channel SET channel.0x300status0x300 = 3 WHERE channel.id = "{-Variable.id_channel-}" AND channel.0x300status0x300 <> 3 LIMIT 1
Код:
DELETE FROM channel WHERE channel.id="";
Код:
SELECT channel.videoCount FROM channel WHERE channel.id = "{-Variable.id_channel-}" LIMIT 1
Код:
SELECT Count(video.id_video) FROM video WHERE video.id_channel = "{-Variable.id_channel-}" LIMIT 1
Код:
SELECT channel.relatedPlaylists_uploads, channel.token_list_video FROM channel WHERE channel.id = "{-Variable.id_channel-}" LIMIT 1
Код:
UPDATE channel SET channel.0x300status0x300 = 5, channel.token_list_video = "0" WHERE channel.id = "{-Variable.id_channel-}" LIMIT 1
UPDATE channel SET channel.0x300status0x300 = 4 WHERE channel.id = "{-Variable.id_channel-}" LIMIT 1
Код:
INSERT INTO video (video.id_video, video.id_channel, video.title, video.data_greate, video.discription) VALUES {-Variable.query_video_list-} ON DUPLICATE KEY UPDATE 0x300timestamp0x300=now()И вот если в результатах запроса к API был обнаружен токен странички - значит, нам необходимо установить статус канала так, чтобы он был доступным для других потоков, и указать актуальный токен. Собственно дальше следующий поток уже сможет проверить докачать следующую страничку со списком видео.
Код:
UPDATE channel SET channel.0x300status0x300 = 2, channel.token_list_video = "{-Variable.token_list_video-}" WHERE channel.id = "{-Variable.id_channel-}" LIMIT 1
Код:
UPDATE channel SET channel.0x300status0x300 = 5, channel.token_list_video = "0" WHERE channel.id = "{-Variable.id_channel-}" LIMIT 1Как и в предыдущих шаблонах мы видим, что обратно получаем ИД канала, с которым желаем работать, но в этот раз получаем канал с статусом 5 и количеством видео больше нуля.
Дальше меняем статус канала с 5 на 6, чтобы другие потоки игнорировали его и занимались работой с другими каналами. Обращаю внимание, чтобы мы могли определить был, изменен статус или нет, определяем, что менять статус будем только тогда, когда статус не равен значению 6 (другой поток еще не изменил статус). Если выполнять запрос в Зеннопостере в режиме "Без ответа" - то в переменную нам сохранится либо количество измененных строк, либо ноль. Если значение больше чем ноль - значит, статус изменился, а значит, мы можем продолжать работу - иначе - необходимо будет получить другой канал (или закончить работу шаблона).
Вспоминаем, что в прошлых шаблонах удаляли пустые строки - данный запрос перекочевал оттуда сюда - думаю, лишним не будет, хотя, если изначально проверять данные, перед добавлением их в базу на предмет пусты - то вероятнее всего данный запрос можно будет не выполнять, так как пустых строк в базе данных не будет.
Дальше мы подсчитываем количество видео с статусом 0 (отмечу, что работать уже мы будем с таблицей в которой хранятся видео - до этого времени мы работали с таблицой в которой хранилась информация о каналах).
Если в базе данных нет видео с таким статусом - значит пора изменить статус наканала в значение 7 (это будет говорить о том, что информация о всех видео уже загружена в базу).
В противном случае мы получим с базы данных 50 идентификаторов каналов (да, информацию о видео мы можем получать пачками через API - в этом и прелесть).
Конечно же изменим статус канала в значение 7 чтобы освободить его, если в переменной в результате выполнения предыдущего запроса пусто.
Если же мы получили идентификаторы, то шаблон уже обращается к API описанными ранее способами, получает данные, разбирает по переменных, формирует значения для запроса - и вот только потом отправляет данный запрос. Здесь отмечу, что в случае обнаружения дубля обновляются все поля - дело в том, что если мы скачали статистику вчера, то сегодня у нас информация по количеству просмотров уже изменилась - а значит - есть смысл перекачивать информацию повторно чтобы держать её в актуальном состоянии.
И вот, после добавления информации об видео в базу данных осталось еще добавить теги. Так как теги разбиты у меня на две таблички - то добавляются они по очереди двумя запросами. В первом добавляются теги в табличку с тегами, и при обнаружении дубликата счетчик в базе данных увеличивается на 1 (таким образом можно будет обнаружить самые популярные теги).
А уже после добавления тегов - добавляются теги и идентификаторы видео в другую табличку - для того, чтобы в дальнейшем можно было делать выборку роликов по определенным тегам.
В завершение возвращаем статус канала в значение 5 (чтобы следующий поток смог взять следующие 50 роликов). Здесь также требуется замечание о том, что в данном случае каналам изменяются статусы вначале работы шаблона, так как опираемся мы на данные с базы, а не с API.
Код:
SELECT channel.id FROM channel WHERE channel.0x300status0x300 = 5 AND channel.videoCount > 0 LIMIT 1
Код:
UPDATE channel SET channel.0x300status0x300 = 6 WHERE channel.id = "{-Variable.id_channel-}" AND channel.0x300status0x300 <> 6 LIMIT 1
Код:
DELETE FROM channel WHERE channel.id="";
Код:
SELECT Count(video.id_video) FROM video WHERE video.0x300status0x300 = 0 AND video.id_channel = "{-Variable.id_channel-}"
Код:
UPDATE channel SET channel.0x300status0x300 = 7 WHERE channel.id = "{-Variable.id_channel-}" LIMIT 1
Код:
SELECT video.id_video FROM video WHERE video.id_channel = "{-Variable.id_channel-}" AND video.0x300status0x300 = 0 LIMIT 50
Код:
UPDATE channel SET channel.0x300status0x300 = 7 WHERE channel.id = "{-Variable.id_channel-}" LIMIT 1
Код:
INSERT INTO video (video.id_video, video.id_channel, video.title, video.discription, video.0x300status0x300, video.categoryid, video.default_language, video.privatstatus, video.license, video.stat_view, video.view_count, video.likecount, video.dislikecount, video.favoritecount, video.commentcount) VALUES {-Variable.query_video_update-} ON DUPLICATE KEY UPDATE video.title=VALUES(title), video.discription=VALUES(discription), video.0x300status0x300=VALUES(0x300status0x300), video.categoryid=VALUES(categoryid), video.default_language=VALUES(default_language), video.privatstatus=VALUES(privatstatus), video.license=VALUES(license), video.stat_view=VALUES(stat_view), video.view_count=VALUES(view_count), video.likecount=VALUES(likecount), video.dislikecount=VALUES(dislikecount), video.favoritecount=VALUES(favoritecount), video.commentcount=VALUES(commentcount)
Код:
INSERT INTO tag (id) VALUES {-Variable.query_tag-} ON DUPLICATE KEY UPDATE count=count+1
Код:
INSERT INTO video_tag (video_tag.id_video, video_tag.id_tag) VALUES {-Variable.query_tag-} ON DUPLICATE KEY UPDATE video_tag.0x300timestamp0x300=now()
Код:
UPDATE channel SET channel.0x300status0x300 = 5 WHERE channel.id = "{-Variable.id_channel-}" LIMIT 1Собрав информацию о всех роликах мы можем начинать работать с комментариями. Комментариев может быть очень много - так что набираемся терпения. При этом шаблон построен так, чтобы вне зависимости от количества комментариев в видео были собраны все комментарии без зависаний шаблона и входа в бесконечные циклы.
И так, обратно мы берем канал и изменяем ему статус. В этот раз уже канал со статусом 7 и количеством видео больше 0 (ведь если нет видео - то комментариев там точно нет).
Уже знакомый запрос удаления пустых строк с базы данных будет использован если вдруг мы ничего не получим с базы данных.
Дальше статус нашего канала должен мигрировать с 7 на 8 - по аналогии с предыдущими шаблонами.
После чего подсчитываем количество видео с комментариями и статусом 1.
Если количество видео будет больше чем ноль, значит можно получить с базы данных идентификатор видео и токен странички с комментариями (вдруг уже другой поток скачал часть комментариев и оставил метку нам).
Если мы ничего не получили - значит на данном видео еще нет комментариев либо все комментарии загружены в базу данных. А значит - меняем статус для канала (освобождаем его).
Иначе меняем статус видео, и добавляем токен чтобы другой поток смог продолжить нашу работу - скачать очередные комментарии.
Обратно, по условию, освобождаем канал, считая, что все комментарии скачали (служить этим признаком может отсутствие токена в ответе API).
Изменяем статус видео в значение 2, изменяем токен.
Если другой поток еще должен докачивать комментарии - меняем статус для канала в значение 7.
Дальше мы добавляем собранных авторов комментариев в базу данных, при обнаружении дублей - обновляем временную метку.
И под конец работы нашего шаблона добавляем комментарии, которые были скачаны.
И так, обратно мы берем канал и изменяем ему статус. В этот раз уже канал со статусом 7 и количеством видео больше 0 (ведь если нет видео - то комментариев там точно нет).
Код:
SELECT channel.id FROM channel WHERE channel.0x300status0x300 = 7 AND channel.videoCount > 0 LIMIT 1
Код:
DELETE FROM channel WHERE channel.id="";
Код:
UPDATE channel SET channel.0x300status0x300 = 8 WHERE channel.id = "{-Variable.id_channel-}" AND channel.0x300status0x300 <> 8 LIMIT 1
Код:
SELECT Count(video.commentcount) FROM video WHERE video.id_channel = "{-Variable.id_channel-}" AND video.commentcount > 0 AND video.0x300status0x300 = 1 LIMIT 1
Код:
SELECT video.id_video, token_comment FROM video WHERE video.id_channel = "{-Variable.id_channel-}" AND video.0x300status0x300 = 1 AND video.commentcount > 0 LIMIT 1
Код:
UPDATE channel SET channel.0x300status0x300 = 9 WHERE channel.id = "{-Variable.id_channel-}" LIMIT 1
Код:
UPDATE video SET video.0x300status0x300 = 1, video.token_comment = "{-Variable.token_list_comment-}" WHERE video.id_video = "{-Variable.id_video_comment-}" LIMIT 1
Код:
UPDATE channel SET channel.0x300status0x300 = 9 WHERE channel.id = "{-Variable.id_channel-}" LIMIT 1
Код:
UPDATE video SET video.0x300status0x300 = 2, video.token_comment = "{-Variable.token_list_comment-}" WHERE video.id_video = "{-Variable.id_video_comment-}" LIMIT 1
Код:
UPDATE channel SET channel.0x300status0x300 = 7 WHERE channel.id = "{-Variable.id_channel-}" LIMIT 1
Код:
INSERT into channel(channel.id) VALUES {-Variable.query_commentators-} ON DUPLICATE KEY UPDATE 0x300timestamp0x300 = now();
Код:
INSERT into 0x300comment0x300(0x300comment0x300.id_video, 0x300comment0x300.id_comment, 0x300comment0x300.authorChannelId, 0x300comment0x300.textDisplay, 0x300comment0x300.publishedAt, 0x300comment0x300.updatedAt, 0x300comment0x300.likeCount, 0x300comment0x300.parentId) VALUES {-Variable.query_comment-} ON DUPLICATE KEY UPDATE 0x300comment0x300.likeCount = VALUES(likeCount);Выше описан план, а значит пора приступать к делу - создать пачку шаблонов для Зеннопостера, которые быстро, без использования браузера и с использованием APIv3 YouTube будут получать необходимую общедоступную информацию.
Собирать будем информацию о канале, видео, комментарии к видео. После чего добавим всю информацию в базу данных. Чтобы в дальнейшем можно было делать выборку данных с базы данных поопределенным нами параметрам (тут уже творческая работа).
Так вот шаблонов будет несколько - один будет собирать только информацию о канале, второй будет собирать только список видео на канале, третий будет собирать только статистику просмотров, описания и теги к роликам, и последний - будет собирать комментарии к этим видеороликам.
Каждый из шаблонов содержит входящие настройки, из которых подхватывает ключ для доступа к API YouTube и данные для доступа к базе данных (логин, пароль, сервер, имя базы данных). Также во входящих настройках добавлены значения по умолчанию, которые в дальнейшем заменяются шаблоном после получения данных с базы (добавлены для того, чтобы иметь возможность протестировать шаблоны/запросы без базы данных).
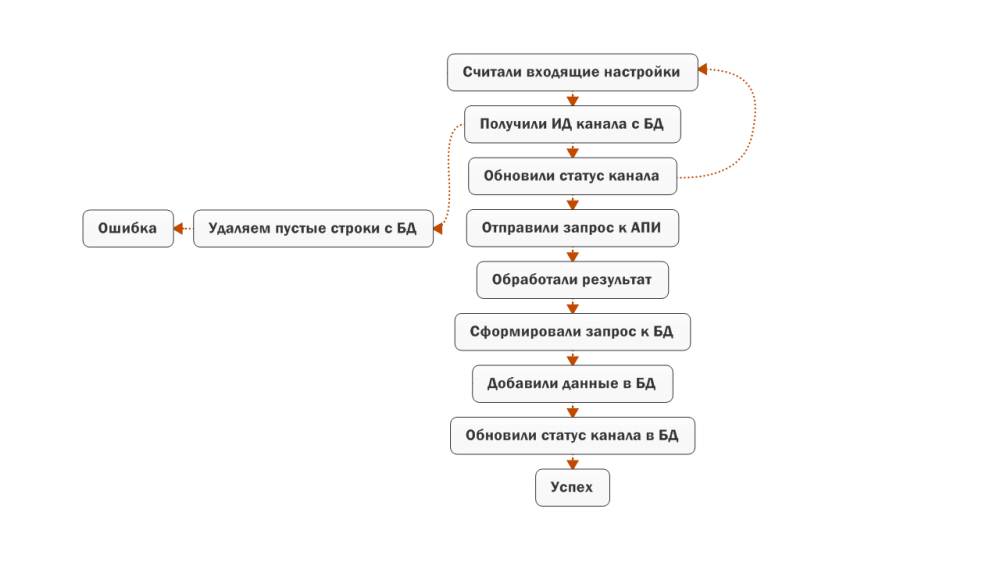
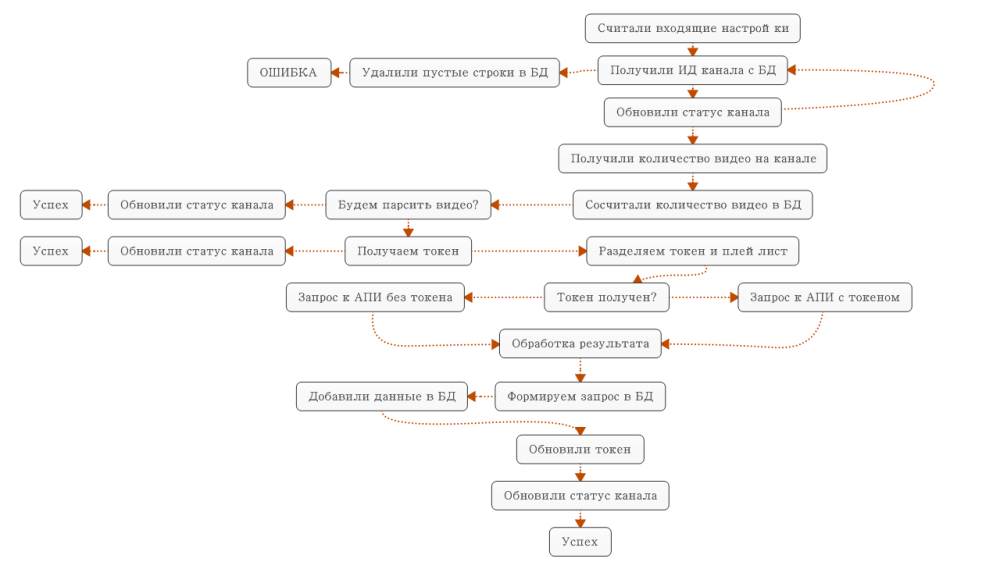
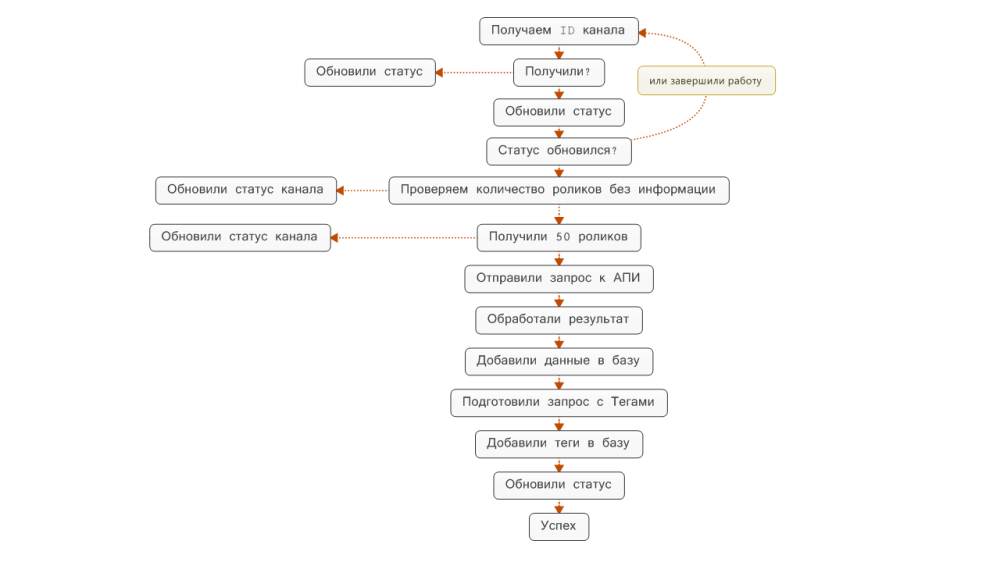
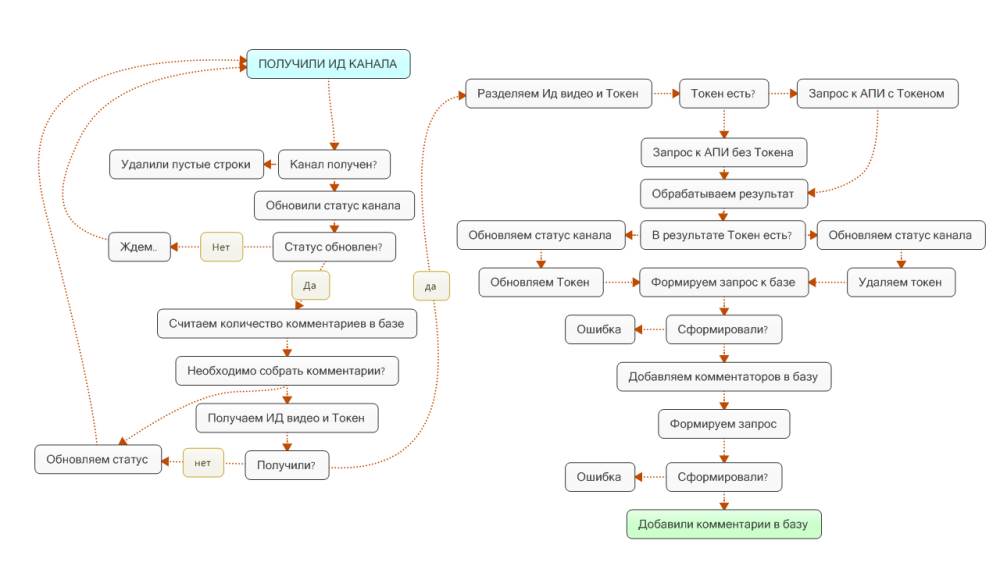
Собирать будем информацию о канале, видео, комментарии к видео. После чего добавим всю информацию в базу данных. Чтобы в дальнейшем можно было делать выборку данных с базы данных поопределенным нами параметрам (тут уже творческая работа).
Так вот шаблонов будет несколько - один будет собирать только информацию о канале, второй будет собирать только список видео на канале, третий будет собирать только статистику просмотров, описания и теги к роликам, и последний - будет собирать комментарии к этим видеороликам.
Каждый из шаблонов содержит входящие настройки, из которых подхватывает ключ для доступа к API YouTube и данные для доступа к базе данных (логин, пароль, сервер, имя базы данных). Также во входящих настройках добавлены значения по умолчанию, которые в дальнейшем заменяются шаблоном после получения данных с базы (добавлены для того, чтобы иметь возможность протестировать шаблоны/запросы без базы данных).
Логика работы шаблона для Зеннопостера, который, с помощью API собирает общедоступную информацию с канала YouTube, выглядит следующим образом:
Прежде всего, шаблон получает входящие настройки и, используя полученные значения, обращается к базе данных за получением идентификатора канала (информацию о котором требуется получить). Предполагается, что в базе данных уже добавлен список каналов. Если это не так - то шаблон попытается удалить пустые строки и закончит работу.
Если шаблон получил с базы данных идентификатор канала, то следующим действием он попытается изменить статус канала в базе данных - и если изменение было произведено успешно - продолжит работу, иначе - попытается получить следующий идентификатор канала. Данный подход применен с целью обеспечения многопоточности шаблона - каждый поток будет получать другой идентификатор канала - а значит, разные потоки не будут выполнять одну и ту же работу.
Так вот, если идентификатор канала получен, статус изменен успешно. Определяется это по количеству измененных строк в базе данных. Если база вернула 0, значит ничего не изменено, а значит, статус не изменился, если же база данных возвращает 1 – значит, изменена одна строка - а значит, статус изменился, то шаблон может обратиться к API YouTube, используя ключ доступа (API KEY) обычным GET запросом с целью получения необходимой информации.
После выполнения запроса в переменной, которая используется для временного хранения результата, будет содержаться масив данных в формате JSON. В зависимости от навыков работы с Зеннопостером эти данные необходимо разобрать попеременных для дальнейшего сохранения в таблицу, список, файлы или для формирования запроса к базе данных.
Я определился с сохранением данных в базу данных MySQL и разбором полученного JSON с помощью регулярных выражений в одном сниппете C# кода. Результатом успешного выполнения сниппета является строка с подготовленными значениями для добавления в базу данных. Собственно переменная с данным результатом и будет использоваться в SQL запросе экшина для работы с базами данных.
После добавления данных о канале, которые были собраны, есть необходимость изменить статус канала - освободить его для возможности работы с ним другими шаблонами. После чего шаблон заканчивает работу. При желании в любом месте шаблона можно добавить уведомления в лог, чтобы иметь возможность наблюдения за состоянием переменных - но, после того, как шаблон оттестирован, я удалил все уведомления, оставив только последнее, которое оповещает об успешном добавлении информации о канале.
Итого, в результате выполенния данного шаблона в базу данных будет добавлена общая информация о канале, среди нее будет сохранен идентификатор плейлиста всех загруженных роликов на канал, который и будет использован в следующем шаблоне.
Прежде всего, шаблон получает входящие настройки и, используя полученные значения, обращается к базе данных за получением идентификатора канала (информацию о котором требуется получить). Предполагается, что в базе данных уже добавлен список каналов. Если это не так - то шаблон попытается удалить пустые строки и закончит работу.
Если шаблон получил с базы данных идентификатор канала, то следующим действием он попытается изменить статус канала в базе данных - и если изменение было произведено успешно - продолжит работу, иначе - попытается получить следующий идентификатор канала. Данный подход применен с целью обеспечения многопоточности шаблона - каждый поток будет получать другой идентификатор канала - а значит, разные потоки не будут выполнять одну и ту же работу.
Так вот, если идентификатор канала получен, статус изменен успешно. Определяется это по количеству измененных строк в базе данных. Если база вернула 0, значит ничего не изменено, а значит, статус не изменился, если же база данных возвращает 1 – значит, изменена одна строка - а значит, статус изменился, то шаблон может обратиться к API YouTube, используя ключ доступа (API KEY) обычным GET запросом с целью получения необходимой информации.
После выполнения запроса в переменной, которая используется для временного хранения результата, будет содержаться масив данных в формате JSON. В зависимости от навыков работы с Зеннопостером эти данные необходимо разобрать попеременных для дальнейшего сохранения в таблицу, список, файлы или для формирования запроса к базе данных.
Я определился с сохранением данных в базу данных MySQL и разбором полученного JSON с помощью регулярных выражений в одном сниппете C# кода. Результатом успешного выполнения сниппета является строка с подготовленными значениями для добавления в базу данных. Собственно переменная с данным результатом и будет использоваться в SQL запросе экшина для работы с базами данных.
После добавления данных о канале, которые были собраны, есть необходимость изменить статус канала - освободить его для возможности работы с ним другими шаблонами. После чего шаблон заканчивает работу. При желании в любом месте шаблона можно добавить уведомления в лог, чтобы иметь возможность наблюдения за состоянием переменных - но, после того, как шаблон оттестирован, я удалил все уведомления, оставив только последнее, которое оповещает об успешном добавлении информации о канале.
Итого, в результате выполенния данного шаблона в базу данных будет добавлена общая информация о канале, среди нее будет сохранен идентификатор плейлиста всех загруженных роликов на канал, который и будет использован в следующем шаблоне.
Логика работы шаблона для Зеннопостера, который собирает список загруженных видео на канал YouTube без использования браузера (но с использованием YouTube API) выглядит следующим образом.
Прежде всего, шаблон получает с входящих настроек данные, для доступа к базе данных, и ключ доступа к YouTube API который будет использоваться для получения от YouTube информации (в данном случае списка видео на канале).
Используя полученые с входящих настроек значения, шаблон обращается к базе данных, запрашивая идентификатор канала, список видео которого еще не сохранен в базу данных. Если в результате выполнения запроса ничего не было получено - делаем вывод, что в базе данных либо есть пустые строки (получена пустая строка - в таком случае удалим пустые стоки с базы данных соответствующим запросом). Если же был получен идентификатор канала – значит, шаблон следующим запросом изменит статус, обозначив тем самым для других потоков Зеннопостера, что данный канал сейчас обрабатывается - таким образом, следующие потоки не смогут получить для работы этот же идентификатор канала - данная манипуляция позволяет реализовать многопоточную работу.
Дальше шаблон получает количество видео на канале (эта информация хранится в базе данных как результат выполнения работы предыдущего шаблона) и подсчитывает количество уже добавленных идентификаторов видео в базу данных. Если количество роликов на канале больше, чем количество добавленных идентификаторов видео в базе данных мы можем сделать вывод, что на канале появились новые ролики - а значит необходимо перейти к загрузке списка роликов с данного канала. В противном случае - изменяем статус канала (освобождая его для других потоков и шаблонов) и заканчиваем выполнение шаблона.
Если же есть необходимость скачать список видео - то проверяем, не хранится ли случайно в базе данных токен, который предназначен для получения определенной странички с роликами на интересующем нас канале. Одновременно получаем с базы данных и идентификатор плейлиста, в котором хранятся все загруженные видео на канал.
Разделив по разделителю (предыдущим запросом к базе данных мы получили идентификатор плейлиста и токен и сохранили их в одной переменной) идентификатор плейлиста и токен мы можем проверить есть пустой токен у нас или нет. Если токена нет - отправляем запрос к API без использования токена. Если токен есть – значит, отправляем запрос с токеном.
В результате обращения к API YouTube мы получим масив данных в формате JSON, который, как и в предыдущем шаблоне, нам необходимо разобрать регулярными выражениями попеременных и сформировать запрос для добавления в базу данных.
После добавления списка роликов в нашу базу данных, шаблон должен освободить канал, изменив его статус, после чего работа шаблона заканчивается успешным выполнением и уведомлением (при необходимости).
Естественно, что прежде чем удалить все уведомления в лог, которые оповещали на каждом шаге, как происходит выполнение, я протестировал шаблон, и убедившись, что каждая переменная принимает корректные значения - удалил их.
В итоге выполнения работы данного шаблона в базе данных у нас уже хранится как информация о канале (результат работы предыдущего шаблона), так полный список загруженных видео на канал (или частичный - тогда следующие потоки догрузят весь список) с краткой информацией о видео. Но, так как нам необходимы теги к видео и статистика просмотров - это уже более подробная информация - а значит, получать эти данные будет следующий шаблон.
Прежде всего, шаблон получает с входящих настроек данные, для доступа к базе данных, и ключ доступа к YouTube API который будет использоваться для получения от YouTube информации (в данном случае списка видео на канале).
Используя полученые с входящих настроек значения, шаблон обращается к базе данных, запрашивая идентификатор канала, список видео которого еще не сохранен в базу данных. Если в результате выполнения запроса ничего не было получено - делаем вывод, что в базе данных либо есть пустые строки (получена пустая строка - в таком случае удалим пустые стоки с базы данных соответствующим запросом). Если же был получен идентификатор канала – значит, шаблон следующим запросом изменит статус, обозначив тем самым для других потоков Зеннопостера, что данный канал сейчас обрабатывается - таким образом, следующие потоки не смогут получить для работы этот же идентификатор канала - данная манипуляция позволяет реализовать многопоточную работу.
Дальше шаблон получает количество видео на канале (эта информация хранится в базе данных как результат выполнения работы предыдущего шаблона) и подсчитывает количество уже добавленных идентификаторов видео в базу данных. Если количество роликов на канале больше, чем количество добавленных идентификаторов видео в базе данных мы можем сделать вывод, что на канале появились новые ролики - а значит необходимо перейти к загрузке списка роликов с данного канала. В противном случае - изменяем статус канала (освобождая его для других потоков и шаблонов) и заканчиваем выполнение шаблона.
Если же есть необходимость скачать список видео - то проверяем, не хранится ли случайно в базе данных токен, который предназначен для получения определенной странички с роликами на интересующем нас канале. Одновременно получаем с базы данных и идентификатор плейлиста, в котором хранятся все загруженные видео на канал.
Разделив по разделителю (предыдущим запросом к базе данных мы получили идентификатор плейлиста и токен и сохранили их в одной переменной) идентификатор плейлиста и токен мы можем проверить есть пустой токен у нас или нет. Если токена нет - отправляем запрос к API без использования токена. Если токен есть – значит, отправляем запрос с токеном.
В результате обращения к API YouTube мы получим масив данных в формате JSON, который, как и в предыдущем шаблоне, нам необходимо разобрать регулярными выражениями попеременных и сформировать запрос для добавления в базу данных.
После добавления списка роликов в нашу базу данных, шаблон должен освободить канал, изменив его статус, после чего работа шаблона заканчивается успешным выполнением и уведомлением (при необходимости).
Естественно, что прежде чем удалить все уведомления в лог, которые оповещали на каждом шаге, как происходит выполнение, я протестировал шаблон, и убедившись, что каждая переменная принимает корректные значения - удалил их.
В итоге выполнения работы данного шаблона в базе данных у нас уже хранится как информация о канале (результат работы предыдущего шаблона), так полный список загруженных видео на канал (или частичный - тогда следующие потоки догрузят весь список) с краткой информацией о видео. Но, так как нам необходимы теги к видео и статистика просмотров - это уже более подробная информация - а значит, получать эти данные будет следующий шаблон.
Как и предыдущие шаблоны Зеннопостера для сбора общедоступной информации о каналах на YouTube с использованием API - данный шаблон также не будет использовать браузер, будет сохранять результат своей работы в базу данных MySQL, данные для доступа к API и к нашей базе данных будет получать с входящих настроек. Впрочем, и логика работы данного шаблона будет аналогичной с предыдущими шаблонами, но с некоторыми изменениями.
Шаблон получит идентификатор канала YouTube с базы данных и изменит для него статус, и в случае успеха проверит количество роликов, к которым еще не была скачана информация. Если полученное значение будет больше нуля - значит можно взять первых 50 роликов (да, получать информацию дальше будем пачками) и отправить запрос к API на получение данных.
Результатом, как и раньше, будет масив данных в формате JSON, а значит, уже знакомый сниппет разберет его регулярными выражениями попеременных и сформирует запросы к базе данных на добавление информации о видео и добавление информации о тегах.
В конце шаблон освободит канал для других потоков и шаблонов, изменив статус, закончит работу уведомлением в лог. Обратно-таки, в процессе тестирования шаблона уведомлений было много - но когда была запущена рабочая версия - все уведомления были убраны с шаблона.
В итоге в результате выполнения шаблона в базе данных уже будет сохранена подробная информация о 50 видеороликах (идентификаторы которых мы получали с базы данных в начале выполнения шаблона), а также будут сохранены теги, которые автор ролика вводил для лучшего обнаружения ролика потенциальными зрителями.
Шаблон получит идентификатор канала YouTube с базы данных и изменит для него статус, и в случае успеха проверит количество роликов, к которым еще не была скачана информация. Если полученное значение будет больше нуля - значит можно взять первых 50 роликов (да, получать информацию дальше будем пачками) и отправить запрос к API на получение данных.
Результатом, как и раньше, будет масив данных в формате JSON, а значит, уже знакомый сниппет разберет его регулярными выражениями попеременных и сформирует запросы к базе данных на добавление информации о видео и добавление информации о тегах.
В конце шаблон освободит канал для других потоков и шаблонов, изменив статус, закончит работу уведомлением в лог. Обратно-таки, в процессе тестирования шаблона уведомлений было много - но когда была запущена рабочая версия - все уведомления были убраны с шаблона.
В итоге в результате выполнения шаблона в базе данных уже будет сохранена подробная информация о 50 видеороликах (идентификаторы которых мы получали с базы данных в начале выполнения шаблона), а также будут сохранены теги, которые автор ролика вводил для лучшего обнаружения ролика потенциальными зрителями.
Для сбора комментариев, которые пользователи размещают под видео на YouTube, будем придумывать шаблон, который, как и предыдущие, не будет использовать браузер и сможет получать комментарии, используя API KEY. Запрос, который используется, был описан выше - здесь же предлагаю рассмотреть логику работы шаблона.
Получив идентификатор канала с базы данных, шаблон изменит его статус для обеспечения многопоточности, после чего сравнив количество комментариев, написанных для видео, и количество комментариев в базе шаблон определяет завершать ему работу или идти отправлять запрос на получение комментариев от YouTube.
Допустим, что необходимо собрать комментарии - тогда мы получаем с базы данных идентификатор видео и токен, при этом, если токен присутствует – значит, отправляем к YouTube запрос с токеном, иначе - без токена, после чего разобрав результат попеременных, формируем запрос к базе данных, и добавляем данные в базу.
В промежутке нужно будет еще проверять пришел ли нам токен в ответ - если пришел, добавляем его в базу и изменяем статус канала, если не пришел – значит, что все комментарии скачаны - обратно изменим статус канала.
Завершение шаблона, как и в предыдущих шаблонах, это изменение статуса канала, после чего работа над каналом закончена, и можно показать уведомление в лог, а другие потоки, или шаблоны, уже могут использовать полученную информацию, получая её с базы данных.
Итогом выполнения данного шаблона является добавленный список комментариев, которые добавлены под видео роликом на YouTube, а при многократном выполнении все комментарии будут сохранены в базу данных. Также данный шаблон автоматически пополняет базу данных новыми каналами комментаторов - что позволяет постепенно наполнять базу данных новыми каналами и делать в дальнейшем выборки самих активных зрителей.
Получив идентификатор канала с базы данных, шаблон изменит его статус для обеспечения многопоточности, после чего сравнив количество комментариев, написанных для видео, и количество комментариев в базе шаблон определяет завершать ему работу или идти отправлять запрос на получение комментариев от YouTube.
Допустим, что необходимо собрать комментарии - тогда мы получаем с базы данных идентификатор видео и токен, при этом, если токен присутствует – значит, отправляем к YouTube запрос с токеном, иначе - без токена, после чего разобрав результат попеременных, формируем запрос к базе данных, и добавляем данные в базу.
В промежутке нужно будет еще проверять пришел ли нам токен в ответ - если пришел, добавляем его в базу и изменяем статус канала, если не пришел – значит, что все комментарии скачаны - обратно изменим статус канала.
Завершение шаблона, как и в предыдущих шаблонах, это изменение статуса канала, после чего работа над каналом закончена, и можно показать уведомление в лог, а другие потоки, или шаблоны, уже могут использовать полученную информацию, получая её с базы данных.
Итогом выполнения данного шаблона является добавленный список комментариев, которые добавлены под видео роликом на YouTube, а при многократном выполнении все комментарии будут сохранены в базу данных. Также данный шаблон автоматически пополняет базу данных новыми каналами комментаторов - что позволяет постепенно наполнять базу данных новыми каналами и делать в дальнейшем выборки самих активных зрителей.
- Тема статьи
- Парсинг
- Номер конкурса статей
- Седьмой конкурс статей
Вложения
-
41,7 КБ Просмотры: 1 695
-
56,7 КБ Просмотры: 1 069
-
52,1 КБ Просмотры: 974
-
50,2 КБ Просмотры: 1 091
-
29,9 КБ Просмотры: 1 039
Для запуска проектов требуется программа ZennoPoster или ZennoDroid.
Это основное приложение, предназначенное для выполнения автоматизированных шаблонов действий (ботов).
Подробнее...
Для того чтобы запустить шаблон, откройте нужную программу. Нажмите кнопку «Добавить», и выберите файл проекта, который хотите запустить.
Подробнее о том, где и как выполняется проект.
Последнее редактирование:

 :-)")

