


- Регистрация
- 05.09.2012
- Сообщения
- 23 141
- Реакции
- 10 371
- Баллы
- 113
Это тема уже для отдельного топика..Можно спросить как эти данные по разным файлам раскидать? То есть в несколько списков?
 :)")
Это тема уже для отдельного топика..Можно спросить как эти данные по разным файлам раскидать? То есть в несколько списков?
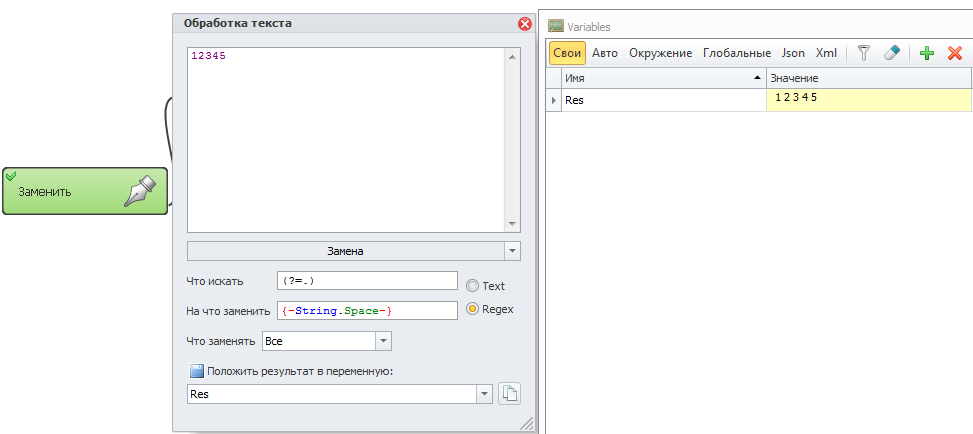
как после каждого символа вставить пробел? можно и для np++
<a class="small" href="https://сайт.ру/раздел/тут-12любые-буквы67-и-45цифры-цифры">(?<=<a\ class="small"\ href="https://сайт\.ру/раздел/).*?(?=")(?<=-)[^-]+$Исходный код в переменной:
Нужно получить цифры, стоящие между последним дефисом и кавычкой.Код:<a class="small" href="https://сайт.ру/раздел/тут-12любые-буквы67-и-45цифры-цифры">
Я смог это сделать через создание промежуточной переменной так:
и последующей обработкой этой переменной так:Код:(?<=<a\ class="small"\ href="https://сайт\.ру/раздел/).*?(?=")
Код:(?<=-)[^-]+$
Подозреваю, что есть более элегантное решение. Прошу помочь.
(?<=-)\d+(?=">)Для латиницы:Извиняюсь за нубство)
Подскажите, найти любую букву?
Любая цифра- \d , а буква как?)
спасибо!Для латиницы:
[A-Za-z]
Для кириллицы:
[А-Яа-яЁё]
Универсальная:
[A-Za-zА-Яа-яЁё]
нельзя. Можно искать текст по регулярке через обработку текста, а потом просто проверять результирующую переменную на пустотуОтвет нашёл, пустое значение - ^$ (^ - начало строки $- конец строки)
Вопрос, можно ли, и если да то как использовать регулярное выражение в кубике if?
а как проверить результирующую переменную на пустоту в случае с if ?нельзя. Можно искать текст по регулярке через обработку текста, а потом просто проверять результирующую переменную на пустоту
"{-Variable.x-}"==""а как проверить результирующую переменную на пустоту в случае с if ?
{-Variable.x-}== что?
(?<=_)[^_]+$Подскажите, плиз. Есть вот значения такого плана
QZO6_59UV8_KITB7BGV_9fs
OEAB_U6029T0S8_A63b
g3_3RGe23ZF3_1XR67A
XLdIZS_d55O09_xccu
Мне надо получить ту часть, которая идет после последней _
Т.е. вот эти значения:
9fs
A63b
1XR67A
xccu
Какой регуляркой это можно сделать?
(?<=>).*?(?=</a)Подскажите пожалуйста регулярное выражение при парсинге, чтобы оставалось только значение: "дубить кожу", "дубленная кожа", "кожа"
href="/keywords/?q=%D0%B4%D0%B5%D0%BB%D0%B0%D1%82%D1%8C%20%D0%B4%D1%80%D0%B0%D0%BA%D0%BE%D0%BD%D0%B0%20%D0%B8%D0%B3%D1%80%D0%B0">дубить кожу</a>
href="/keywords/?q=%D0%BA%D0%B0%D0%BA%20%D0%B4%D0%B5%D0%BB%D0%B0%D1%8E%D1%82%20%D0%B4%D1%80%D0%B0%D0%BA%D0%BE%D0%BD%D0%BE%D0%B2%20%D0%B2%20%D0%B8%D0%B3%D1%80%D0%B5%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2">дубленная кожа</a>
href="/keywords/?q=%D0%BF%D0%B5%D1%80%D0%B5%D0%BF%D1%83%D1%82%D0%B0%D0%BD%D0%BD%D1%8B%D0%B5%20%D0%B8%D0%B3%D1%80%D1%8B%20%D0%B8%20%D0%B4%D1%80%D0%B0%D0%BA%D0%BE%D0%BD%D0%BE%D0%B2">кожа</a
Вам ответили тут:Доброго времени суток, мне нужна помощь в удалении html тегов дублей, пример:
<h5> слова слова слова </h5><h5> –слова слова слова </h5><h5><h5><h5><h5> слова слова слова (2) </h5></h5></h5></h5><ul><ul><li> слова слова слова<strong> слова </strong> . All </li></ul></ul> <p> слова слова слова </p><p> слова слова слова </p><p><p><p> слова слова слова </p></p></p>
Просто брать и делать блоком замену через </p></p></p>|</p></p>|</p></p></p></p>
На </p> я могу, мне нужно понять как правильно сделать:
1) чтобы одна регулярка удовлетворила под не ограниченное количество одинаковых рядом стоящих тегов в плотную, между ними нет и не будет пробелов и слов, они все стоят вплотную </p></p></p> или <ul><ul> или </h5></h5></h5></h5> и т.д.
2) Нужно что-то подобного вида: [</h5>]{2,}
т.е. как сделать, чтобы регулярка ловила от 2 и более одинаковых тегов </h5> или <h5> или </p> и дальше сделать замену на один тег
Регулярка:Господа знатоки, подскажите, спарсил базу данных (больше 5к сайтов). Не могу найти способ убрать все слова после доменного имени (.com | .org | .co.uk) в урлах типа https://www.{имя сайта}.com/blog/2018/06/5-common-mistakes.
Необходимо очистить все эти категории и подкатегории и оставить голый адрес на домашнюю страницу :
(https://www.{имя сайта}.com).
Перерыл всё, что мог, очень надеюсь на ваш совет!
(https://|http://).*?(?=/.*/)Большое спасибо! А возможно ли в этот regexp добавить удаление дублей? Что бы не приходилось ставить кубик с обработкой списка.
