Redsmokky
Client
- Регистрация
- 06.10.2015
- Сообщения
- 321
- Реакции
- 197
- Баллы
- 43
Спасибо! То что доктор прописал)(?<=^|[.?!]\s*)[^\r\n.,?!]{25,60}(?=[.,?!])
как-то так
Держи: сочин.*?Народ, перепробовал варианты, но не смог получить результат, полагаюсь на ваши умы. Задача такая - имеется к примеру предложение :
"Если ты ищешь готовое сочинение по литературе - добро пожаловать!.
Требуется проверить в этом тексте наличие словоформы "сочин". Чтобы потом построить логику - по наличию данного текста, о чем идет речь.
P.s. по сути подходит это решение (?i)\bgo.*?(?=\W|\ |\r|\n|$) на примере выше. Но почему то у меня не выходит ничего, или я дико туплю. Помогите плиз.
Держи: сочин.*?
А теперь вопрос к знатокам - требуется при парсинге проверить текст на количество знаков, т.е. мне нужно парсить пост где есть минимум 250 символов. Подскажите, пожалуйста, регулярку.
А теперь вопрос к знатокам - требуется при парсинге проверить текст на количество знаков, т.е. мне нужно парсить пост где есть минимум 250 символов. Подскажите, пожалуйста, регулярку.
потому, что в красном кавадрате это скрипт!Ребята, вот текст
вот регулярка <![\w\W]*?</head> Этой регуляркой я удаляю текст который между <! и </head> . Почему она удаляет всё кроме того что в красном квадрате? Как это побороть?
Ка к его удалить? вот это <script[^>]*>.*?</script> и это <script>[\w\W]*?</script> не удаляетпотому, что в красном кавадрате это скрипт!
@jonvy ссыль на страницу где этот скрипт можно?post: 231709 написал(а):Ка к его удалить? вот это <script[^>]*>.*?</script> и это <script>[\w\W]*?</script> не удаляет
(?i)<script[^>]*>[\w\W]*?</script>Ка к его удалить? вот это <script[^>]*>.*?</script> и это <script>[\w\W]*?</script> не удаляет
возможно! Ктото уже писал про зависания при парсинге, возможно баг! Попробуйте повторить чтобы была ошибка и со скринами в тему о багах!Как так происходит? вот эта страница http://tajny-nlo.ru/dokazatelstva-prebyvaniya-inoplanetyan-zemle-0 вот регулярка <script[^>]*>.*?</script> и вчера она не удаляла всю эту хрень
jQuery.extend(Drupal.settings, {"basePath":"\/","pathPrefix":"","ajaxPageState":{"theme":"tajny_adaptive","theme_token":"mbbalgx6glPW6DC4HTytbpBrjkmZnP2U5k7orsxoMp8","jquery_version":"1.7","css":{"modules\/system\/system.base.css":1,"modules\/system\/system.menus.css":1,"modules\/system\/system.messages.css":1,"modules\/system\/system.theme.css":1,"sites\/all\/libraries\/mediaelement\/build\/mediaelementplayer.min.css":1,"misc\/ui\/jquery.ui.core.css":1,"misc\/ui\/jquery.ui.theme.css":1,"modules\/comment\/comment.css":1,"modules\/field\/theme\/field.css":1,"modules\/node\/node.css":1,"modules\/poll\/poll.css":1,"modules\/search\/search.css":1,"modules\/user\/user.css":1,"sites\/all\/modules\/video_filter\/video_filter.css":1,"modules\/forum\/forum.css":1,"sites\/all\/modules\/views\/css\/views.css":1,"sites\/all\/modules\/ckeditor\/css\/ckeditor.css":1,"sites\/all\/modules\/cctags\/cctags.css":1,"sites\/all\/modules\/ctools\/css\/ctools.css":1,"sites\/all\/modules\/dhtml_menu\/dhtml_menu.css":1,"sites\/all\/modules\/panels\/css\/panels.css":1,"sites\/all
А сегодня удаляет. Это почему так происходит?
После добавления регулярки, проект нужно запускать заново? или можно продолжать выполнение с только что добавленного кубика с регуляркой? Может в этом дело?
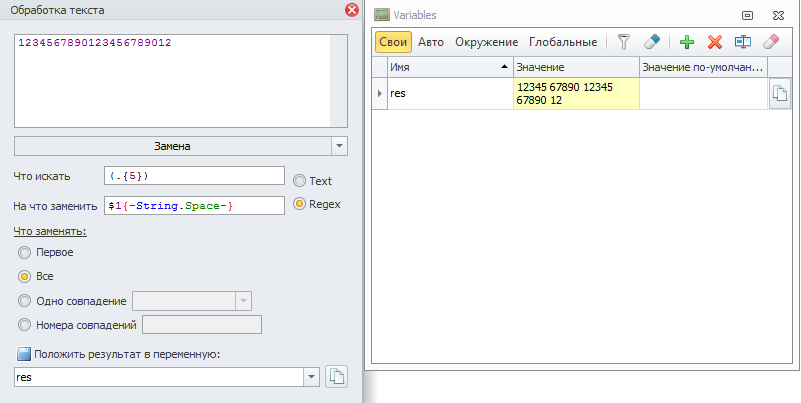
Подскажи регулярку, нужно разбить строку по каждому 5му символузамена \d{4,}$ на пустоту по регулярке
или \d{4,}\b
нужен не хвост, по каждому 5 символу чтобы разбить, у меня строка из 1000 символов ее нужно разбить по каждому 5 символу..{5}
или
.{1,5}
если нужен хвост, который меньше 5 символов
дай пример на короткой строкенужен не хвост, по каждому 5 символу чтобы разбить, у меня строка из 1000 символов ее нужно разбить по каждому 5 символу.
9azYx NCRj4 dCjnW 1nncr PbQVF YugfR aBiudGjKMOxtLXKNYehjXc0jYWAvLHIbyDPgRqeFWUmFPcTY5GM4NBOHVJQA4ZMq0VN6qlsc0EHtVrIqB4j3HRmo3XlFmlOIUgFDvncRzx4s8xZO8jD0zVsdfU2y0bCbX8bbjCRgnFmamrqn1PT8YOtA3jhJcyECnvkMBsorFgkYd0F9vztuLDLwZDzMvFLpqRD3DqWYjksiimf3Ryp11d2SRy6qKoIMc8xOtPddLnHkjWZahjduzKiGW0hv3jF7AdS9дай пример на короткой строке
9azYx NCRj4 dCjnW 1nncr PbQVF YugfR aBiudGjKMOxtLXKNYehjXc0jYWAvLHIbyDPgRqeFWUmFPcTY5GM4NBOHVJQA4ZMq0VN6qlsc0EHtVrIqB4j3HRmo3XlFmlOIUgFDvncRzx4s8xZO8jD0zVsdfU2y0bCbX8bbjCRgnFmamrqn1PT8YOtA3jhJcyECnvkMBsorFgkYd0F9vztuLDLwZDzMvFLpqRD3DqWYjksiimf3Ryp11d2SRy6qKoIMc8xOtPddLnHkjWZahjduzKiGW0hv3jF7AdS9
и так нужно разбить всю строку