Спасибо скачал архив с ParserDomens распаковал нашёл в выдаче под нужную мне тему Рабалка несколько доноров с ТОП 10, закинул их в файл Domens и Запустил - Зенку, добавил задание выбрав файл ParserDomens и пошла проверка доменов, пишет что Нужных данных в Вебархиве НЕТ оставляем типа для ручной проверки и переходим к другому доменупотом так с несколькими доменами прошло и только из 6 сайтов 1 нашёлся в Вебархиве и начилась проверка страниц и нашлось 1045 страниц и на этих страницах потихоньку находились дропы, но Дропы в файле Спаршенные домены повторяются и много раз повторяются и так как страниц много я в файле Чистая карта удалил много страниц оставил 145 штук, они проверялись, дропы находились, ну все одинаковые восновном несколько попалось разных, потом как парсинг был завершён и домены закончились в файле Domens, я зашёл в файл Спаршенные домены и там куча одинаковых доменов, ну я поудалял дубли и закинул файл Спаршенные домены в папку 200ОК, там какое то Приложение httpanswer, запустил его и где написано: ЗАДАЙТЕ ИСХОДНЫЙ ФАЙЛ я там выбрал место тоесть папку 200ОК и выбрал файл Спаршенные домены и нажал на кнопку СТАРТ, после чего увидел какие то подсчеты цифры побежали и вообщем когда всё приостановилось и не чего больше не происходило я посмотрел появились какие то файлы в папке 200ОК, файлы имеют названия: 2xx, 3xx, 4xx, 5xx, noanswer, other, что это за папки я так и не понял если честно, но зайдя в каждый из файлов увидел тоже самое почти что и в файле Спаршенные домены, тоесть по несколько раз повторяются одни и теже домены, причём в каждом файле, я кароче вручную УДАЛИЛ ДУБЛИ ДОМЕНОВ и НАЧАЛ ИХ ПРОВЕРЯТЬ И ВСЕ ОНИ ОКАЗАЛИСЬ ДОСТУПНЫ ТОЕСТЬ НА НИХ РАБОЧИЕ САЙТЫ В ИТОГЕ НЕ ОДНОГО ДРОПА Я ТАК И НЕ ДОБЫЛ!!! footashes- Скажите пожалуйста может я что то сделал не правильно???? и что значат эти файлы в папке 200ОК ??? Хочу по рыбалке Дропов найти и не получается!!!
Спасибо скачал архив с ParserDomens распаковал нашёл в выдаче под нужную мне тему Рабалка несколько доноров с ТОП 10, закинул их в файл Domens и Запустил - Зенку, добавил задание выбрав файл ParserDomens и пошла проверка доменов, пишет что Нужных данных в Вебархиве НЕТ оставляем типа для ручной проверки и переходим к другому доменупотом так с несколькими доменами прошло и только из 6 сайтов 1 нашёлся в Вебархиве и начилась проверка страниц и нашлось 1045 страниц и на этих страницах потихоньку находились дропы, но Дропы в файле Спаршенные домены повторяются и много раз повторяются и так как страниц много я в файле Чистая карта удалил много страниц оставил 145 штук, они проверялись, дропы находились, ну все одинаковые восновном несколько попалось разных, потом как парсинг был завершён и домены закончились в файле Domens, я зашёл в файл Спаршенные домены и там куча одинаковых доменов, ну я поудалял дубли и закинул файл Спаршенные домены в папку 200ОК, там какое то Приложение httpanswer, запустил его и где написано: ЗАДАЙТЕ ИСХОДНЫЙ ФАЙЛ я там выбрал место тоесть папку 200ОК и выбрал файл Спаршенные домены и нажал на кнопку СТАРТ, после чего увидел какие то подсчеты цифры побежали и вообщем когда всё приостановилось и не чего больше не происходило я посмотрел появились какие то файлы в папке 200ОК, файлы имеют названия: 2xx, 3xx, 4xx, 5xx, noanswer, other, что это за папки я так и не понял если честно, но зайдя в каждый из файлов увидел тоже самое почти что и в файле Спаршенные домены, тоесть по несколько раз повторяются одни и теже домены, причём в каждом файле, я кароче вручную УДАЛИЛ ДУБЛИ ДОМЕНОВ и НАЧАЛ ИХ ПРОВЕРЯТЬ И ВСЕ ОНИ ОКАЗАЛИСЬ ДОСТУПНЫ ТОЕСТЬ НА НИХ РАБОЧИЕ САЙТЫ В ИТОГЕ НЕ ОДНОГО ДРОПА Я ТАК И НЕ ДОБЫЛ!!! footashes- Скажите пожалуйста может я что то сделал не правильно???? и что значат эти файлы в папке 200ОК ??? Хочу по рыбалке Дропов найти и не получается!!!
Всё, что можно было неправильно сделать, было сделано на 99%. До футбола сделаю видео, перепишу помощь и разошлю. Насчет поисков дропов по рыбалке, попугаям и другим узким тематикам - ParserDomens работает по методике вероятностей - чем уже тематика, тем меньше шансов. Если у вас сайт по дрессировке жирафов - какая вероятность, что найдется ещё один такой брошенный сайт.
Это работает так - вы находите сайт по, например, здоровому образу жизни. Очень большая вероятность, что комментарии (со своей ссылкой) оставляют люди с такой же или близкой тематикой (как правило, так и есть). И очень большая вероятность, что многие эти сайты уже брошены. Парсер работает по методике - собирает ссылки и пишет в файл.
Всё, что можно было неправильно сделать, было сделано на 99%. До футбола сделаю видео, перепишу помощь и разошлю. Насчет поисков дропов по рыбалке, попугаям и другим узким тематикам - ParserDomens работает по методике вероятностеАй - чем уже тематика, тем меньше шансов. Если у вас сайт по дрессировке жирафов - какая вероятность, что найдется ещё один такой брошенный сайт.
Это работает так - вы находите сайт по, например, здоровому образу жизни. Очень большая вероятность, что комментарии (со своей ссылкой) оставляют люди с такой же или близкой тематикой (как правило, так и есть). И очень большая вероятность, что многие эти сайты уже брошены. Парсер работает по методике - собирает ссылки и пишет в файл.
а что конкретно я сделал не правильно почему я не говорю про Узкую тематику я назвал тематика Рыбалка а это не узная тематика я не сказал что мне нужны статьи по теме Зимняя рыбалка на Окуня или Зимняя рыбалка на Щуку и так далее что относится к Зимней рыбалке! Просто нету конретного видео по работе ParserDomens чтобы можно было наглядно смотреть и настраивать всё так же а ещё было бы лучше если голосом комментировать думаю всем кто покупал парсер у вас было бы Очень полезное данное видео!
Небольшой обзор, как работать с комплексом программ по Вебархиву (читайте помощь - 99.9% ответов на нестандартные ситуации находятся там). Покажу примеры работы парсера Вебархива - WebArchiveMasters V2.4 с примерами, разберем принцип работы ParserDomens - как он работает и за что отвечает, рассмотрим принцип восстановления сайта (с видео), вскользь затронем проверку через Text.ru и Content-watch, затронем и Дзен v2.2.
WebArchiveMasters - принцип работы (вкратце):
Забираем только текст, формируем данные для проверки на уникальность. Это основная задача Мастера Вебархива - забрать текст и подготовить его к проверке. Как это происходит:
Скачиваем все текста и формируем данные для проверки на уникальность.
Файлы складываем в домены, чтобы не путаться.
Формируем названия файлов
В готовом тексте находятся тайтлы (если они есть). Они нам нужны, чтобы было от чего отталкиваться при названии статьи. (продажа или использование для своих сайтов)
Есть много интересных решений по парсеру WebArchiveMasters. Например - дать выбор для парсинга определенного промежутка времени. Например, брать только текст с 2010 до 2013 годов (еще раз - парсер вебархива забирает весь текст, который может забрать на полном автомате. Именно для этого он и предназначен. Излишняя гибкость, чтобы дать пользователю управлять данными может сыграть злую шутку. Всегда можно сделать что-то не так).
Также можно вынести настройки проверки доменов, которые вы скачиваете списком с регистраторов просроченных доменов. Можно дать управление, что, если при проверке этого домена парсер нашел мало ссылок, занести этот домен в "черный список" и игнорировать его (эти проверки сделаны изначально, но они жестко "вшиты" и гласят - если в домене менее семи ссылок, игнорировать его, но не заносить в "черный список", а проверить, записать текст в домен и дать пользователю самому делать выбор - удалять эти файлы или нет.
Именно поэтому у вас в некоторых доменах по 5-6 текстов - это "мусорные" домены со списка регистраторов (даже по ключам). Тем не менее, они обрабатываются и вам решать - нужны они вам или нет. Для этих случаев вам нужно использовать методику на вероятностях, иначе у вас не хватит мощностей и времени для обработки.
Поэтому можно вынести ключевые настройки, чтобы дать выбор самим решать, нужно вам это или нет. Но это усложнит технику работы, так-как Мастер Вебархива предназначен просто запустить и забыть - он сам всё сделает.
Принцип работы ParserDomens - автоматизированная работа по методике. Здесь я покажу основные принципы работы:
attachFull30805
Принцип работы - вставляете домен и он забирает ссылки. Здесь много тонкостей - какой домен, какие ссылки (есть много разных конструкций, типа GOTO или SPF, и многие другие, которые вычисляются только на практике, сложные сниппеты здесь не помогут. Именно поэтому я прошу прислать логи Зеннопостера или нестандартный домен, так как я не могу объять необъятное (никто ничего не присылал).
Программа забирает домены со страницы (а их может быть и десятки и сотни). При работе программы не нужно ничего трогать.
Реализованна проверка на дубли, и, самое главное, "черный список" стандартных доменов - реклама, скрипты, cdn и т.д.
После получения доменов можно выбрать технические и скопировать в блеклист.
Принцип работы - получить структуированный сайт в формате HTML. Его нужно забросить на хостинг, со временем перенести на CMS. Либо сразу продать. Нужно заметить, что восстанавливать имеет смысл, если сайт действительно интересен и имеет смысл тратить на него время. В других случаях лучше просто забирать текст.
Небольшой видеообзор готового сайта:
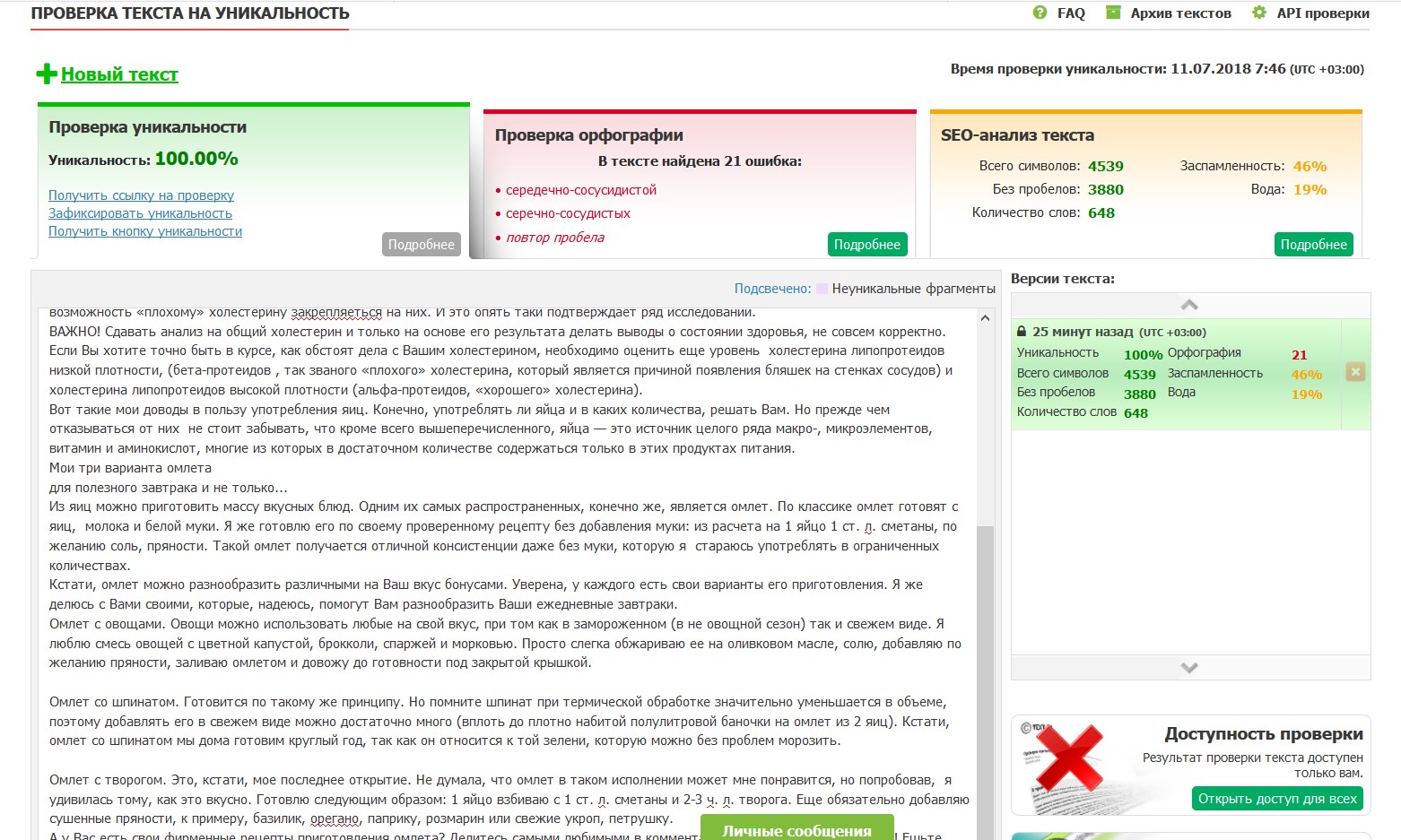
Принцип работы Textru и Content-watch - автоматическая проверка текста на уникальность с помощю прокси.
Проверка на уникальность:
Как я применяю применяю текста из Вебархива. Ищется тематика, набираются текста и проверяются на уникальность. Как только наберется достаточно статей, идем на Телдери и за копейки покупаем трастовый домен вашей тематики. Такой домен имеет вес в глазах ПС, также его можно добавить во все биржи.
Уникальный (оригинальный) текст имеет огромное значение для интернета. Такой текст вы всегда можете продать, использовать для своих сайтов, использовать для рекламодателей (ГГЛ, Ротапост, Миралинкс, Вебартекс), бирж покупки текстов (Етекст, ТекстСале и т.д.).
WebArchiveMastersV2.3 - парсер Вебархива + Дзен v2.2 + Антиплагиат + Мануал + Content Watch + ParserDomens. Восстановление всего сайта из Вебархива. Полностью готовый сайт, остается только залить на сервер. Пригодится для своих сайтов.
Цена - 500 рублей. Шаблон полностью открытый и без привязок.
Отправляю. Сегодня ночью будет описание принципов работы по всей ветке Вебархива. От Мастера Вебархива до проверки текстов и откровений работы с биржами и сайтами. Ну и много интересного. С примерами парсинга и жизненных примеров, что и как работает. Не пропустите.
Слишком много информации, форум такие данные распределяет по частям, поэтому, во избежание потери данных, перепишу в pdf.
П.С.
Небольшой срыв по срокам, приехали друзья - лето, жара, шашлыки, пляж - постараюсь сделать сегодня к вечеру в формате форума. Всё уже было подготовлено - видео, как я пришел к Вебархиву - и вот так.
Слишком много информации, форум такие данные распределяет по частям, поэтому, во избежание потери данных, перепишу в pdf.
П.С.
Небольшой срыв по срокам, приехали друзья - лето, жара, шашлыки, пляж - постараюсь сделать сегодня к вечеру в формате форума. Всё уже было подготовлено - видео, как я пришел к Вебархиву - и вот так.
Нужно больше информации - код ошибки или скриншот (на почту). Но так, навскидку - если используется постинг своих статей, у фото должно быть расширение .jpg, а не jpeg, JPG, bmp и т.д.
Нужно больше информации - код ошибки или скриншот (на почту). Но так, навскидку - если используется постинг своих статей, у фото должно быть расширение .jpg, а не jpeg, JPG, bmp и т.д.
Так, отправил, но на всякий продублирую. После этой правки регистр перестанет иметь значение. Вот так можно сделать - открыть Проджект Мекер, изменить свитч и сохранить проект. После этого будут правильно вставлятся картинки с расширением jpg и JPG (для Зеннопостера они считаются разными). Разумеется, самостоятельно руками расширение у файлов менять нельзя, иначе можно doc поменять на jpg и попробовать загрузить. Сразу возникнет надпись, что формат не поддерживается.
Возможно, у них было обновление серверов и данных. У меня сейчас все работает. Если вы используете домены по ключам, возможно, что в 90% там действительно нет данных, попробуйте посмотреть вручную. Как правило, это выглядит так:
Сегодня доделаю постер по фри блогам. Идея такая - вы публикуете статьи на своем сайте и их сразу нужно загнать в индекс. Загнать бота можно с трастовых блогов. Я раньше работал по такой схеме, это давало хорошие результаты. Работает по принципу плагина SNAP.
Пока подключил пять блогов, хочу сделать комбайн - минимум 20 фриблогов, все соцсети и чтобы всё отправлялось одним нажатием. Если есть интересные фриблоги, присылайте, я их попытаюсь подключить.
Тестовую версию разошлю через пару дней для тестирования. Если будет иметь смысл, то продолжу работу над шаблоном.
Что-то я немного не понял, как правильно прописать ссылку (т.е. как должна выглядеть ссылка) в Create full-text feed from feed or webpage URL - Enter URL
Что-то я немного не понял, как правильно прописать ссылку (т.е. как должна выглядеть ссылка) в Create full-text feed from feed or webpage URL - Enter URL
Всем отправил.
Несколько дней не смотрел почту, так-как нашел очень интересный сайт в Вебархиве (по методике), который имело смысл не просто восстановить или забрать с него тексты, но перенести на Вордпресс со всей структурой. Этим и был занят все это время.
WebArchiveMastersV2.4 - парсер Вебархива + Дзен v2.2 + Антиплагиат + Мануал + Content Watch + ParserDomens. Восстановление всего сайта из Вебархива. Полностью готовый сайт, остается только залить на сервер. Пригодится для своих сайтов.
Если вы хотите создать сайт или он у вас уже есть, рано или поздно вы столкнетесь с проблемой, где взять текста для сайта. Писать самому или платить на биржах (где очень много статей из Вебархива) не вариант - лучше научиться их добывать самому. Мне это сэкономило громадное количество денег, а по качеству многие статьи на порядок выше доморощенных писателей с бирж. Вообще, лично мое мнение, что поведенческие факторы интересных оригинальных статей из Вебархива гораздо важнее технической уникальности с бирж текста.
Это обновление для тех, кто брал здесь - https://primearea.biz/product/142100/. Если у вас версия Вебархива 2.4, то это последняя версия. Готовится v2.5, пока тестируется.
Сейчас делаю новую фичу по рассылке емейл - делаю для своего сайта, примерно 5000 входящих - тонкости работы опишу, но для пкупателей парсера Вебархива.
Работаю по серой схеме и правильной базе рассылок. Объясню покупателям, если будет интересно. По белому ничего не заработаешь.



 :-)")