



Оплатил на яндексWebArchiveMastersV2.3 - парсер Вебархива + Дзен v2.2 + Антиплагиат + Мануал + Content Watch + ParserDomens. Восстановление всего сайта из Вебархива. Полностью готовый сайт, остается только залить на сервер. Пригодится для своих сайтов.
Цена - 500 рублей. Шаблон полностью открытый и без привязок.
Вебмани: Z251978534905
Яндекс-Деньги: 410011187505134
Киви - +7 961 999‑51‑37
PayPal - footashes@gmail.com
Получил, спасибо за проделанную работу.WebArchiveMastersV2.3 - парсер Вебархива + Дзен v2.2 + Антиплагиат + Мануал + Content Watch + ParserDomens. Восстановление всего сайта из Вебархива. Полностью готовый сайт, остается только залить на сервер. Пригодится для своих сайтов.
Цена - 500 рублей. Шаблон полностью открытый и без привязок.
Вебмани: Z251978534905
Яндекс-Деньги: 410011187505134
Киви - +7 961 999‑51‑37
PayPal - footashes@gmail.com
- Регистрация
- 20.02.2015
- Сообщения
- 1 054
- Благодарностей
- 440
- Баллы
- 83
- Регистрация
- 20.02.2015
- Сообщения
- 1 054
- Благодарностей
- 440
- Баллы
- 83
Сделаем по другому. Теперь WebArchiveMastersV2.3 - парсер Вебархива + Дзен v2.2 + Антиплагиат + Мануал + Content Watch + ParserDomens. Восстановление всего сайта из Вебархива. Полностью готовый сайт, остается только залить на сервер. Пригодится для своих сайтов можно сразу получить при оплате - https://primearea.biz/product/134651/.
Небольшое дополнение - ParserDomens теперь заменяет устаревший Black Window Spider. В течении некоторого времени не смогу отвечать оперативно (1-2 недели) в связи с восстановлением диска. Алгоритм Криворучки полностью переписывается и тестируется на мобильных прокси, так-как они показывают наилучшие результаты.
Небольшое дополнение - ParserDomens теперь заменяет устаревший Black Window Spider. В течении некоторого времени не смогу отвечать оперативно (1-2 недели) в связи с восстановлением диска. Алгоритм Криворучки полностью переписывается и тестируется на мобильных прокси, так-как они показывают наилучшие результаты.

Двумя постами выше автор указал торговую площадку, где теперь продается этот продукт. Там возможны десятки способов оплаты: электронными деньгами, мобильными операторами, банковскими картами (VISA/MasterCard), различными платежными системами и т.п.Как насчёт PayPal? К сожалению нет ни WMZ ни WMR и нет возможности обменять.
Прошу прощения, прогляделДвумя постами выше автор указал торговую площадку, где теперь продается этот продукт. Там возможны десятки способов оплаты: электронными деньгами, мобильными операторами, банковскими картами (VISA/MasterCard), различными платежными системами и т.п.
 :-)")
- Регистрация
- 20.02.2015
- Сообщения
- 1 054
- Благодарностей
- 440
- Баллы
- 83
Продублирую - https://primearea.biz/product/134651/.Прошу прощения, проглядел
WebArchiveMastersV2.3 - парсер Вебархива + Дзен v2.2 + Антиплагиат + Мануал + Content Watch + ParserDomens. Восстановление всего сайта из Вебархива. Полностью готовый сайт, остается только залить на сервер. Пригодится для своих сайтов.
Для примера - восстановленный сайт из Вебархива. На Телдери после переноса на WordPress идут хорошо. Берут в основном женщинам, чтобы не начинать с нуля. Можно выставлять и так, но уже дешевле.
https://yadi.sk/d/faZZMKyw3VY4VM
P.S.
Возможно, чью-то почту проглядел, так-как забили ящик спамом. Кто-то нашел лазейку. т.к. ящик Гмайл.
P.P.S
Ответил всем.
Последнее редактирование:
player_kid
Client
- Регистрация
- 05.07.2017
- Сообщения
- 5
- Благодарностей
- 0
- Баллы
- 1
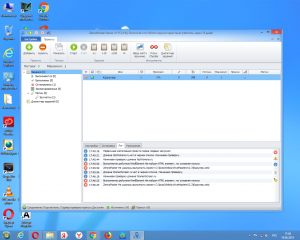
Здравствуйте! Вчера приобрел у вас парсер WebArchiveMasters. Все файлы скачал, инструкцию прочел, видео посмотрел. Поставил Open server и демо версию ZennoPoster RU 5.17.2.0. Все делал по инструкции но при запуске краулера в Зенно вылетает ошибка:
Выполнение действия HtmlElement Не найден HTML элемент, по условиям поиска
ZennoPoster Не удалось выполнить проект C:/bots/WebArchiveMastersV2.3/Краулер.xmlz
Прикрепляю скриншот ошибки
Пробовал запускать старую и новую версию WebArchiveMasters, результат один и тот же.
Еще у меня возникло два вопроса:
1) Почему в новой версии шаблона нет следующих документов:
Config.сfg
Kategory.сfg
scraper.txt
Zapros.сfg
Они есть в старой версии, и во всех мануалах, но в новой версии шаблона их нет. Они не нужны для работы новой версии?
2) Что означает парсер вебархива с "Входными Настройками"?
Выполнение действия HtmlElement Не найден HTML элемент, по условиям поиска
ZennoPoster Не удалось выполнить проект C:/bots/WebArchiveMastersV2.3/Краулер.xmlz
Прикрепляю скриншот ошибки
Пробовал запускать старую и новую версию WebArchiveMasters, результат один и тот же.
Еще у меня возникло два вопроса:
1) Почему в новой версии шаблона нет следующих документов:
Config.сfg
Kategory.сfg
scraper.txt
Zapros.сfg
Они есть в старой версии, и во всех мануалах, но в новой версии шаблона их нет. Они не нужны для работы новой версии?
2) Что означает парсер вебархива с "Входными Настройками"?
Вложения
-
 291 КБ Просмотры: 650
291 КБ Просмотры: 650
Viking01
Client
- Регистрация
- 19.08.2017
- Сообщения
- 247
- Благодарностей
- 186
- Баллы
- 43
хочу уточнить, шаблон парсит тексты из вебархива или восстанавливает полностью сайт?
если восстанавливает, то
а. есть ли возможность восстанавливать на конкретную дату (или до даты),
б. выкачивает ли кроме текста и картинок всякие js скрипты,
в. в каком формате возвращает готовый сайт, хтмл со структурой (ну то есть раскладывает по папочкам) или все в общей куче?
и последний интересный вопрос - этот комбайн работает только с ру или можно бурж совать (поиск контента, поиск дропов и пр)? ))
если восстанавливает, то
а. есть ли возможность восстанавливать на конкретную дату (или до даты),
б. выкачивает ли кроме текста и картинок всякие js скрипты,
в. в каком формате возвращает готовый сайт, хтмл со структурой (ну то есть раскладывает по папочкам) или все в общей куче?
и последний интересный вопрос - этот комбайн работает только с ру или можно бурж совать (поиск контента, поиск дропов и пр)? ))
Добрый день. Прошу помочь. Все работало нормально. Месяц шаблон не использовался. Настройки не менялись. Сейчас выдает ошибки:
Тип Время Сообщение
21:40:21 Количество текстовых ссылок: ~ 147
Тип Время Сообщение
21:40:22 Бесшаблонный парсер подключен неправильно
Тип Время Сообщение
21:43:47 ZennoPoster Не удалось выполнить проект C:\bots\WebArchiveMasters\Краулер.xmlz
прошу помочь.
Подскажите пожалуйста, по ссылке на версию WebArchiveMastersV2.3.rar в архиве находится файл domens.txt и все. Так и должно быть? Если нет, отправьте пожалуйста актуальную ссылку.
Тип Время Сообщение
21:40:21 Количество текстовых ссылок: ~ 147
Тип Время Сообщение
21:40:22 Бесшаблонный парсер подключен неправильно
Тип Время Сообщение
21:43:47 ZennoPoster Не удалось выполнить проект C:\bots\WebArchiveMasters\Краулер.xmlz
прошу помочь.
Подскажите пожалуйста, по ссылке на версию WebArchiveMastersV2.3.rar в архиве находится файл domens.txt и все. Так и должно быть? Если нет, отправьте пожалуйста актуальную ссылку.
- Регистрация
- 20.02.2015
- Сообщения
- 1 054
- Благодарностей
- 440
- Баллы
- 83
Пример восстановленного сайта:
Пример парсинга текстов с этого сайта (вчера делал) - https://zennolab.com/discussion/attachments/mamyprofi-ru-rar.30496/?temp_hash=8dcf93c34afc4bc6ffd2e8b4d1fc8f45
Нашел кучу интересных сайтов, попробую восстановить и почистить. Кто хочет попробовать себя в этом деле - велкам.
WebArchiveMastersV2.3 - парсер Вебархива + Дзен v2.2 + Антиплагиат + Мануал + Content Watch + ParserDomens. Восстановление всего сайта из Вебархива. Полностью готовый сайт, остается только залить на сервер. Пригодится для своих сайтов, можно сразу получить при оплате - https://primearea.biz/product/134651/.
Небольшое дополнение - ParserDomens теперь заменяет устаревший Black Window Spider. В течении некоторого времени не смогу отвечать оперативно (1-2 недели) в связи с восстановлением диска. Алгоритм Криворучки полностью переписывается и тестируется на мобильных прокси, так-как они показывают наилучшие результаты.
___________________________________________________________________
Добрый день. Прошу помочь. Все работало нормально. Месяц шаблон не использовался. Настройки не менялись. Сейчас выдает ошибки:
Тип Время Сообщение
21:40:21 Количество текстовых ссылок: ~ 147
Тип Время Сообщение
21:40:22 Бесшаблонный парсер подключен неправильно
Тип Время Сообщение
21:43:47 ZennoPoster Не удалось выполнить проект C:\bots\WebArchiveMasters\Краулер.xmlz
Сегодня скачал текста с сайта. ZennoPoster v5.17.2.0 тоже. Если используете v5.17.2.0, ставьте браузер в настройкак Фаерфокс 45, иначе будет много мусора.
21:40:22 Бесшаблонный парсер подключен неправильно - нет подключения к full-text-rss - он должен стоять на сервере или Опен Сервере. Самое главное - добавляйте 200-300 заданий, тогда при потере доступа к скрипту шаблон будет его постоянно запрашивать, и когда он ответит, пойдет дальше. У вас видимо стоит одно задание, поэтому при любом сбое задание заканчивается и программа останавливается.
Подскажите пожалуйста, по ссылке на версию WebArchiveMastersV2.3.rar в архиве находится файл domens.txt и все. Так и должно быть? Если нет, отправьте пожалуйста актуальную ссылку.
Попробуйте использовать новый архиватор - вчера скачал и запустил - всё работает, как и должно, вчерашние текста приложил. Попробуйте почитать WebArchiveMasters.pdf, как правило, этого бывает достаточно.
____________________________________________
хочу уточнить, шаблон парсит тексты из вебархива или восстанавливает полностью сайт?
если восстанавливает, то
а. есть ли возможность восстанавливать на конкретную дату (или до даты),
б. выкачивает ли кроме текста и картинок всякие js скрипты,
в. в каком формате возвращает готовый сайт, хтмл со структурой (ну то есть раскладывает по папочкам) или все в общей куче?
и последний интересный вопрос - этот комбайн работает только с ру или можно бурж совать (поиск контента, поиск дропов и пр)? ))
Восстанавливает полностью - скрипты, стили и т.д. Текст парсит на любом языке.
P.S.
Если кто работает с AMS и нужно быстро импортировать сотни и тысячи релеев, быстренько для себя написал шаблон импорта.
Файл "Емейлы.txt" - сюда ложим емейлы с паролями (через точку с запятой - kasparovanatasha70@mail.ru;Ls1c91DIawtfx), файл "Готовые релеи.LST" - сюда будут записываться готовые к импорту релеи), файл "Релеи.txt" - служебный (основной шаблон импорта).
Пример парсинга текстов с этого сайта (вчера делал) - https://zennolab.com/discussion/attachments/mamyprofi-ru-rar.30496/?temp_hash=8dcf93c34afc4bc6ffd2e8b4d1fc8f45
Нашел кучу интересных сайтов, попробую восстановить и почистить. Кто хочет попробовать себя в этом деле - велкам.
WebArchiveMastersV2.3 - парсер Вебархива + Дзен v2.2 + Антиплагиат + Мануал + Content Watch + ParserDomens. Восстановление всего сайта из Вебархива. Полностью готовый сайт, остается только залить на сервер. Пригодится для своих сайтов, можно сразу получить при оплате - https://primearea.biz/product/134651/.
Небольшое дополнение - ParserDomens теперь заменяет устаревший Black Window Spider. В течении некоторого времени не смогу отвечать оперативно (1-2 недели) в связи с восстановлением диска. Алгоритм Криворучки полностью переписывается и тестируется на мобильных прокси, так-как они показывают наилучшие результаты.
___________________________________________________________________
Добрый день. Прошу помочь. Все работало нормально. Месяц шаблон не использовался. Настройки не менялись. Сейчас выдает ошибки:
Тип Время Сообщение
21:40:21 Количество текстовых ссылок: ~ 147
Тип Время Сообщение
21:40:22 Бесшаблонный парсер подключен неправильно
Тип Время Сообщение
21:43:47 ZennoPoster Не удалось выполнить проект C:\bots\WebArchiveMasters\Краулер.xmlz
Сегодня скачал текста с сайта. ZennoPoster v5.17.2.0 тоже. Если используете v5.17.2.0, ставьте браузер в настройкак Фаерфокс 45, иначе будет много мусора.
21:40:22 Бесшаблонный парсер подключен неправильно - нет подключения к full-text-rss - он должен стоять на сервере или Опен Сервере. Самое главное - добавляйте 200-300 заданий, тогда при потере доступа к скрипту шаблон будет его постоянно запрашивать, и когда он ответит, пойдет дальше. У вас видимо стоит одно задание, поэтому при любом сбое задание заканчивается и программа останавливается.
Подскажите пожалуйста, по ссылке на версию WebArchiveMastersV2.3.rar в архиве находится файл domens.txt и все. Так и должно быть? Если нет, отправьте пожалуйста актуальную ссылку.
Попробуйте использовать новый архиватор - вчера скачал и запустил - всё работает, как и должно, вчерашние текста приложил. Попробуйте почитать WebArchiveMasters.pdf, как правило, этого бывает достаточно.
____________________________________________
хочу уточнить, шаблон парсит тексты из вебархива или восстанавливает полностью сайт?
если восстанавливает, то
а. есть ли возможность восстанавливать на конкретную дату (или до даты),
б. выкачивает ли кроме текста и картинок всякие js скрипты,
в. в каком формате возвращает готовый сайт, хтмл со структурой (ну то есть раскладывает по папочкам) или все в общей куче?
и последний интересный вопрос - этот комбайн работает только с ру или можно бурж совать (поиск контента, поиск дропов и пр)? ))
Восстанавливает полностью - скрипты, стили и т.д. Текст парсит на любом языке.
P.S.
Если кто работает с AMS и нужно быстро импортировать сотни и тысячи релеев, быстренько для себя написал шаблон импорта.
Файл "Емейлы.txt" - сюда ложим емейлы с паролями (через точку с запятой - kasparovanatasha70@mail.ru;Ls1c91DIawtfx), файл "Готовые релеи.LST" - сюда будут записываться готовые к импорту релеи), файл "Релеи.txt" - служебный (основной шаблон импорта).
Вложения
-
279,7 КБ Просмотры: 681
-
24 КБ Просмотры: 439
Последнее редактирование:
ЛевТроцкий
Пользователь
- Регистрация
- 19.12.2017
- Сообщения
- 43
- Благодарностей
- 1
- Баллы
- 8
А можете помочь с установкой собственного сервера для парсера веб архива? Делаю как в инструкции, но что-то все не работает. Программу скачал, а вот как подключить ее к парсеру не пойму
- Регистрация
- 20.02.2015
- Сообщения
- 1 054
- Благодарностей
- 440
- Баллы
- 83
Там всё элементарно. Если вы установили скрипт full-text-rss на поддомене http://feed.cheerfulness.ru, то так и пишите во входящих настройках, если на локальном сервере, то пишите: http://full-text-rss/. Скрипт full-text-rss, находящийся в папке, нужно перенести на локальный сервер или хостинг. Программа будет к нему обращаться для парсинга. Я сейчас использую Open Server, который запускаю на своем компьютере, копирую туда скрипт full-text-rss и во входящих настройках прописываю путь к нему - http://full-text-rss. Кому-то удобнее создать поддомен своего сайта и закинуть скрипт на хостинг, после чего прописать путь к поддомену.А можете помочь с установкой собственного сервера для парсера веб архива? Делаю как в инструкции, но что-то все не работает. Программу скачал, а вот как подключить ее к парсеру не пойму
ЛевТроцкий
Пользователь
- Регистрация
- 19.12.2017
- Сообщения
- 43
- Благодарностей
- 1
- Баллы
- 8
- Регистрация
- 20.02.2015
- Сообщения
- 1 054
- Благодарностей
- 440
- Баллы
- 83
Какая версия Зеннопостер? Сделано под 5.9.9.1 и выше с Фаерфокс 45. Ниже версию нельзя. Ошибок вообще не встречал, скиньте скрин на почту или логи. Или видео.У меня пишет что "Выполнение действия HtmlElement Не найден HTML элемент, по условиям поиска
"
ЛевТроцкий
Пользователь
- Регистрация
- 19.12.2017
- Сообщения
- 43
- Благодарностей
- 1
- Баллы
- 8
Я разобрался, именно тогда, когда подключил свой сервер, у меня подключились прокси с которых веб архив был заблокирован, после смены прокси все заработало. Извините, что отвлек)
- Регистрация
- 20.02.2015
- Сообщения
- 1 054
- Благодарностей
- 440
- Баллы
- 83
Завтра будет обновление WebArchiveMastersV2.3 под версию Зеннопостер 5.17.2.0 с браузером Фаерфокс 52, так-как Фаерфокс 42 устарел и Вебархив его не пускает на некоторые сайты. Обновление не критичное.
Совет дня - для поиска доменов используйте методику нахождения дропов - у вас просто не хватит ресурсов перелопатить все брошенные домены даже по ключам, чтобы найти интересующее, так-как там 90 процентов мусора.
Всем отправил. Кто не получил - пишите на почту footashes@gmail.comЗавтра будет обновление WebArchiveMastersV2.3 под версию Зеннопостер 5.17.2.0 с браузером Фаерфокс 52, так-как Фаерфокс 42 устарел и Вебархив его не пускает на некоторые сайты. Обновление не критичное.
Совет дня - для поиска доменов используйте методику нахождения дропов - у вас просто не хватит ресурсов перелопатить все брошенные домены даже по ключам, чтобы найти интересующее, так-как там 90 процентов мусора.
Последнее редактирование:
- Регистрация
- 20.02.2015
- Сообщения
- 1 054
- Благодарностей
- 440
- Баллы
- 83
Тут есть тонкости - урл должны быть такими же, вложенность, теги, комментарии. Я переносил в полуавтоматическом режиме, но тут без Зеннопостера не обойтись. Сделать шаблон и переносить на автомате. Или Кворк. Или Яндекс. Лично мне проще почистить HTML и продать.Ребят, кто подскажет как перенести контент с HTML на WordPress? А именно выкачал сайт с вебархива, а ручками 900 страниц на вордпресс перенести как-то нудновато)
Webfrilanser
Новичок
- Регистрация
- 07.12.2017
- Сообщения
- 23
- Благодарностей
- 0
- Баллы
- 1
Здравствуйте вы мне присылали письмо в котором была ссылка на скачивание ParserDomens, но та ссылка ведёт на Яндекс диск и битая оказалась, когда скачиваеш файл с ошибкой скачивается и я так и не смог скачать этот - ParserDomens, я у вас уже покупал WebArchiveMastersV2.3 можете мне прислать на мою почту: webfrilanser777@gmail.com архив с ParserDomens и Дзен v2.2 если есть что то нового в архивах - Антиплагиат + Мануал + Content Watch то тоже прошу мне их скинуть! Спасибо!Продублирую - https://primearea.biz/product/134651/.
WebArchiveMastersV2.3 - парсер Вебархива + Дзен v2.2 + Антиплагиат + Мануал + Content Watch + ParserDomens. Восстановление всего сайта из Вебархива. Полностью готовый сайт, остается только залить на сервер. Пригодится для своих сайтов.
Для примера - восстановленный сайт из Вебархива. На Телдери после переноса на WordPress идут хорошо. Берут в основном женщинам, чтобы не начинать с нуля. Можно выставлять и так, но уже дешевле.
https://yadi.sk/d/faZZMKyw3VY4VM
P.S.
Возможно, чью-то почту проглядел, так-как забили ящик спамом. Кто-то нашел лазейку. т.к. ящик Гмайл.
P.P.S
Ответил всем.
- Регистрация
- 20.02.2015
- Сообщения
- 1 054
- Благодарностей
- 440
- Баллы
- 83
Отправил, но в базе вы есть. Только что проверил - всё скачивается и распаковывается. Используется новый архиватор, старый распаковать не сможет.Здравствуйте вы мне присылали письмо в котором была ссылка на скачивание ParserDomens, но та ссылка ведёт на Яндекс диск и битая оказалась, когда скачиваеш файл с ошибкой скачивается и я так и не смог скачать этот - ParserDomens, я у вас уже покупал WebArchiveMastersV2.3 можете мне прислать на мою почту: webfrilanser777@gmail.com архив с ParserDomens и Дзен v2.2 если есть что то нового в архивах - Антиплагиат + Мануал + Content Watch то тоже прошу мне их скинуть! Спасибо!