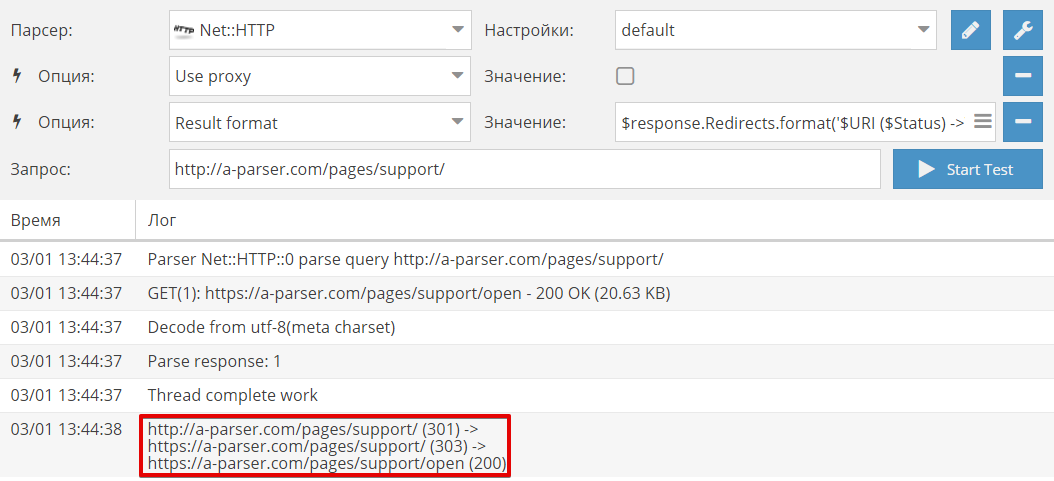
A-Parser Support
Активный пользователь
- Регистрация
- 03.06.2013
- Сообщения
- 344
- Благодарностей
- 32
- Баллы
- 28
1.2.455 - поддержка puppeteer, все методы в Net::HTTP, обновление Bypass Cloudflare
Начиная с версии 1.2.455 мы начинаем официальную поддержку Node.JS модуля puppeteer - средства автоматизации работы с браузером Chrome(Chromium), благодаря чему возможен полноценный рендеринг DOM с поддержкой JS. В качестве примера мы выкладываем парсер, который делает скриншоты сайтов в формате PNG, доступен выбор размера скриншота. Chromium может быть запущен как на Windows, так и на Linux серверах без GUI.
Улучшения
Исправления в связи с изменениями в выдаче
Исправления
Начиная с версии 1.2.455 мы начинаем официальную поддержку Node.JS модуля puppeteer - средства автоматизации работы с браузером Chrome(Chromium), благодаря чему возможен полноценный рендеринг DOM с поддержкой JS. В качестве примера мы выкладываем парсер, который делает скриншоты сайтов в формате PNG, доступен выбор размера скриншота. Chromium может быть запущен как на Windows, так и на Linux серверах без GUI.
Улучшения
-
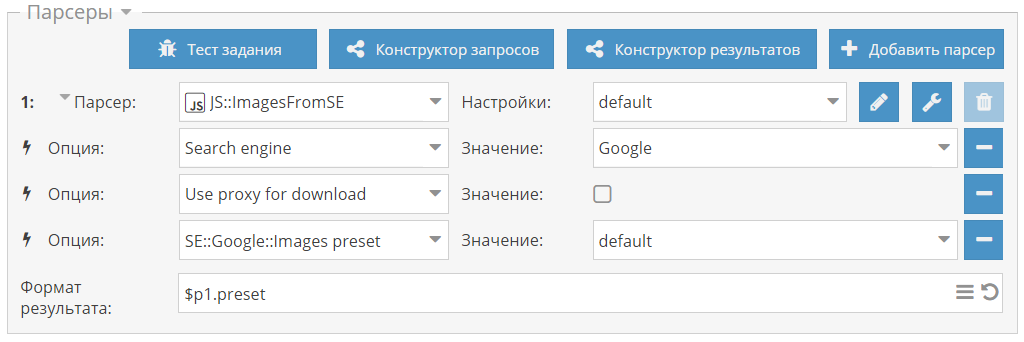
SE::Bing::Images полностью переписан, добавлен сбор дополнительных данных, а также в настройках добавлен выбор региона и языка интерфейса

- В
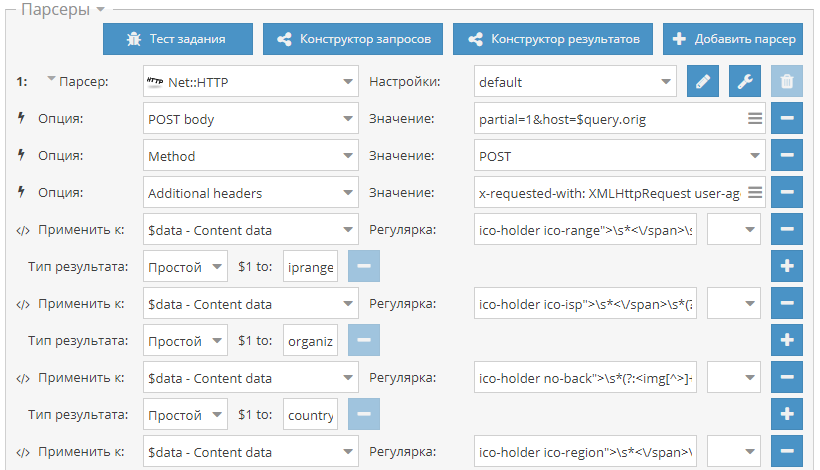
Net::HTTP добавлены все методы в настройки, а также реализована возможность переопределения через заголовок Method

- Добавлена возможность форматирования всех цифр в интерфейсе
- JS парсеры: в this.parser.request для override добавлена опция needData, которая определяет передавать или нет в ответе data/pages[], может использоваться для оптимизации
- JS парсеры: добавлена поддержка модулей url и ws
Исправления в связи с изменениями в выдаче
-
Net::Whois - не всегда корректно обрабатывалась доменная зона com.br

-
SE::Yandex,
 SE::Ask,
SE::Ask, SE:: DuckDuckGo,
SE:: DuckDuckGo, SE:: DuckDuckGo::Images,
Rank::MajesticSEO
SE:: DuckDuckGo::Images,
Rank::MajesticSEO
Исправления
- Исправлена работа функции Bypass Cloudflare в
Net::HTTP
- Исправлена ошибка, из-за которой при определенных настройках не писался Начальный текст
- Исправлена работа некоторых socks4 прокси
- Исправлена ошибка в $tools.base64.encode() при работе с кириллическими символами
- В
Shop::Amazon исправлена ошибка, при которой игнорировался домен

- JS парсеры: исправлена редкая ошибка в работе сокетов в Node.js

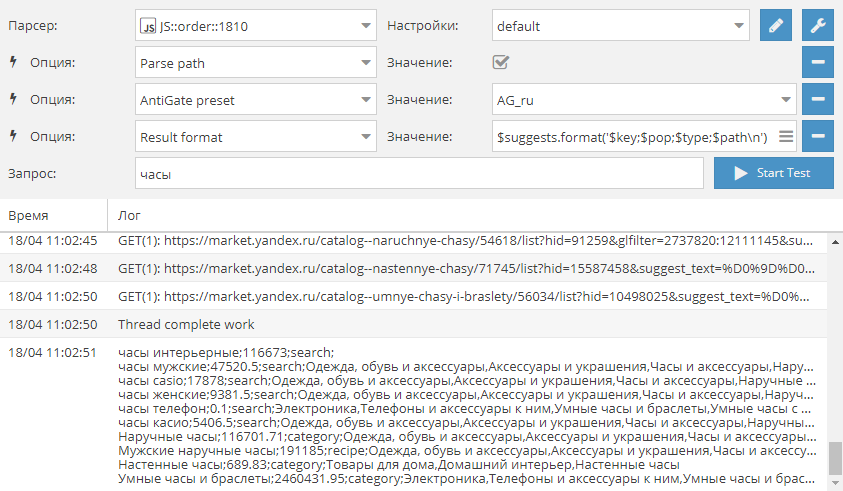





 osition, Rank::MegaIndex
osition, Rank::MegaIndex













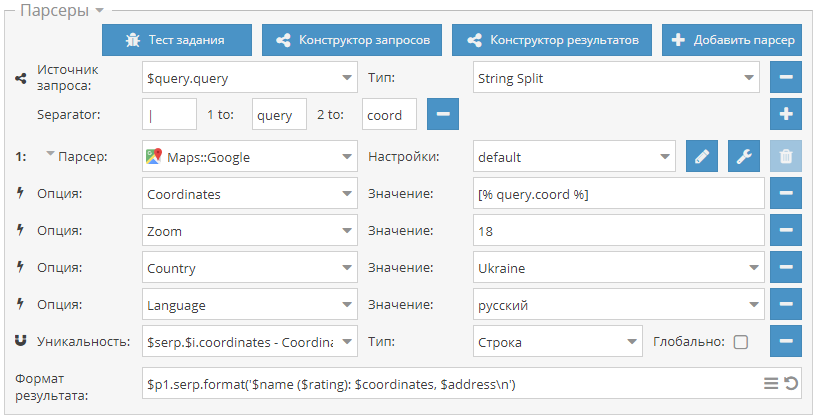

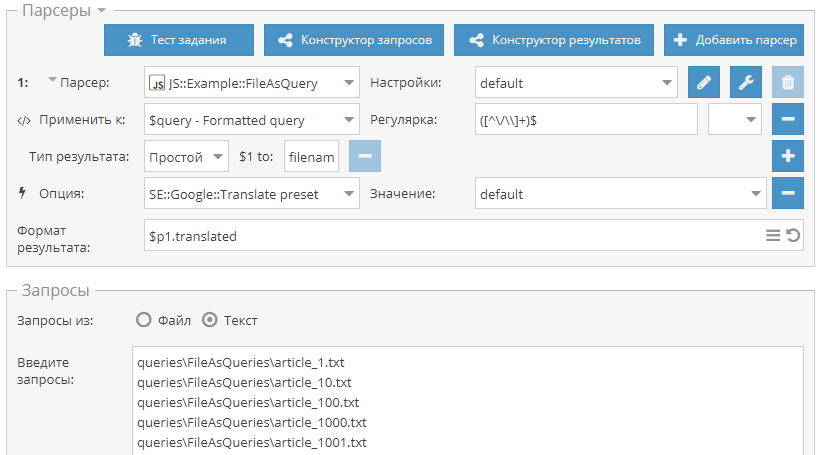









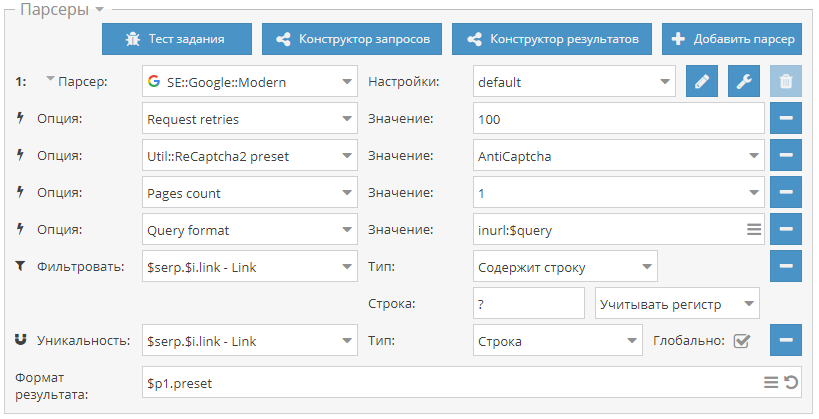
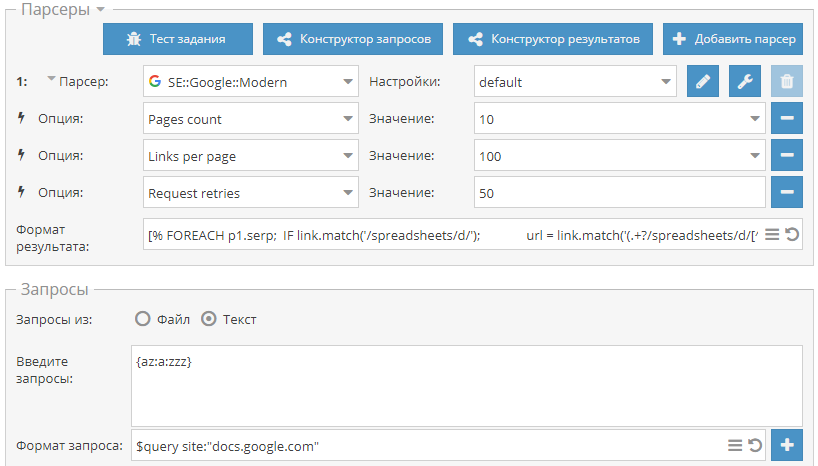
 :-)") ) - отписывайтесь
) - отписывайтесь 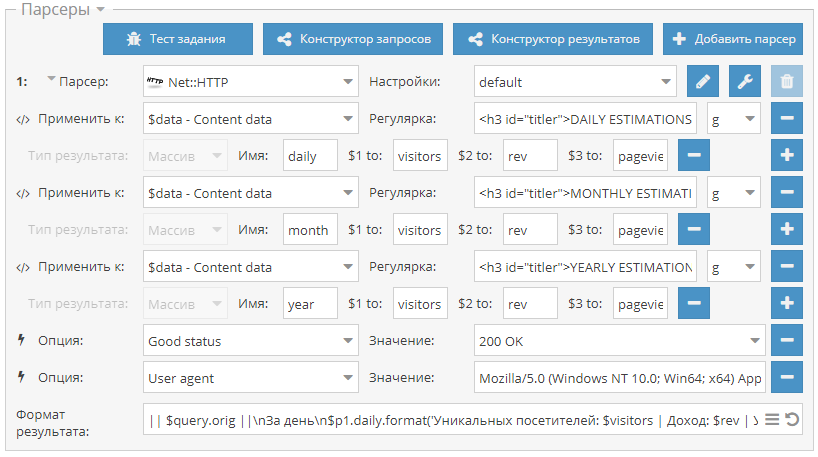
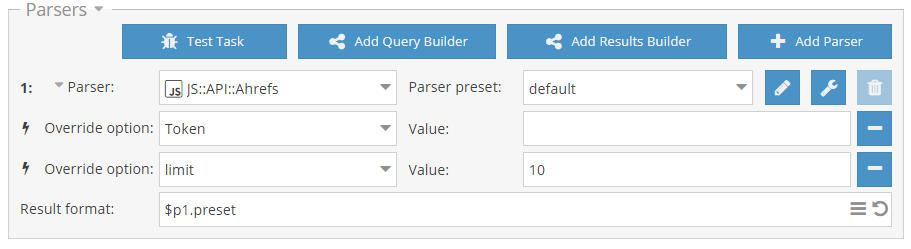












 Rank::Ahrefs
Rank::Ahrefs Util::ReCaptcha2
Util::ReCaptcha2 Rank::Bukvarix::*
Rank::Bukvarix::* SE::Rambler
SE::Rambler Social::Instagram:
Social::Instagram: Social::Instagram::Tag
Social::Instagram::Tag











 Telegram::GroupScraper
Telegram::GroupScraper Shop::eBay
Shop::eBay