



- Регистрация
- 01.10.2015
- Сообщения
- 256
- Благодарностей
- 1 058
- Баллы
- 93
Приветствую всех!  :-)")
Сразу предупреждаю, что данная статья сугубо техническая (возможно, даже слишком для этого конкурса манимейкерских статей ). Так что если что, неподготовленным умам рекомендую сразу покидать топик, не стоит мучать себя.
). Так что если что, неподготовленным умам рекомендую сразу покидать топик, не стоит мучать себя.
Кратко о стандартных lock'ах
Если вам приходилось использовать сниппеты работы со списками, таблицами и буфером обмена, наверняка много раз видели, что такие блоки кода помещаются в специальные конструкции, которые гарантируют правильную работу с указаными ресурсами в многопоточном режиме. В кубики подобные конструкции вставлены по умолчанию, просто мы их не видим.
Если один из потоков шаблона попадает внутрь такой конструкции, то остальные потоки, дойдя до этого блока, остановятся, пока первый не выйдет из него.
Проще говоря, код внутри фигурных скобок после lock(SyncObjects.ListSyncer) выполняется потоками последовательно, в этих участках многопотока как такового нет. Этот момент гарантирует, что целевым ресурсом (н-р, файлом или буфером обмена) одновременно занимается только один поток, ибо в ином случае можно словить ошибки.
Вспоминая популярную аналогию - через
Для популярных типов внешних ресурсов в ZennoPoster предусмотрено три объекта синхронизации, которые в C#-коде указываются в круглых скобках после lock:
SyncObjects.ListSyncer - для списков
SyncObjects.TableSyncer - для таблиц
SyncObjects.InputSyncer - для буфера обмена
Разные объекты синхронизации нужны для того, чтобы иметь возможность блокировать доступ к разным ресурсам, и их блокировки между собой никак не пересекались.
Допустим, у нас шаблон работает с 1 списком и 1 таблицей, привязанных к файлам. Если использовать для них обоих 1 объект синхронизации, то может возникнуть такая ситуация: пока один поток работает со списком, другой поток подошел к работе с таблицей, но не может её начать - так как соответствующий код заблокирован тем же объектом, что и код работы со списком.
Чтобы такого не было, для каждого типа ресурса в ZennoPoster используется свой объект синхронизации. В результате получаем, что ситуация, когда один поток работает со списком, а другой с таблицей - нормальная и позволительная, а ситуация, когда 2 потока работают со списком - запрещена и невозможна, так как может привести к сбоям.
Проблема стандартных локов
С вышеописанной базой, думаю, всё понятно. Но давайте рассмотрим другую ситуацию.
Допустим, в проекте 10 списков, каждый из них привязан к своему собственному файлу.
Если лочить работу с каждым из них конструкцией lock (SyncObjects.ListSyncer) { ... }, то в многопотоке велика вероятность случится подобной ситуации:
Один поток начал работать, скажем, со списком №5, в этот момент другой поток дошёл до работы со списком №8. Что начинает делать другой поток? Ждать, когда первый поток закончит работу с пятым списком, так как оба лока блокируются одним и тем же объектом синхронизации.
Согласитесь, ситуация не совсем нормальная, так как списки (и, соответственно, файлы) совершенно разные, и второй поток ждать первого по-хорошему не должен. В перспективе это значит, что когда какой-то поток работает с одним списком, другие потоки могут "подтормаживать" не только на подходе к этому, но и ко всем другим спискам.
Если обратится к аналогии - пока через один из турникетов в метро кто-то проходит, соседние турникеты никого не пускают.
Если вы создаёте шаблоны только на кубиках - эта проблема касается и вас тоже, так как в них явно используются те же стандартные объекты синхронизации (на 100% всё же сказать не могу, т.к. не проверял, но вряд ли там используются другие объекты).
Проблема пересечения с другими шаблонами
Но это ещё не всё. Объекты SyncObjects.ListSyncer, SyncObjects.TableSyncer, SyncObjects.InputSyncer берутся из библиотечки Global.dll, что в нашем случае значит, что одни и те же объекты синхронизации применяются не только к разным потокам одного шаблона, но и вообще ко всем запущенным шаблонам.
То есть, если в одном запущенном шаблоне блокируется список с помощью стандартного лока, то совершенно другой работающий шаблон с совершенно другими списками (но стандартными локами) будет ждать первый шаблон, прежде чем начать работу со своими списками.
Если снова обратиться к аналогии - пока через один турникет кто-то проходит, все остальные турникеты (в том числе других станций метро) никого не пускают.
В определенных ситуациях такое положение дел оправдано. Например, буфер обмена компьютера один на все работающие шаблоны, он и должен лочиться для всех. Также, разные шаблоны могут работать с одним файлом, и тут один лок на все шаблоны тоже именно то, что нужно.
Однако, в случае с разными файлами списков или таблиц, такое устройство выглядит, скажем так, довольно неоптимизированным.
Решение
Что же можно сделать?
С кубиками, к сожалению, ничего не сделать, а вот с кодом - можно. Необходимо создать свои собственные объекты синхронизации в Общем коде. По умолчанию там даже один уже есть:
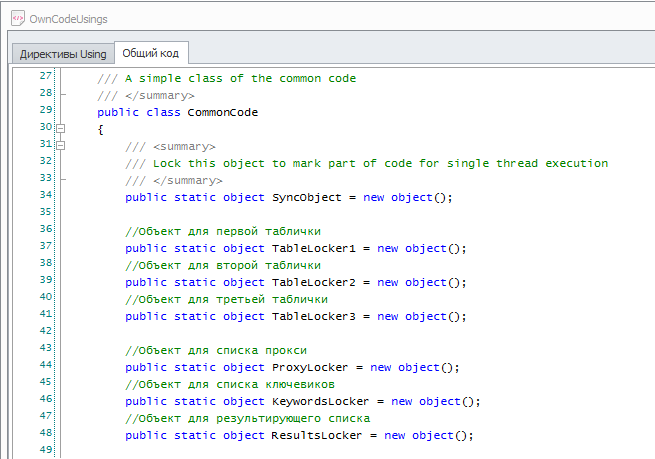
Допустим, у нас в шаблоне 3 таблицы и 3 списка, привязанные к своим файлам. В этом случае рекомендуется создать по объекту на каждый файл.
Далее можно использовать их в коде C#-сниппетов:
Как результат - в многопоточном режиме у нас точно ни один поток зазря подтормаживать не будет. Также, как другие шаблоны не смогут влиять на текущий, так и текущий на другие - у всех свои собственные локи под каждый файл.
Вот мы и научились небольшой оптимизации проектов для многопотока и одновременной работе нескольких шаблонов.
PS
Стоит отметить, что данная проблема (торможение потоков на разных файлах при стандартных локах) в большинстве случаев не такая страшная, как может показаться. Блокируются обычно только минимальные операции, например, добавление строки в список (то есть очень быстрые и короткие по времени), поэтому оптимизировав свои шаблоны с помощью вышеописанного способа, особых изменений можно и не заметить.
Реальные улучшения, как правило, встречаются в следующих ситуациях:
1) когда выполняются операции с ооооочень большими файлами;
2) когда используются "кривые" сниппеты - то есть, лочится не отдельная операция (н-р, добавление строки в таблицу), а целый набор операций (н-р, цикл добавления 100500 строк в таблицу).
Тем не менее, надеюсь, что вам статья придётся по вкусу, хотя бы чисто для расширения кругозора в сфере разработки на ZennoPoster.
Сразу предупреждаю, что данная статья сугубо техническая (возможно, даже слишком для этого конкурса манимейкерских статей
). Так что если что, неподготовленным умам рекомендую сразу покидать топик, не стоит мучать себя. Кратко о стандартных lock'ах
Если вам приходилось использовать сниппеты работы со списками, таблицами и буфером обмена, наверняка много раз видели, что такие блоки кода помещаются в специальные конструкции, которые гарантируют правильную работу с указаными ресурсами в многопоточном режиме. В кубики подобные конструкции вставлены по умолчанию, просто мы их не видим.
C#:
//Лочим код изменения списка для многопотока
lock (SyncObjects.ListSyncer){
//Добавляем в список "Список 1" элемент со значением "строка"
project.Lists["Список 1"].Add("строка");
}Проще говоря, код внутри фигурных скобок после lock(SyncObjects.ListSyncer) выполняется потоками последовательно, в этих участках многопотока как такового нет. Этот момент гарантирует, что целевым ресурсом (н-р, файлом или буфером обмена) одновременно занимается только один поток, ибо в ином случае можно словить ошибки.
Вспоминая популярную аналогию - через
Для популярных типов внешних ресурсов в ZennoPoster предусмотрено три объекта синхронизации, которые в C#-коде указываются в круглых скобках после lock:
SyncObjects.ListSyncer - для списков
SyncObjects.TableSyncer - для таблиц
SyncObjects.InputSyncer - для буфера обмена
Разные объекты синхронизации нужны для того, чтобы иметь возможность блокировать доступ к разным ресурсам, и их блокировки между собой никак не пересекались.
Допустим, у нас шаблон работает с 1 списком и 1 таблицей, привязанных к файлам. Если использовать для них обоих 1 объект синхронизации, то может возникнуть такая ситуация: пока один поток работает со списком, другой поток подошел к работе с таблицей, но не может её начать - так как соответствующий код заблокирован тем же объектом, что и код работы со списком.
Чтобы такого не было, для каждого типа ресурса в ZennoPoster используется свой объект синхронизации. В результате получаем, что ситуация, когда один поток работает со списком, а другой с таблицей - нормальная и позволительная, а ситуация, когда 2 потока работают со списком - запрещена и невозможна, так как может привести к сбоям.
Проблема стандартных локов
С вышеописанной базой, думаю, всё понятно. Но давайте рассмотрим другую ситуацию.
Допустим, в проекте 10 списков, каждый из них привязан к своему собственному файлу.
Если лочить работу с каждым из них конструкцией lock (SyncObjects.ListSyncer) { ... }, то в многопотоке велика вероятность случится подобной ситуации:
Один поток начал работать, скажем, со списком №5, в этот момент другой поток дошёл до работы со списком №8. Что начинает делать другой поток? Ждать, когда первый поток закончит работу с пятым списком, так как оба лока блокируются одним и тем же объектом синхронизации.
Согласитесь, ситуация не совсем нормальная, так как списки (и, соответственно, файлы) совершенно разные, и второй поток ждать первого по-хорошему не должен. В перспективе это значит, что когда какой-то поток работает с одним списком, другие потоки могут "подтормаживать" не только на подходе к этому, но и ко всем другим спискам.
Если обратится к аналогии - пока через один из турникетов в метро кто-то проходит, соседние турникеты никого не пускают.
Если вы создаёте шаблоны только на кубиках - эта проблема касается и вас тоже, так как в них явно используются те же стандартные объекты синхронизации (на 100% всё же сказать не могу, т.к. не проверял, но вряд ли там используются другие объекты).
Проблема пересечения с другими шаблонами
Но это ещё не всё. Объекты SyncObjects.ListSyncer, SyncObjects.TableSyncer, SyncObjects.InputSyncer берутся из библиотечки Global.dll, что в нашем случае значит, что одни и те же объекты синхронизации применяются не только к разным потокам одного шаблона, но и вообще ко всем запущенным шаблонам.
То есть, если в одном запущенном шаблоне блокируется список с помощью стандартного лока, то совершенно другой работающий шаблон с совершенно другими списками (но стандартными локами) будет ждать первый шаблон, прежде чем начать работу со своими списками.
Если снова обратиться к аналогии - пока через один турникет кто-то проходит, все остальные турникеты (в том числе других станций метро) никого не пускают.
В определенных ситуациях такое положение дел оправдано. Например, буфер обмена компьютера один на все работающие шаблоны, он и должен лочиться для всех. Также, разные шаблоны могут работать с одним файлом, и тут один лок на все шаблоны тоже именно то, что нужно.
Однако, в случае с разными файлами списков или таблиц, такое устройство выглядит, скажем так, довольно неоптимизированным.
Решение
Что же можно сделать?
С кубиками, к сожалению, ничего не сделать, а вот с кодом - можно. Необходимо создать свои собственные объекты синхронизации в Общем коде. По умолчанию там даже один уже есть:
Допустим, у нас в шаблоне 3 таблицы и 3 списка, привязанные к своим файлам. В этом случае рекомендуется создать по объекту на каждый файл.
Далее можно использовать их в коде C#-сниппетов:
C#:
lock (CommonCode.ProxyLocker){
project.Lists["Прокси"].Add(proxy);
}
//...тут некий код
lock (CommonCode.KeywordsLocker){
project.Lists["Ключевики"].Clear();
}
//...тут некий код
lock (CommonCode.ResultsLocker){
project.Lists["Results"].AddRange(results);
}Вот мы и научились небольшой оптимизации проектов для многопотока и одновременной работе нескольких шаблонов.
PS
Стоит отметить, что данная проблема (торможение потоков на разных файлах при стандартных локах) в большинстве случаев не такая страшная, как может показаться. Блокируются обычно только минимальные операции, например, добавление строки в список (то есть очень быстрые и короткие по времени), поэтому оптимизировав свои шаблоны с помощью вышеописанного способа, особых изменений можно и не заметить.
Реальные улучшения, как правило, встречаются в следующих ситуациях:
1) когда выполняются операции с ооооочень большими файлами;
2) когда используются "кривые" сниппеты - то есть, лочится не отдельная операция (н-р, добавление строки в таблицу), а целый набор операций (н-р, цикл добавления 100500 строк в таблицу).
Тем не менее, надеюсь, что вам статья придётся по вкусу, хотя бы чисто для расширения кругозора в сфере разработки на ZennoPoster.
- Тема статьи
- Другое
- Номер конкурса статей
- Восьмой конкурс статей
Для запуска проектов требуется программа ZennoPoster или ZennoDroid.
Это основное приложение, предназначенное для выполнения автоматизированных шаблонов действий (ботов).
Подробнее...
Для того чтобы запустить шаблон, откройте нужную программу. Нажмите кнопку «Добавить», и выберите файл проекта, который хотите запустить.
Подробнее о том, где и как выполняется проект.

 Было и интересно и актуально,возьму на вооружение для своих проектов.
Было и интересно и актуально,возьму на вооружение для своих проектов.







