


2 место Регулярные выражения, что это такое и с чем их едят?
- Автор темы ZennoScript
- Дата начала

trapni
Client
- Регистрация
- 16.10.2013
- Сообщения
- 299
- Благодарностей
- 22
- Баллы
- 18
Что-то не получается....Код:htt.*?/[\d]+/[\d]+/[\d\/]+$
- Регистрация
- 04.03.2011
- Сообщения
- 4 452
- Благодарностей
- 1 889
- Баллы
- 113
http://site.ru/2015/11/03/
http://site.ru/2015/11/04/
http://site.ru/2015/11/11/stat-stat/
http://site.ru/2015/12/11/stat1-stat1/
Подскажите пожалуйста, реально ли как-то удалить строку(и) только с числами, т.е первую и вторую? Получить только "stat-stat/", "stat1-stat1/" или две последние строки целиком? Или проще говоря, как избавиться от двух верхних строк )) ?
Код:
http.*?/[\d/]+(?=[\r\n$])YrKa
Client
- Регистрация
- 20.04.2015
- Сообщения
- 220
- Благодарностей
- 113
- Баллы
- 43
Спасибо за статью. Очень полезная.[\.\-_A-Za-z0-9]+?@[\.\-A-Za-z0-9]+?[\.A-Za-z0-9]{2,} - найдет все email;
Но не находит емаилы с дефисом "-" после @, например, info@wer-1324.com выпарсит только info@wer. Подскажите, плиз, регулярку для этого?
- Регистрация
- 04.03.2011
- Сообщения
- 4 452
- Благодарностей
- 1 889
- Баллы
- 113
Спасибо за статью. Очень полезная.
Но не находит емаилы с дефисом "-" после @, например, info@wer-1324.com выпарсит только info@wer. Подскажите, плиз, регулярку для этого?
Код:
[\.\-_A-Za-z0-9]+?@[\.\-A-Za-z0-9-]+?[-\.A-Za-z0-9]{2,}Подскажите пожалуйста
Есть строки такого формата:
Купить, продать, сшить, оформить, зачем, привет, пока, ля-ля
Купить, оренда, форма, оформить, зачем, запрет, привет
Мне нужно достать текст:
привет, пока, ля-ля
запрет, привет
Как это сделать? Тоесть после 5-й запятой
Есть строки такого формата:
Купить, продать, сшить, оформить, зачем, привет, пока, ля-ля
Купить, оренда, форма, оформить, зачем, запрет, привет
Мне нужно достать текст:
привет, пока, ля-ля
запрет, привет
Как это сделать? Тоесть после 5-й запятой
Dimionix
Moderator
- Регистрация
- 09.04.2011
- Сообщения
- 3 068
- Благодарностей
- 3 140
- Баллы
- 113
Подскажите пожалуйста
Есть строки такого формата:
Купить, продать, сшить, оформить, зачем, привет, пока, ля-ля
Купить, оренда, форма, оформить, зачем, запрет, привет
Мне нужно достать текст:
привет, пока, ля-ля
запрет, привет
Как это сделать? Тоесть после 5-й запятой
Код:
(?<=(.*,\ ){5}).*Подскажите как спарсить часть из мыла идущую перед @
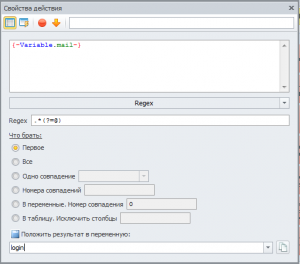
Саму регулярку я сделал, но как взять это прямо из переменной?
Нужно чтобы часть перед @ вставлялась в качестве логина на сайте.
У меня получилась такая регулярка .*(?=@){-Variable.mail-}
В переменной {-Variable.mail-} как раз лежит мыло.
Но эта регулярка работает неверно) Что не так делаю?
Саму регулярку я сделал, но как взять это прямо из переменной?
Нужно чтобы часть перед @ вставлялась в качестве логина на сайте.
У меня получилась такая регулярка .*(?=@){-Variable.mail-}
В переменной {-Variable.mail-} как раз лежит мыло.
Но эта регулярка работает неверно) Что не так делаю?
Подскажите пожалуйста, как почистить текст от линков и доменов которые без http и www. ?
Чисто на домен я нашел как - [A-Za-z0-9а-яА-Я]+\.(com|ru|net|org|cn|рф|fm|ua|ру), а вот что бы удаляло - такой линк - Contentsgoldcoastdjs.com/wp/11/Maid-of-Honor-and-Bridesmaid-Speeches.pdf , не знаю.
Чисто на домен я нашел как - [A-Za-z0-9а-яА-Я]+\.(com|ru|net|org|cn|рф|fm|ua|ру), а вот что бы удаляло - такой линк - Contentsgoldcoastdjs.com/wp/11/Maid-of-Honor-and-Bridesmaid-Speeches.pdf , не знаю.
Mikhail B.
Client
- Регистрация
- 23.12.2014
- Сообщения
- 14 449
- Благодарностей
- 5 477
- Баллы
- 113
Обращаем Ваше внимание на то, что данный пользователь заблокирован.
Не рекомендуем проводить с Mikhail B. какие-либо сделки.
[A-Za-z0-9а-яА-Я]+/.(com|ru|net|org|cn|рф|fm|ua|ру|pdf)
Предположительно...
Предположительно...
Последнее редактирование:
Такое сделал, но опять же не универсальная чистка [A-Za-z0-9а-яА-Я]+\.(com|ru|net|org|cn|рф|fm|info|ua|us|ру)/.*/[A-Za-z0-9а-яА-Я]*-.*\.[A-Za-z0-9а-яА-Я]*[A-Za-z0-9а-яА-Я]+/.(com|ru|net|org|cn|рф|fm|ua|ру|pdf)
Предположительно...
Mikhail B.
Client
- Регистрация
- 23.12.2014
- Сообщения
- 14 449
- Благодарностей
- 5 477
- Баллы
- 113
Обращаем Ваше внимание на то, что данный пользователь заблокирован.
Не рекомендуем проводить с Mikhail B. какие-либо сделки.
Лучше здесь спросить.Такое сделал, но опять же не универсальная чистка [A-Za-z0-9а-яА-Я]+\.(com|ru|net|org|cn|рф|fm|info|ua|us|ру)/.*/[A-Za-z0-9а-яА-Я]*-.*\.[A-Za-z0-9а-яА-Я]*
http://zennolab.com/discussion/threads/reguljarnye-vyrazhenija-na-vse-sluchai-zhizni.20829/page-5
- Регистрация
- 04.03.2011
- Сообщения
- 4 452
- Благодарностей
- 1 889
- Баллы
- 113
Такое сделал, но опять же не универсальная чистка [A-Za-z0-9а-яА-Я]+\.(com|ru|net|org|cn|рф|fm|info|ua|us|ру)/.*/[A-Za-z0-9а-яА-Я]*-.*\.[A-Za-z0-9а-яА-Я]*
Код:
[A-Za-z0-9а-яА-Я-\.]+.(com|ru|net|org|cn|рф|fm|info|ua|us|ру)\S*contract2003
Новичок
- Регистрация
- 09.04.2014
- Сообщения
- 20
- Благодарностей
- 0
- Баллы
- 1
- Регистрация
- 05.09.2012
- Сообщения
- 22 812
- Благодарностей
- 10 226
- Баллы
- 113
http://zennolab.com/discussion/threads/vopros-po-reguljarnomu-vyrazheniju.26198/#post-182023Подскжите как взять первый или второй вариант регуляркой???
Botlab.su
Client
- Регистрация
- 06.04.2015
- Сообщения
- 145
- Благодарностей
- 21
- Баллы
- 18
Здравствуйте!Символьные обозначения:
«.» - любой символ, кроме переноса строки(\n);
«\d» - цифровой символ, т.е. любая цифра от 0 до 9;
«[0-9]» - цифровой диапазон - отличается от \d тем, что в данном виде есть возможность указать не любой цифровой символ, а используя диапазоны, например [1-3], который найдет только цифры 1, 2 и 3;
«\D» - не цифровой символ. Т.е. все символы - буквенные и пробелы, кроме цифр;
«\s» -все пробельные символы, которые могут включать в себя:
- пробел «\ »;
- новая страница «\f»;
- возврат каретки «\r»;
- новая строка «\n»;
- знак табуляции «\t»;
- знак вертикальной табуляции «\v»;
«\S» - не пробельный символ, т.е. все буквы, цифры и знаки. Всё, что не перечислено выше, как пробельные символы.
«\w» - буквенный или цифровой символ или знак подчёркивания.
«\W» - любой символ, кроме буквенного или цифрового символа или знака подчёркивания.
Обозначения границ:
^ - начало строки;
$ - конец строки;
\b - граница слова;
\B - не граница слова.
К примеру, нам нужно проверить, содержит ли строка слово “Красный”, прописав в конструкторе «красный», мы можем получить так же и другие слова, в которые входит данное слово, такие как “прекрасный” и т.д. Что бы этого не происходило, необходимо прописать \bкрасный\b - таким образом, все слова, которые могут быть похожи на искомое учитываться не будут.
Не граница слова, соответственно, работает наоборот. К примеру, мы знаем, что слово должно заканчиваться на “жили”, но само слово “жили” нам не нужно, тогда мы прописываем \Bжили и получаем список слов с нужным нам окончанием - дорожили, выжили и т.д.
Обозначения количества совпадений (Квантификаторы):
{5} - ровно 5;
{1,5} - от 1 до 5 включительно;
{1,} - от 1 и более;
? - ноль или одно, так же соответствует {0,1};
* - ноль или более, так же соответствует {0,};
+ - Одно или более, так же соответствует {1,}.
Квантификаторы устанавливаются после символов, число повторений которых необходимо задать.
Возьмём для примера точку, которая обозначает любой символ, и составим регулярное выражение, которому будет соответствовать любая последовательность из 4 символов. Результат будет выглядеть таким образом: .{4}
Так можно указать, что внутри искомого текста имеется установленное или неограниченное число повторений установленных символов, т.е.:
с.{2}л - такое регулярное выражение найдёт такие слова, как стол, стул и т.д., но ему так же будет соответствовать строка, имеющая в середине пробелы, цифры и прочее.
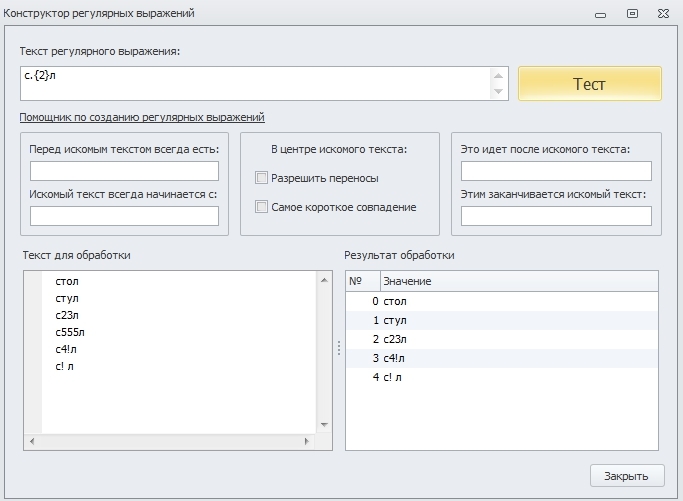
Для того, чтобы указать, что внутри будут только буквы, необходимо прописать таким образом:
c[а-я]{2}л

Так же можно задать определённую последовательность или набор символов, которые должны учитываться. Для этого используются квадратные скобки, внутри которых прописываются диапазоны, или наборы символов.
Для указания диапазонов используется тире между значениями. Для перечисления, символы просто прописываются в строку без каких либо разделителей.
[a-zA-Z1-5абв] - данная последовательность обозначает любую английскую букву в верхнем и нижнем регистре, числа от 1 до 5 включительно, а так же русские буквы а, б и в.
Регулярное выражение будет иметь такой вид:
с[тоу]{2}л
Мы обозначаем, что после буквы “с” идут 2 любых символа, указанных в квадратных скобках и данная последовательность найдёт слова стол и стул, но ему так же будут соответствовать последовательности букв “суул”, “сутл” и прочие.
Модификаторы:
(?i) - включает нечувствительность выражения к регистру символов;
(?-i) - выключает нечувствительность выражения к регистру символов.
Используя данные модификаторы, мы можем указывать регулярному выражению, важен ли нам регистр символов при поиске совпадений. Отключив регистр в начале регулярного выражения, мы его выключаем для всех последующих совпадений в строке.
Пример использования:
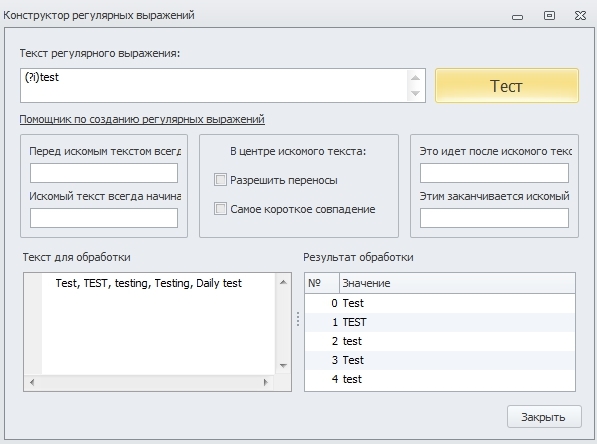

Так же бывают случаи, когда в одном месте регистр для нас не важен, а в другом важен.
Пример использования:
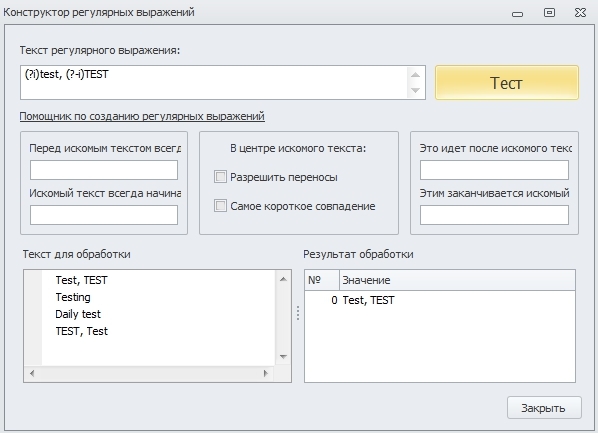
Данное регулярное выражение найдёт строку “Test, TEST”, т.к. у первой фразы включена нечувствительность к регистру и она находит все совпадения, но не найдёт “TEST, Test”, т.к. во второй фразе должно быть точное совпадение по регистру.
Модификаторы многострочного поиска:
(?m) - включает многострочный поиск
(?-m) - отключает многострочный поиск
Для того чтобы найти все строки, начинающиеся с не пробельного символа, подойдёт такое регулярное выражение:
(?m)^\S.*
Символы, которые должны экранироваться, для того, чтобы они учитывались в регулярном выражении как текст, а не как часть регулярного выражения (метасимволы):
^ [ . $ { *
( \ + ) | ?
При использовании данных символов в регулярном выражении, как части текста, они должны экранироваться знаком \.
К примеру, если в тексте у вас должен находиться знак вопроса, он обозначается как \?
Хочу попросить помочь мне исправить ошибки, возникаемые при работе регулярного выражения [\.\-_A-Za-z0-9]+?@[\.\-A-Za-z0-9]+?[\.A-Za-z0-9]{2,}
Файл со ссылками на страницы, и с емейлами, извлеченными с этих страниц прикрепил. Спасибо
Вложения
-
6,4 КБ Просмотры: 540
Botlab.su
Client
- Регистрация
- 06.04.2015
- Сообщения
- 145
- Благодарностей
- 21
- Баллы
- 18
Исправил сам. Вот регулярное выражение, которое все обрабатывает нормально [\.\-_A-Za-z0-9]+?@[\.\-A-Za-z0-9]+\.[\.A-Za-z0-9]{2,} Исправьте его пожалуйста в посте.Здравствуйте!
Хочу попросить помочь мне исправить ошибки, возникаемые при работе регулярного выражения [\.\-_A-Za-z0-9]+?@[\.\-A-Za-z0-9]+?[\.A-Za-z0-9]{2,}
Файл со ссылками на страницы, и с емейлами, извлеченными с этих страниц прикрепил. Спасибо
kagorec
Client
- Регистрация
- 24.08.2013
- Сообщения
- 1 136
- Благодарностей
- 654
- Баллы
- 113
\D - неЦифры, замени на пусто
Код:
stringTest=project.Variables["peremennaya"].Value;
stringregexTest=System.Text.RegularExpressions.Regex.Replace(Test,@"drugoe chtoto|\D","");
returnregexTest;Gamma
Client
- Регистрация
- 14.05.2016
- Сообщения
- 83
- Благодарностей
- 10
- Баллы
- 8
Всем привет. Тему вроде понял, запилил регулярку под свой проект, в тестере всё работает и нужное мне значение нашёл, перенёс регулярку в экшн "обработка текста - regex - {-Page.Dom-}" и спарсеное совпадение в переменную... запускаю проект - переменная пустая, не могу понять почему. Помогите.
Моя регулярка:
Скрины:


Моя регулярка:
Код:
(?<=\ \ <div\ class="item-params\ c-1">\n\s+)[0-9][\w\W]*?(?=\ </div>)Gamma
Client
- Регистрация
- 14.05.2016
- Сообщения
- 83
- Благодарностей
- 10
- Баллы
- 8
Заработало)) Иногда решение некоторых действий настолько простое... часа три сидел голову ломал над этим....попробуй убрать \n
doc
Client
- Регистрация
- 30.03.2012
- Сообщения
- 8 685
- Благодарностей
- 4 652
- Баллы
- 113
это приходит с опытом. я на этом не раз обжигался, когда кубик и конструктор по разному воспринимают эти символыЗаработало)) Иногда решение некоторых действий настолько простое... часа три сидел голову ломал над этим....
- Регистрация
- 04.03.2011
- Сообщения
- 4 452
- Благодарностей
- 1 889
- Баллы
- 113
Только в последней версии программы возникла такая ситуация. Раньше никогда не попадалось ситуаций, чтобы что то по разному работало в конструкторе и ПМ.это приходит с опытом. я на этом не раз обжигался, когда кубик и конструктор по разному воспринимают эти символы
doc
Client
- Регистрация
- 30.03.2012
- Сообщения
- 8 685
- Благодарностей
- 4 652
- Баллы
- 113
у меня предпоследняя, но в принципе, это, наверно, одно и тоже. Последняя что-то типа хотфиксаТолько в последней версии программы возникла такая ситуация. Раньше никогда не попадалось ситуаций, чтобы что то по разному работало в конструкторе и ПМ.