

Nord
Client
- Регистрация
- 22.03.2012
- Сообщения
- 2 423
- Благодарностей
- 1 485
- Баллы
- 113
Взять в переменную совпадение по регуляркеНе совсем понял, как использовать?
Взять в переменную совпадение по регуляркеНе совсем понял, как использовать?
(\d+) ₽$ Не даёт результат регулярка, да и короткаяВзять в переменную совпадение по регулярке
\s\d+?(?=\s₽)(\d+) ₽$ Не даёт результат регулярка, да и короткая
Товарищи помогите решить проблему. Есть список, нужно получить цену.
(?<=-\ ).*?(?=\ ₽\ ) Этой регуляркой получаю, но если в строке ещё одна цифра, то результат такой "134 (KS слюда) - 50"
Как получать только последнее число в строке?
Космос (KS картон) - 50 ₽
Родоппи ( KS картон) - 50 ₽
Opal (KS слюда) - 50 ₽
Ту - 134 (KS слюда) - 50 ₽
var s = project.Variables["trash"].Value;
return Regex.Match(s, @"(\d+)(?=\s*₽)", RegexOptions.RightToLeft).Value ?? "null";
(\d+)(?=\s*₽)Не совсем понял, как использовать?
Подскажите, пожалуйста, как составить регулярку, которая будет определять с заглавной ли буквы (кириллица) написано первое слово фразы или со строчной?
Задача - отсортировать в таблице строки, в которых в определенном столбце прописаны фразы, у которых и нужно определить - заглавная первая буква или строчная.
Спасибо огромное )^[А-Я] - с заглавной
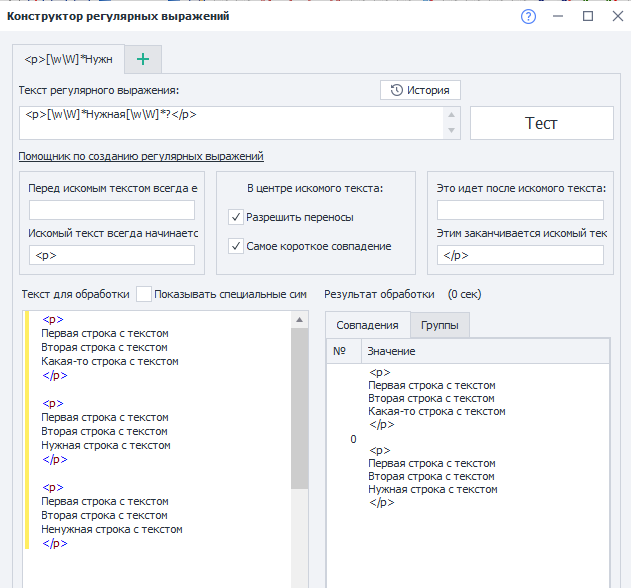
<p>
Первая строка
Вторая строка
Какая-то строка
</p>
<p>
Первая строка
Вторая строка
Нужная строка
</p>
<p>
Первая строка
Вторая строка
Ненужная строка
</p>Нет, так не работает.может точки не хватает? я не могу сейчас проверить <p>[\w\W]*Нужная[\w\W].*?</p>
Спасибо, так пашет! А не подскажите как называются эти галочки в скобочках? Как найти про них почитать подробнее?<p>([^<]*\bНужная\b[^<]*)<\/p>
Символ ^ в квадратных скобках ставится перед тем символом, которого не должно быть в искомом фрагменте текста.Спасибо, так пашет! А не подскажите как называются эти галочки в скобочках? Как найти про них почитать подробнее?
Тут нужно создать словарь в котором вы руками пропишите все возможные варианты и соответственно все возможные варианты на которые надо заменитьРебят, требуется регулярное выражение для EmEditor. Оно у меня будет сложным, но мне хотя бы важно разобраться с его принципом. И так, требуется найти все слова целиком вне зависимости от регистра "аа" и заменить их на "аб", при этом сохранив регистр заменяемого слова. То есть, исходное слово может быть: аа, АА, Аа, аА.
Для "Найти", вот хотя бы есть рабочие вариант:
\b[Аа][Аа]\b
\b([Аа])([Аа])\b
А заменить каким выражением?
Для приведённого примера, результат работы выражения должен преобразовать в: аб, АБ, Аб, аБ.
string[] aaDictionary = { "aa","AA","Aa","aA" };
string[] abDictionary = { "ab","AB","Ab", "aB" };
string str = project.Variables["text"].Value;
int i = 0;
while (i < abDictionary.Length)
{
str = str.Replace(aaDictionary[i], abDictionary[i]);
i++;
}
return str;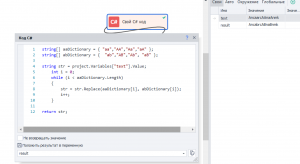
Возможно, длинный составной класс class="tgme_widget_message_footer\ compact\ js-message_footer" и/или class="tgme_widget_message_photo поменялся.Уважаемые форумчане. Есть регулярка, которая парсила с канала урл, картинку, описание и короткую ссылку, затем складывала все в таблицу; но в определенный момент она перестала работать, прошу помощи!
Канал в телеграмме https://t.me/s/darom_ali
Регулярка: (?<=<a\ class="tgme_widget_message_photo_wrap)[\w\W]*?(https://t\.me/darom_ali/.*?(?="))[\w\W]*?(https://cdn4\.telegram\-cdn\.org/.*?(?='))[\w\W]*?((?<=<b>).*?(?=<br>))[\w\W]*?((?<=<a\ href=")[\w\W]*?(?="))[\w\W]*?()[\w\W]*?(?=<div\ class="tgme_widget_message_footer\ compact\ js-message_footer">)
Подскажите пожалуйста, где в ней ошибка почему перестала работать?
То есть у меня должно остаться 252,00
\S+(?=\s)Оправка - после первого знаска |Код:\S+(?=\s)
Попробуйте не регуляркой, а методом Split. Как мне кажется, в этой ситуации он более подходящий)Оправка - после первого знаска |
Т.к. тесты показали, что если попадется числовое значение записанное таким боразом - 2 579,00 грн то в переменную сохраняется только двойка.
Спс за помощь
Используй специализированные библиотеки для парсинга HTML. Погугли HtmlAgilityPack для C#. Должно помочь.Уважаемые знатоки! Помогите, пжлста, с регуляркой, которая будет искать незакрытые теги </p>. Столкнулся с такой напастью, что после парсинга сайта попадаются статьи, где у некоторых предложений отсутствует закрывающий тег </p>. Нужна регулярка которая будет проставлять закрывающие теги, вот пример:
<h2>здесь какой то текст</h2>
<p>здесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текст.
<p>здесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текст:
<ul>
<li>здесь какой то текст</li>
<li>здесь какой то текст</li>
</ul>
<p>здесь какой то текстздесь какой то текстздесь какой то текст
<p>здесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текст</p>
<p>здесь какой то текстздесь какой то текстздесь какой то текст
<p>здесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текст</p>
string text = project.Variables["HTML"].Value;Уважаемые знатоки! Помогите, пжлста, с регуляркой, которая будет искать незакрытые теги </p>. Столкнулся с такой напастью, что после парсинга сайта попадаются статьи, где у некоторых предложений отсутствует закрывающий тег </p>. Нужна регулярка которая будет проставлять закрывающие теги, вот пример:
<h2>здесь какой то текст</h2>
<p>здесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текст.
<p>здесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текст:
<ul>
<li>здесь какой то текст</li>
<li>здесь какой то текст</li>
</ul>
<p>здесь какой то текстздесь какой то текстздесь какой то текст
<p>здесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текст</p>
<p>здесь какой то текстздесь какой то текстздесь какой то текст
<p>здесь какой то текстздесь какой то текстздесь какой то текстздесь какой то текст</p>
Спасибо друг, но не помогло(string text = project.Variables["HTML"].Value;
string pattern = @"(<p[^>]*>)([^<]*)(?!<\/p>)";
string result = System.Text.RegularExpressions.Regex.Replace(text, pattern, "$1$2</p>");
project.Variables["HTML"].Value = result;
