


- Регистрация
- 09.10.2015
- Сообщения
- 3 916
- Благодарностей
- 3 883
- Баллы
- 113
ДаА как, ты говорил, он обновляться будет? За счет какой-то внешней библиотеки?
 :-)")
Где-то может неправильно определить контент, это нормально - везде есть ошибки, идеального алгоритма нету (я про это начал свой первый пост с отсылкой на видео в моем блоге).Заметил, правда, что он некоторые тексты все-таки режет, но что уж тут, либо скорость, либо качество
В пол потока парсил? Очень долго что-то.400 текстов за 20 минут - найз


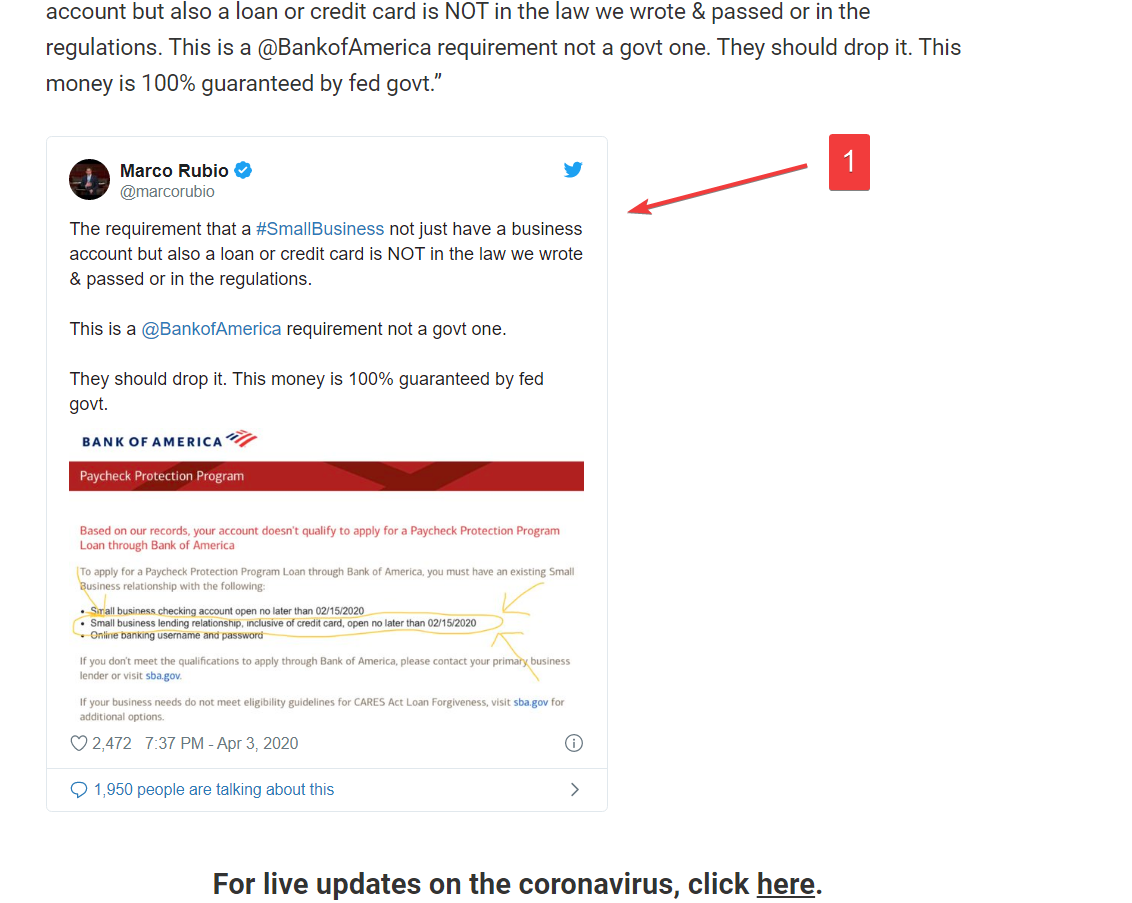
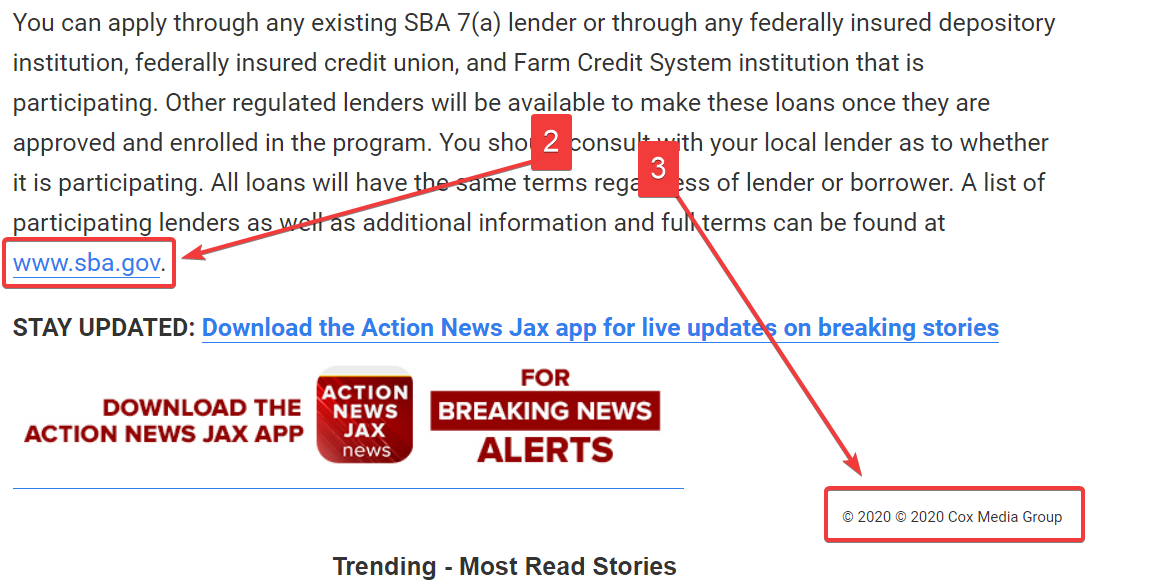

 Получается что не вычищает
Получается что не вычищает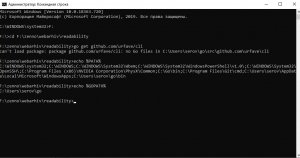


 я же ее отслеживать поставил, когда голосовал. Админы удалите пожалуйста мою писанину с данной темы. И ты автор извини что натоптал тут.
я же ее отслеживать поставил, когда голосовал. Админы удалите пожалуйста мою писанину с данной темы. И ты автор извини что натоптал тут.